When Model Merging Breaks Routing: Training-Free Calibration for MoE
Pith reviewed 2026-06-28 11:43 UTC · model grok-4.3
The pith
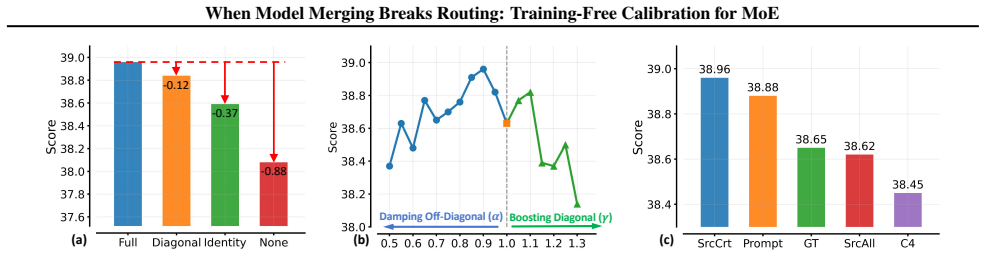
Merged MoE models suffer routing breakdown because softmax and top-k routing are sensitive to parameter changes from merging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Model merging applied to MoE architectures produces routing breakdown in which the merged router fails to dispatch tokens to suitable experts; this breakdown can be corrected by Hessian-Aware Router Calibration, which leverages second-order curvature information to realign the router parameters through a closed-form solution solved with a matrix-free conjugate gradient method.
What carries the argument
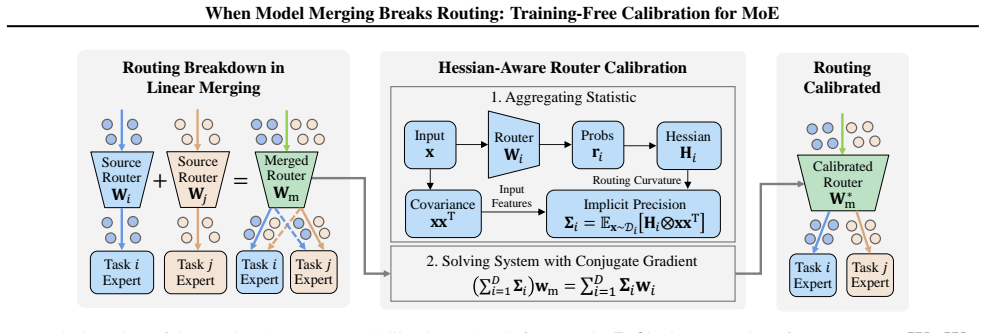
Hessian-Aware Router Calibration (HARC), a training-free framework that computes a second-order curvature adjustment to the merged router parameters.
If this is right
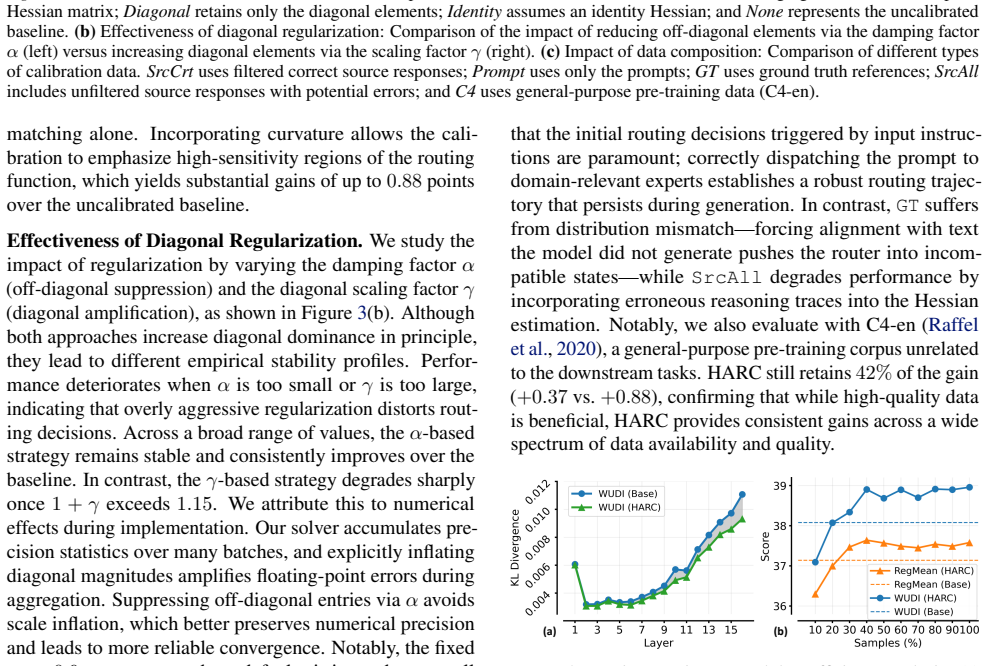
- HARC produces substantial performance gains on mathematical reasoning and code generation tasks after merging.
- The method works across diverse MoE merging baselines without any task-specific data.
- The closed-form solution allows efficient calibration using only the merged parameters and their Hessian.
- Load-balancing constraints from pretraining amplify the sensitivity that HARC targets.
Where Pith is reading between the lines
- If second-order adjustments suffice here, similar curvature-based corrections might address other non-linear gating failures in merged models.
- The approach could be tested on MoE variants that use different routing functions beyond softmax top-k.
- Extending the calibration to the expert parameters themselves rather than only the router remains an open direction.
Load-bearing premise
The non-linear softmax and discrete top-k routing mechanisms remain correctable by a second-order curvature adjustment derived from the merged parameters without requiring any retraining or access to the original training data.
What would settle it
Running HARC on a merged MoE model and measuring no increase in routing accuracy to the originally specialized experts or no gain on downstream math-reasoning benchmarks would falsify the claim.
Figures
read the original abstract
Model merging has emerged as a cost-effective approach for consolidating the capabilities of multiple LLMs without retraining. However, existing merging techniques, largely based on linear parameter arithmetic or optimization, struggle when applied to Mixture-of-Experts (MoE) architectures. We identify a critical failure mode in MoE merging, termed routing breakdown, in which the merged router fails to dispatch tokens to suitable experts. Routing breakdown stems from the sensitivity of the non-linear softmax and discrete Top-k routing mechanisms to parameter perturbations from merging, a sensitivity further amplified by load-balancing constraints imposed during MoE pretraining. Because fine-tuned experts exhibit distinct specializations, even modest misrouting can cause severe performance degradation. To address this issue, we propose Hessian-Aware Router Calibration (HARC), a training-free framework that leverages second-order curvature information to realign the merged router. This approach admits a closed-form solution that can be efficiently solved using a matrix-free conjugate gradient method. Experiments on mathematical reasoning and code generation tasks show that HARC effectively mitigates routing breakdown across diverse MoE merging baselines and leads to substantial performance improvements. Our code is available at https://github.com/huangcb01/HARC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies routing breakdown as a failure mode when merging MoE models, arising from the sensitivity of softmax and discrete Top-k routing (amplified by load-balancing) to parameter perturbations. It proposes Hessian-Aware Router Calibration (HARC), a training-free method that derives a closed-form correction from the Hessian of the merged router parameters and solves it via matrix-free conjugate gradient. Experiments on mathematical reasoning and code generation tasks are reported to show that HARC mitigates breakdown across merging baselines and yields substantial gains; code is released at the cited GitHub repository.
Significance. If the experimental outcomes and the validity of the curvature correction hold, the work would be a useful practical contribution to training-free merging of MoE architectures, which are central to efficient large-scale LLMs. The training-free, closed-form character and the public code release are clear strengths that facilitate reproducibility and extension.
major comments (1)
- [method / HARC derivation] The derivation of the closed-form calibration (method section) models the router objective as locally quadratic via its Hessian and applies a matrix-free CG solve. Because the true routing map includes a non-differentiable Top-k operator (plus load-balancing), the routing function is piecewise constant and its Hessian is undefined almost everywhere; the quadratic approximation therefore cannot be guaranteed to restore correct expert assignments after the hard threshold. This assumption is load-bearing for the central claim that HARC corrects routing breakdown without retraining or data access.
minor comments (2)
- [abstract / experiments] The abstract states performance gains but supplies no numerical values, baselines, error bars, or ablation on the Hessian approximation; the experiments section should include these details with explicit tables.
- [method] Notation for the router parameters and the precise form of the curvature objective should be introduced with an equation number early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key subtlety in the theoretical grounding of HARC. We address the concern directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [method / HARC derivation] The derivation of the closed-form calibration (method section) models the router objective as locally quadratic via its Hessian and applies a matrix-free CG solve. Because the true routing map includes a non-differentiable Top-k operator (plus load-balancing), the routing function is piecewise constant and its Hessian is undefined almost everywhere; the quadratic approximation therefore cannot be guaranteed to restore correct expert assignments after the hard threshold. This assumption is load-bearing for the central claim that HARC corrects routing breakdown without retraining or data access.
Authors: We agree that the full routing map, once the non-differentiable Top-k and load-balancing are included, is piecewise constant and that its Hessian is formally undefined almost everywhere. In the derivation we compute the Hessian only on the differentiable component of the router—the linear transformation that produces the pre-softmax logits—treating the subsequent discretization as a downstream threshold. The quadratic model is therefore an approximation to the logit-level objective, not to the discrete assignment map itself. The closed-form correction is intended to reduce the logit discrepancy between the merged router and the original routers, thereby increasing the probability that the subsequent Top-k recovers the intended expert. We do not claim, and the manuscript does not prove, that this procedure is guaranteed to restore exact original assignments after the hard threshold. The central empirical claim is that the resulting router yields measurably better routing fidelity and downstream performance than the uncalibrated merged router, which our experiments support across several merging baselines. We will revise the method section to state explicitly that the quadratic approximation applies to the logit function and to note the absence of a theoretical guarantee for the discrete Top-k step. revision: yes
Circularity Check
No circularity: HARC calibration is an independent second-order correction derived from merged parameters
full rationale
The paper presents HARC as a training-free method that computes a closed-form correction from the Hessian of the merged router weights and solves it via matrix-free CG. This step is constructed from the input merged parameters and standard curvature information rather than from any self-referential definition, fitted subset renamed as prediction, or load-bearing self-citation. No equation or section reduces the claimed correction to the paper's own inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The merged router's routing decisions are governed by non-linear softmax and discrete Top-k operations that are sensitive to parameter perturbations from merging.
- standard math Second-order curvature information from the Hessian admits a closed-form calibration solution solvable by matrix-free conjugate gradient.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2503.08099. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint,
-
[2]
URL https://arxiv.org/abs/2110.14168. Cui, G., Yuan, L., Ding, N., Yao, G., He, B., Zhu, W., Ni, Y ., Xie, G., Xie, R., Lin, Y ., Liu, Z., and Sun, M. UL- TRAFEEDBACK: boosting language models with scaled AI feedback. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21- 27, 2024, Proceedings of Machine Learning ...
Pith/arXiv arXiv 2024
-
[3]
URL https://arxiv.org/abs/2504.10902. Deep, P. T., Bhardwaj, R., and Poria, S. Della-merging: Re- ducing interference in model merging through magnitude- based sampling.arXiv preprint,
-
[4]
URL https: //arxiv.org/abs/2406.11617. Frankle, J., Dziugaite, G. K., Roy, D. M., and Carbin, M. Linear mode connectivity and the lottery ticket hypothesis. InInternational Conference on Machine Learning, pp. 3259–3269,
-
[5]
Neuron- merge: Merging models via functional neuron groups
Gu, W., Gao, Q., Li-Xin, Z., Shen, X., and Ye, J. Neuron- merge: Merging models via functional neuron groups. In Findings of the Association for Computational Linguis- tics: ACL 2025, pp. 9015–9037,
2025
-
[6]
URL https://arxiv. org/abs/2212.09849. Lin, Y .-T., Jin, D., Xu, T., Wu, T., Sukhbaatar, S., Zhu, C., He, Y ., Chen, Y .-N., Weston, J., Tian, Y ., Rahnama, A., Wang, S., Ma, H., and Fang, H. Step-kto: Op- timizing mathematical reasoning through stepwise bi- nary feedback.arXiv preprint,
-
[7]
URL https: //arxiv.org/abs/2501.10799. Liu, J., Xia, C. S., Wang, Y ., and Zhang, L. Is your code gen- erated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in neural information processing systems, 36:21558–21572,
-
[8]
URL https: //arxiv.org/abs/2409.02060. Nobari, A. H., Alim, K., ArjomandBigdeli, A., Srivastava, A., Ahmed, F., and Azizan, N. Activation-informed merg- ing of large language models.arXiv preprint,
-
[9]
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P
URL https://arxiv.org/abs/2502.02421. Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21 (140):1–67,
-
[10]
Com- monsenseqa: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Com- monsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics, pp. 4149–4158,
2019
-
[11]
Wan, F., Zhong, L., Yang, Z., Chen, R., and Quan, X
URL https: //arxiv.org/abs/2410.01560. Wan, F., Zhong, L., Yang, Z., Chen, R., and Quan, X. Fusechat: Knowledge fusion of chat models.arXiv preprint,
-
[12]
Wang, K., Dimitriadis, N., Ortiz-Jim ´enez, G., Fleuret, F., and Frossard, P
URL https://arxiv.org/abs/ 2408.07990. Wang, K., Dimitriadis, N., Ortiz-Jim ´enez, G., Fleuret, F., and Frossard, P. Localizing task information for improved model merging and compression. InInternational Con- ference on Machine Learning, pp. 50268–50287,
-
[13]
Wortsman, M., Ilharco, G., Gadre, S
URL https://arxiv.org/abs/2501.01230. Wortsman, M., Ilharco, G., Gadre, S. Y ., Roelofs, R., Gontijo-Lopes, R., Morcos, A. S., Namkoong, H., Farhadi, A., Carmon, Y ., Kornblith, S., et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pp. 2...
-
[14]
Yadav, P., Tam, D., Choshen, L., Raffel, C
URL https://arxiv.org/abs/2411.18729. Yadav, P., Tam, D., Choshen, L., Raffel, C. A., and Bansal, M. Ties-merging: Resolving interference when merging models.Advances in Neural Information Processing Systems, 36:7093–7115,
-
[15]
Yang, E., Wang, Z., Shen, L., Liu, S., Guo, G., Wang, X., and Tao, D
URL https: //arxiv.org/abs/2505.09388. Yang, E., Wang, Z., Shen, L., Liu, S., Guo, G., Wang, X., and Tao, D. Adamerging: Adaptive model merging for multi-task learning.arXiv preprint,
-
[16]
URL https: //arxiv.org/abs/2310.02575. 10 When Model Merging Breaks Routing: Training-Free Calibration for MoE Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y . Language mod- els are super mario: Absorbing abilities from homologous models as a free lunch. InInternational Conference on Machine Learning,
-
[17]
11 When Model Merging Breaks Routing: Training-Free Calibration for MoE A
URL https://arxiv.org/abs/2311.07911. 11 When Model Merging Breaks Routing: Training-Free Calibration for MoE A. Proofs and Assumption Validation In this section, we provide detailed proofs for the theoretical results presented in Section 4 and validate the key assumption underlying Lemma 4.1. A.1. Proof and Assumption Validation of Lemma 4.1 Proof.Let th...
-
[18]
Maintaining the CG state vectors (e.g.,w,r,p,q) takesO(Kd)
memory. Maintaining the CG state vectors (e.g.,w,r,p,q) takesO(Kd). The overall space complexity reduces toO(N total ·d+Kd). • Time Complexity:The CG solver computes matrix-vector products on the fly. Evaluating the operator for all tokens in a single iteration takes O(Ntotal ·Kd) time. Thus, the optimization time for all layers is O(L·T·N total ·Kd) . No...
2024
-
[19]
and CommonsenseQA (Talmor et al., 2019)), math benchmarks (GSM8K (Cobbe et al.,
2019
-
[20]
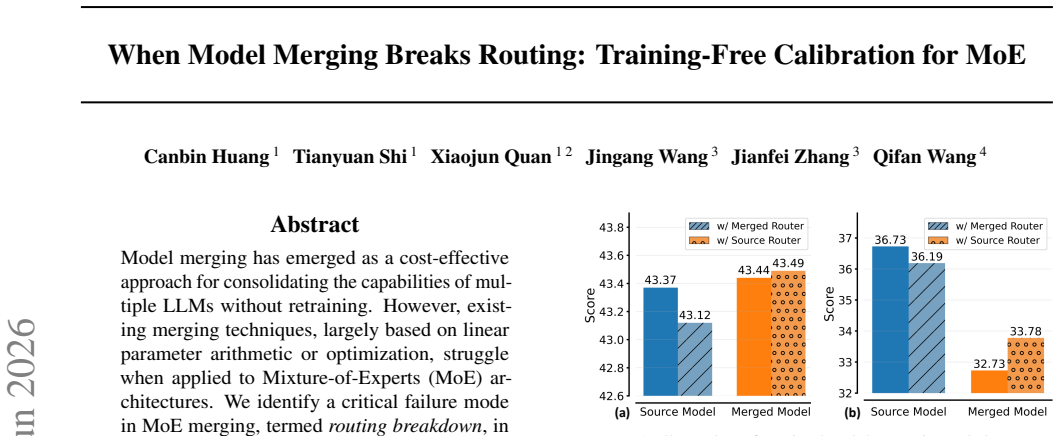
Table 5.Multi-task performance when merging three OLMoE models (chat, math, and code)
and MATH500 (Lin et al., 2025)), and code benchmarks (HumanEval+ and MBPP+ (Liu et al., 2023)). Table 5.Multi-task performance when merging three OLMoE models (chat, math, and code). Method Chat Math Code OverallIFEval CommQA Average GSM8K MATH500 Average HumanEval+ MBPP+ Average Individual 63.05 58.98 61.02 69.20 17.53 43.37 33.50 39.95 36.73 47.04 Weigh...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.