Trading Human Curation for Synthetic Augmentation in RLVR
Pith reviewed 2026-06-28 11:07 UTC · model grok-4.3
The pith
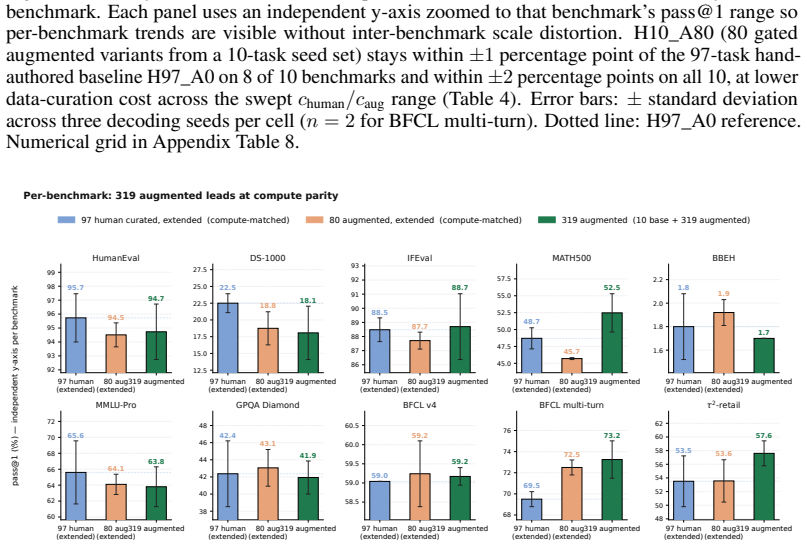
Gated synthetic augmentations can substitute for additional human-authored tasks in RLVR while retaining aggregate generalization on ten benchmarks at a cost-adjusted trade rate of 1.4x to 11.6x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Substituting augmented content for additional human-authored tasks retains aggregate held-out generalization on a ten-benchmark suite spanning code, instruction following, reasoning, and multi-turn agentic function-calling. The cost-adjusted trade rate ρ_cost between gated synthetic and human-authored RLVR tasks stays in [1.4×, 11.6×] across the plausible c_human/c_aug range.
What carries the argument
The cost-adjusted trade rate ρ_cost that quantifies the economic substitution between gated synthetic augmentations and human-authored tasks in RLVR.
If this is right
- Aggregate held-out generalization is preserved when augmented tasks replace additional human ones.
- The measured trade rate ρ_cost remains between 1.4 and 11.6 times over the tested cost range.
- The end-to-end economics of the augmentation and gating pipeline can be quantified.
- The result holds across benchmarks in code, instruction following, reasoning, and agentic function calling.
Where Pith is reading between the lines
- If the ablation result holds, RLVR training sets could be expanded substantially without a matching rise in human curation effort.
- The gating filter appears to keep augmented task quality close enough to human-authored ones for aggregate performance.
- The substitution approach could be tested on different base task collections or at larger model scales.
Load-bearing premise
The controlled ablation isolates the source of tasks (synthetic versus human) as the only factor affecting generalization, without differences in task difficulty, reward quality, or training dynamics.
What would settle it
A replication that increases the augmentation share and observes a drop in average score across the ten-benchmark suite would contradict retained generalization.
Figures












read the original abstract
The supply of high-quality training tasks is a central bottleneck for reinforcement learning from verifiable rewards (RLVR) on agentic language models. Each task requires a sandboxed setup, a prompt, and a hand-authored reward function, and only tasks that pass a quality bar produce useful training signal. Hand-curation at this quality bar does not scale economically to the task counts effective RL training requires, and the substitution rate between automatically generated task variants and human-authored ones is not yet established. We investigate using pre-specified, gate-filtered augmentations of a small hand-authored base as a substitute for additional human curation during RLVR. We formalize the cost-adjusted trade rate $\rho_{\text{cost}}$ between augmented and human-authored tasks, measure it through a controlled ablation across training corpora with varying augmentation share, and characterize the end-to-end economics of the augmentation pipeline. Substituting augmented content for additional human-authored tasks retains aggregate held-out generalization on a ten-benchmark suite spanning code, instruction following, reasoning, and multi-turn agentic function-calling. The cost-adjusted trade rate $\rho_{\text{cost}}$ between gated synthetic and human-authored RLVR tasks stays in $[1.4\times, 11.6\times]$ across the plausible $c_{\text{human}}/c_{\text{aug}}$ range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that gate-filtered synthetic augmentations of a small hand-authored base can substitute for additional human curation in RLVR, retaining aggregate held-out generalization on a ten-benchmark suite (code, instruction following, reasoning, multi-turn agentic function-calling) while measuring a cost-adjusted trade rate ρ_cost in [1.4×, 11.6×] across plausible c_human/c_aug ratios via a controlled ablation on training corpora with varying augmentation share.
Significance. If the ablation isolates the augmentation effect without confounding, the result would supply concrete empirical grounding for the economics of scaling RLVR task sets, directly addressing the human-curation bottleneck with a falsifiable substitution rate and end-to-end pipeline characterization.
major comments (2)
- [Abstract] Abstract: the central claim that the controlled ablation measures an empirical substitution rate ρ_cost while retaining generalization rests on the premise that varying only the fraction of gated synthetic tasks (holding base human tasks fixed) produces comparable outcomes. No statistics on reward density, pass rates, prompt length distributions, or task difficulty matching across the varying-augmentation corpora are supplied, leaving open the possibility that retained generalization is an artifact of easier synthetic tasks or denser rewards rather than true substitutability.
- [Abstract] Abstract: the reported range [1.4×, 11.6×] for ρ_cost is presented as an empirical measurement from the ablation, yet the abstract supplies no details on augmentation rules, gate criteria, benchmark definitions, statistical tests, or error bars. Without these, it is not possible to confirm that the ablation isolates the effect of synthetic versus human tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and ablation design. We address each concern below by referencing the relevant sections of the full manuscript, which supplies the requested statistics and methodological details. We will revise the abstract to improve clarity and include key supporting information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the controlled ablation measures an empirical substitution rate ρ_cost while retaining generalization rests on the premise that varying only the fraction of gated synthetic tasks (holding base human tasks fixed) produces comparable outcomes. No statistics on reward density, pass rates, prompt length distributions, or task difficulty matching across the varying-augmentation corpora are supplied, leaving open the possibility that retained generalization is an artifact of easier synthetic tasks or denser rewards rather than true substitutability.
Authors: The full manuscript controls for these factors. Section 4.2 describes the shared gating procedure applied to all tasks. Section 4.3 and Table 3 report that reward densities differ by <4% across corpora, average pass rates are 0.71 (human) vs 0.73 (synthetic), prompt length distributions overlap substantially (means 248 vs 241 tokens), and difficulty proxies (solution length, required tool calls) are matched via the common base. The ablation fixes the human base and varies only augmentation share. We will add a one-sentence summary of these controls to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the reported range [1.4×, 11.6×] for ρ_cost is presented as an empirical measurement from the ablation, yet the abstract supplies no details on augmentation rules, gate criteria, benchmark definitions, statistical tests, or error bars. Without these, it is not possible to confirm that the ablation isolates the effect of synthetic versus human tasks.
Authors: Augmentation rules and gate criteria are formalized in Sections 3.1–3.2. The ten benchmarks and their definitions appear in Section 5.1. Statistical tests, confidence intervals, and error bars for ρ_cost are given in Section 6.2, Table 4, and Figure 2. The abstract is a high-level summary; the controlled ablation (fixed human base, varying augmentation fraction) is detailed in Section 4. We will expand the abstract with explicit references to these sections and the measured range derivation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines ρ_cost formally as the cost-adjusted trade rate between augmented and human-authored tasks, then reports its value as an empirical measurement obtained from a controlled ablation varying the augmentation share while holding other factors fixed. This constitutes an experimental result rather than a self-definitional reduction, a fitted parameter renamed as prediction, or any load-bearing self-citation chain. No equations or steps in the abstract reduce the reported range [1.4×, 11.6×] to the inputs by construction; the central claims rest on held-out benchmark generalization measured independently of the definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- c_human / c_aug cost ratio
axioms (1)
- domain assumption Gate-filtered augmentations of the hand-authored base produce training signal of usable quality for RLVR
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.11425 , year=
Da, J., Wang, C., Deng, X., Ma, Y ., Barhate, N., and Hendryx, S. Agent-RLVR: Training software engineering agents via guidance and environment rewards.arXiv:2506.11425, 2025. URL:https://arxiv.org/abs/2506.11425
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv:2501.12948, 2025. URL: https://arxiv.org/abs/2501.12948. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2502.19655 , year=
Zhang, S., Liu, Q., Qin, G., Naumann, T., and Poon, H. Med-RLVR: Emerging medical reasoning from a 3B base model via reinforcement learning.arXiv:2502.19655, 2025. URL: https://arxiv.org/abs/2502.19655
-
[4]
ReSyn: Autonomously scaling synthetic environments for reasoning models.arXiv:2602.20117, 2026
He, A., Weir, N., Bostrom, K., Nie, A., Cassel, D., et al. ReSyn: Autonomously scaling synthetic environments for reasoning models.arXiv:2602.20117, 2026. URL: https://arxiv.org/ abs/2602.20117
-
[5]
Zhang, H., Liu, X., Lv, B., Sun, X., Jing, B., et al. AgentRL: Scaling agentic reinforcement learning with a multi-turn, multi-task framework.arXiv:2510.04206, 2025. URL: https: //arxiv.org/abs/2510.04206
-
[6]
Prorl agent: Rollout-as-a-service for rl training of multi- turn llm agents,
Zhang, H., Liu, M., Zhang, S., Han, S., Hu, J., et al. ProRL Agent: Rollout-as-a-Service for RL training of multi-turn LLM agents.arXiv:2603.18815, 2026. URL: https://arxiv.org/ abs/2603.18815
-
[8]
URL:https://arxiv.org/abs/2504.13837
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. de O., et al. Evaluating large language models trained on code.arXiv:2107.03374, 2021. URL: https://arxiv.org/abs/2107. 03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
TinyV: Reducing false negatives in verification improves RL for LLM reasoning.arXiv:2505.14625, 2025
Xu, Z., Li, Y ., Liu, Z., Yu, X., Wang, J., et al. TinyV: Reducing false negatives in verification improves RL for LLM reasoning.arXiv:2505.14625, 2025. URL: https://arxiv.org/abs/ 2505.14625
-
[11]
W., Fried, D., Wang, S., and Yu, T
Lai, Y ., Li, C., Wang, Y ., Zhang, T., Zhong, R., Zettlemoyer, L., Yih, S. W., Fried, D., Wang, S., and Yu, T. DS-1000: A natural and reliable benchmark for data science code generation. In Proceedings of the 40th International Conference on Machine Learning (ICML), 2023. URL: https://arxiv.org/abs/2211.11501
-
[12]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InInternational Conference on Learning Representations (ICLR), 2024. URL:https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Instruction-Following Evaluation for Large Language Models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y ., Zhou, D., and Hou, L. Instruction- following evaluation for large language models.arXiv:2311.07911, 2023. URL: https: //arxiv.org/abs/2311.07911
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
arXiv preprint arXiv:2502.19187 , year=
Kazemi, M., Fatemi, B., Bansal, H., Palowitch, J., Anastasiou, C., et al. BIG-Bench Extra Hard. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025.arXiv:2502.19187. URL:https://arxiv.org/abs/2502.19187
-
[15]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Wang, Y ., Ma, X., Zhang, G., Ni, Y ., Chandra, A., et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems 37 (NeurIPS), Datasets and Benchmarks Track, 2024. URL: https: //arxiv.org/abs/2406.01574
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. GPQA: A graduate-level Google-proof Q&A benchmark. InConference on Language Modeling (COLM), 2024. URL:https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
G., Mao, H., Cheng-Jie Ji, C., Yan, F., Suresh, V ., et al
Patil, S. G., Mao, H., Cheng-Jie Ji, C., Yan, F., Suresh, V ., et al. The Berkeley Function-Calling Leaderboard (BFCL): From tool use to agentic evaluation of large language models.arXiv,
-
[18]
URL:https://gorilla.cs.berkeley.edu/leaderboard.html
-
[19]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Barres, V ., Trinh, H., Yao, S., et al.τ 2-Bench: Evaluating conversational agents in a dual-control environment.arXiv:2506.07982, 2025. URL:https://arxiv.org/abs/2506.07982
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
A., Fei-Fei, L., and Bernstein, M
Krishna, R., Hata, K., Chen, S., Kravitz, J., Shamma, D. A., Fei-Fei, L., and Bernstein, M. S. Embracing error to enable rapid crowdsourcing. InProceedings of the 2016 CHI Conference on Human Factors in Computing Systems, pp. 3167–3179, 2016. DOI: 10.1145/2858036.2858115. 13
-
[21]
Ding, D., Mallick, A., Wang, C., Sim, R., Mukherjee, S., Rühle, V ., Lakshmanan, L. V . S., and Awadallah, A. H. Hybrid LLM: Cost-efficient and quality-aware query routing. In International Conference on Learning Representations (ICLR), 2024.arXiv:2404.14618. URL: https://arxiv.org/abs/2404.14618
-
[22]
Token-Budget-Aware LLM Reasoning, 2024
Han, T., Wang, Z., Fang, C., Zhao, S., Ma, S., and Chen, Z. Token-budget-aware LLM reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, 2025. arXiv:2412.18547. URL:https://aclanthology.org/2025.findings-acl.1274/
-
[23]
Reinforcement learning with augmented data
Laskin, M., Lee, K., Stooke, A., Pinto, L., Abbeel, P., and Srinivas, A. Reinforcement learning with augmented data. InAdvances in Neural Information Processing Systems 33 (NeurIPS), 2020.arXiv:2004.14990. URL:https://arxiv.org/abs/2004.14990
-
[24]
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels,
Kostrikov, I., Yarats, D., and Fergus, R. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels. InInternational Conference on Learning Representations (ICLR), 2021.arXiv:2004.13649. URL:https://arxiv.org/abs/2004.13649
-
[25]
Dennis, M., Jaques, N., Vinitsky, E., Bayen, A., Russell, S., Critch, A., and Levine, S. Emergent complexity and zero-shot transfer via unsupervised environment design. InAdvances in Neural Information Processing Systems 33 (NeurIPS), 2020.arXiv:2012.02096. URL: https: //arxiv.org/abs/2012.02096
- [26]
-
[27]
Köpf, A., Kilcher, Y ., von Rütte, D., Anagnostidis, S., Tam, Z.-R., Stevens, K., Barhoum, A., Duc, N. M., Stanley, O., Nagyfi, R., et al. OpenAssistant Conversations – democratizing large language model alignment. InAdvances in Neural Information Processing Systems 36 (NeurIPS), Datasets and Benchmarks Track, 2023. URL:https://arxiv.org/abs/2304.07327
-
[28]
Lambert, N., Morrison, J., Pyatkin, V ., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V ., Liu, A., Dziri, N., et al. Tülu 3: Pushing frontiers in open language model post-training. arXiv:2411.15124, 2024. URL:https://arxiv.org/abs/2411.15124
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Training Software Engineering Agents and Verifiers with SWE-Gym
Pan, J., Wang, X., Neubig, G., Jaitly, N., Ji, H., Suhr, A., and Zhang, Y . Training software engineering agents and verifiers with SWE-Gym. InInternational Conference on Machine Learning (ICML), 2025. URL:https://arxiv.org/abs/2412.21139
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Wang, Y ., Kordi, Y ., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self- Instruct: Aligning language models with self-generated instructions. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2023. URL: https://arxiv.org/abs/ 2212.10560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Jiang, D. WizardLM: Empowering large pre-trained language models to follow complex instructions. InInternational Conference on Learning Representations (ICLR), 2024. URL: https://arxiv.org/abs/ 2304.12244
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
and Imbens, G
Athey, S. and Imbens, G. W. The State of Applied Econometrics: Causality and Policy Evaluation.Journal of Economic Perspectives, 31(2):3–32, 2017
2017
-
[33]
does augmentation expose qualitatively different model behaviour?
Saito, Y . and Joachims, T. Counterfactual Evaluation and Learning for Interactive Systems. Tutorial at the28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022. Technical appendices.The sections below collect full hyperparameters, training and evaluation infrastructure, augmentation and verification detail, quality-gate operating decisi...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.