FLARE: Fine-Grained Diagnostic Feedback for LLM Code Refinement
Pith reviewed 2026-06-28 08:45 UTC · model grok-4.3
The pith
A lightweight diagnostic model supplies line-level suspiciousness signals that improve LLM code refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
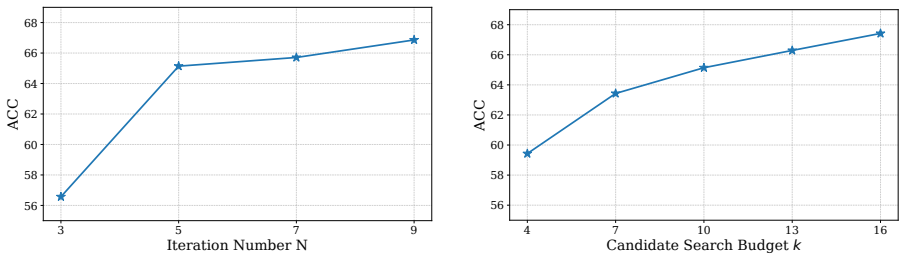
Flare is an iterative framework with a lightweight diagnostic model that predicts line-level suspiciousness signals for bug localization and code refinement. Given the inherent uncertainty of diagnostic predictions, Flare searches over the top-k suspicious regions and selects the best candidate according to execution outcomes. Experiments on LiveCodeBench and BigCodeBench with five base LLMs show that even without candidate search the approach outperforms the strongest baseline, and searching over ten candidates yields further average gains.
What carries the argument
Lightweight diagnostic model that predicts line-level suspiciousness signals, combined with top-k search and execution-based candidate selection.
If this is right
- Even single-candidate refinement using the top suspicious line raises success rates over baselines that rely only on tests or critiques.
- Expanding the search to ten candidates produces an additional average lift in performance.
- The diagnostic model itself outperforms recent fault localization techniques when evaluated in isolation.
- The gains appear consistently across five different base LLMs and two separate code benchmarks.
Where Pith is reading between the lines
- The same line-level signals could be surfaced directly in developer tools to highlight likely bug locations without any refinement loop.
- Combining the diagnostic model with other feedback sources might further reduce reliance on large test suites.
- The approach could be tested on non-code generation tasks where fine-grained localization of errors is useful.
Load-bearing premise
The line-level suspiciousness signals produced by the diagnostic model are accurate enough to improve refinement outcomes beyond what execution feedback alone can achieve.
What would settle it
If replacing the diagnostic model's line predictions with random line selections produces no drop in refinement success rates across the same benchmarks and models, the contribution of the fine-grained signals would be refuted.
Figures

read the original abstract
Large language models often generate code with bugs. Existing methods rely on feedback signals such as test failures and self-critiques to iteratively refine the generated code. Such signals are either too coarse-grained or too high-level, which is not sufficient to inform the model where to fix the bug. In this work, we present Flare, an iterative framework with a lightweight diagnostic model that predicts line-level suspiciousness signals for bug localization and code refinement. Given the inherent uncertainty of diagnostic predictions, Flare searches over the top-k suspicious regions and selects the best candidate according to execution outcomes. Experiments on LiveCodeBench and BigCodeBench with five base LLMs show that, even without candidate search (k=1), Flare outperforms the strongest baseline with an absolute improvement from 1.72% to 7.42%. Furthermore, searching over 10 candidates yields an average improvement of 8.50% compared with no candidate search. When evaluated in isolation, our lightweight diagnostic model achieves the best performance compared with recent fault localization methods, demonstrating that it can provide reliable fine-grained guidance for code refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLARE, an iterative refinement framework for LLM-generated code that employs a lightweight diagnostic model to output line-level suspiciousness scores for bug localization. These signals guide selection of top-k candidate regions, which are then filtered by execution outcomes. Experiments on LiveCodeBench and BigCodeBench across five base LLMs report that FLARE at k=1 already improves over the strongest baseline (1.72% to 7.42% absolute) and that increasing to k=10 yields a further average 8.50% gain; the diagnostic model itself also outperforms prior fault-localization methods when evaluated in isolation.
Significance. If the attribution of gains to the diagnostic signals can be isolated, the work would demonstrate a practical way to supply fine-grained, execution-augmented feedback that is more actionable than test failures or self-critiques alone, with potential impact on automated program repair pipelines.
major comments (2)
- [Experiments (Section 4) and abstract] The central claim that the 1.72%→7.42% lift at k=1 (and the additional 8.50% from search) is produced by the diagnostic model's line-level suspiciousness signals is not supported by any ablation that holds the refinement loop, prompt format, and execution-based candidate selection fixed while replacing the diagnostic predictions with uniform random line selections. Without this control, the observed gains cannot be confidently attributed to the diagnostic component rather than other unablated differences in the iterative procedure.
- [Abstract and Section 4] The reported performance numbers in the abstract and experimental section supply no information on experimental controls, statistical significance testing, exact baseline re-implementations, random seeds, or train/test splits, preventing assessment of whether the data support the stated improvements.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below and plan to revise the paper to strengthen the experimental validation and provide additional details for reproducibility.
read point-by-point responses
-
Referee: [Experiments (Section 4) and abstract] The central claim that the 1.72%→7.42% lift at k=1 (and the additional 8.50% from search) is produced by the diagnostic model's line-level suspiciousness signals is not supported by any ablation that holds the refinement loop, prompt format, and execution-based candidate selection fixed while replacing the diagnostic predictions with uniform random line selections. Without this control, the observed gains cannot be confidently attributed to the diagnostic component rather than other unablated differences in the iterative procedure.
Authors: We acknowledge that a direct ablation comparing the diagnostic model against uniform random line selections, while keeping the refinement loop, prompt format, and execution-based selection fixed, would provide stronger evidence isolating the contribution of the diagnostic signals. Our current evaluation demonstrates that FLARE outperforms baselines using coarser feedback signals, and the diagnostic model outperforms prior fault localization methods in isolation. However, to address this concern, we will include the suggested random baseline ablation in the revised manuscript. revision: yes
-
Referee: [Abstract and Section 4] The reported performance numbers in the abstract and experimental section supply no information on experimental controls, statistical significance testing, exact baseline re-implementations, random seeds, or train/test splits, preventing assessment of whether the data support the stated improvements.
Authors: We agree that the manuscript would benefit from more comprehensive reporting of experimental details, including controls, statistical significance tests, exact baseline implementations, random seeds used, and train/test splits. We will expand the experimental section and abstract (where space permits) to include these details in the revised version to improve reproducibility and allow better assessment of the results. revision: yes
Circularity Check
No circularity: empirical framework with external benchmarks
full rationale
The paper reports an iterative refinement framework whose central claims are performance deltas measured on LiveCodeBench and BigCodeBench against external baselines and prior fault-localization methods. No equations, first-principles derivations, or fitted parameters are invoked; the diagnostic model is trained and evaluated separately, then plugged into the loop. The k=1 and k=10 gains are presented as experimental outcomes, not as quantities that reduce by construction to the model's own outputs or to self-citations. The cited fault-localization results are independent benchmarks, not load-bearing self-references. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In2006 12th Pacific Rim International Symposium on Dependable Computing (PRDC’06), pages 39–46
An evaluation of similarity coefficients for software fault localization. In2006 12th Pacific Rim International Symposium on Dependable Computing (PRDC’06), pages 39–46. IEEE. Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt...
Pith/arXiv arXiv 2023
-
[2]
InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, pages 169–180
Deepfl: Integrating multiple fault diagnosis di- mensions for deep fault localization. InProceedings of the 28th ACM SIGSOFT international symposium on software testing and analysis, pages 169–180. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, B...
2023
-
[3]
Yihao Qin, Shangwen Wang, Yiling Lou, Jinhao Dong, Kaixin Wang, Xiaoling Li, and Xiaoguang Mao
Agentfl: Scaling llm-based fault localization to project-level context. Yihao Qin, Shangwen Wang, Yiling Lou, Jinhao Dong, Kaixin Wang, Xiaoling Li, and Xiaoguang Mao
-
[4]
Jeongju Sohn and Shin Yoo
Soapfl: A standard operating procedure for llm-based method-level fault localization.IEEE Transactions on Software Engineering, 51(4):1173– 1187. Jeongju Sohn and Shin Yoo. 2017. Fluccs: Using code and change metrics to improve fault localization. In Proceedings of the 26th ACM SIGSOFT international symposium on software testing and analysis, pages 273–28...
2017
-
[5]
Adam Stein, Arthur Wayne, Aaditya Naik, Mayur Naik, and Eric Wong
IEEE. Adam Stein, Arthur Wayne, Aaditya Naik, Mayur Naik, and Eric Wong. 2025. Where’s the bug? attention probing for scalable fault localization.arXiv preprint arXiv:2502.13966. Qwen Team. 2024. Qwen2.5: A party of foundation models. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukh...
arXiv 2025
-
[6]
Kechi Zhang, Zhuo Li, Jia Li, Ge Li, and Zhi Jin
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Kechi Zhang, Zhuo Li, Jia Li, Ge Li, and Zhi Jin
-
[7]
InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 769–787, Toronto, Canada
Self-edit: Fault-aware code editor for code generation. InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 769–787, Toronto, Canada. Association for Computational Linguistics. Weiming Zhang, Qingyao Li, Xinyi Dai, Jizheng Chen, Kounianhua Du, Weiwen Liu, Yasheng Wang, Ruim- ing Tang, ...
2025
-
[8]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 12834–12859
Opencodeinterpreter: Integrating code gener- ation with execution and refinement. InFindings of the Association for Computational Linguistics: ACL 2024, pages 12834–12859. Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, and 1 others. 2024. Deepseek- coder-v2: Breaking the barrier of closed-sou...
Pith/arXiv arXiv 2024
-
[9]
Analyze the code carefully
-
[10]
Identify the lines that most likely contain hallucinations
-
[11]
Rank them from most suspicious to least suspicious
-
[12]
Return 10 line numbers, ordered by suspicion level (most suspicious first) Your response should be in the following format (one line number per line, most suspicious first):
-
[13]
Line <number>: <brief reason>
-
[14]
__main__
Line <number>: <brief reason> ... Table 6: Direct Prompting LLM for fault localization. C Prompt Templates This section lists the prompt templates used for initial generation, refinement, ablations, and top- k candidate search. Templates use placeholders for task text, failed code, execution feedback, and diagnostic feedback. C.1 Initial Code Generation P...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.