DDOR: Delta Debugging for Explainable Overrefusal Testing and Repair
Pith reviewed 2026-06-28 08:52 UTC · model grok-4.3
The pith
DDOR uses delta debugging to localize minimal refusal fragments in LLMs and repair them to reduce overrefusals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DDOR applies delta debugging to localize minimal refusal-triggering fragments (mRTFs) that provide phrase-level, explainable evidence for why a refusal occurs. Conditioned on these mRTFs, DDOR generates diverse, context-rich prompts and performs multi-oracle validation to filter intrinsically unsafe or ambiguous cases, producing scalable and model-specific overrefusal test suites (approximately 1K cases per model). Beyond evaluation, DDOR leverages localized mRTFs to perform targeted prompt repair, substantially reducing overrefusal while preserving the original intent and maintaining safety on genuinely harmful inputs.
What carries the argument
Delta debugging to localize minimal refusal-triggering fragments (mRTFs)
If this is right
- Produces model-specific overrefusal test suites of approximately 1K cases each.
- Supplies phrase-level explanations for why refusals occur.
- Enables targeted prompt repairs that reduce overrefusal while preserving safety on harmful inputs.
- Operates fully in a black-box setting using only inputs and outputs.
Where Pith is reading between the lines
- The identified fragments could be compared across models to find shared overrefusal patterns.
- Similar localization methods might apply to other unwanted LLM outputs such as biased responses.
- The resulting test suites could form the basis for standardized evaluations of overrefusal.
Load-bearing premise
The minimal refusal-triggering fragments are causally responsible for the refusal and multi-oracle validation reliably separates unsafe or ambiguous cases from benign overrefusals.
What would settle it
An experiment in which removing an identified mRTF from a prompt still triggers refusal, or in which repaired prompts allow genuinely harmful content to pass.
Figures

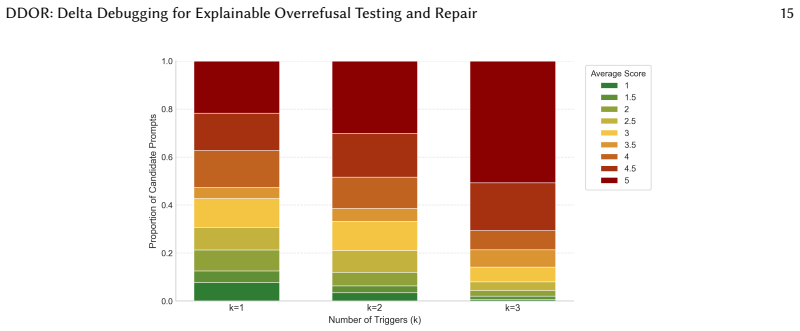

read the original abstract
While safety alignment and guardrails help large language models (LLMs) avoid harmful outputs, they can also induce overrefusal, i.e., unwarranted rejection of benign queries that merely appear risky. We present DDOR (Delta Debugging for OverRefusal), a fully automated and explainable framework for overrefusal testing and repair in a black-box setting, where only model inputs and outputs are accessible and internal safety mechanisms remain opaque. DDOR applies delta debugging to localize minimal refusal-triggering fragments (mRTFs) that provide phrase-level, explainable evidence for why a refusal occurs. Conditioned on these mRTFs, DDOR generates diverse, context-rich prompts and performs multi-oracle validation to filter intrinsically unsafe or ambiguous cases, producing scalable and model-specific overrefusal test suites (approximately 1K cases per model). Beyond evaluation, we further leverage localized mRTFs to perform targeted prompt repair, substantially reducing overrefusal while preserving the original intent and maintaining safety on genuinely harmful inputs. Overall, DDOR offers a practical end-to-end solution to both evaluate and mitigate overrefusal, improving LLM usability without sacrificing safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DDOR, a black-box framework that applies delta debugging to localize minimal refusal-triggering fragments (mRTFs) as explainable evidence for LLM overrefusals, then uses these to generate diverse prompts, applies multi-oracle validation to produce ~1K-case model-specific test suites, and performs targeted prompt repair to reduce overrefusals while preserving safety on harmful inputs.
Significance. If the core assumptions hold, DDOR would supply a practical, automated, and phrase-level explainable method for both diagnosing and mitigating overrefusal in deployed LLMs without internal access, addressing a real usability gap in safety-aligned models.
major comments (3)
- [Abstract, §3] Abstract and §3 (DDOR framework): the claim that mRTFs are causally responsible for refusals rests on delta debugging's minimal-subset guarantee, yet the paper does not address or test the known non-monotonicity of LLM refusal decisions; no experiments demonstrate that the extracted mRTF remains sufficient or necessary when the surrounding prompt context is varied.
- [Abstract, §4] Abstract and §4 (multi-oracle validation): the production of scalable ~1K-case suites is asserted to cleanly separate overrefusals from unsafe/ambiguous cases, but no inter-oracle agreement statistics, oracle selection criteria, or human validation results are reported, leaving the reliability of the filter unverified.
- [Abstract] Abstract (repair procedure): the targeted repair is claimed to substantially reduce overrefusal while maintaining safety on genuinely harmful inputs, yet the abstract (and by extension the central end-to-end claim) provides no quantitative metrics, ablation results, or error analysis to support effectiveness.
minor comments (2)
- [§3] Notation for mRTF is introduced without an explicit formal definition or pseudocode in the early sections, making the precise output of the delta-debugging step harder to replicate.
- [Abstract] The abstract states 'approximately 1K cases per model' without specifying the exact generation parameters or diversity metrics used to reach that scale.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (DDOR framework): the claim that mRTFs are causally responsible for refusals rests on delta debugging's minimal-subset guarantee, yet the paper does not address or test the known non-monotonicity of LLM refusal decisions; no experiments demonstrate that the extracted mRTF remains sufficient or necessary when the surrounding prompt context is varied.
Authors: Delta debugging guarantees a minimal subset that is sufficient to trigger the observed refusal in the specific prompt context from which it was extracted. We agree that this does not automatically establish causality or necessity across all possible contexts due to the potential non-monotonicity of LLM decisions. The manuscript does not include experiments that vary the surrounding context to test this. We will add a dedicated discussion of this limitation in the revised paper, including why such tests were not performed in the initial evaluation. revision: partial
-
Referee: [Abstract, §4] Abstract and §4 (multi-oracle validation): the production of scalable ~1K-case suites is asserted to cleanly separate overrefusals from unsafe/ambiguous cases, but no inter-oracle agreement statistics, oracle selection criteria, or human validation results are reported, leaving the reliability of the filter unverified.
Authors: The multi-oracle validation procedure is detailed in §4, including the use of multiple oracles to filter cases. However, we acknowledge that explicit inter-oracle agreement statistics, detailed selection criteria, and human validation results are not reported. We will revise the manuscript to include inter-oracle agreement metrics and clarify the oracle selection process. Human validation is noted as future work due to resource constraints. revision: yes
-
Referee: [Abstract] Abstract (repair procedure): the targeted repair is claimed to substantially reduce overrefusal while maintaining safety on genuinely harmful inputs, yet the abstract (and by extension the central end-to-end claim) provides no quantitative metrics, ablation results, or error analysis to support effectiveness.
Authors: The abstract is intended as a concise overview and does not include specific numbers. The full paper presents quantitative results, ablations, and error analysis in the experimental sections supporting the repair effectiveness. To better align the abstract with the central claims, we will update the abstract to include key quantitative metrics from the evaluation. revision: yes
- Experiments testing mRTF sufficiency and necessity under varied prompt contexts, as this would require substantial additional empirical evaluation not present in the current work.
Circularity Check
No circularity; procedural framework relies on external oracles
full rationale
The paper introduces DDOR as a procedural algorithm that applies delta debugging (a pre-existing technique) to localize mRTFs, then uses multi-oracle validation and prompt repair. No equations, fitted parameters, predictions, or derivations are present. Claims rest on the external validity of oracles and delta debugging monotonicity assumptions rather than any self-referential definition or self-citation chain that reduces the result to its inputs. This is the normal case of a self-contained engineering method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aider-AI. 2025. Aider: AI Pair Programming in Your Terminal. https://aider.chat/
2025
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073 2022
-
[3]
Somnath Banerjee, Sayan Layek, Soham Tripathy, Shanu Kumar, Animesh Mukherjee, and Rima Hazra. 2025. SafeInfer: Context Adaptive Decoding Time Safety Alignment for Large Language Models. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA. AAAI Press, 27188–27196. https...
-
[4]
ChatAnywhere. 2025. ChatAnywhere API. https://api.chatanywhere.tech
2025
-
[5]
Holger Cleve and Andreas Zeller. 2005. Locating Causes of Program Failures. InProceedings of the 27th International Conference on Software Engineering (ICSE ’05). ACM, 342–351. doi:10.1145/1062455.1062522
-
[6]
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. 2025. OR-Bench: An Over-Refusal Benchmark for Large Language Models. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id= CdFnEu0JZV
2025
-
[7]
Tianqi Du, Zeming Wei, Quan Chen, and Yisen Wang. 2025. Advancing LLM Safe Alignment with Safety Representation Ranking. InICML 2025 Workshop on Reliable and Responsible Foundation Models. https://openreview.net/forum?id= BfWptIx53G
2025
-
[8]
Simos Gerasimou, Hasan Ferit Eniser, Alper Sen, and Alper Çakan. 2020. Importance-driven deep learning system testing. InICSE ’20: 42nd International Conference on Software Engineering, Seoul, South Korea, 27 June - 19 July, 2020, Gregg Rothermel and Doo-Hwan Bae (Eds.). ACM, 702–713. doi:10.1145/3377811.3380391
-
[9]
Google. 2025. Generative Language API. https://generativelanguage.googleapis.com
2025
-
[10]
HotBento. 2025. ORFuzz. https://figshare.com/ndownloader/files/57175505?private_link=358b7ac0c060327480c7
arXiv 2025
-
[11]
HotBento. 2025. ORFuzz. https://github.com/HotBento/ORFuzz
2025
-
[12]
Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, and Ling Liu. 2025. Safety Tax: Safety Alignment Makes Your Large Reasoning Models Less Reasonable.CoRRabs/2503.00555 (2025). arXiv:2503.00555 doi:10.48550/ARXIV.2503.00555
-
[13]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674(2023)
Pith/arXiv arXiv 2023
-
[14]
Leonard Kaufman and Peter J. Rousseeuw. 1990.Finding Groups in Data: An Introduction to Cluster Analysis. John Wiley. https://doi.org/10.1002/9780470316801
-
[15]
Yue Liu, Hongcheng Gao, Shengfang Zhai, Jun Xia, Tianyi Wu, Zhiwei Xue, Yulin Chen, Kenji Kawaguchi, Jiaheng Zhang, and Bryan Hooi. 2025. GuardReasoner: Towards Reasoning-based LLM Safeguards. InICLR 2025 Workshop on Foundation Models in the Wild. https://openreview.net/forum?id=5evTkMBwJA
2025
-
[16]
Master-PLC. 2025. RASS. https://github.com/Master-PLC/RASS
2025
-
[17]
Ghassan Misherghi and Zhendong Su. 2006. HDD: Hierarchical Delta Debugging. InProceedings of the 28th International Conference on Software Engineering (ICSE ’06). ACM, 142–151. doi:10.1145/1134285.1134307
-
[18]
Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh
Kyle O’Brien, David Majercak, Xavier Fernandes, Richard G. Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh. 2025. Steering Language Model Refusal with Sparse Autoencoders. InICML 2025 Workshop on Reliable and Responsible Foundation Models. https://openreview.net/forum? id=PMK1jdGQoc
2025
-
[19]
OpenAI. 2025. OpenAI API. https://api.openai.com
2025
-
[20]
OpenAI. 2026. OpenAI API. https://platform.openai.com/tokenizer
2026
-
[21]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow 22 instructions with ...
2022
-
[22]
Licheng Pan, Yongqi Tong, Xin Zhang, Xiaolu Zhang, Jun Zhou, and Zhixuan Chu. 2025. Understanding and Mitigating Overrefusal in LLMs from an Unveiling Perspective of Safety Decision Boundary. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet P...
2025
-
[23]
John Regehr, Yang Chen, Pascal Cuoq, Eric Eide, Chucky Ellison, and Xuejun Yang. 2012. Test-Case Reduction for C Compiler Bugs. InProceedings of the 33rd ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI ’12). ACM, 335–346. doi:10.1145/2345156.2254104
-
[24]
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa...
-
[25]
Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics20 (1987), 53–65
1987
-
[26]
Shengyun Si, Xinpeng Wang, Guangyao Zhai, Nassir Navab, and Barbara Plank. 2025. Think Before Refusal : Triggering Safety Reflection in LLMs to Mitigate False Refusal Behavior.CoRRabs/2503.17882 (March 2025). https: //doi.org/10.48550/arXiv.2503.17882
-
[27]
Qwen Team. 2025. Qwen3Guard Technical Report.CoRRabs/2510.14276 (2025). arXiv:2510.14276 doi:10.48550/ARXIV. 2510.14276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[28]
Miriam Ugarte, Pablo Valle, José Antonio Parejo, Sergio Segura, and Aitor Arrieta. 2025. ASTRAL: A Tool for the Automated Safety Testing of Large Language Models. InProceedings of the 34th ACM SIGSOFT International Symposium on Software Testing and Analysis. 31–35
2025
-
[29]
Xinpeng Wang, Chengzhi Hu, Paul Röttger, and Barbara Plank. 2025. Surgical, Cheap, and Flexible: Mitigating False Refusal in Language Models via Single Vector Ablation. InThe Thirteenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=SCBn8MCLwc
2025
-
[30]
Xiaohan Yuan, Jinfeng Li, Dongxia Wang, Yuefeng Chen, Xiaofeng Mao, Longtao Huang, Jialuo Chen, Hui Xue, Xiaoxia Liu, Wenhai Wang, Kui Ren, and Jingyi Wang. 2025. S-Eval: Towards Automated and Comprehensive Safety Evaluation for Large Language Models.Proc. ACM Softw. Eng.2, ISSTA (2025), 2136–2157. doi:10.1145/3728971
-
[31]
Andreas Zeller. 1999. Yesterday, my Program Worked. Today, it Does Not. Why? InSoftware Engineering — ESEC/FSE ’99. Lecture Notes in Computer Science, Vol. 1687. Springer, 253–267. doi:10.1007/3-540-48166-4_16
-
[32]
Andreas Zeller and Ralf Hildebrandt. 2002. Simplifying and Isolating Failure-Inducing Input.IEEE Trans. Software Eng. 28, 2 (2002), 183–200. doi:10.1109/32.988498
-
[33]
Yi Zeng, Yu Yang, Andy Zhou, Jeffrey Ziwei Tan, Yuheng Tu, Yifan Mai, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, and Bo Li. 2025. AIR-BENCH 2024: A Safety Benchmark based on Regulation and Policies Specified Risk Categories. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum? id=UVnD9Ze6mF
2025
-
[34]
Haonan Zhang, Dongxia Wang, Yi Liu, Kexin Chen, Jiashui Wang, Xinlei Ying, Long Liu, and Wenhai Wang. 2025. ORFuzz: Fuzzing the "Other Side" of LLM Safety - Testing Over-Refusal. InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering, ASE 2025, Seoul, South Korea, November 16 - November 20, 2025. ACM. https://arxiv.o...
Pith/arXiv arXiv 2025
-
[35]
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. 2024. SafetyBench: Evaluating the Safety of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024. Ass...
-
[36]
Xuandong Zhao, Will Cai, Tianneng Shi, David Huang, Licong Lin, Song Mei, and Dawn Song. 2025. Improving LLM Safety Alignment with Dual-Objective Optimization. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=Kjivk5OPtL
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.