Stateful Visual Encoders for Vision-Language Models
Pith reviewed 2026-06-28 07:24 UTC · model grok-4.3
The pith
Stateful visual encoders improve vision-language models by conditioning each image on prior visual features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
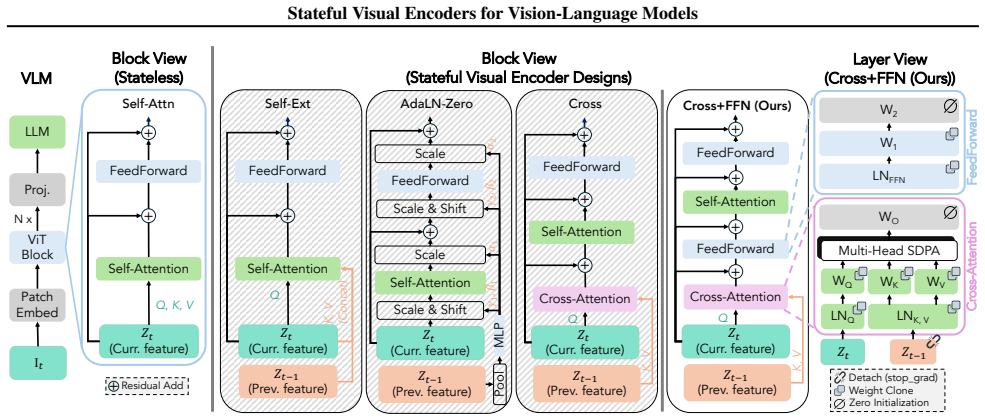
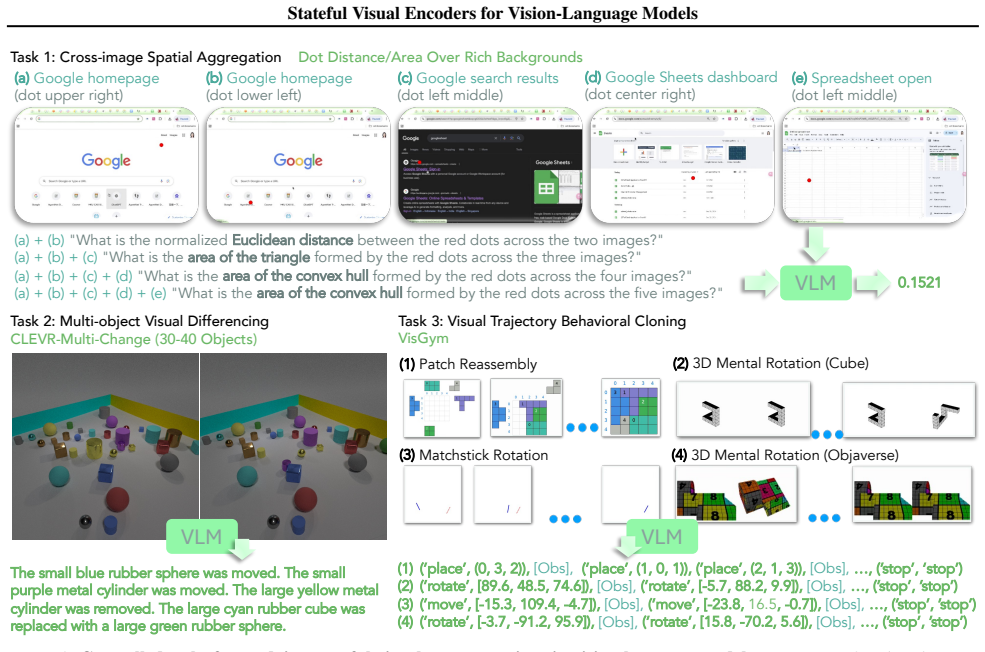
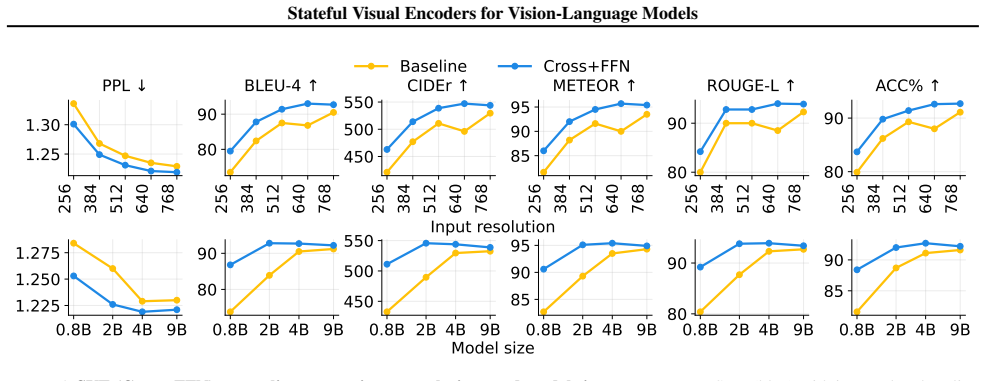
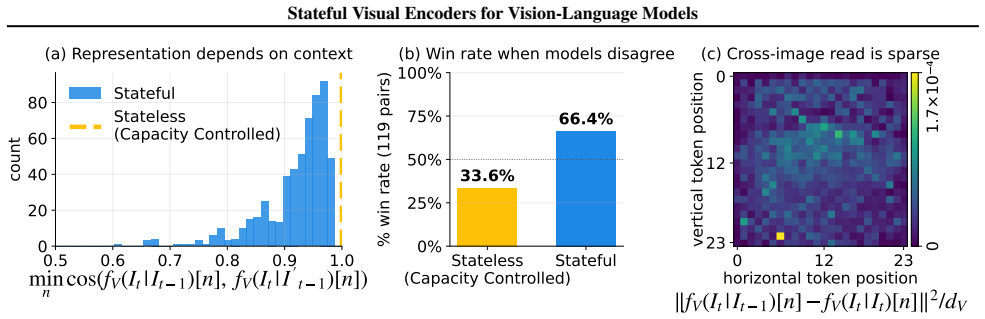
A Stateful Visual Encoder conditions each visual representation on prior visual features. When added to VLMs and trained with supervised finetuning, it produces consistent gains on cross-image spatial aggregation, multi-object visual differencing, and visual trajectory behavior cloning. The same pattern appears on longitudinal radiology, fine-grained image comparison, and remote sensing, where the models match or exceed specialized baselines.
What carries the argument
The Stateful Visual Encoder, which conditions each image's visual representation on features from previous images.
If this is right
- VLMs become better suited for multi-image, multi-turn agentic tasks where decisions depend on visual changes.
- Performance gains remain consistent across different input resolutions, language model sizes, and VLM backbones.
- Stateful encoders can improve generalist VLMs to match or surpass specialized models in domains like radiology and remote sensing.
- Visual comparisons shift partly from the language model to the encoder, potentially reducing attenuation of small changes.
Where Pith is reading between the lines
- Future work could test whether statefulness allows smaller language models to achieve similar multi-image reasoning.
- Integrating statefulness might extend naturally to video inputs or longer sequences without additional architectural changes.
- The approach could be combined with existing techniques for efficient multi-image processing to further scale.
Load-bearing premise
That the observed improvements result mainly from the cross-image conditioning in the encoder rather than from changes in finetuning procedure or data selection.
What would settle it
A controlled experiment that applies identical supervised finetuning to both a stateful and a stateless encoder and measures whether the performance gap on the cross-image tasks disappears.
Figures

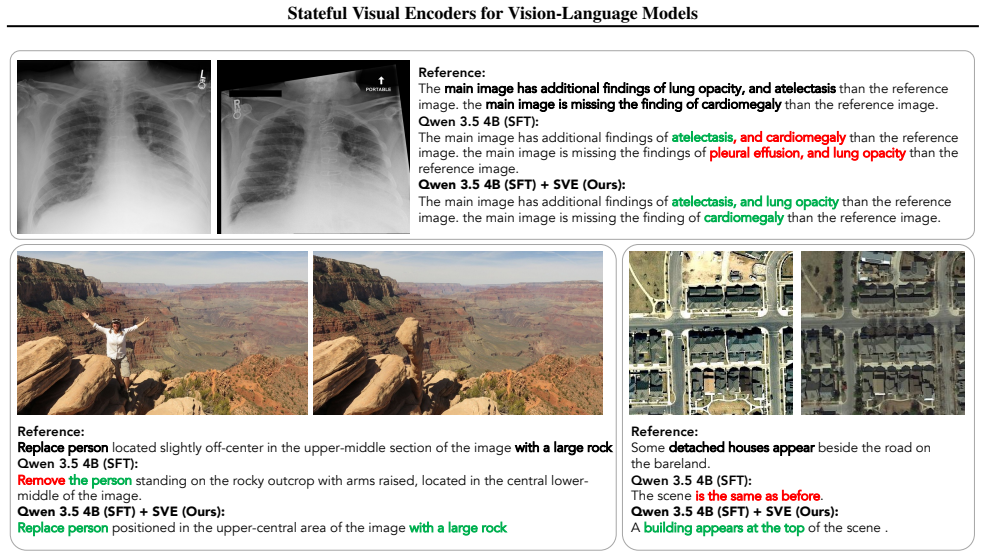
read the original abstract
Vision-language models (VLMs) are increasingly used in multi-image, multi-turn agentic settings where decisions depend on visual changes. However, in existing open-weight VLMs, visual comparisons happen only inside the language model, while the visual encoder itself remains stateless: each image is encoded independently, without access to the prior visual context. As a result, small but task-critical changes may be attenuated before the language model has a chance to compare them, especially when those changes do not affect the high-level semantics of the scene. We introduce a Stateful Visual Encoder, which conditions each visual representation on prior visual features. Under supervised finetuning, VLMs equipped with stateful encoders achieve consistent improvements on controlled tasks involving cross-image spatial aggregation, multi-object visual differencing, and visual trajectory behavior cloning. These improvements are consistent across input resolutions, language model sizes, and VLM backbones. Finally, we validate our model on real-world tasks, including longitudinal radiology, fine-grained image comparison, and remote sensing, where stateful encoders consistently improve generalist VLM baselines and can match or surpass specialized models in selected domains. Project page: https://statefulvisualencoders.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Stateful Visual Encoder for vision-language models that conditions each image's visual representation on prior visual features, rather than encoding images independently. Under supervised finetuning, VLMs using this encoder show consistent improvements on controlled tasks (cross-image spatial aggregation, multi-object visual differencing, visual trajectory behavior cloning) and real-world tasks (longitudinal radiology, fine-grained image comparison, remote sensing). Gains are reported as consistent across input resolutions, language model sizes, and VLM backbones.
Significance. If the improvements are attributable to the cross-image conditioning mechanism rather than capacity or optimization differences, the work could provide a practical architectural modification for VLMs in multi-image and agentic settings. The consistency across multiple axes (resolutions, model sizes, backbones) and the validation on both controlled and real-world tasks would be a strength, though the empirical claims require isolation of the proposed mechanism to establish significance.
major comments (2)
- [Results on controlled tasks] The central claim requires that gains arise specifically from conditioning each visual representation on prior features. No ablation is described that holds total parameters, training steps, data, and optimization fixed while toggling only the cross-image conditioning path (see results sections and tables reporting supervised finetuning outcomes). This leaves alternative explanations (extra capacity from the state module, different dynamics) viable and is load-bearing for the mechanism.
- [Real-world validation experiments] Table reporting real-world task results: comparisons to specialized models are presented without error bars, multiple runs, or statistical tests, making it difficult to evaluate whether stateful encoders reliably match or surpass baselines in selected domains.
minor comments (2)
- [Abstract] The abstract asserts 'consistent improvements' without any quantitative deltas, baselines, or variance measures; move at least one key numeric result (with error bars) into the abstract for clarity.
- [Method] Notation for the state module and how prior features are aggregated should be formalized with an equation in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our experimental design and noting where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Results on controlled tasks] The central claim requires that gains arise specifically from conditioning each visual representation on prior features. No ablation is described that holds total parameters, training steps, data, and optimization fixed while toggling only the cross-image conditioning path (see results sections and tables reporting supervised finetuning outcomes). This leaves alternative explanations (extra capacity from the state module, different dynamics) viable and is load-bearing for the mechanism.
Authors: Our controlled-task results compare the stateful encoder directly against the standard stateless baseline under matched training conditions (identical data, steps, optimizer, and learning rate schedule). The state module is the core of the proposed mechanism and necessarily adds parameters for cross-image conditioning. While we did not include an auxiliary control that adds equivalent non-functional capacity to the baseline, the observed gains hold across multiple VLM backbones, language-model sizes, and input resolutions. This consistency makes a pure capacity explanation less likely. In revision we will add an explicit limitations paragraph discussing this point and the value of future parameter-matched controls. revision: partial
-
Referee: [Real-world validation experiments] Table reporting real-world task results: comparisons to specialized models are presented without error bars, multiple runs, or statistical tests, making it difficult to evaluate whether stateful encoders reliably match or surpass baselines in selected domains.
Authors: We agree that variability reporting would improve interpretability. The real-world experiments were performed under domain-specific fine-tuning regimes that were computationally expensive; several were executed as single runs. In the revised manuscript we will add error bars and standard deviations for all tasks that were repeated across seeds, and we will explicitly note single-run limitations for the remaining tasks. revision: yes
Circularity Check
No circularity: empirical results with no derivations or self-referential fits
full rationale
The paper introduces a stateful visual encoder and reports empirical gains under supervised finetuning on controlled and real-world tasks. No equations, derivations, or parameter-fitting steps are described in the abstract or full text. All claims rest on experimental comparisons against baselines rather than any reduction of outputs to inputs by construction, self-citation chains, or ansatz smuggling. This is a standard empirical ML paper whose central claims are externally falsifiable via replication on the reported tasks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Stateful Visual Encoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Icml , volume=
Is space-time attention all you need for video understanding? , author=. Icml , volume=
-
[2]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vivit: A video vision transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[3]
Advances in neural information processing systems , volume=
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training , author=. Advances in neural information processing systems , volume=
-
[4]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[5]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[6]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
-
[9]
ArXiv , year=
Gemma 3 Technical Report , author=. ArXiv , year=
-
[10]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[11]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[12]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[13]
arXiv preprint arXiv:2511.17803 , year=
Pillar-0: A new frontier for radiology foundation models , author=. arXiv preprint arXiv:2511.17803 , year=
-
[14]
arXiv preprint arXiv:2511.19418 , year=
Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens , author=. arXiv preprint arXiv:2511.19418 , year=
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Perception tokens enhance visual reasoning in multimodal language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
Jiang, Dongfu and He, Xuan and Zeng, Huaye and Wei, Cong and Ku, Max and Liu, Qian and Chen, Wenhu , journal =
-
[17]
Li, Feng and Zhang, Renrui and Zhang, Hao and Zhang, Yuanhan and Li, Bo and Li, Wei and Ma, Zejun and Li, Chunyuan , journal =
-
[18]
Li, Bo and Zhang, Yuanhan and Guo, Dong and Zhang, Renrui and Li, Feng and Zhang, Hao and Zhang, Kaichen and Li, Yanwei and Liu, Ziwei and Li, Chunyuan , journal =
-
[19]
Conference on Language Modeling (COLM) , year =
Building and Better Understanding Vision-Language Models: Insights and Future Directions , author =. Conference on Language Modeling (COLM) , year =
-
[20]
Lin, Ji and Yin, Hongxu and Ping, Wei and Molchanov, Pavlo and Shoeybi, Mohammad and Han, Song , booktitle =
-
[21]
He, Bo and Li, Hengduo and Jang, Young Kyun and Jia, Menglin and Cao, Xuefei and Shah, Ashish and Shrivastava, Abhinav and Lim, Ser-Nam , booktitle =
-
[22]
Zhang, Haoji and Wang, Yiqin and Tang, Yansong and Liu, Yong and Feng, Jiashi and Dai, Jifeng and Jin, Xiaojie , booktitle =
-
[23]
Diko, Anxhelo and others , booktitle =
-
[24]
Xu, Yujie and others , journal =
-
[25]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[29]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[30]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Robust Change Captioning , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[32]
IEEE International Geoscience and Remote Sensing Symposium (IGARSS) , year =
A Transformer-Based Siamese Network for Change Detection , author =. IEEE International Geoscience and Remote Sensing Symposium (IGARSS) , year =
-
[33]
IEEE Transactions on Geoscience and Remote Sensing , volume =
Remote Sensing Image Change Detection With Transformers , author =. IEEE Transactions on Geoscience and Remote Sensing , volume =
-
[34]
Dong, Sijun and Wang, Libo and Du, Bo and Meng, Xiaoliang , journal =
-
[35]
arXiv preprint arXiv:2508.09123 , year=
Opencua: Open foundations for computer-use agents , author=. arXiv preprint arXiv:2508.09123 , year=
-
[36]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Describing and localizing multiple changes with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[37]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[38]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[39]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cider: Consensus-based image description evaluation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[40]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
2005
-
[41]
European conference on computer vision , pages=
Spice: Semantic propositional image caption evaluation , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[42]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[43]
arXiv preprint arXiv:2601.16973 , year=
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents , author=. arXiv preprint arXiv:2601.16973 , year=
-
[44]
Advances in neural information processing systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in neural information processing systems , volume=
-
[45]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Exploring simple siamese representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[46]
Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset , year=
Liu, Chenyang and Zhao, Rui and Chen, Hao and Zou, Zhengxia and Shi, Zhenwei , journal=. Remote Sensing Image Change Captioning With Dual-Branch Transformers: A New Method and a Large Scale Dataset , year=
-
[47]
IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium , pages=
Progressive scale-aware network for remote sensing image change captioning , author=. IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium , pages=. 2023 , organization=
2023
-
[48]
IEEE Transactions on Image Processing , volume=
Changes to captions: An attentive network for remote sensing change captioning , author=. IEEE Transactions on Image Processing , volume=. 2023 , publisher=
2023
-
[49]
Single-Stream Extractor Network With Contrastive Pre-Training for Remote-Sensing Change Captioning , year=
Zhou, Qing and Gao, Junyu and Yuan, Yuan and Wang, Qi , journal=. Single-Stream Extractor Network With Contrastive Pre-Training for Remote-Sensing Change Captioning , year=
-
[50]
IEEE Transactions on Geoscience and Remote Sensing , year=
Diffusion-rscc: Diffusion probabilistic model for change captioning in remote sensing images , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[51]
A Multitask Network and Two Large-Scale Datasets for Change Detection and Captioning in Remote Sensing Images , year=
Shi, Jingye and Zhang, Mengge and Hou, Yuewu and Zhi, Ruicong and Liu, Jiqiang , journal=. A Multitask Network and Two Large-Scale Datasets for Change Detection and Captioning in Remote Sensing Images , year=
-
[52]
A Decoupling Paradigm With Prompt Learning for Remote Sensing Image Change Captioning , year=
Liu, Chenyang and Zhao, Rui and Chen, Jianqi and Qi, Zipeng and Zou, Zhengxia and Shi, Zhenwei , journal=. A Decoupling Paradigm With Prompt Learning for Remote Sensing Image Change Captioning , year=
-
[53]
arXiv preprint arXiv:2511.21420 , year=
SAM Guided Semantic and Motion Changed Region Mining for Remote Sensing Change Captioning , author=. arXiv preprint arXiv:2511.21420 , year=
-
[54]
IEEE Transactions on Geoscience and Remote Sensing , year=
Spatial-Semantic Alignment and Change-aware Network for Remote Sensing Image Change Captioning , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[55]
arXiv preprint arXiv:2508.06471 , year=
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
-
[56]
Hu, Xinyue and Gu, Lin and An, Qiyuan and Zhang, Mengliang and liu, liangchen and Kobayashi, Kazuma and Harada, Tatsuya and Summers, Ronald and Zhu, Yingying , title =. 2025 , month = feb, note =. doi:10.13026/e6dd-cn74 , url =
-
[57]
2025 , eprint=
ImgEdit: A Unified Image Editing Dataset and Benchmark , author=. 2025 , eprint=
2025
-
[58]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Adding conditional control to text-to-image diffusion models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[59]
Uncertainty in artificial intelligence , pages=
Rezero is all you need: Fast convergence at large depth , author=. Uncertainty in artificial intelligence , pages=. 2021 , organization=
2021
-
[60]
Advances in neural information processing systems , volume=
Glow: Generative flow with invertible 1x1 convolutions , author=. Advances in neural information processing systems , volume=
-
[61]
Advances in Neural Information Processing Systems , volume=
Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
International Conference on Learning Representations , volume=
Gated delta networks: Improving mamba2 with delta rule , author=. International Conference on Learning Representations , volume=
-
[63]
arXiv preprint arXiv:2002.05202 , year=
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
Pith/arXiv arXiv 2002
-
[64]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Going deeper with image transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[65]
arXiv preprint arXiv:2004.05150 , year=
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
Pith/arXiv arXiv 2004
-
[66]
Advances in Neural Information Processing Systems , volume=
Imgedit: A unified image editing dataset and benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
DiffTell: A High-Quality Dataset for Describing Image Manipulation Changes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[68]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Superedit: Rectifying and facilitating supervision for instruction-based image editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[69]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
What Changed? Detecting and Evaluating Instruction-Guided Image Edits with Multimodal Large Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[70]
2026 , month = apr, day =
Introducing Claude Opus 4.7 , author =. 2026 , month = apr, day =
2026
-
[71]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[72]
proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Quo vadis, action recognition? a new model and the kinetics dataset , author=. proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Multiscale vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[74]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video swin transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[75]
European conference on computer vision , pages=
Internvideo2: Scaling foundation models for multimodal video understanding , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[76]
Gundavarapu and Liangzhe Yuan and Hao Zhou and Shen Yan and Jennifer J
Long Zhao and Nitesh B. Gundavarapu and Liangzhe Yuan and Hao Zhou and Shen Yan and Jennifer J. Sun and Luke Friedman and Rui Qian and Tobias Weyand and Yue Zhao and Rachel Hornung and Florian Schroff and Ming-Hsuan Yang and David A. Ross and Huisheng Wang and Hartwig Adam and Mikhail Sirotenko and Ting Liu and Boqing Gong , booktitle =
-
[77]
2026 , eprint=
Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing , author=. 2026 , eprint=
2026
-
[78]
Advances in Neural Information Processing Systems , volume=
Perception encoder: The best visual embeddings are not at the output of the network , author=. Advances in Neural Information Processing Systems , volume=
-
[79]
arXiv preprint arXiv:2602.08683 , year=
OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence , author=. arXiv preprint arXiv:2602.08683 , year=
-
[80]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.