Black-box, Adaptive, Efficient, Transferable, Harmful, Applicable... Attacks Are All You Need to Break LLMs
Pith reviewed 2026-06-28 09:19 UTC · model grok-4.3
The pith
Indirect Harm Optimization trains a black-box masked diffusion attacker via iterative preference optimization that transfers across behaviors and models while raising success rates against layered LLM defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
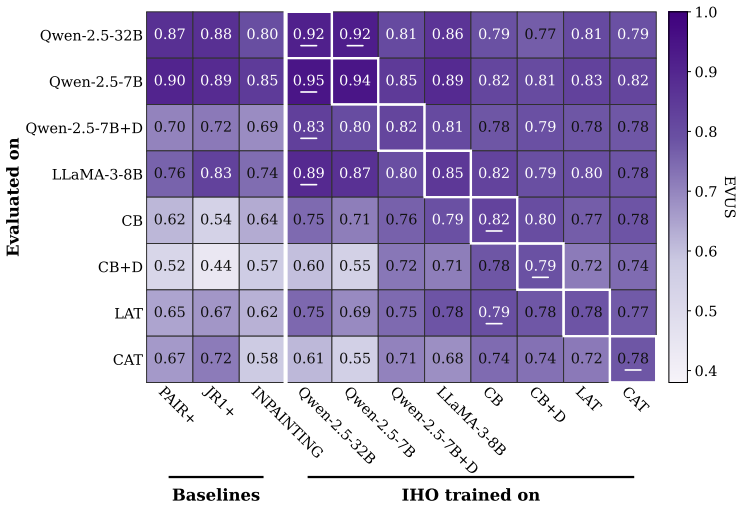
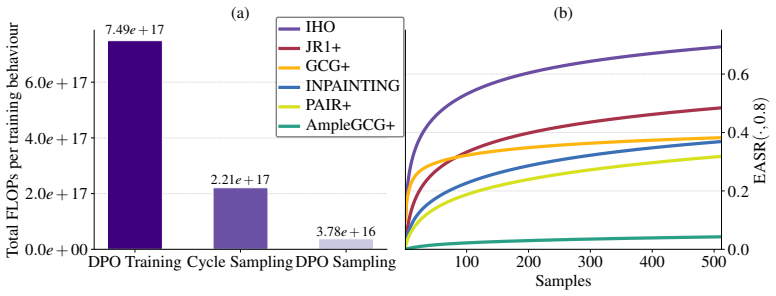
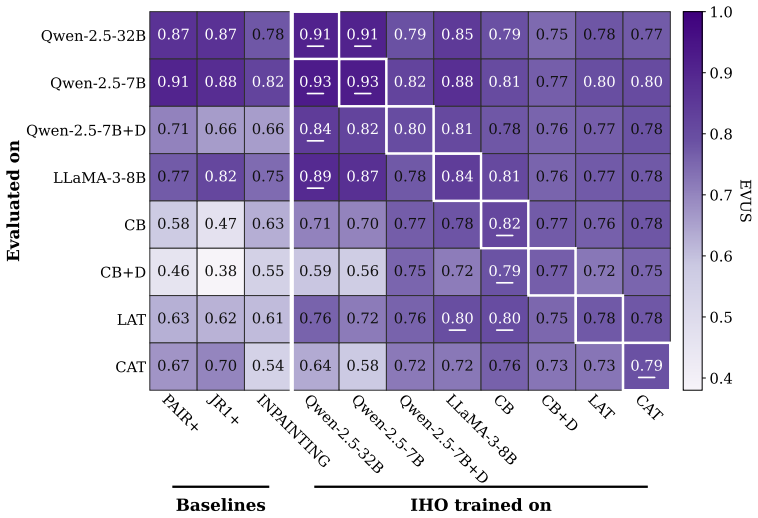
IHO is a masked diffusion language model attacker trained via iterative preference optimization against a harmfulness judge that requires only black-box access to the target; the same trained model serves without modification as a strong adaptive attack on individual behaviors or as an efficient amortized policy that transfers to held-out behaviors and unseen target models, and it raises attack success rates considerably over prior methods even on layered defenses such as a Circuit Breaker model plus an auxiliary detector.
What carries the argument
Indirect Harm Optimization (IHO): a masked diffusion language model trained with iterative preference optimization against a harmfulness judge to produce transferable jailbreak prompts from black-box access only.
If this is right
- The same IHO model works as an adaptive attack on specific behaviors or as an amortized policy transferring to new behaviors and models without fine-tuning.
- IHO raises attack success rates over prior methods on layered defenses without any defense-specific changes.
- IHO requires only black-box access, making it usable on closed models where gradient access is unavailable.
- Results position IHO as a candidate for standardized jailbreak evaluation baselines that would improve reliability of defense comparisons.
Where Pith is reading between the lines
- Defense papers may need to test against amortized attackers that generalize across targets rather than only per-defense tuned attacks.
- The diffusion-based generation in IHO might expose vulnerabilities in current safety training that token-level or gradient-based attacks miss.
- If IHO generalizes well, similar preference-optimization loops could be applied to create standardized attackers for other safety properties beyond jailbreaks.
- Widespread adoption of IHO-style evaluation could shift focus from per-defense tuning to building defenses robust to black-box transferable policies.
Load-bearing premise
The harmfulness judge used during iterative preference optimization correctly labels outputs as harmful without systematic biases or errors that would misguide training or invalidate measured success rates.
What would settle it
Replicating the experiments on the Circuit Breaker plus detector defense and finding that IHO attack success rates do not exceed those of the prior state-of-the-art methods would falsify the claim of consistent improvement without defense-specific adaptation.
Figures














read the original abstract
Accurately evaluating adversarial robustness is a longstanding challenge. A flawed attack design can inflate robustness estimates, making deployment risk assessment and defense comparison unreliable. Historically, standardized attacks such as AutoAttack have largely resolved this for image classifiers, providing a reliable evaluation baseline for systematic comparison across defenses. However, no equivalent exists for LLM jailbreak evaluation yet, where designing such an attack is considerably more difficult. A reliable attack must, among other things, be black-box compatible, applicable to arbitrary defense pipelines, and efficient, which no existing method jointly satisfies. We introduce Indirect Harm Optimization (IHO), a masked diffusion language model attacker trained via iterative preference optimization against a harmfulness judge, requiring only black-box access to the target. The same method can be used without modification as a strong adaptive attack on individual behaviors, or as an efficient amortized policy that transfers to held-out behaviors and unseen target models without fine-tuning. Even against layered defenses, such as a Circuit Breaker-trained model combined with an auxiliary detector, IHO improves attack success considerably over state-of-the-art approaches, without any defense-specific adaptation. Our results position IHO as a practical step toward the kind of standardized jailbreak evaluation that has improved reliability in the past. Code and models are available on GitHub and Hugging Face.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Indirect Harm Optimization (IHO), a masked diffusion language model attacker trained via iterative preference optimization against a harmfulness judge. It requires only black-box access to the target LLM and can be deployed either as an adaptive attack on individual behaviors or as an amortized policy that transfers to held-out behaviors and unseen models without fine-tuning. The central claim is that IHO considerably improves attack success rates over state-of-the-art methods even against layered defenses such as a Circuit Breaker-trained model plus an auxiliary detector, without any defense-specific adaptation, and positions IHO as a step toward standardized, reliable jailbreak evaluation akin to AutoAttack for image classifiers.
Significance. If the empirical claims hold under rigorous verification, IHO would address a genuine gap in LLM robustness evaluation by providing a black-box, efficient, and transferable attack that does not require defense-specific tuning. The public release of code and models on GitHub and Hugging Face strengthens reproducibility and enables independent verification, which is a positive contribution to the field.
major comments (2)
- [Abstract] Abstract: The reported gains in attack success against layered defenses (Circuit Breaker + detector) are measured using the same class of harmfulness judge employed during iterative preference optimization. This setup risks circularity: the attacker may be optimized to produce outputs that the judge misclassifies as harmful rather than genuinely harmful content, which would inflate both the optimization objective and the final success metrics without independent validation of judge accuracy.
- [Abstract] Abstract: No experimental details, metrics, baselines, controls, or ablation results are described to support the claims of considerable improvement, transferability to held-out behaviors, and applicability without defense-specific adaptation. Without these, it is impossible to assess whether the central empirical result is load-bearing or an artifact of the evaluation protocol.
minor comments (2)
- The title is unusually long and contains redundant adjectives; consider shortening for clarity while retaining the core contribution.
- [Abstract] The abstract references 'state-of-the-art approaches' without naming them; explicit citation of the compared methods would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported gains in attack success against layered defenses (Circuit Breaker + detector) are measured using the same class of harmfulness judge employed during iterative preference optimization. This setup risks circularity: the attacker may be optimized to produce outputs that the judge misclassifies as harmful rather than genuinely harmful content, which would inflate both the optimization objective and the final success metrics without independent validation of judge accuracy.
Authors: We acknowledge the validity of this concern regarding potential circularity. The use of the same judge class for both training and evaluation is a common practice in automated LLM safety evaluations but does carry the risk noted. In the revised version, we will add results using an independent judge model not involved in optimization, along with a human evaluation on a random subset of successful attacks, to provide external validation of the reported gains against layered defenses. revision: yes
-
Referee: [Abstract] Abstract: No experimental details, metrics, baselines, controls, or ablation results are described to support the claims of considerable improvement, transferability to held-out behaviors, and applicability without defense-specific adaptation. Without these, it is impossible to assess whether the central empirical result is load-bearing or an artifact of the evaluation protocol.
Authors: Abstracts are by design concise overviews and do not contain full experimental protocols. The manuscript provides these details in Section 4 (Experiments), including attack success rate metrics, comparisons to SOTA baselines such as GCG and PAIR, controls for transferability across held-out behaviors and models, and ablations on the iterative preference optimization procedure. To address the comment, we will revise the abstract to include one or two key quantitative results (e.g., relative ASR improvements) while respecting length limits, and ensure the experimental section explicitly cross-references the abstract claims. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes IHO, a masked diffusion attacker trained via iterative preference optimization against an external harmfulness judge, and reports empirical improvements in attack success (measured by the same judge) over SOTA on black-box, adaptive, and transferable settings including layered defenses. This does not match any enumerated circularity pattern: there are no self-definitional equations, no fitted parameters renamed as independent predictions, no load-bearing self-citations, and no imported uniqueness theorems or ansatzes. The judge is treated as an independent evaluation component rather than a quantity defined by the method itself, and the central claims rest on empirical comparisons rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, et al. Foundational challenges in assuring alignment and safety of large language models.arXiv preprint arXiv:2404.09932, 2024
arXiv 2024
-
[2]
Chen Chen, Xueluan Gong, Ziyao Liu, Weifeng Jiang, Si Qi Goh, and Kwok-Yan Lam. Trust- worthy, responsible, and safe ai: A comprehensive architectural framework for ai safety with challenges and mitigations.arXiv preprint arXiv:2408.12935, 2024
Pith/arXiv arXiv 2024
-
[3]
Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[4]
Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419, 2023
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419, 2023
Pith/arXiv arXiv 2023
-
[5]
Best-of-n jailbreaking.arXiv preprint arXiv:2412.03556, 2024
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking.arXiv preprint arXiv:2412.03556, 2024
arXiv 2024
-
[6]
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. InICML, 2018
2018
-
[7]
On Adaptive Attacks to Adversarial Example Defenses
Florian Tramer, Nicholas Carlini, Wieland Brendel, and Aleksander Madry. On Adaptive Attacks to Adversarial Example Defenses. InNeurIPS, 2020
2020
-
[8]
Investigating adversarial trigger transfer in large language models.Transactions of the Association for Computational Linguistics, 13:953–979, 2025
Nicholas Meade, Arkil Patel, and Siva Reddy. Investigating adversarial trigger transfer in large language models.Transactions of the Association for Computational Linguistics, 13:953–979, 2025
2025
-
[9]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming.arXiv preprint arXiv:2501.18837, 2025
Pith/arXiv arXiv 2025
-
[10]
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. Jailbreaking leading safety-aligned llms with simple adaptive attacks.arXiv preprint arXiv:2404.02151, 2024
arXiv 2024
-
[11]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, et al. The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections. arXiv preprint arXiv:2510.09023, 2025
Pith/arXiv arXiv 2025
-
[12]
Zeyi Liao and Huan Sun. Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms.arXiv preprint arXiv:2404.07921, 2024
arXiv 2024
-
[13]
Weiyang Guo, Zesheng Shi, Zhuo Li, Yequan Wang, Xuebo Liu, Wenya Wang, Fangming Liu, Min Zhang, and Jing Li. Jailbreak-r1: Exploring the jailbreak capabilities of llms via reinforcement learning.arXiv preprint arXiv:2506.00782, 2025
arXiv 2025
-
[14]
Leo Schwinn, Moritz Ladenburger, Tim Beyer, Mehrnaz Mofakhami, Gauthier Gidel, and Stephan Günnemann. A coin flip for safety: Llm judges fail to reliably measure adversarial robustness.arXiv preprint arXiv:2603.06594, 2026
arXiv 2026
-
[15]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InNeurIPS, 2023
2023
-
[16]
On evaluating adversarial robustness.arXiv preprint arXiv:1902.06705, 2019
Nicholas Carlini, Anish Athalye, Nicolas Papernot, Wieland Brendel, Jonas Rauber, Dimitris Tsipras, Ian Goodfellow, Aleksander Madry, and Alexey Kurakin. On evaluating adversarial robustness.arXiv preprint arXiv:1902.06705, 2019
Pith/arXiv arXiv 1902
-
[17]
Tim Beyer, Yan Scholten, Leo Schwinn, and Stephan Günnemann. Sampling-aware adversarial attacks against large language models.arXiv preprint arXiv:2507.04446, 2025
arXiv 2025
-
[18]
Simon Geisler, Tom Wollschläger, MHI Abdalla, Johannes Gasteiger, and Stephan Günne- mann. Attacking large language models with projected gradient descent.arXiv preprint arXiv:2402.09154, 2024. 10
arXiv 2024
-
[19]
Tree of attacks: Jailbreaking black-box llms automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically. In NeurIPS, 2024
2024
-
[20]
Diffusion llms are natural adversaries for any llm.arXiv preprint arXiv:2511.00203, 2025
David Lüdke, Tom Wollschläger, Paul Ungermann, Stephan Günnemann, and Leo Schwinn. Diffusion llms are natural adversaries for any llm.arXiv preprint arXiv:2511.00203, 2025
arXiv 2025
-
[21]
Simon Geisler, Tom Wollschläger, MHI Abdalla, Vincent Cohen-Addad, Johannes Gasteiger, and Stephan Günnemann. REINFORCE adversarial attacks on large language models: An adaptive, distributional, and semantic objective.arXiv preprint arXiv:2502.17254, 2025
arXiv 2025
-
[22]
Lora: Low-rank adaptation of large language models.ICLR, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 2022
2022
-
[23]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[24]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
Pith/arXiv arXiv 2025
-
[25]
Improving alignment and robustness with short circuiting.arXiv preprint arXiv:2406.04313, 2024
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving alignment and robustness with short circuiting.arXiv preprint arXiv:2406.04313, 2024
arXiv 2024
-
[26]
Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, et al. Latent adver- sarial training improves robustness to persistent harmful behaviors in llms.arXiv preprint arXiv:2407.15549, 2024
arXiv 2024
-
[27]
Efficient adversarial training in llms with continuous attacks
Sophie Xhonneux, Alessandro Sordoni, Stephan Günnemann, Gauthier Gidel, and Leo Schwinn. Efficient adversarial training in llms with continuous attacks. InNeurIPS, 2024
2024
-
[28]
Priyanshu Kumar, Devansh Jain, Akhila Yerukola, Liwei Jiang, Himanshu Beniwal, Thomas Hartvigsen, and Maarten Sap. Polyguard: A multilingual safety moderation tool for 17 lan- guages.arXiv preprint arXiv:2504.04377, 2025
arXiv 2025
-
[29]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. arXiv preprint arXiv:2404.01318, 2024
Pith/arXiv arXiv 2024
-
[30]
A strongreject for empty jailbreaks.arXiv preprint arXiv:2402.10260, 2024
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, et al. A strongreject for empty jailbreaks.arXiv preprint arXiv:2402.10260, 2024
Pith/arXiv arXiv 2024
-
[31]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
Pith/arXiv arXiv 2024
-
[32]
Large language diffusion models, 2025
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models, 2025. URL https: //arxiv.org/abs/2502.09992
Pith/arXiv arXiv 2025
-
[33]
Sicheng Zhu, Ruiyi Zhang, Bang An, Gang Wu, Joe Barrow, Zichao Wang, Furong Huang, Ani Nenkova, and Tong Sun. Autodan: Automatic and interpretable adversarial attacks on large language models.arXiv preprint arXiv:2310.15140, 2023
arXiv 2023
-
[34]
Advprompter: Fast adaptive adversarial prompting for llms.arXiv preprint arXiv:2404.16873, 2024
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, and Yuandong Tian. Advprompter: Fast adaptive adversarial prompting for llms.arXiv preprint arXiv:2404.16873, 2024. 11
arXiv 2024
-
[35]
Xiaogeng Liu, Peiran Li, Edward Suh, Yevgeniy V orobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms.arXiv preprint arXiv:2410.05295, 2024
arXiv 2024
-
[36]
Ipo: Your language model is secretly a preference classifier, 2025
Shivank Garg, Ayush Singh, Shweta Singh, and Paras Chopra. Ipo: Your language model is secretly a preference classifier, 2025. URLhttps://arxiv.org/abs/2502.16182
arXiv 2025
-
[37]
Kto: Model alignment as prospect theoretic optimization, 2024
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization, 2024. URL https://arxiv.org/abs/ 2402.01306
Pith/arXiv arXiv 2024
-
[38]
Simpo: Simple preference optimization with a reference-free reward, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward, 2024. URLhttps://arxiv.org/abs/2405.14734
arXiv 2024
-
[39]
Tim Beyer, Jonas Dornbusch, Jakob Steimle, Moritz Ladenburger, Leo Schwinn, and Stephan Günnemann. Adversariallm: A unified and modular toolbox for llm robustness research.arXiv preprint arXiv:2511.04316, 2025
arXiv 2025
-
[40]
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts.arXiv preprint arXiv:2309.10253, 2023
Pith/arXiv arXiv 2023
-
[41]
One model transfer to all: On robust jailbreak prompts generation against llms, 2025
Linbao Li, Yannan Liu, Daojing He, and Yu Li. One model transfer to all: On robust jailbreak prompts generation against llms, 2025. URLhttps://arxiv.org/abs/2505.17598
arXiv 2025
-
[42]
Rui Zheng, Hongyi Guo, Zhihan Liu, Xiaoying Zhang, Yuanshun Yao, Xiaojun Xu, Zhaoran Wang, Zhiheng Xi, Tao Gui, Qi Zhang, et al. Toward optimal llm alignments using two-player games.arXiv preprint arXiv:2406.10977, 2024. 12 Appendix Overview Appendix A: Algorithmic Description of IHO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.