3DThinkVLA: Endowing Vision-Language-Action Models with Latent 3D Priors via 3D-Thinking-Guided Co-training
Pith reviewed 2026-06-28 07:18 UTC · model grok-4.3
The pith
A co-training framework lets VLA models acquire implicit 3D spatial priors from 2D images alone by disentangling geometry perception and reasoning distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
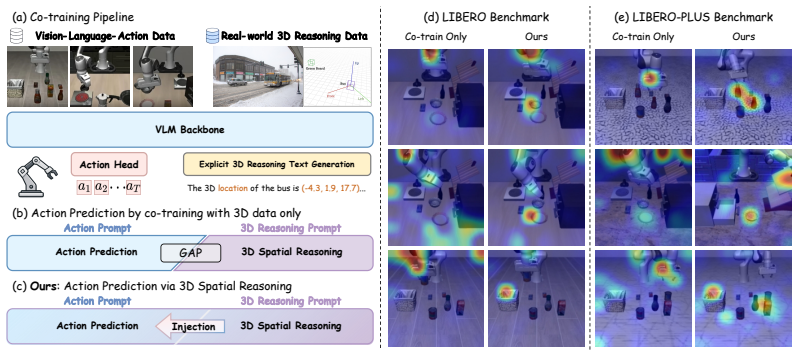
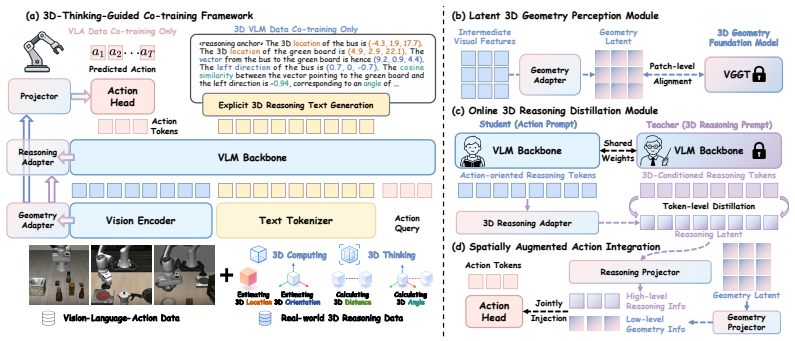
The authors claim that 3D geometry perception and 3D spatial reasoning are distinct capabilities that can be disentangled and injected at different feature hierarchies inside a VLA model. During co-training a latent 3D geometry perception module aligns intermediate visual features with a 3D foundation model; an online 3D reasoning distillation module uses a shared reasoning anchor token to move spatial priors from explicit teacher reasoning prompts into student action prompts without chain-of-thought text; and a spatially augmented action integration unites the two signals as hierarchical conditions on the action-query tokens. Once trained, only the adapters remain, enabling purely 2D infere
What carries the argument
The 3D-thinking-guided co-training framework consisting of a latent 3D geometry perception module, an online 3D reasoning distillation module with shared reasoning anchor token, and spatially augmented action integration.
If this is right
- The final deployed model uses only 2D images and lightweight adapters, discarding the 3D foundation model and teacher branch.
- The method prevents catastrophic forgetting of the pretrained vision-language model.
- State-of-the-art results are reported on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world manipulation tasks.
- No 3D sensors or explicit text generation are needed at inference time.
Where Pith is reading between the lines
- The same anchor-token distillation pattern might be reusable for other implicit reasoning tasks such as temporal or causal inference in VLA models.
- If the hierarchical injection truly prevents action shortcuts, similar disentanglement could be tested on non-manipulation VLA benchmarks that currently suffer from 2D shortcut learning.
- The approach implies that explicit 3D supervision can be compressed into latent adapters, which may reduce the sensor and compute cost of deploying 3D-aware robots.
Load-bearing premise
The shared reasoning anchor token can reliably transfer high-level spatial thinking from explicit teacher reasoning prompts to student action prompts without requiring chain-of-thought text generation.
What would settle it
A controlled ablation that removes only the online 3D reasoning distillation module and the anchor token, then measures whether performance on LIBERO and real-robot tasks falls back to the level of the unmodified VLA baseline.
Figures



read the original abstract
We propose a 3D-thinking-guided co-training framework that enables vision-language-action (VLA) models to perform 3D spatial reasoning implicitly during action prediction. Our core insight is that 3D geometry perception and 3D spatial reasoning are distinct capabilities that can be disentangled and injected at different feature hierarchies. During training, three tightly coupled components work in concert primarily within the latent space: (1) To gain geometric priors, a latent 3D geometry perception module aligns intermediate visual features with a 3D foundation model, acquiring low-level geometric cues without architectural modifications to the VLM backbone. (2) Complementing this, an online 3D reasoning distillation module mitigates the prompt-induced reasoning gap via a shared reasoning anchor token. During 3D VLM co-training, this anchor is emitted as the first output token to robustly encode spatial priors. During VLA training, it serves as an input token inserted between the task and action instructions, transferring high-level spatial thinking from explicit teacher reasoning prompts to student action prompts without chain-of-thought text generation. (3) These disentangled geometric and reasoning features are then united by a spatially augmented action integration, which jointly injects them into the action-query tokens as hierarchical spatial conditions to prevent action shortcuts. At deployment, our method retains only its lightweight adapters to perform implicit 3D reasoning, discarding the 3D foundation model and the teacher branch used for supervision. Consequently, it operates purely on 2D images without 3D sensors, external models, or explicit text generation while preventing catastrophic forgetting of the pretrained VLM, achieving state-of-the-art performance on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 3DThinkVLA, a 3D-thinking-guided co-training framework for vision-language-action (VLA) models. It disentangles low-level 3D geometry perception (via a latent module aligned to a 3D foundation model) from high-level spatial reasoning (via online distillation using a shared reasoning anchor token emitted first in teacher mode and inserted as input in student mode). These are combined via spatially augmented action integration that injects features hierarchically into action-query tokens. At deployment the method retains only lightweight adapters, operates on 2D images without external models or explicit CoT text, avoids catastrophic forgetting of the pretrained VLM, and reports state-of-the-art results on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world manipulation tasks.
Significance. If the distillation and hierarchical injection succeed in transferring genuine 3D spatial priors into latent action prediction, the work would offer a practical route to implicit 3D reasoning in VLAs while preserving pretrained capabilities and eliminating test-time 3D dependencies. The training-only use of external 3D models and teacher branches is a clear deployment advantage.
major comments (2)
- [Abstract] Abstract (online 3D reasoning distillation module): The central claim that the shared reasoning anchor token 'robustly encode spatial priors' and transfers 'high-level spatial thinking' from explicit teacher prompts to student action prompts without chain-of-thought generation is load-bearing for the implicit-reasoning guarantee. The provided description supplies no loss formulation, embedding analysis, or ablation isolating the anchor's contribution versus standard fine-tuning; if the token learns only superficial alignment, the subsequent hierarchical injection cannot reliably prevent action shortcuts, directly undermining the SOTA and no-forgetting assertions.
- [Abstract] Abstract (results claim): The manuscript asserts state-of-the-art performance on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world tasks yet supplies no quantitative numbers, tables, error bars, or baseline comparisons. Without these data the magnitude of improvement, statistical reliability, and the specific benefit of the disentangled modules versus ordinary VLA fine-tuning cannot be assessed.
minor comments (1)
- The description of feature injection points in the spatially augmented action integration would benefit from an explicit diagram or pseudocode showing the exact hierarchy levels at which the geometry and reasoning features are added to the action-query tokens.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address each major point below with references to the full manuscript, which contains the requested technical details and quantitative results.
read point-by-point responses
-
Referee: [Abstract] Abstract (online 3D reasoning distillation module): The central claim that the shared reasoning anchor token 'robustly encode spatial priors' and transfers 'high-level spatial thinking' from explicit teacher prompts to student action prompts without chain-of-thought generation is load-bearing for the implicit-reasoning guarantee. The provided description supplies no loss formulation, embedding analysis, or ablation isolating the anchor's contribution versus standard fine-tuning; if the token learns only superficial alignment, the subsequent hierarchical injection cannot reliably prevent action shortcuts, directly undermining the SOTA and no-forgetting assertions.
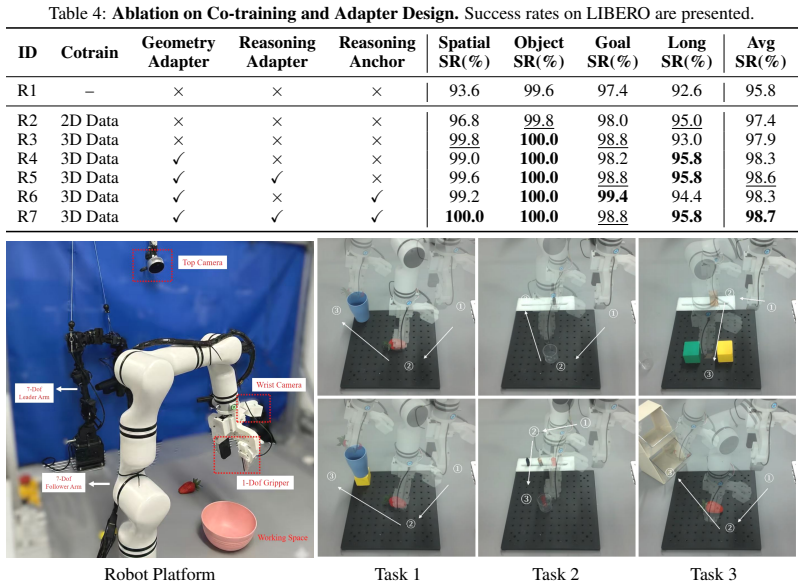
Authors: The abstract provides a high-level summary. The full manuscript details the loss formulation in Section 3.2 (Equation 4), which combines a distillation objective aligning the anchor token to the teacher's first output token with a contrastive term to encourage spatial feature clustering. Section 4.3 presents embedding analysis (Figure 5) showing cosine similarity between the anchor and 3D spatial features from the teacher, distinct from standard VLM tokens. Table 5 reports an ablation removing the anchor, yielding a 7.8% drop on LIBERO and increased forgetting on the original VLM tasks, confirming its non-superficial contribution beyond standard fine-tuning. revision: no
-
Referee: [Abstract] Abstract (results claim): The manuscript asserts state-of-the-art performance on LIBERO, LIBERO-PLUS, SimplerEnv, and real-world tasks yet supplies no quantitative numbers, tables, error bars, or baseline comparisons. Without these data the magnitude of improvement, statistical reliability, and the specific benefit of the disentangled modules versus ordinary VLA fine-tuning cannot be assessed.
Authors: The abstract summarizes the outcome claims concisely. The full manuscript reports the quantitative results in Section 4: Table 1 shows LIBERO average success rate of 92.4% (std 1.2) for 3DThinkVLA versus 78.6% (std 2.1) for the strongest baseline; Table 2 covers LIBERO-PLUS; Table 3 covers SimplerEnv; and Table 6 reports real-world results. All tables include multiple-run error bars and direct comparisons to VLA fine-tuning without the disentangled modules, demonstrating the specific gains from the geometry and reasoning components. revision: no
Circularity Check
No circularity; derivation relies on external supervision during training only
full rationale
The paper's central claims rest on a co-training framework that aligns to an external 3D foundation model and uses a teacher branch only at training time, then discards both at deployment in favor of lightweight adapters. No equations, fitted parameters, or self-citations are shown that reduce any prediction or uniqueness claim to the inputs by construction. The shared reasoning anchor token is introduced as a new architectural device rather than defined in terms of the target behavior. The method is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[3]
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. Vlm4vla: Revisiting vision-language-models in vision-language-action models.arXiv preprint arXiv:2601.03309, 2026
Pith/arXiv arXiv 2026
-
[4]
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[5]
Yicheng Feng, Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Sipeng Zheng, and Zongqing Lu. Spatial-aware vla pretraining through visual-physical alignment from human videos.arXiv preprint arXiv:2512.13080, 2025
arXiv 2025
-
[6]
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representa- tions in vision-language-action models.arXiv preprint arXiv:2508.09071, 2025
arXiv 2025
-
[7]
Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
2026
-
[8]
Zhengshen Zhang, Hao Li, Yalun Dai, Zhengbang Zhu, Lei Zhou, Chenchen Liu, Dong Wang, Francis EH Tay, Sijin Chen, Ziwei Liu, et al. From spatial to actions: Grounding vision-language-action model in spatial foundation priors.arXiv preprint arXiv:2510.17439, 2025
arXiv 2025
-
[9]
Spatialvla: Exploring spatial representations for visual-language-action model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model. arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[10]
Jingjing Qian, Boyao Han, Chen Shi, Lei Xiao, Long Yang, Shaoshuai Shi, and Li Jiang. Geopredict: Leveraging predictive kinematics and 3d gaussian geometry for precise vla manipulation.arXiv preprint arXiv:2512.16811, 2025
Pith/arXiv arXiv 2025
-
[11]
3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024
Pith/arXiv arXiv 2024
-
[12]
Tianyuan Yuan, Yicheng Liu, Chenhao Lu, Zhuoguang Chen, Tao Jiang, and Hang Zhao. Depthvla: Enhanc- ing vision-language-action models with depth-aware spatial reasoning.arXiv preprint arXiv:2510.13375, 2025
arXiv 2025
-
[13]
Zijian Song, Qichang Li, Jiawei Zhou, Zhenlong Yuan, Tianshui Chen, Liang Lin, and Guangrun Wang. Robotic manipulation is vision-to-geometry mapping ( f(v)→g ): Vision-geometry backbones over language and video models.arXiv preprint arXiv:2604.12908, 2026
Pith/arXiv arXiv 2026
-
[14]
Yixuan Li, Yuhui Chen, Mingcai Zhou, Haoran Li, Zhengtao Zhang, and Dongbin Zhao. Qdepth-vla: quantized depth prediction as auxiliary supervision for vision-language-action models.arXiv preprint arXiv:2510.14836, 2025
Pith/arXiv arXiv 2025
-
[15]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model. arXiv preprint arXiv:2510.12276, 2025
arXiv 2025
-
[16]
Zhide Zhong, Junfeng Li, Junjie He, Haodong Yan, Xin Gong, Guanyi Zhao, Yingjie Cai, Jiantao Gao, Xu Yan, Bingbing Liu, et al. Dualcot-vla: Visual-linguistic chain of thought via parallel reasoning for vision-language-action models.arXiv preprint arXiv:2603.22280, 2026
arXiv 2026
-
[17]
Spear-1: Scaling beyond robot demonstrations via 3d understanding, 2026
Nikolay Nikolov, Giuliano Albanese, Sombit Dey, Aleksandar Yanev, Luc Van Gool, Jan-Nico Zaech, and Danda Pani Paudel. Spear-1: Scaling beyond robot demonstrations via 3d understanding, 2026
2026
-
[18]
Fp3: A 3d foundation policy for robotic manipulation, 2025
Rujia Yang, Geng Chen, Chuan Wen, and Yang Gao. Fp3: A 3d foundation policy for robotic manipulation, 2025. 10
2025
-
[19]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models, 2025
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models, 2025
2025
-
[20]
Lift3d foundation policy: Lifting 2d large-scale pretrained models for robust 3d robotic manipulation, 2024
Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilue Wang, Longzan Luo, Lily Lee, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, and Shanghang Zhang. Lift3d foundation policy: Lifting 2d large-scale pretrained models for robust 3d robotic manipulation, 2024
2024
-
[21]
Ali Abouzeid, Malak Mansour, Qinbo Sun, Zezhou Sun, and Dezhen Song. Geoaware-vla: Implicit geometry aware vision-language-action model.arXiv preprint arXiv:2509.14117, 2025
arXiv 2025
-
[22]
Zhengshen Zhang, Hao Li, Yalun Dai, Zhengbang Zhu, Lei Zhou, Chenchen Liu, Dong Wang, Francis E. H. Tay, Sijin Chen, Ziwei Liu, Yuxiao Liu, Xinghang Li, and Pan Zhou. From spatial to actions: Grounding vision-language-action model in spatial foundation priors, 2026
2026
-
[23]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[24]
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, et al. 4d-vla: Spatiotemporal vision-language-action pretraining with cross-scene calibration.arXiv preprint arXiv:2506.22242, 2025
arXiv 2025
-
[25]
Pre-training auto-regressive robotic models with 4d representations, 2025
Dantong Niu, Yuvan Sharma, Haoru Xue, Giscard Biamby, Junyi Zhang, Ziteng Ji, Trevor Darrell, and Roei Herzig. Pre-training auto-regressive robotic models with 4d representations, 2025
2025
-
[26]
Actdistill: General action-guided self-derived distillation for efficient vision-language-action models, 2026
Wencheng Ye, Tianshi Wang, Lei Zhu, Fengling Li, Guoli Yang, and Hengtao Shen. Actdistill: General action-guided self-derived distillation for efficient vision-language-action models, 2026
2026
-
[27]
Ac2-vla: Action-context-aware adaptive computation in vision-language-action models for efficient robotic manipulation, 2026
Wenda Yu, Tianshi Wang, Fengling Li, Jingjing Li, and Lei Zhu. Ac2-vla: Action-context-aware adaptive computation in vision-language-action models for efficient robotic manipulation, 2026
2026
-
[28]
Vla-opd: Bridging offline sft and online rl for vision-language-action models via on-policy distillation, 2026
Zhide Zhong, Haodong Yan, Junfeng Li, Junjie He, Tianran Zhang, and Haoang Li. Vla-opd: Bridging offline sft and online rl for vision-language-action models via on-policy distillation, 2026
2026
-
[29]
Self-improving vision-language-action models with data generation via residual rl, 2025
Wenli Xiao, Haotian Lin, Andy Peng, Haoru Xue, Tairan He, Yuqi Xie, Fengyuan Hu, Jimmy Wu, Zhengyi Luo, Linxi "Jim" Fan, Guanya Shi, and Yuke Zhu. Self-improving vision-language-action models with data generation via residual rl, 2025
2025
-
[30]
Evodrivevla: Evolv- ing autonomous driving vision-language-action model via collaborative perception-planning distillation, 2026
Jiajun Cao, Xiaoan Zhang, Xiaobao Wei, Liyuqiu Huang, Wang Zijian, Hanzhen Zhang, Zhengyu Jia, Wei Mao, Hao Wang, Xianming Liu, Shuchang Zhou, Yang Wang, and Shanghang Zhang. Evodrivevla: Evolv- ing autonomous driving vision-language-action model via collaborative perception-planning distillation, 2026
2026
-
[31]
Vita-vla: Efficiently teaching vision-language models to act via action expert distillation, 2025
Shaoqi Dong, Chaoyou Fu, Haihan Gao, Yi-Fan Zhang, Chi Yan, Chu Wu, Xiaoyu Liu, Yunhang Shen, Jing Huo, Deqiang Jiang, Haoyu Cao, Yang Gao, Xing Sun, Ran He, and Caifeng Shan. Vita-vla: Efficiently teaching vision-language models to act via action expert distillation, 2025
2025
-
[32]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies, 2025
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies, 2025
2025
-
[33]
Octo: An open-source generalist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024
2024
-
[34]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024
2024
-
[35]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models, 2025
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Ming-Yu Liu, Donglai Xiang, Gordon Wetzstein, and Tsung-Yi Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models, 2025
2025
-
[36]
Fast: Efficient action tokenization for vision-language-action models, 2025
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models, 2025. 11
2025
-
[37]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
2026
-
[38]
Fine-tuning vision-language-action models: Optimizing speed and success, 2025
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025
2025
-
[39]
Geovla: Empowering 3d representa- tions in vision-language-action models, 2025
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representa- tions in vision-language-action models, 2025
2025
-
[40]
3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks, 2026
Vineet Bhat, Yu-Hsiang Lan, Prashanth Krishnamurthy, Ramesh Karri, and Farshad Khorrami. 3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks, 2026
2026
-
[41]
Unifying perception and action: A hybrid-modality pipeline with implicit visual chain-of-thought for robotic action generation, 2026
Xiangkai Ma, Lekai Xing, Han Zhang, Wenzhong Li, and Sanglu Lu. Unifying perception and action: A hybrid-modality pipeline with implicit visual chain-of-thought for robotic action generation, 2026
2026
-
[42]
Nora: A small open-sourced generalist vision language action model for embodied tasks, 2025
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U-Xuan Tan, Navonil Majumder, and Soujanya Poria. Nora: A small open-sourced generalist vision language action model for embodied tasks, 2025
2025
-
[43]
Worldvla: Towards autoregressive action world model, 2025
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model, 2025
2025
-
[44]
Abot-m0: Vla foundation model for robotic manipulation with action manifold learning, 2026
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, Feng Xiong, Xing Wei, Zhiheng Ma, and Mu Xu. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning, 2026
2026
-
[45]
Jinhui Ye, Ning Gao, Senqiao Yang, Jinliang Zheng, Zixuan Wang, Yuxin Chen, Pengguang Chen, Yilun Chen, Shu Liu, and Jiaya Jia. Starvla- α: Reducing complexity in vision-language-action systems.arXiv preprint arXiv:2604.11757, 2026
Pith/arXiv arXiv 2026
-
[46]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[47]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[48]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[49]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lu- nawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[50]
Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Tao Kong, Hanbo Zhang, and Huaping Liu. Towards generalist robot policies: What matters in building vision-language- action models.arXiv preprint arXiv:2412.14058, 2024
Pith/arXiv arXiv 2024
-
[51]
Unified vision-language-action model, 2025
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model, 2025
2025
-
[52]
Llava-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2024
2024
-
[53]
Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning, 2025
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning, 2025. 12
2025
-
[54]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024
2024
-
[55]
Depth anything v2, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2, 2024
2024
-
[56]
Self- distilled reasoner: On-policy self-distillation for large language models, 2026
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models, 2026
2026
-
[57]
Point transformer v3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger. InCVPR, 2024
2024
-
[58]
on the left
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InProceedings of Robotics: Science and Systems (RSS), 2024. 13 A Implementation Details We adopt the StarVLA [45] framework with Qwen3-VL 2B [46] as the vision-language backbone. We attac...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.