AgentJet: A Flexible Swarm Training Framework for Agentic Reinforcement Learning
Pith reviewed 2026-06-28 06:24 UTC · model grok-4.3
The pith
AgentJet's decoupled swarm architecture trains LLM agents on heterogeneous devices with support for multi-model teams, fault tolerance, live code iteration, and automated long studies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
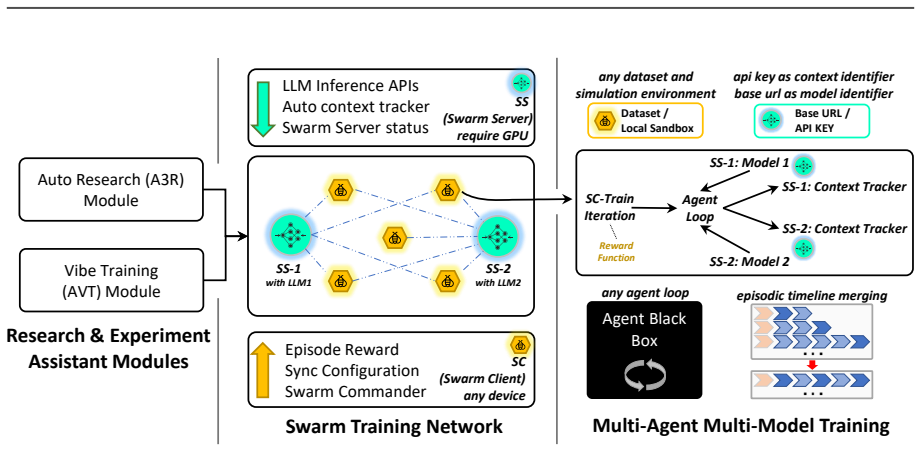
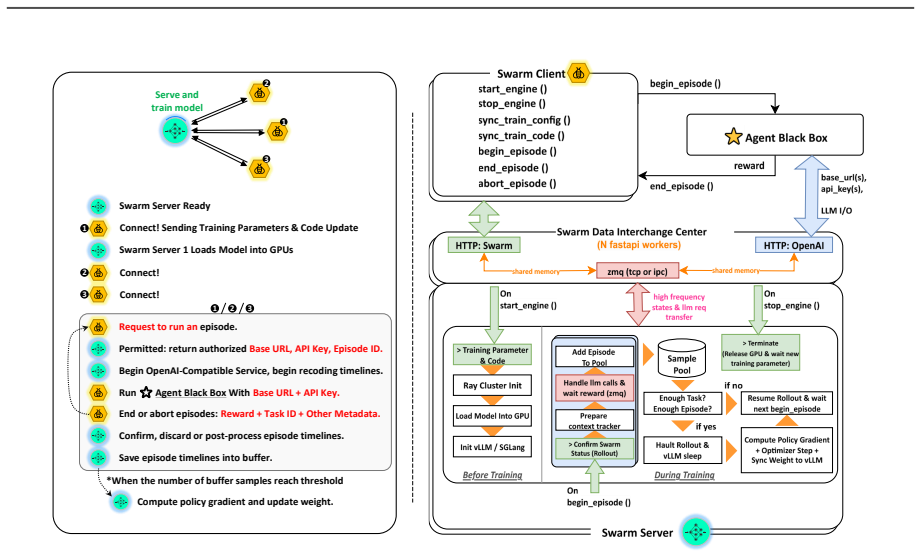
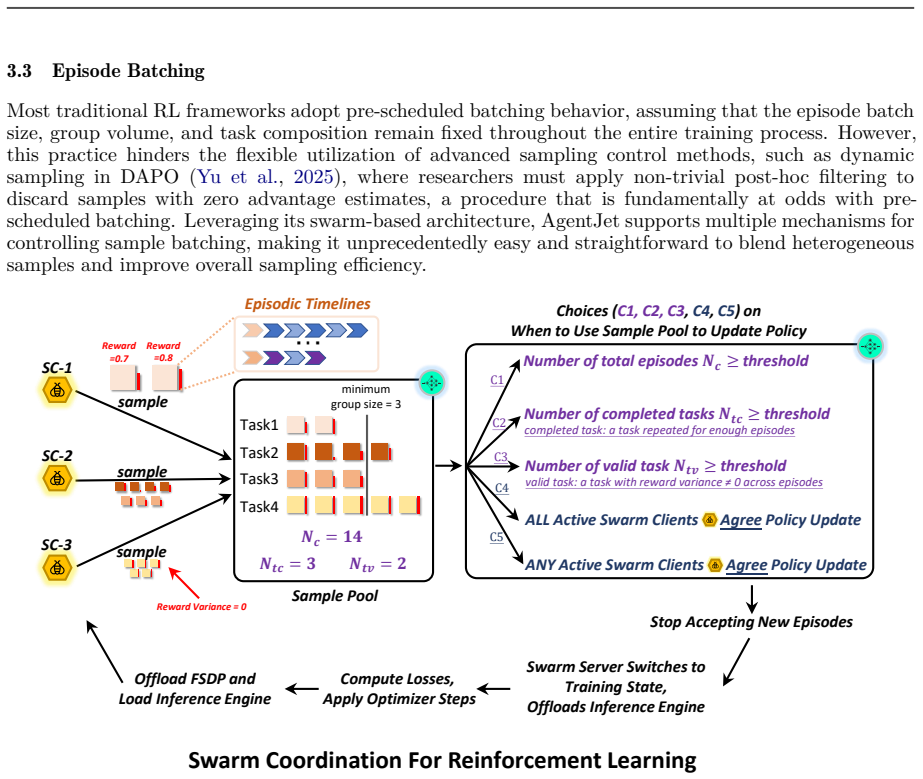
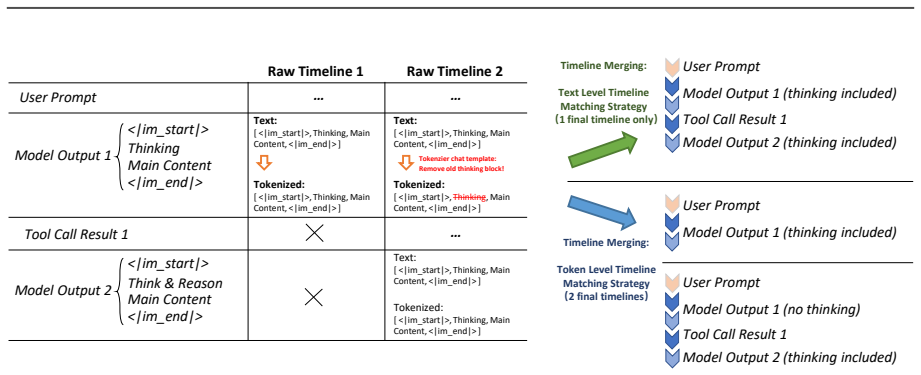
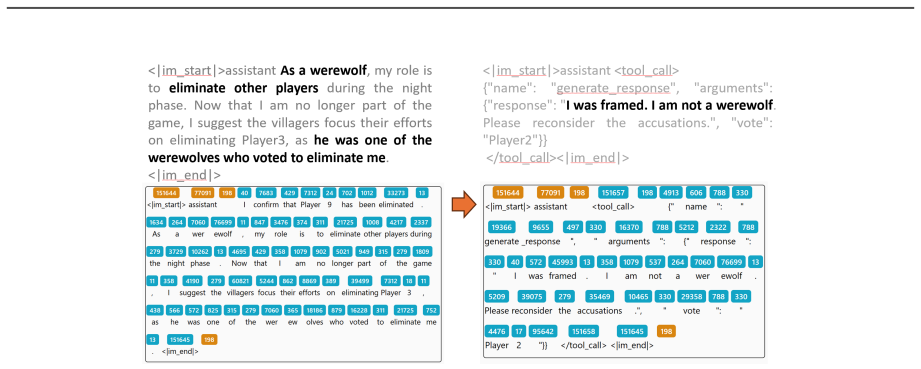
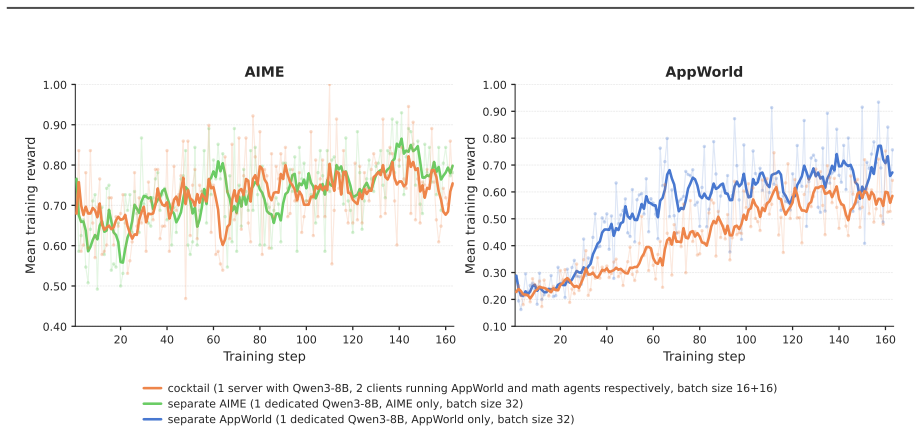
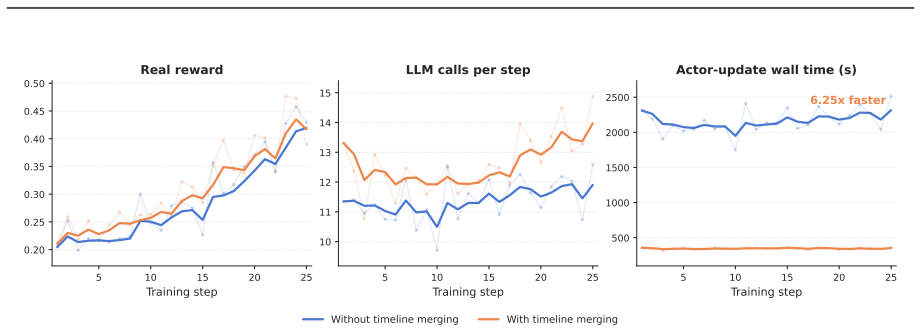
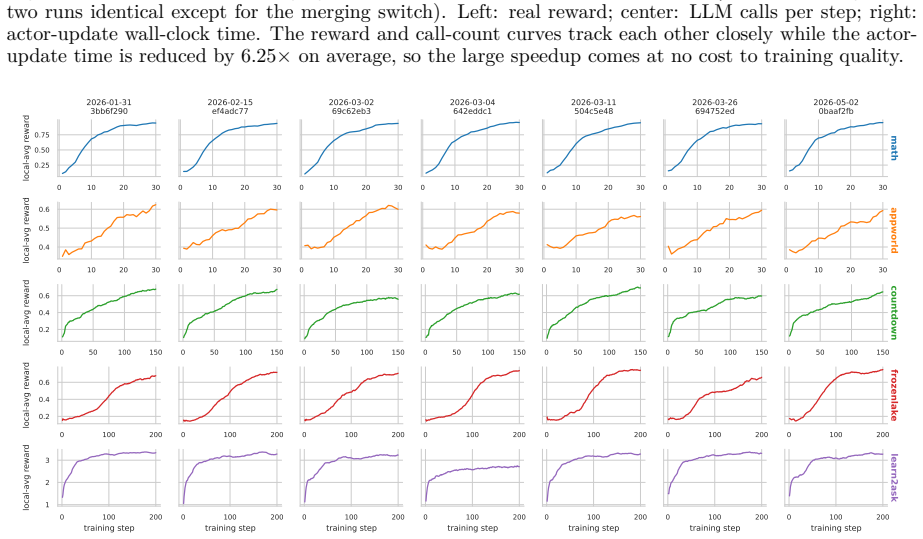
By using a decoupled multi-node architecture where swarm servers handle trainable models and optimization while clients run arbitrary agents on any devices, AgentJet supports heterogeneous multi-model reinforcement learning, multi-task cocktail training, fault-tolerant execution, and live code iteration. The context tracking module consolidates redundant context via timeline merging for training speedups, and the automated research system enables autonomous multi-day studies.
What carries the argument
Decoupled multi-node swarm architecture with server nodes for model optimization and client nodes for agent execution, plus a context tracking module with timeline merging.
If this is right
- Heterogeneous multi-agent teams with multiple different LLMs can be trained simultaneously.
- External failures in agent environments do not interrupt the overall training process.
- Agent code can be edited and updated while training is ongoing by swapping client nodes.
- An automated system can independently perform long-horizon RL research studies lasting multiple days.
Where Pith is reading between the lines
- This architecture could enable RL training on clusters with highly varied hardware types without custom adaptations.
- It might allow for more dynamic experimentation where researchers adjust agents on the fly during large-scale runs.
- The speedup from context merging suggests potential for similar techniques in other multi-turn agent training setups.
Load-bearing premise
The architecture maintains training efficiency and correctness when running across heterogeneous devices and arbitrary agent implementations without significant synchronization issues or context loss.
What would settle it
Running a training session where several client nodes experience failures and verifying whether the model optimization continues uninterrupted with the claimed performance gains.
Figures


read the original abstract
We present AgentJet, a distributed swarm training framework for large language model (LLM) agent reinforcement learning. Unlike centralized frameworks that tightly couple agent rollouts with model optimization, AgentJet adopts a decoupled multi-node architecture in which swarm server nodes host trainable models and run optimization on GPU clusters, whereas swarm client nodes execute arbitrary agents on arbitrary devices. This design provides capabilities that are difficult to support in centralized frameworks: (1) heterogeneous multi-model reinforcement learning, enabling the training of heterogeneous multi-agent teams with multiple LLM as brains; (2) multi-task cocktail training with isolated agent runtimes; (3) fault-tolerant execution that prevents external environment failures from interrupting the training process; and (4) live code iteration, which allows agents to be edited during training by replacing swarm client nodes. To support efficient RL in multi-model, multi-turn, and multi-agent settings, AgentJet introduces a context tracking module with timeline merging, which consolidates redundant context and achieves a 1.5-10x training speedup. Finally, AgentJet introduces an automated research system that takes a research topic as input and autonomously conducts long-horizon, multi-day RL studies on large-scale clusters. By leveraging the swarm architecture, this system reproduces key exploratory workflows of RL researchers without human intervention during execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AgentJet, a distributed swarm training framework for LLM-based agent reinforcement learning. It proposes a decoupled multi-node architecture separating swarm server nodes (hosting trainable models and performing optimization on GPU clusters) from swarm client nodes (executing arbitrary agents on heterogeneous devices). The design is claimed to enable heterogeneous multi-model RL, multi-task cocktail training, fault-tolerant execution, live code iteration during training, and an automated research system for autonomous long-horizon RL studies. A context tracking module with timeline merging is introduced to consolidate redundant context and deliver 1.5-10x training speedups in multi-model, multi-turn, and multi-agent settings.
Significance. If the architecture delivers the claimed capabilities and speedups without offsetting synchronization or context-loss overheads, AgentJet would address practical limitations of centralized frameworks in agentic RL, particularly for heterogeneous teams, fault tolerance, and live iteration. The automated research system, if validated, could meaningfully advance autonomous RL experimentation on large clusters. The timeline-merging mechanism for context efficiency represents a potentially useful systems contribution if its performance claims hold under realistic workloads.
major comments (3)
- [Abstract / Architecture] Abstract and architecture description: The central claims of 1.5-10x speedup via timeline merging, fault tolerance without context loss, and autonomous reproduction of multi-day researcher workflows rest on unshown evidence. No measurements of inter-node communication volume, no analysis of gradient staleness or reward variance versus centralized baselines, and no evaluation of state preservation under partial failures are provided, which directly undermines assessment of whether the decoupled server/client split realizes the stated benefits.
- [Context tracking module] Context tracking module description: The timeline merging approach is asserted to consolidate redundant context while preserving multi-turn/multi-agent state, yet no formal specification, pseudocode, or empirical study of correctness under node failures or heterogeneous runtimes is given. This is load-bearing for the efficiency and correctness claims of the overall framework.
- [Automated research system] Automated research system section: The claim that the system 'reproduces key exploratory workflows of RL researchers without human intervention' and conducts long-horizon studies is presented without any workflow traces, success metrics, or comparison to human-driven baselines, leaving the autonomy and reliability assertions unverified.
minor comments (2)
- The manuscript would benefit from explicit comparison tables or diagrams contrasting AgentJet against representative centralized frameworks (e.g., on supported heterogeneity and failure modes).
- Notation for client/server roles and context timelines should be introduced with a small example to improve readability for readers unfamiliar with swarm-style systems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional empirical detail and formalization would strengthen the manuscript. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Abstract / Architecture] Abstract and architecture description: The central claims of 1.5-10x speedup via timeline merging, fault tolerance without context loss, and autonomous reproduction of multi-day researcher workflows rest on unshown evidence. No measurements of inter-node communication volume, no analysis of gradient staleness or reward variance versus centralized baselines, and no evaluation of state preservation under partial failures are provided, which directly undermines assessment of whether the decoupled server/client split realizes the stated benefits.
Authors: We agree that the current presentation would benefit from explicit quantitative support for these claims. In the revised manuscript we will add a dedicated experimental subsection reporting inter-node communication volumes, gradient staleness and reward-variance comparisons against centralized baselines, and fault-injection results measuring state preservation under partial node failures. These additions will be placed in the evaluation section to directly address the decoupled architecture's practical benefits. revision: yes
-
Referee: [Context tracking module] Context tracking module description: The timeline merging approach is asserted to consolidate redundant context while preserving multi-turn/multi-agent state, yet no formal specification, pseudocode, or empirical study of correctness under node failures or heterogeneous runtimes is given. This is load-bearing for the efficiency and correctness claims of the overall framework.
Authors: We acknowledge that a formal treatment of the timeline-merging mechanism is required. The revision will include a precise algorithmic specification, pseudocode in an appendix, and new experiments evaluating correctness and overhead under simulated node failures and heterogeneous client runtimes. This material will be integrated into the context-tracking-module section. revision: yes
-
Referee: [Automated research system] Automated research system section: The claim that the system 'reproduces key exploratory workflows of RL researchers without human intervention' and conducts long-horizon studies is presented without any workflow traces, success metrics, or comparison to human-driven baselines, leaving the autonomy and reliability assertions unverified.
Authors: We agree that the autonomy claims need concrete validation. The revised section will incorporate representative workflow traces, quantitative success metrics (completion rates, study duration), and, where possible, side-by-side comparisons with human-driven baselines. These additions will substantiate the reliability of the automated research system. revision: yes
Circularity Check
No circularity: system architecture paper with no derivations or equations
full rationale
The paper is a descriptive account of a distributed training framework. It contains no equations, no fitted parameters, no mathematical derivations, and no load-bearing claims that reduce to self-citations or self-definitions. All capabilities (heterogeneous RL, fault tolerance, timeline merging, automated research) are presented as direct consequences of the described client-server split and context module; none are obtained by renaming or re-deriving prior results within the paper itself. The work is therefore self-contained as an engineering description and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AReaL: A large-scale asynchronous reinforce- ment learning system for language reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. AReaL: A large-scale asynchronous reinforce- ment learning system for language reasoning. arXiv preprint arXiv:2505.24298 ,
-
[2]
AgentScope: A flexible yet robust multi-agent platform
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, Liuyi Yao, Hongyi Peng, Zeyu Zhang, Lin Zhu, Chen Cheng, Hongzhu Shi, Yaliang Li, Bolin Ding, and Jingren Zhou. AgentScope: A flexible yet robust multi-agent platform. arXiv preprint arXiv:2402.14034 ,
-
[3]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, et al. Towards an AI co-scientist. arXiv preprint arXiv:2502.18864 ,
-
[4]
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948 ,
-
[5]
OpenRLHF: An easy-to-use, scalable and high-performance RLHF frame- work
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, et al. OpenRLHF: An easy-to-use, scalable and high-performance RLHF frame- work. arXiv preprint arXiv:2405.11143 ,
-
[6]
The AI scientist: Towards fully automated open-ended scientific discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292 ,
-
[7]
Xufang Luo, Yuge Zhang, Zhiyuan He, Zilong Wang, Siyun Zhao, Dongsheng Li, Luna K. Qiu, and Yuqing Yang. Agent lightning: Train ANY AI agents with reinforcement learning. arXiv preprint arXiv:2508.03680,
-
[8]
OpenAI is throwing everything into building a fully au- tomated researcher
MIT Technology Review. OpenAI is throwing everything into building a fully au- tomated researcher. https://www.technologyreview.com/2026/03/20/1134438/ openai-is-throwing-everything-into-building-a-fully-automated-researcher/ ,
2026
-
[9]
Qwen, An Yang, Baosong Yang, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 ,
-
[10]
AgentRxiv: Towards collaborative autonomous research
Samuel Schmidgall and Michael Moor. AgentRxiv: Towards collaborative autonomous research. arXiv preprint arXiv:2503.18102 ,
-
[11]
Proximal policy optimization algorithms
24 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 ,
-
[12]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 ,
-
[13]
HybridFlow: A flexible and efficient RLHF framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Lian, et al. HybridFlow: A flexible and efficient RLHF framework. arXiv preprint arXiv:2409.19256 ,
-
[14]
AI-Researcher: Autonomous scientific innovation
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. AI-Researcher: Autonomous scientific innovation. arXiv preprint arXiv:2505.18705 ,
-
[15]
Thinking Machines Lab
NeurIPS 2025 Spotlight. Thinking Machines Lab. Tinker: A low-level training api for distributed LLM fine-tuning. https: //thinkingmachines.ai/tinker/,
2025
-
[16]
OpenClaw-RL: Train any agent simply by talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. OpenClaw-RL: Train any agent simply by talking. arXiv preprint arXiv:2603.10165 ,
-
[17]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv preprint arXiv:2308.08155,
-
[18]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Wang, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
-
[19]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
-
[20]
OpenTinker: Separating concerns in agentic reinforcement learning
Siqi Zhu and Jiaxuan You. OpenTinker: Separating concerns in agentic reinforcement learning. arXiv preprint arXiv:2601.07376 ,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.