Multi-Granularity 3D Kidney Lesion Characterization from CT Volumes
Pith reviewed 2026-06-28 07:04 UTC · model grok-4.3
The pith
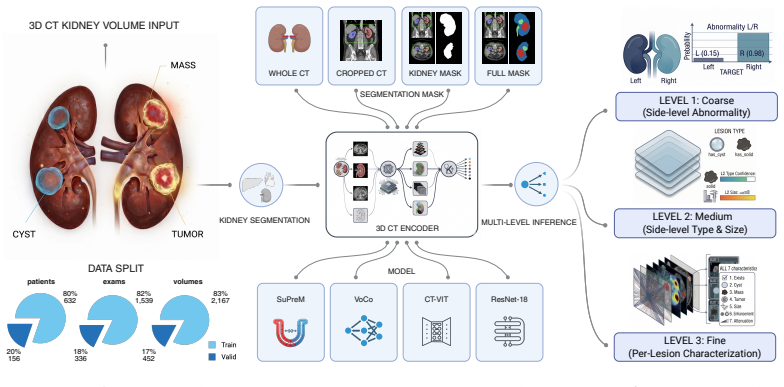
LesionDETR reformulates kidney CT analysis as per-lesion set prediction, outputting variable numbers of lesions each with clinical attributes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
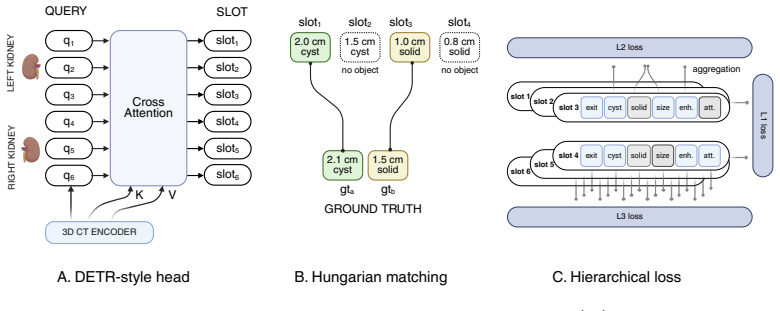
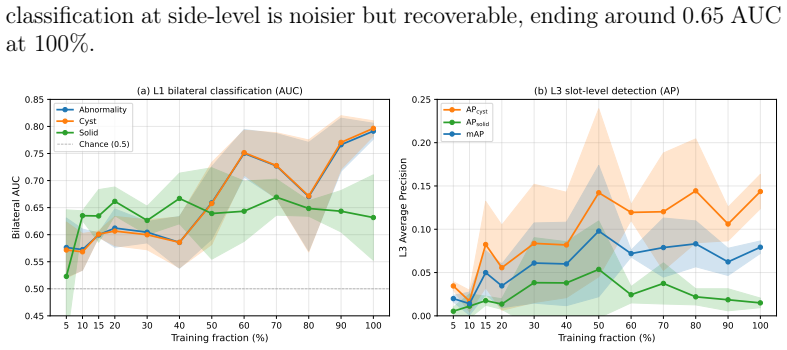
LesionDETR is a DETR-style architecture that applies size-distance Hungarian matching and a hierarchical loss aggregating per-slot outputs to side-level objectives. Across four input representations and six encoder initializations, segmentation mask input and same-domain abdominal pretraining (SuPreM) dominate, while generic large-corpus pretraining performs no better than random initialization. The model attains bilateral side-level abnormality AUC 0.799 ± 0.009 on UF-Health and 0.817 ± 0.072 on KiTS23; a count-conditioned variant reaches per-lesion mAP 0.190 ± 0.083 on cystic lesions, though rare solid-lesion AP remains at the noise floor. The framework produces verified per-lesion predict
What carries the argument
LesionDETR, a DETR-style set-prediction model using size-distance Hungarian matching for variable lesion counts and a hierarchical loss that aggregates per-slot outputs to side-level objectives.
If this is right
- Per-lesion outputs directly support generation of structured radiology reports from CT volumes.
- Segmentation mask as an input channel measurably improves side-level abnormality detection.
- Same-domain abdominal pretraining outperforms both random initialization and generic large-corpus pretraining.
- Data volume and diversity, rather than architecture changes, are the next bottleneck for rare solid lesions.
- The model generalizes to an external dataset in zero-shot side-level abnormality detection.
Where Pith is reading between the lines
- The same per-lesion set-prediction approach could transfer to lesions in other organs once comparable multi-granularity labels become available.
- Emphasis on domain-specific pretraining implies that medical imaging benefits more from targeted pretraining corpora than from further scaling of general image models.
- Low performance on solid lesions points to targeted collection of additional examples for those classes as the highest-impact follow-up.
- The hierarchical loss that bridges instance and aggregate objectives may apply to other medical set-prediction tasks requiring both levels of granularity.
Load-bearing premise
The multi-granularity side- and per-lesion labels curated from a single academic medical center are sufficiently accurate and consistent to support both internal evaluation and zero-shot external validation.
What would settle it
If removing the segmentation mask input channel or replacing same-domain pretraining with random initialization drops side-level AUC below 0.75 on the UF-Health dataset, the claimed dominance of those two design choices would not hold.
Figures
read the original abstract
Radiology reports describe kidney lesions by type, size, enhancement, and attenuation, yet existing 3D methods predict only at the patient or organ level. We reformulate kidney CT characterization as a per-lesion set-prediction task: one model emits a variable number of lesions per kidney, each with four clinical attributes. We curated 2,619 CT volumes from 788 patients at one academic medical center, with multi-granularity side- and per-lesion labels, and used KiTS23 (489 cases) for zero-shot external validation. We propose \textbf{LesionDETR}, a DETR-style architecture with size-distance Hungarian matching and a hierarchical loss that aggregates per-slot outputs to side-level objectives. Across four input representations and six encoder initializations, two design choices dominate: a segmentation mask as an input channel, and same-domain abdominal pretraining (SuPreM); generic large-corpus pretraining is no better than random initialization. LesionDETR reaches bilateral side-level abnormality AUC $0.799 \pm 0.009$ on UF-Health and $0.817 \pm 0.072$ on KiTS23. A count-conditioned variant reaches per-lesion mAP $0.190 \pm 0.083$ on cystic lesions; rare solid-lesion AP stays at the noise floor, pointing to targeted data collection, not architecture, as the next bottleneck. The framework yields verified per-lesion predictions for downstream structured report generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reformulates kidney lesion characterization from CT as a per-lesion set-prediction task using a DETR-style architecture (LesionDETR) with size-distance Hungarian matching and hierarchical loss. It curates 2,619 volumes from 788 patients at one center (UF-Health) with multi-granularity side- and per-lesion labels for four clinical attributes, employs KiTS23 for zero-shot external validation, and reports that a segmentation mask input channel plus same-domain abdominal pretraining (SuPreM) dominate across four input representations and six encoder initializations. Side-level abnormality AUC reaches 0.799 ± 0.009 (UF-Health) and 0.817 ± 0.072 (KiTS23); a count-conditioned variant yields per-lesion mAP 0.190 ± 0.083 on cystic lesions while solid-lesion AP remains near noise floor.
Significance. If the label quality supports the comparisons, the work usefully isolates two practical design choices (mask channel, domain pretraining) over generic pretraining and correctly flags data collection rather than architecture as the next bottleneck for rare solid lesions. The held-out internal/external splits and reporting of standard deviations are strengths; the framework's potential for structured reporting is a clear downstream motivation.
major comments (2)
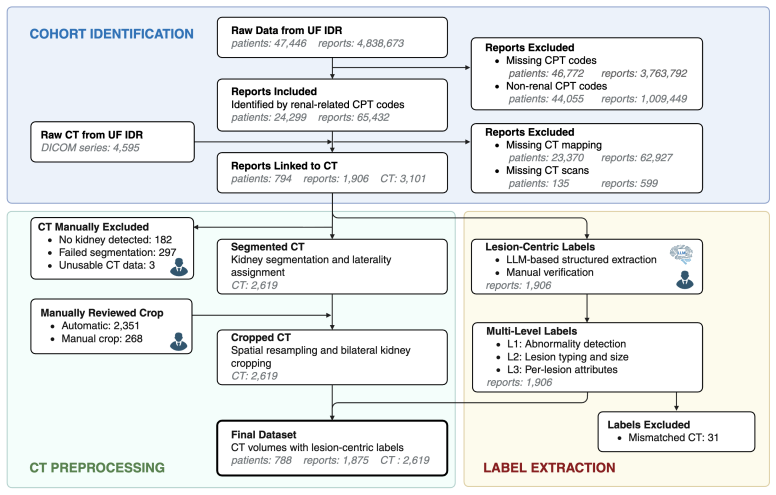
- [Dataset curation paragraph] Dataset curation paragraph: the multi-granularity side- and per-lesion labels (type, size, enhancement, attenuation) are the foundation for all ablation results and the KiTS23 zero-shot transfer, yet no inter-rater statistics, pathology correlation, explicit extraction protocol from reports, or verification procedure are described. Without these, observed gaps between mask+SuPreM and other configurations cannot be attributed to the model choices rather than label noise or center-specific annotation patterns.
- [Abstract and results sections] Abstract and results sections: the reported AUCs and mAP values include standard deviations but provide no information on the number of runs, data-split stratification, or statistical testing for the claimed dominance of the two design choices; this weakens the strength of the cross-representation and cross-initialization conclusions.
minor comments (2)
- [Abstract] The phrase 'verified per-lesion predictions' in the abstract is not supported by any explicit verification step described in the text.
- [Method] Notation for the hierarchical loss and size-distance matching cost could be clarified with an explicit equation reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in dataset curation and experimental reporting. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Dataset curation paragraph] Dataset curation paragraph: the multi-granularity side- and per-lesion labels (type, size, enhancement, attenuation) are the foundation for all ablation results and the KiTS23 zero-shot transfer, yet no inter-rater statistics, pathology correlation, explicit extraction protocol from reports, or verification procedure are described. Without these, observed gaps between mask+SuPreM and other configurations cannot be attributed to the model choices rather than label noise or center-specific annotation patterns.
Authors: We agree that additional details on the label curation process are required to support attribution of performance differences to model choices. In the revised manuscript, we will expand the dataset section with an explicit description of the report extraction protocol (structured parsing of clinical radiology reports by trained annotators), the verification procedure (review by board-certified radiologists), and any inter-rater agreement statistics that were recorded during curation. Pathology correlation is not available for the majority of cases, as biopsy confirmation was not performed for benign or low-risk lesions; we will state this limitation explicitly. These additions will clarify the label generation process and strengthen the interpretation of the ablation results. revision: yes
-
Referee: [Abstract and results sections] Abstract and results sections: the reported AUCs and mAP values include standard deviations but provide no information on the number of runs, data-split stratification, or statistical testing for the claimed dominance of the two design choices; this weakens the strength of the cross-representation and cross-initialization conclusions.
Authors: We acknowledge that the current description of the experimental protocol is insufficient. The reported standard deviations reflect variability across multiple independent runs. In the revision, we will explicitly state the number of runs, detail the patient-level stratification used for train/validation/test splits (to avoid data leakage), and add statistical comparisons (paired t-tests or equivalent) between the dominant configurations (mask channel and SuPreM pretraining) and the alternatives. These clarifications will be included in the results section and, space permitting, referenced in the abstract. revision: yes
Circularity Check
No circularity: empirical results on held-out data with independent architecture
full rationale
The paper reports AUC and mAP metrics computed on held-out UF-Health test volumes and zero-shot KiTS23 cases, with no equations or claims that reduce these quantities to fitted parameters or self-citations by construction. LesionDETR is presented as a DETR variant with size-distance matching and hierarchical loss; these are standard architectural choices whose performance is measured externally rather than defined into the evaluation. Ablations across input representations and initializations provide independent content, and the central claims rest on data splits and external validation rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. G. Silverman, I. Pedrosa, J. H. Ellis, N. M. Hindman, N. Schieda, A. D. Smith, E. M. Remer, A. B. Shinagare, N. E. Curci, D. J. Rader, et al., Bosniak classification of cystic renal masses, version 2019: An update proposal and needs assessment, Radiology 292 (2) (2019) 475– 488
2019
-
[2]
B. R. Herts, S. G. Silverman, N. M. Hindman, R. G. Uzzo, R. P. Hart- man, G. M. Israel, D. A. Baumgarten, C. B. Sussman, N. H. Ramaiya, Management of the incidental renal mass on CT: A white paper of the ACR incidental findings committee, Journal of the American College of Radiology 15 (2) (2018) 264–273
2018
-
[3]
H. Sung, J. Ferlay, R. L. Siegel, M. Laversanne, I. Soerjomataram, A. Je- mal, F. Bray, Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries, CA: A Cancer Journal for Clinicians 71 (3) (2021) 209–249
2020
- [4]
-
[5]
Zhou, et al., An end-to-end framework for kidney cancer diagnosis from multi-phase CT scans, npj Precision Oncology 5 (2021) 24
J. Zhou, et al., An end-to-end framework for kidney cancer diagnosis from multi-phase CT scans, npj Precision Oncology 5 (2021) 24. 26
2021
- [6]
-
[7]
S. Han, S. I. Hwang, H. J. Lee, The classification of renal cancer in 3-phase CT images using a deep learning method, Journal of Digital Imaging 32 (4) (2019) 638–643
2019
-
[8]
Isensee, P
F. Isensee, P. F. Jaeger, S. A. A. Kohl, J. Petersen, K. H. Maier-Hein, nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation, Nature Methods 18 (2) (2021) 203–211
2021
-
[9]
Wasserthal, H.-C
J. Wasserthal, H.-C. Breit, M. T. Meyer, et al., TotalSegmentator: Ro- bust segmentation of 104 anatomic structures in CT images, Radiology: Artificial Intelligence 5 (5) (2023) e230024
2023
-
[10]
A. Myronenko, et al., Automated 3D segmentation of kidneys and tumors in MICCAI KiTS 2023 challenge, in: Springer LNCS, 2023, arXiv:2310.04110
arXiv 2023
-
[11]
I.L.Xi, Y.Zhao, R.Fishman, M.Kamyab, P.Lipton, B.Lehrer, M.Hao, S. S. Raman, Stratification of cystic renal masses into benign and po- tentially malignant: Applying machine learning to the Bosniak classifi- cation, European Radiology 30 (2020) 2817–2826
2020
-
[12]
M. E. Klontzas, G. Kalarakis, E. Koltsakis, T. Papathomas, A. H. Karantanas, A. Tzortzakakis, Convolutional neural networks for the dif- ferentiation between benign and malignant renal tumors with a multi- center international computed tomography dataset, Insights into Imag- ing 15 (2024) 48
2024
-
[13]
Uhlig, A
J. Uhlig, A. Parakh, B. Sauer, et al., Deep learning and radiomic feature- based blending ensemble classifier for malignancy risk prediction in cys- tic renal lesions, Insights into Imaging 13 (2022) 6
2022
-
[14]
K. Yan, Y. Tang, Y. Peng, V. Sandfort, M. Bagheri, Z. Lu, R. M. Sum- mers, MULAN: Multitask universal lesion analysis network for joint lesion detection, tagging, and segmentation, in: Medical Image Com- puting and Computer-Assisted Intervention (MICCAI), Vol. 11769 of LNCS, 2019, pp. 194–202. 27
2019
-
[15]
Zlocha, Q
M. Zlocha, Q. Dou, B. Glocker, Improving RetinaNet for CT lesion de- tection with dense masks from weak RECIST labels, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), Vol. 11769 of LNCS, 2019, pp. 402–410
2019
-
[16]
O. Oktay, J. Schlemper, L. Le Folgoc, M. Lee, M. Heinrich, K. Mis- awa, K. Mori, S. McDonagh, N. Y. Hammerla, B. Kainz, B. Glocker, D. Rueckert, Attention U-Net: Learning where to look for the pancreas, in: Medical Imaging with Deep Learning (MIDL), 2018, arXiv:1804.03999
Pith/arXiv arXiv 2018
-
[17]
Kamnitsas, C
K. Kamnitsas, C. Ledig, V. F. J. Newcombe, J. P. Simpson, A. D. Kane, D. K. Menon, D. Rueckert, B. Glocker, Efficient multi-scale 3D CNN with fully connected CRF for accurate brain lesion segmentation, Medical Image Analysis 36 (2017) 61–78
2017
-
[18]
H. Kalisch, et al., CT-GRAPH: Hierarchical graph attention network for anatomy-guided CT report generation, in: ICCV Workshop, 2025, arXiv:2508.05375
arXiv 2025
-
[19]
M. Baharoon, et al., Exploring the design space of 3D MLLMs for CT re- port generation, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2025, arXiv:2506.21535
arXiv 2025
-
[20]
Tajbakhsh, J
N. Tajbakhsh, J. Y. Shin, S. R. Gurudu, R. T. Hurst, C. B. Kendall, M. B. Gotway, J. Liang, Convolutional neural networks for medical im- ageanalysis: Fulltrainingorfinetuning?, IEEETransactionsonMedical Imaging 35 (5) (2016) 1299–1312
2016
-
[21]
Raghu, C
M. Raghu, C. Zhang, J. Kleinberg, S. Bengio, Transfusion: Understand- ing transfer learning for medical imaging, in: Advances in Neural Infor- mation Processing Systems (NeurIPS), 2019
2019
-
[22]
Li, et al., How well do supervised 3D models transfer to medical imaging tasks?, in: International Conference on Learning Representa- tions (ICLR), 2024, oral
W. Li, et al., How well do supervised 3D models transfer to medical imaging tasks?, in: International Conference on Learning Representa- tions (ICLR), 2024, oral. GitHub: MrGiovanni/SuPreM
2024
-
[23]
L. Wu, J. Zhuang, et al., VoCo: A simple-yet-effective volume contrastive learning framework for 3D medical image analysis, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition 28 (CVPR), 2024, arXiv:2402.17300. Extended version: IEEE TPAMI
arXiv 2024
-
[24]
GitHub: Luffy503/VoCo
-
[25]
I. E. Hamamci, et al., Developing generalist foundation models from a multimodal dataset for 3D computed tomography, Nature Biomedical EngineeringArXiv:2403.17834 (2025)
arXiv 2025
-
[26]
Z. Zhou, V. Sodha, J. Pang, M. B. Gotway, J. Liang, Models genesis, Medical Image Analysis 67 (2021) 101840
2021
-
[27]
Z. Huang, et al., STU-Net: Scalable and transferable medical im- age segmentation models empowered by large-scale supervised pre- trainingArXiv:2304.06716. GitHub: uni-medical/STU-Net (2023)
arXiv 2023
-
[28]
L. Blankemeier, et al., Merlin: A computed tomography vision-language foundation model and dataset, NatureArXiv:2406.06512 (2026)
arXiv 2026
-
[29]
F. Bai, et al., M3D: Advancing 3D medical image analysis with multi- modal large language modelsArXiv:2404.00578 (2024)
arXiv 2024
-
[30]
Haghgoo, R
J.Irvin, P.Rajpurkar, M.Ko, Y.Yu, S.Ciurea-Ilcus, C.Chute, H.Mark- lund, B. Haghgoo, R. Ball, K. Shpanskaya, J. Seekins, D. A. Mong, S. S. Halabi, J. K. Sandberg, R. Jones, D. B. Larson, C. P. Langlotz, B. N. Patel, M. P. Lungren, A. Y. Ng, CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison, in: AAAI Con- ference on A...
2019
-
[31]
L. C. Adams, D. Truhn, F. Busch, A. Kader, S. M. Niehues, M. R. Makowski, K. K. Bressem, Leveraging GPT-4 for post hoc transforma- tion of free-text radiology reports into structured reporting: A multilin- gual feasibility study, Radiology 307 (4) (2023) e230725
2023
-
[32]
P. Bassi, et al., RadGPT: Constructing 3D image-text tumor datasets, in: IEEE/CVF International Conference on Computer Vision (ICCV), 2025, arXiv:2501.04678
arXiv 2025
-
[33]
Y. Zhao, X. Wang, T. Che, G. Bao, S. Li, Multi-task deep learning for medical image computing and analysis: A review, Computers in Biology and Medicine 153 (2023) 106496. 29
2023
-
[34]
12346 of LNCS, 2020, pp
N.Carion, F.Massa, G.Synnaeve, N.Usunier, A.Kirillov, S.Zagoruyko, End-to-end object detection with transformers, in: European Confer- ence on Computer Vision (ECCV), Vol. 12346 of LNCS, 2020, pp. 213– 229
2020
-
[35]
H. Li, et al., Transformer-powered precision: A DETR-based approach for robust detection in medical ultrasound with cholelithiasis as a case study, Computational and Structural Biotechnology Journal (2025)
2025
-
[36]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft COCO: Common objects in context, in: European Conference on Computer Vision (ECCV), 2014, pp. 740– 755
2014
-
[37]
Y. Tang, et al., Self-supervised pre-training of Swin Transformers for 3D medical image analysis, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, arXiv:2111.14791
arXiv 2022
-
[38]
multiple additional smaller cysts
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense objectdetection, in: IEEEInternationalConferenceonComputerVision (ICCV), 2017, pp. 2980–2988. 30 Appendix A. Representative report snippets Sample 1. FINDINGS:Kidneys: Right kidney: No hydronephrosis. No obstructing calculus. There is a mildly lobular, solid heterogeneously enhancing...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.