When Should the Teacher Move? Temporal Coupling and Stability in Self On-Policy Distillation
Pith reviewed 2026-06-28 11:11 UTC · model grok-4.3
The pith
In self on-policy distillation, isolation periods between teacher updates stabilize learning while clock-driven refreshes trigger irreversible collapse; a gated refresh method eliminates collapse across tasks with one parameter set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
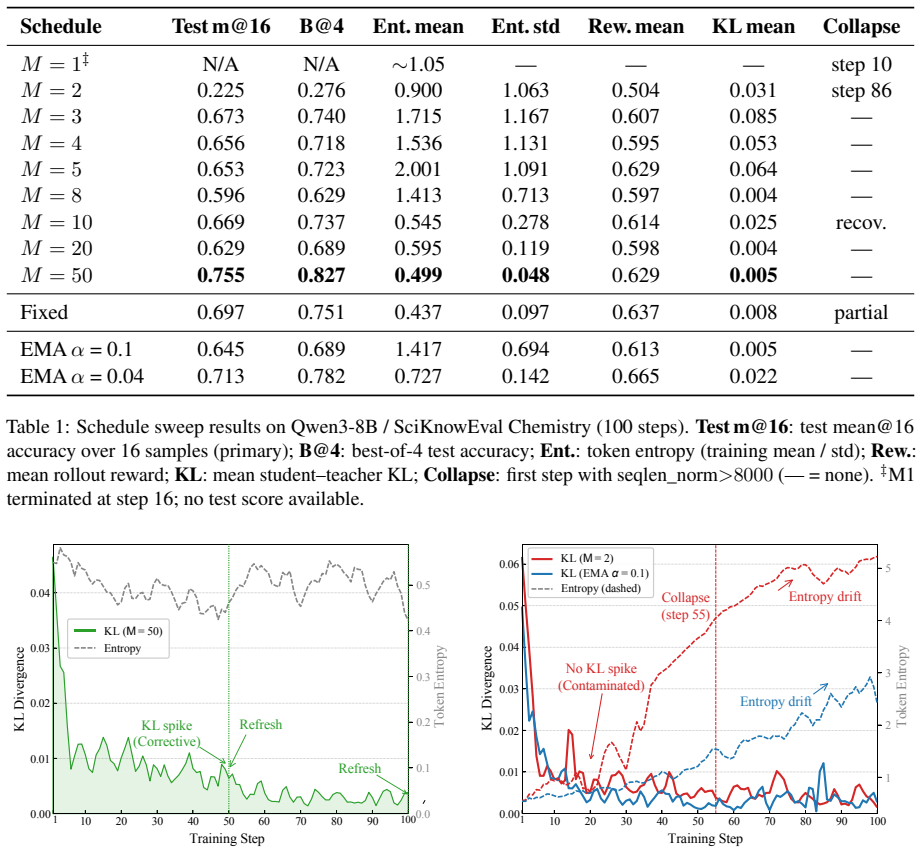
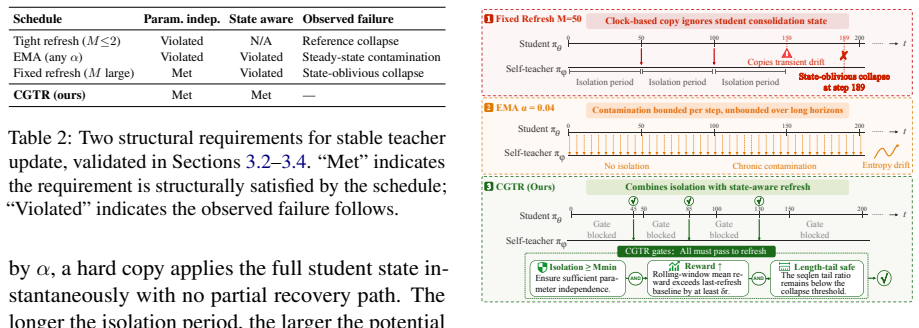
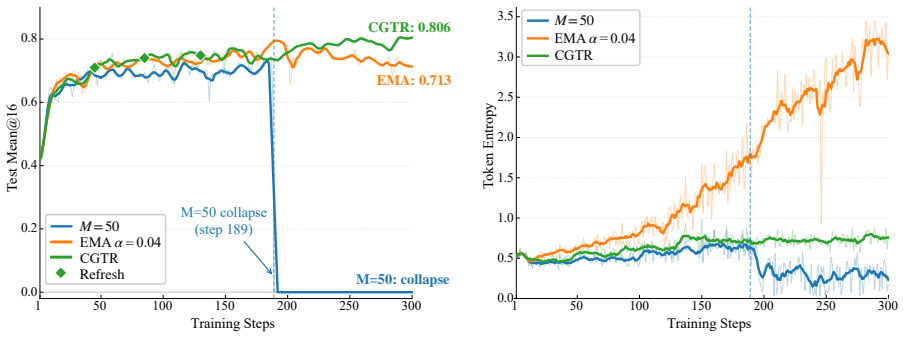
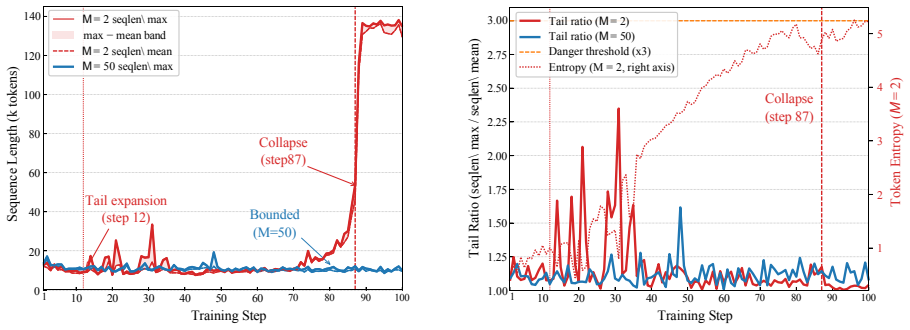
Self on-policy distillation trains a student against a teacher drawn from its own past parameters, yet the schedule that decides when the teacher moves has remained unexamined as a stability factor. Controlled sweeps reveal that complete isolation periods, not teacher age, are the structural feature that prevents instability. Fixed short-horizon schedules fail at long horizons by allowing a clock signal to copy a transiently drifted student into the teacher in one step, a failure mode distinct from EMA contamination. Consolidation-Gated Teacher Refresh preserves isolation but gates each refresh on joint evidence of reward gain and length-tail safety, producing zero collapse and the best scor
What carries the argument
Consolidation-Gated Teacher Refresh (CGTR), which maintains isolation periods and conditions each teacher update on simultaneous reward improvement and length-tail safety checks rather than a fixed clock.
If this is right
- Fixed clock-driven teacher refreshes produce irreversible collapse once training exceeds the short horizon used for schedule tuning.
- Isolation periods alone stabilize learning even when teacher age varies.
- CGTR self-regulates refresh frequency to match each task's learning dynamics without manual retuning.
- A single parameter set suffices for best performance and zero collapse across Chemistry, Biology, Physics, and ToolUse.
Where Pith is reading between the lines
- The gating logic could be tested on other on-policy methods that maintain a teacher copy to see whether the same collapse pattern appears.
- Longer-horizon experiments on the same tasks would directly test whether the reported refresh-shock metric predicts collapse timing.
- The diagnostic framework of temporal KL structure and length-tail risk might be applied to measure stability in related distillation setups that do not use on-policy data.
Load-bearing premise
The stability benefit of isolation periods and the zero-collapse outcome of CGTR observed on four tasks with Qwen3-8B will hold for other model sizes, domains, and training lengths.
What would settle it
Train the same model on one of the four tasks for several times the reported horizon using a fixed short refresh schedule and check whether state-oblivious collapse appears at the point predicted by the temporal KL and refresh-shock diagnostics.
Figures

read the original abstract
Self on-policy distillation trains a student policy against a teacher derived from its own parameter history, yet the teacher's update schedule -- which governs the \emph{temporal coupling} between teacher and student -- has not been systematically studied as a stability variable. Through a controlled schedule sweep on Qwen3-8B, we establish that \emph{isolation periods}, defined as complete teacher freezing between updates, are the key structural property enabling stable learning, not teacher age. To characterize these underlying training dynamics, we introduce a diagnostic framework of temporal KL structure, refresh shock, and length-tail risk. This framework further uncovers \emph{state-oblivious collapse}: optimal short-horizon fixed schedules catastrophically fail under long-horizon training because a clock-driven refresh can copy a transiently drifting student into the teacher in a single, irreversible step. This failure mode is invisible under short-horizon evaluation and mechanistically distinct from EMA's chronic contamination. To address this, we propose \emph{Consolidation-Gated Teacher Refresh} (CGTR), which preserves isolation periods while gating each refresh on joint evidence of reward improvement and length-tail safety, ensuring every teacher movement responds to genuine student consolidation rather than a clock signal. With a single shared parameter set and no per-dataset retuning, CGTR achieves \textbf{zero collapse} and the best final score on all four tasks (Chemistry, Biology, Physics, ToolUse), self-regulating its refresh frequency to each task's learning dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the role of teacher update schedules (temporal coupling) in self on-policy distillation. It concludes that isolation periods, rather than teacher age, are the key structural property for stability; introduces diagnostics (temporal KL structure, refresh shock, length-tail risk) that reveal state-oblivious collapse in clock-driven fixed schedules; and proposes Consolidation-Gated Teacher Refresh (CGTR), which gates refreshes on joint reward improvement and length-tail safety. With one shared parameter set, CGTR is reported to produce zero collapse and the highest final score on Chemistry, Biology, Physics, and ToolUse using Qwen3-8B.
Significance. If the empirical outcomes hold under scrutiny, the work supplies a practical, adaptive mechanism for stabilizing self-distillation that avoids both chronic EMA contamination and irreversible state-oblivious collapse, while eliminating per-task retuning.
major comments (2)
- [Abstract] Abstract/Results: the claim of zero collapse and best final score on all four tasks is presented without reported variance, number of independent runs, or precise operational definitions of the diagnostic metrics (temporal KL structure, refresh shock, length-tail risk) and the collapse criterion; these omissions are load-bearing for the central empirical claim.
- [Abstract] The gating logic of CGTR (joint reward improvement + length-tail safety) plus the shared-parameter claim rests on performance observed only with Qwen3-8B on the four listed tasks; no evidence is supplied that the same thresholds remain sufficient when reward sparsity, sequence-length distributions, or model scale alter the underlying KL dynamics.
minor comments (1)
- The distinction between isolation periods and standard EMA should be stated with an explicit equation or pseudocode in the methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical reporting and scope. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract/Results: the claim of zero collapse and best final score on all four tasks is presented without reported variance, number of independent runs, or precise operational definitions of the diagnostic metrics (temporal KL structure, refresh shock, length-tail risk) and the collapse criterion; these omissions are load-bearing for the central empirical claim.
Authors: We agree these elements are necessary to support the central claims. The full manuscript reports results over multiple independent runs with variance in the experimental sections and provides operational definitions (temporal KL structure in Section 3.2, refresh shock in Section 3.3, length-tail risk in Section 3.4, and the collapse criterion in Section 4.1). The abstract, however, does not reference them. In the revision we will update the abstract to state the number of runs, note the presence of variance, and include concise operational definitions or cross-references to the criteria. revision: yes
-
Referee: [Abstract] The gating logic of CGTR (joint reward improvement + length-tail safety) plus the shared-parameter claim rests on performance observed only with Qwen3-8B on the four listed tasks; no evidence is supplied that the same thresholds remain sufficient when reward sparsity, sequence-length distributions, or model scale alter the underlying KL dynamics.
Authors: All reported results use Qwen3-8B on the four tasks and demonstrate that a single shared parameter set for CGTR succeeds without per-task retuning in this regime. No additional experiments on other model scales or altered reward/sequence distributions are included. We will add an explicit limitations paragraph noting the current scope and identifying validation across scales and dynamics as future work. revision: partial
Circularity Check
No circularity: purely empirical claims with no derivation chain
full rationale
The manuscript contains no mathematical derivation, first-principles result, or predictive equation whose output reduces to its inputs by construction. All central claims (zero collapse under CGTR, self-regulation of refresh frequency, superiority on four tasks) are presented as direct experimental outcomes on Qwen3-8B. The introduced diagnostics (temporal KL structure, refresh shock, length-tail risk, state-oblivious collapse) are defined and measured within the same evaluation protocol, but this is standard empirical framing rather than a self-definitional loop or fitted-input-called-prediction. No self-citations, uniqueness theorems, or ansatzes appear as load-bearing steps. The work is therefore self-contained as an empirical study against its own benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Learning Visual Spatial Planning from Symbolic State via Modality-Gap-Aware Self-Distillation
MGSD is a modality-gap-aware self-distillation method that improves visual spatial planning in 4B and 8B VLMs by 19.3% and 18.4% macro average on benchmarks by distilling from symbolic states during training only.
Reference graph
Works this paper leans on
-
[1]
In International Conference on Learning Representa- tions
On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representa- tions. ArXiv:2306.13649. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Zhihong Shao, Peiyi Wang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, and 1 others
-
[2]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948. Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, and Huajun Chen
-
[3]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H
Sciknoweval: Evaluating multi-level scientific knowledge of large language models.Preprint, arXiv:2406.09098. Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko
-
[4]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531. Jonas Hübotter, Frederike Lübeck, Lejs Behric, An- ton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause
-
[5]
Re- inforcement learning via self-distillation.Preprint, arXiv:2601.20802. Yoon Kim and Alexander M. Rush
-
[6]
InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327
Sequence- level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327. Association for Computational Linguistics. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding
2016
-
[7]
Ilya Loshchilov and Frank Hutter
Rethinking on-policy distillation of large lan- guage models: Phenomenology, mechanism, and recipe.Preprint, arXiv:2604.13016. Ilya Loshchilov and Frank Hutter
-
[8]
Crisp: Com- pressed reasoning via iterative self-policy distillation. Preprint, arXiv:2603.05433. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[9]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y .K
Proxi- mal policy optimization algorithms.arXiv preprint arXiv:1707.06347. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo
-
[10]
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.Preprint, arXiv:2402.03300. Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun
-
[11]
Antti Tarvainen and Harri Valpola
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.Preprint, arXiv:2306.05301. Antti Tarvainen and Harri Valpola
-
[12]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan
-
[13]
Self-distilled rlvr. Preprint, arXiv:2604.03128. Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman
-
[14]
InAdvances in Neural Information Processing Systems, volume 35, pages 15476–15488
STaR: Self-taught reasoner boot- strapping reasoning with reasoning. InAdvances in Neural Information Processing Systems, volume 35, pages 15476–15488. Ruicheng Zhang, Guangyu Chen, Zunnan Xu, Zihao Liu, Zhizhou Zhong, Mingyang Zhang, Jun Zhou, and Xiu Li. 2026a. Robostereo: Dual-tower 4d em- bodied world models for unified policy optimization. arXiv prep...
-
[15]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover
Mind- v: Hierarchical video generation for long-horizon robotic manipulation with rl-based physical align- ment.arXiv preprint arXiv:2512.06628. Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover
-
[16]
Self-distilled reasoner: On-policy self-distillation for large language models.Preprint, arXiv:2601.18734. Supplementary Material A Experimental Details A.1 Data and Prompt Format Dataset splits.SciKnowEval (Feng et al.,
-
[17]
The ground-truth labels are not included in the training prompts, so there is no answer-leakage risk
No external verifier or neural reward model is used. The ground-truth labels are not included in the training prompts, so there is no answer-leakage risk. A.3 Rollout and Decoding Parameters Training rollouts.Temperature 1.0, top-p=1.0, top-k=−1 (disabled), n=4 responses per question (GRPO group size (Shao et al., 2024; Zhang et al., 2026b)). Test evaluat...
2024
-
[18]
Cross-task runs (Biology, Physics, ToolUse): every 10 steps
Long-horizon comparison (Chem- istry): every step (test_freq= 1). Cross-task runs (Biology, Physics, ToolUse): every 10 steps. 10 Table 7: Full metrics for all schedule sweep experiments (100 steps). Slen mean/max = seqlen_norm; Succ = success_group_fraction mean; Ent. fin = last-step entropy. †M1 terminated step 16; ent. mean over steps 1–16 only. Settin...
1984
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.