VidMsg: A Benchmark for Implicit Message Inference in Short Videos
Pith reviewed 2026-06-28 10:22 UTC · model grok-4.3
The pith
VidMsg benchmark shows current video models often fail to infer the unspoken messages in short clips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VidMsg establishes that implicit message inference in internet-native short videos requires pragmatic inference, integration of contextual cues, and fine discrimination among semantically close alternatives, capabilities that contemporary video-language and retrieval models largely lack.
What carries the argument
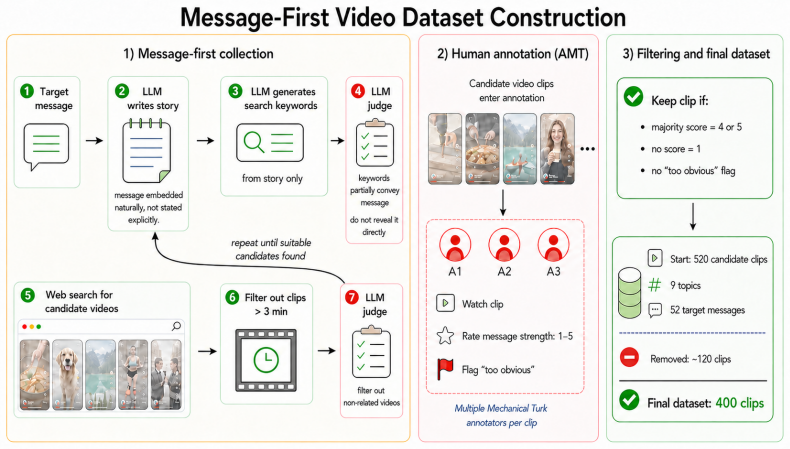
The message-first pipeline, which converts target messages into indirect LLM-generated search scenarios, retrieves candidate clips, and applies human filtering to retain only those conveying the message without explicit statement.
If this is right
- Bidirectional message-clip retrieval becomes feasible for applications such as video search and recommendation once models capture holistic intent.
- Diagnostic multiple-choice QA can pinpoint specific failures in contextual cue integration and semantic discrimination.
- VidVec-Msg demonstrates that targeted training can raise retrieval scores, yet substantial headroom remains for future methods.
Where Pith is reading between the lines
- Improved performance on VidMsg would likely translate to better handling of intent in real-world recommendation systems where creators embed advice or warnings without stating them outright.
- The same message-first curation approach could be adapted to create benchmarks for implicit communication in other short-form media such as social images or audio clips.
- Human agreement rates on the target messages would provide an upper bound that future models should be measured against.
Load-bearing premise
The LLM-generated search scenarios combined with human filtering produce clips that genuinely require implicit message inference without introducing artifacts from the curation process or selection bias.
What would settle it
If human viewers cannot reliably identify the intended message from the clips when shown the multiple-choice options, or if models achieve high accuracy by exploiting surface patterns rather than pragmatic reasoning.
Figures

read the original abstract
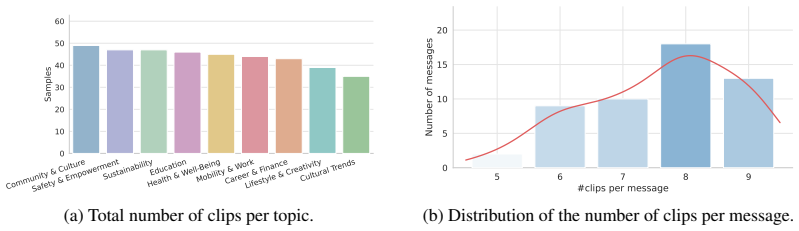
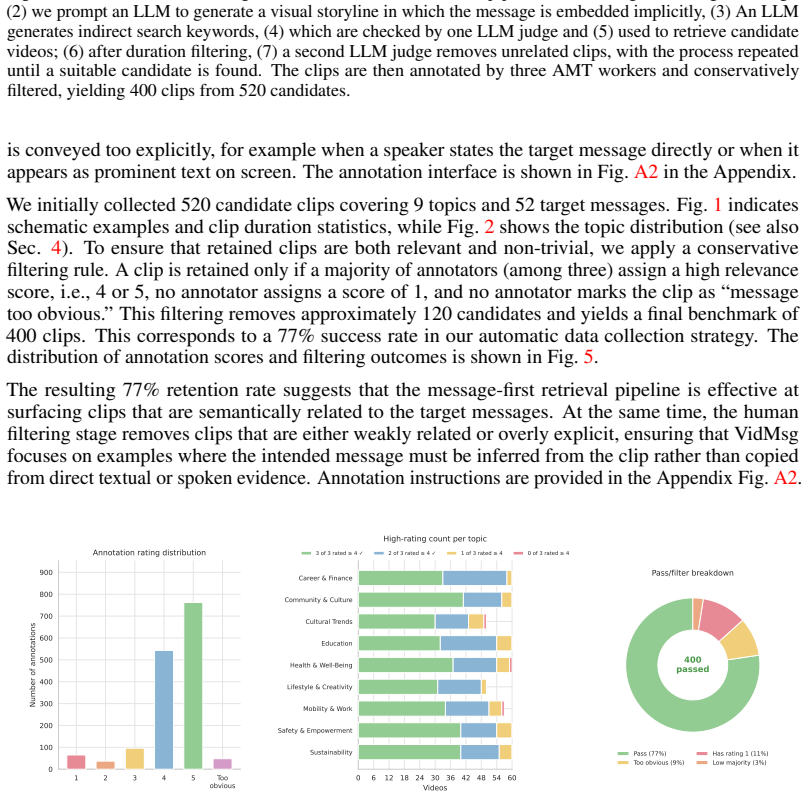
Understanding short online videos involves more than identifying visible objects and actions; video makers often include an underlying message or purpose in the clip. We introduce VidMsg, a benchmark for evaluating implicit message understanding in short, internet-native video clips. VidMsg contains 400 YouTube-derived clips across 9 practical topic areas and 52 fine-grained target messages, covering domains such as career and finance, education, health and well-being, culture, safety, sustainability, and lifestyle. VidMsg is constructed through a message-first pipeline: an LLM first translates target messages into indirect search scenarios, which are used to retrieve candidate clips. Human annotators then retain clips that convey the intended message without being overly explicit. VidMsg is designed primarily for bidirectional message-clip retrieval for scalable applications such as video search and recommendation, where systems must capture holistic video understanding. In addition to retrieval, VidMsg includes a diagnostic multiple-choice QA benchmark, where models select the intended message of a clip from semantically related alternatives. Experiments with contemporary video-language and retrieval models show that strong models often fail on VidMsg, because the task requires pragmatic inference, integration of contextual cues, and discrimination among semantically close messages. We also introduce VidVec-Msg, a baseline method that improves message-oriented retrieval while leaving substantial headroom for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
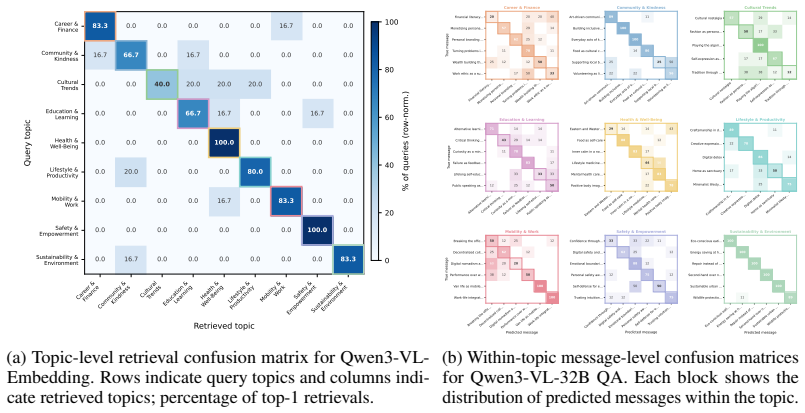
Summary. The paper introduces VidMsg, a benchmark of 400 YouTube-derived short video clips spanning 9 topic areas and 52 fine-grained messages, constructed via an LLM-driven message-first pipeline that generates indirect search scenarios for retrieval followed by human filtering to retain implicitly conveying clips. It supports bidirectional message-clip retrieval and a diagnostic multiple-choice QA task. Experiments with video-language and retrieval models indicate frequent failures attributed to requirements for pragmatic inference, contextual cue integration, and fine semantic discrimination; a baseline VidVec-Msg is proposed that improves retrieval performance while leaving headroom.
Significance. If the retained clips genuinely isolate pragmatic inference demands without curation artifacts, VidMsg could usefully expose limitations in current multimodal models for holistic video understanding and motivate better handling of implicit content in applications such as search and recommendation. The message-first construction approach and dual-task design are constructive contributions, though their impact depends on stronger validation of the dataset's properties.
major comments (3)
- [Dataset construction] Dataset construction section: the human filtering step for retaining non-overly-explicit clips reports no inter-annotator agreement, no comparison of retained vs. discarded clips on explicitness or surface features, and no controls for distributional overlap with pretraining data, leaving the central claim that failures reflect pragmatic inference unsupported.
- [Experiments] Experiments section: the claim that strong models fail due to pragmatic inference, contextual integration, and semantic discrimination is stated without reported quantitative metrics, error analysis, or ablation results, providing limited evidential support for the benchmark's diagnostic value.
- [VidVec-Msg] VidVec-Msg baseline: the method is presented as improving message-oriented retrieval, but without ablations or controls demonstrating that gains arise from better handling of implicit messages rather than generic retrieval improvements.
minor comments (2)
- [Abstract] Abstract: the nine topic areas are named but not enumerated, which would aid clarity.
- [Dataset construction] The manuscript would benefit from explicit discussion of potential selection biases in the LLM-generated scenarios and YouTube retrieval step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VidMsg. The comments identify areas where additional details can strengthen the manuscript, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the human filtering step for retaining non-overly-explicit clips reports no inter-annotator agreement, no comparison of retained vs. discarded clips on explicitness or surface features, and no controls for distributional overlap with pretraining data, leaving the central claim that failures reflect pragmatic inference unsupported.
Authors: We agree that inter-annotator agreement should have been reported and will add it (along with details on the annotation protocol) in the revision. We will also include a quantitative comparison of retained versus discarded clips on explicitness and surface features. Full controls for distributional overlap with pretraining data are inherently limited because pretraining corpora are not fully public; however, we will add a discussion of this issue and any feasible checks (e.g., n-gram overlap with common video-text corpora) to qualify the central claim. revision: partial
-
Referee: [Experiments] Experiments section: the claim that strong models fail due to pragmatic inference, contextual integration, and semantic discrimination is stated without reported quantitative metrics, error analysis, or ablation results, providing limited evidential support for the benchmark's diagnostic value.
Authors: Quantitative metrics are already reported for multiple models on both the retrieval and multiple-choice QA tasks, showing consistent underperformance. We acknowledge that a more granular error analysis (e.g., categorizing failure modes by inference type) would strengthen the diagnostic claims and will add this analysis in the revision. Targeted ablations on contextual cue integration are feasible and will be included where they directly support the stated failure modes. revision: partial
-
Referee: [VidVec-Msg] VidVec-Msg baseline: the method is presented as improving message-oriented retrieval, but without ablations or controls demonstrating that gains arise from better handling of implicit messages rather than generic retrieval improvements.
Authors: We will add ablations (e.g., comparing VidVec-Msg components against standard retrieval baselines on both VidMsg and a generic video-text retrieval benchmark) to isolate the contribution of its message-oriented design. This will clarify that observed gains are not solely generic improvements. revision: yes
Circularity Check
No circularity: benchmark construction and model evaluation paper
full rationale
The paper presents a data creation pipeline (LLM-generated search scenarios, YouTube retrieval, human filtering for implicit messages) and evaluates off-the-shelf video-language models on retrieval and QA tasks. No equations, fitted parameters, predictions, or derivations are claimed. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on external human annotations and standard model evaluations rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 8
Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
-
[3]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1728–1738, 2021. 3
2021
-
[4]
Perception encoder: The best visual embeddings are not at the output of the network.arXiv, 2025
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Daniel Li, Piotr Dollár, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of the network.arXiv, 2025. 7
2025
-
[5]
Collecting highly parallel data for paraphrase evaluation
David Chen and William Dolan. Collecting highly parallel data for paraphrase evaluation. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 190–200, 2011. 3
2011
-
[6]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611, 2026. 8
Pith/arXiv arXiv 2026
-
[7]
Activitynet: A large-scale video benchmark for human activity understanding
Bernard Ghanem Fabian Caba Heilbron, Victor Escorcia and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, 2015. 3
2015
-
[8]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 2, 4
2025
-
[9]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024. 7, 15
Pith/arXiv arXiv 2024
-
[10]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15180–15190, 2023. 7
2023
-
[11]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842– 58...
2017
-
[12]
Localizing moments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. InProceedings of the IEEE International Conference on Computer Vision, pages 5803–5812, 2017. 2
2017
-
[13]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering
Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. Tgif-qa: Toward spatio-temporal reasoning in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2758–2766, 2017. 3
2017
-
[14]
The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017. 2, 3 10
Pith/arXiv arXiv 2017
-
[15]
Fanqi Kong, Weiqin Zu, Xinyu Chen, Yaodong Yang, Song-Chun Zhu, and Xue Feng. Siv- bench: A video benchmark for social interaction understanding and reasoning.arXiv preprint arXiv:2506.05425, 2025. 4
Pith/arXiv arXiv 2025
-
[16]
Dense- captioning events in videos
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense- captioning events in videos. InProceedings of the IEEE International Conference on Computer Vision, pages 706–715, 2017. 3
2017
-
[17]
Hmdb: A large video database for human motion recognition
Hildegard Kuehne, Hueihan Jhuang, Estibaliz Garrote, Tomaso Poggio, and Thomas Serre. Hmdb: A large video database for human motion recognition. InProceedings of the IEEE International Conference on Computer Vision, pages 2556–2563, 2011. 3
2011
-
[18]
Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, and Steven C. H. Hoi. Align and prompt: Video-and-language pre-training with entity prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4943–4953, 2022. 3
2022
-
[19]
Intentqa: Context-aware video intent reasoning
Jiapeng Li, Ping Wei, Wenjuan Han, and Lifeng Fan. Intentqa: Context-aware video intent reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11963–11974, 2023. 2, 3
2023
-
[20]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024. 4
2024
-
[21]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026. 7
Pith/arXiv arXiv 2026
-
[22]
Yunxin Li, Xinyu Chen, Baotian Hu, Longyue Wang, Haoyuan Shi, and Min Zhang. Videovista: A versatile benchmark for video understanding and reasoning.arXiv preprint arXiv:2406.11303,
-
[23]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following. 8
2023
-
[24]
Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL, 2024
Yuanxin Liu et al. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL, 2024. 4
2024
-
[25]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4122–4134, 2025. 8
2025
-
[26]
Adsqa: Towards advertisement video understanding
Xinwei Long, Kai Tian, Peng Xu, Guoli Jia, Jingxuan Li, Sa Yang, Yihua Shao, Kaiyan Zhang, Che Jiang, Hao Xu, Yang Liu, Jiaheng Ma, and Bowen Zhou. Adsqa: Towards advertisement video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025. 2, 4
2025
-
[27]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neurocomputing, 508:293–304, 2022
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.Neurocomputing, 508:293–304, 2022. 3, 7
2022
-
[28]
X-clip: End-to- end multi-grained contrastive learning for video-text retrieval
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-clip: End-to- end multi-grained contrastive learning for video-text retrieval. InProceedings of the 30th ACM International Conference on Multimedia, pages 638–647, 2022. 3
2022
-
[29]
Egoschema: A diagnostic benchmark for very long-form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding. InNeurIPS, 2023. 2, 4 11
2023
-
[30]
Rui Meng, Ziyan Jiang, Ye Liu, Mingyi Su, Xinyi Yang, Yuepeng Fu, Can Qin, Zeyuan Chen, Ran Xu, Caiming Xiong, Yingbo Zhou, Wenhu Chen, and Semih Yavuz. Vlm2vec-v2: Advancing multimodal embedding for videos, images, and visual documents.arXiv preprint arXiv:2507.04590, 2025. 7
Pith/arXiv arXiv 2025
-
[31]
Perception test: A diagnostic benchmark for multimodal video models
Viorica P˘atr˘aucean, Lucas Smaira, Ankush Gupta, Adrià Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osindero, Dima Damen, Andrew Zisse...
2023
-
[32]
Ruchit Rawal, Khalid Saifullah, Ronen Basri, Gal Chechik, and David Jacobs. Cinepile: A long video question answering dataset and benchmark.arXiv preprint arXiv:2405.08813, 2024. 4
arXiv 2024
-
[33]
Movie description.International Journal of Computer Vision, 123(1):94–120, 2017
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. Movie description.International Journal of Computer Vision, 123(1):94–120, 2017. 3
2017
-
[34]
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 3
Pith/arXiv arXiv 2012
-
[35]
Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024. 17
Pith/arXiv arXiv 2024
-
[36]
Issar Tzachor, Dvir Samuel, and Rami Ben-Ari. Vidvec: Unlocking video mllm embeddings for video-text retrieval.arXiv preprint arXiv:2602.08099, 2026. 3, 6, 7, 14, 15, 17
arXiv 2026
-
[37]
Lvbench: An extreme long video understanding benchmark.arXiv preprint arXiv:2406.08035, 2024
Weihan Wang et al. Lvbench: An extreme long video understanding benchmark.arXiv preprint arXiv:2406.08035, 2024. 2, 4
Pith/arXiv arXiv 2024
-
[38]
Vatex: A large-scale, high-quality multilingual dataset for video-and-language research
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4581–4591, 2019. 3
2019
-
[39]
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Jilan Xu, Zun Wang, et al. Internvideo2: Scaling video foundation models for multimodal video understanding.arXiv preprint arXiv:2403.15377, 2024. 3, 7
arXiv 2024
-
[40]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 9777–9786. Computer Vision Foundation / IEEE, 2021. 2, 3
2021
-
[41]
Videoclip: Contrastive pre-training for zero- shot video-text understanding
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero- shot video-text understanding. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6787–6800, 2021. 3
2021
-
[42]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5288–5296, 2016. 2, 3
2016
-
[43]
Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe, 2025
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, Bokai Xu, Junbo Cui, Yingjing Xu, Liqing Ruan, Luoyuan Zhang, Hanyu Liu, Jingkun Tang, Hongyuan Liu, Qining Guo, Wenhao Hu, Bingxiang He, Jie Zhou, Jie Cai, Ji Qi, Zonghao Guo, Chi Chen, Guoyang Zeng, Yuxuan Li, Ganqu Cui, Ning D...
Pith/arXiv arXiv 2025
-
[44]
Activitynet-qa: A dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: A dataset for understanding complex web videos via question answering. InAAAI, pages 9127–9134. AAAI Press, 2019. 2, 3
2019
-
[45]
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multimodal foundation models for image and video understanding.arXiv preprint arXiv:2501.13106, 2025. 8
Pith/arXiv arXiv 2025
-
[46]
Videoprism: A foundational visual encoder for video understanding
Long Zhao, Nitesh Bharadwaj Gundavarapu, Liangzhe Yuan, Hao Zhou, Shen Yan, Jennifer J Sun, Luke Friedman, Rui Qian, Tobias Weyand, Yue Zhao, et al. Videoprism: A foundational visual encoder for video understanding. InForty-first International Conference on Machine Learning. 3, 7
-
[47]
Completely Unrelated
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 2, 4 13 Appendix This Appendix includes details on the followin...
2025
-
[48]
message" and
Output ONLY valid JSON with exactly two keys: "message" and "video_caption"
-
[49]
"message" should be the short 5-7 word arguable cultural message
-
[50]
video_caption
"video_caption" should be a dense description of the video visuals (no speech, no text overlays, no persona appearance)
-
[51]
{narrative}
Do not include any explanation, prefix, or extra text outside the JSON. Figure A4: Prompt used by VidVec-Msg to generate PersonaHub-based training data. 18 Financial literacy for young adults Monetizing personal passions Personal branding as career leverage T urning problems into business ideas Wealth building through consistency Work ethic as a success d...
-
[52]
Subtly includes the hidden narrative
-
[53]
Is suitable for short video content
-
[54]
office worker musician transition
Can be expanded into a full video later Keep it short and focused on the core concept only. Additional Context: {additional_context} (b) User prompt Figure A8: Prompts used for brief story generation. You are a video story editor. Your task is to refine an existing story based on specific feedback while maintaining the core narrative and video suitability...
-
[55]
Captures the core concept of the narrative
-
[56]
Would find videos that align with the narrative’s message
-
[57]
valid": true,
Is specific enough to be useful but not so narrow it misses the point Respond with ONLY a JSON object in this exact format: {"valid": true, "reasoning": "Brief explanation"} or {"valid": false, "reasoning": "Brief explanation of why it doesn’t represent the narrative"} Be reasonably lenient - the query doesn’t need to be perfect, just representative of th...
-
[58]
Title - How well does it align with the narrative?
-
[59]
Description - Does the content description support the narrative?
-
[60]
Uploader - Is the channel type relevant to the narrative?
-
[61]
Duration - Is the video length appropriate for the narrative content?
-
[62]
rankings
View count - Does popularity indicate relevance? You must provide a JSON response with the following structure: { "rankings": [ { "video_id": "video_id_here", "relevance_score": 8.5, "relevance_reasoning": "Detailed explanation of why this video is relevant to the narrative " } ] } Scoring criteria: - 9-10: Perfectly aligned with narrative, highly relevan...
-
[63]
Thematic alignment with the narrative
-
[64]
Content relevance based on available metadata
-
[65]
Appropriateness of the video format for the narrative
-
[66]
(b) User prompt Figure A12: Prompts used for video ranking
Potential storytelling value Provide your response as valid JSON only. (b) User prompt Figure A12: Prompts used for video ranking. 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.