Plan First, Judge Later, Run Better: A DMAIC-Inspired Agentic System for Industrial Anomaly Detection
Pith reviewed 2026-06-28 06:29 UTC · model grok-4.3
The pith
A DMAIC-inspired multi-agent system for industrial anomaly detection improves performance 37.76 percent by generating and ranking strategies before any execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
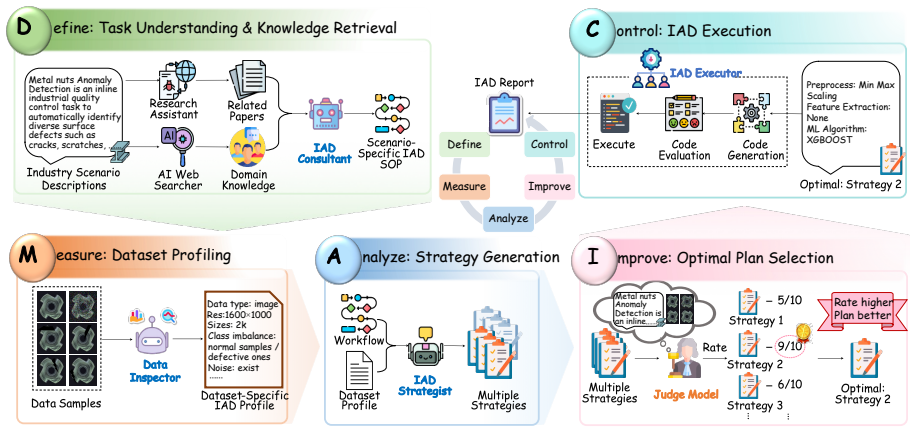
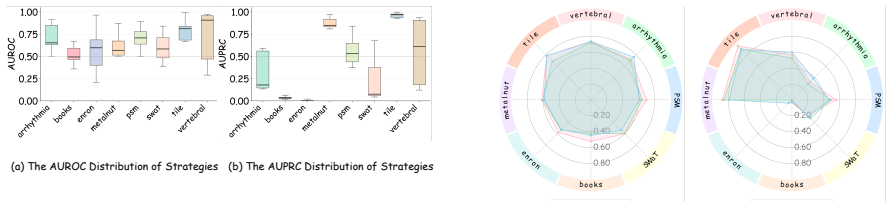
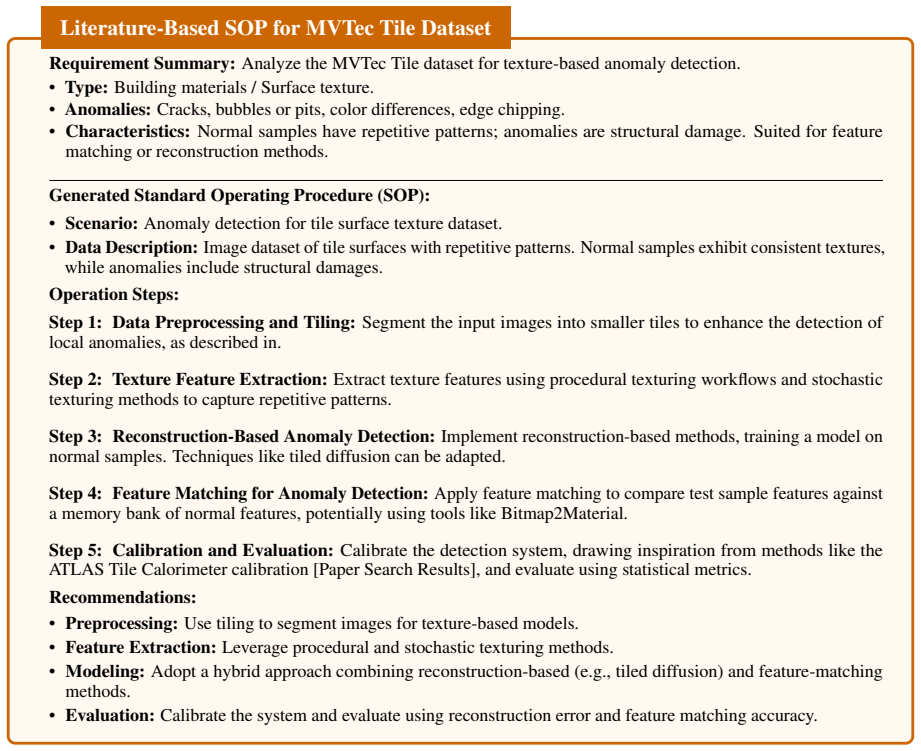
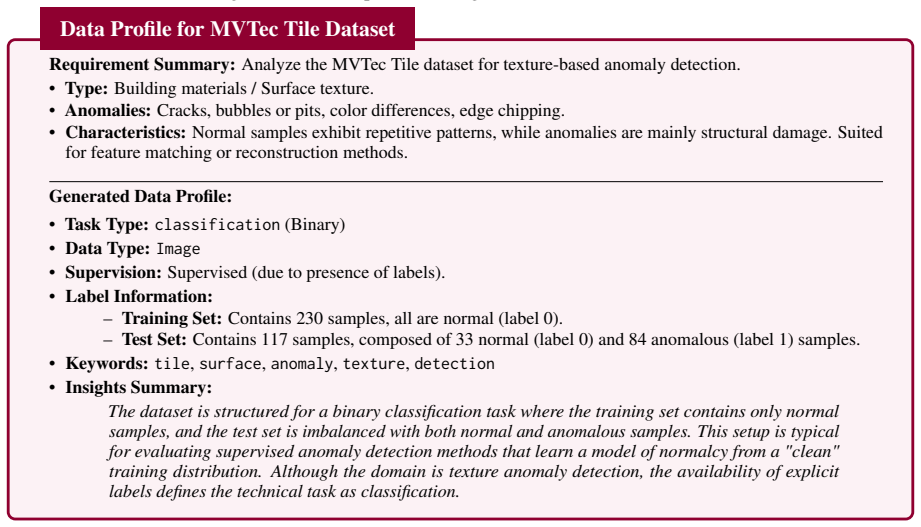
DMAIC-IAD distills heterogeneous references into standardized operating procedures before strategy generation and introduces a pre-trained execution-free judge model to rank candidate strategies without costly runtime trials, resulting in a 37.76 percent improvement in average detection performance across four modalities over applicable agentic baselines.
What carries the argument
The execution-free judge model that ranks strategies produced from SOPs distilled from references, allowing selection without runtime execution trials.
If this is right
- The system can handle multiple sensor and image modalities within one workflow instead of requiring separate models.
- Computational cost drops because only the highest-ranked strategy is executed rather than testing every candidate.
- LLM agents become more compatible with existing industrial quality frameworks such as DMAIC.
- Detection reliability increases in high-stakes manufacturing environments where strategy errors carry safety or cost penalties.
Where Pith is reading between the lines
- The planning-before-execution separation may transfer to other agentic tasks that currently rely on repeated runtime trials.
- Pre-trained judges could serve as a general substitute for expensive trial-and-error loops in broader LLM agent design.
- If the SOP distillation step proves sufficient on its own, the judge component might be removable without losing most of the gain.
Load-bearing premise
Distilling heterogeneous references into SOPs and using a pre-trained execution-free judge model can reliably rank candidate strategies without runtime execution trials.
What would settle it
An ablation study in which the judge model is replaced by random ranking or by full execution-based evaluation and the 37.76 percent gain disappears would falsify the central claim.
Figures



read the original abstract
Large language model (LLM) agents have shown promise in automating complex data-analysis workflows, but their reliable deployment remains challenging in high-stakes industrial scenarios. Industrial anomaly detection (IAD) is essential for manufacturing quality, safety, and efficiency, yet existing LLM-based IAD agents mainly focus on execution while under-exploiting strategy formulation. Consequently, they struggle to handle heterogeneous modalities in a unified and cost-effective manner. Inspired by the DMAIC quality-management framework, we propose DMAIC-IAD (DMAIC-inspired Agentic Industrial Anomaly Detection), a "Plan First, Judge Later" multi-agent system that aligns LLM agents with structured industrial problem-solving. DMAIC-IAD distills heterogeneous references into standardized operating procedures (SOPs) before strategy generation, and introduces a pre-trained execution-free judge model to rank candidate strategies without costly runtime trials. Extensive experiments across four modalities show that DMAIC-IAD improves average detection performance over applicable agentic baselines by 37.76%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DMAIC-IAD, a multi-agent system for industrial anomaly detection (IAD) inspired by the DMAIC quality framework. It distills heterogeneous references into standardized operating procedures (SOPs) prior to strategy generation and introduces a pre-trained execution-free judge model to rank candidate strategies without runtime execution trials, claiming a 37.76% average improvement in detection performance over applicable agentic baselines across four modalities.
Significance. If the empirical performance claim holds under rigorous validation, the work could advance structured planning and judgment mechanisms in LLM agents for high-stakes IAD applications, potentially improving cost-effectiveness and handling of modality heterogeneity. The explicit use of SOP distillation and an execution-free judge offers a concrete operationalization of 'Plan First, Judge Later' that could be tested in other domains.
major comments (2)
- [Experiments (performance tables and judge evaluation)] The central claim (37.76% average improvement) rests on the judge model's ability to rank strategies without execution; however, no evidence is provided that the judge's rankings correlate with actual end-to-end IAD detection performance (e.g., via hold-out runtime trials or correlation analysis between judge scores and observed metrics). This directly affects attribution of the gain to the proposed mechanism rather than to other factors such as SOP quality or baseline selection.
- [Abstract and Experiments section] No modality-specific results, baseline definitions, statistical significance tests, or error bars are reported for the 37.76% figure, preventing evaluation of whether the average improvement is driven by a subset of modalities or is robust.
minor comments (2)
- [Abstract] The abstract states the performance claim without any supporting experimental details; moving a concise summary of baselines and validation approach to the abstract would improve readability.
- [Method] Notation for the judge model (e.g., input features, training objective) should be defined explicitly in the method section to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Experiments (performance tables and judge evaluation)] The central claim (37.76% average improvement) rests on the judge model's ability to rank strategies without execution; however, no evidence is provided that the judge's rankings correlate with actual end-to-end IAD detection performance (e.g., via hold-out runtime trials or correlation analysis between judge scores and observed metrics). This directly affects attribution of the gain to the proposed mechanism rather than to other factors such as SOP quality or baseline selection.
Authors: We agree that explicit validation of the judge model's predictive power is necessary to attribute performance gains specifically to the execution-free ranking mechanism. The original manuscript reports overall improvements but does not include correlation analysis or hold-out trials linking judge scores to runtime metrics. In the revised version we will add a dedicated analysis subsection that computes Pearson/Spearman correlations and reports results from hold-out runtime trials, thereby clarifying the contribution of the judge component. revision: yes
-
Referee: [Abstract and Experiments section] No modality-specific results, baseline definitions, statistical significance tests, or error bars are reported for the 37.76% figure, preventing evaluation of whether the average improvement is driven by a subset of modalities or is robust.
Authors: We acknowledge that the reported average improvement requires supporting detail for proper assessment. The manuscript presents the 37.76% figure as an aggregate across four modalities without per-modality tables, explicit baseline specifications, significance testing, or variability measures. We will revise the Experiments section to include modality-specific performance tables, precise baseline definitions, statistical significance tests (e.g., paired t-tests with p-values), and error bars (standard deviation across multiple runs) for all reported metrics. revision: yes
Circularity Check
No circularity; empirical performance claim is self-contained
full rationale
The paper reports an empirical average improvement of 37.76% measured across four modalities against agentic baselines. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on direct experimental comparison rather than any reduction to inputs by construction, satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yajie Cui, Zhaoxiang Liu, and Shiguo Lian
Anomaly detection: A survey.ACM comput- ing surveys (CSUR), 41(3):1–58. Yajie Cui, Zhaoxiang Liu, and Shiguo Lian. 2023. A survey on unsupervised anomaly detection algo- rithms for industrial images.IEEE Access, 11:55297– 55315. Jeroen De Mast and Joran Lokkerbol. 2012. An analysis of the six sigma dmaic method from the perspective of problem solving.Inte...
arXiv 2023
-
[2]
Zhuo Li, Yuhao Yan, Xiangheng Wang, Yifei Ge, and Lin Meng
A survey on llm-based multi-agent sys- tems: workflow, infrastructure, and challenges.Vici- nagearth, 1(1):9. Zhuo Li, Yuhao Yan, Xiangheng Wang, Yifei Ge, and Lin Meng. 2025. A survey of deep learning for indus- trial visual anomaly detection.Artificial Intelligence Review, 58(9):279. Jiaxin Liang, Haotian Miao, Kai Li, Jianheng Tan, Xi Wang, Rui Luo, an...
2025
-
[3]
Jianming Lv, Yaquan Wang, and Shengjing Chen
Bond: Benchmarking unsupervised outlier node detection on static attributed graphs.Advances in Neural Information Processing Systems, 35:27021– 27035. Jianming Lv, Yaquan Wang, and Shengjing Chen
-
[4]
Stephen DJ McArthur, Campbell D Booth, JR Mc- Donald, and Ian T McFadyen
Adaptive multivariate time-series anomaly detection.Information Processing & Management, 60(4):103383. Stephen DJ McArthur, Campbell D Booth, JR Mc- Donald, and Ian T McFadyen. 2005. An agent- based anomaly detection architecture for condition monitoring.IEEE Transactions on Power Systems, 20(4):1675–1682. Junwen Miao, Penghui Du, Yi Liu, Yu Wang, and Yan...
Pith/arXiv arXiv 2005
-
[5]
Zhenkai Qin, Qining Luo, Xunyi Nong, Xiaolong Chen, Hongfeng Zhang, and Cora Un In Wong
A multimodal anomaly detector for robot- assisted feeding using an lstm-based variational au- toencoder.IEEE Robotics and Automation Letters, 3(3):1544–1551. Zhenkai Qin, Qining Luo, Xunyi Nong, Xiaolong Chen, Hongfeng Zhang, and Cora Un In Wong. 2025. Mas- lstm: A multi-agent lstm-based approach for scal- able anomaly detection in iiot networks.Processes...
arXiv 2025
-
[6]
Julian Wyatt, Adam Leach, Sebastian M Schmon, and Chris G Willcocks
Deep time series models: A comprehensive survey and benchmark.IEEE Transactions on Pat- tern Analysis and Machine Intelligence. Julian Wyatt, Adam Leach, Sebastian M Schmon, and Chris G Willcocks. 2022. Anoddpm: Anomaly detec- tion with denoising diffusion probabilistic models us- ing simplex noise. InProceedings of the IEEE/CVF conference on computer vis...
2022
-
[7]
task_type
uses LVM for multi-stage visual inspection. Besides, LEMAD (Ji et al., 2025b) proposes a multi-agent system for Power Grid Services to pro- cess log anomaly detection. PARAM (Harbola and Purwar, 2025)uses rag for data knowledge retrieval and utilizes a pretrained LLM to realize anomaly detection. These works use LLM as a specific pro- cessor without consi...
2025
-
[8]
Deep methods (AutoEncoder , VAE, DeepSVDD) are available for special cases where classic methods are insufficient
PyOD (Library: pyod) Applicable Data Type: Multivariate Tabular Data, Graph Data (after feature extraction) Description: Python Outlier Detection: a comprehensive library with 40+ anomaly detection algorithms For tabular/numeric data prefer classic, well- established methods: IsolationForest, LOF, OneClassSVM, COPOD, ECOD, ABOD, CBLOF, HBOS (fast and robu...
-
[9]
none"] and feature_extraction=[
TSLib (Library: tslib) - PREFERRED FOR TIME SERIES DATA Applicable Data Type: Time Series Data (msl, yahoo, psm, smap, smd, swat, etc.) Description: Deep learning library for time series developed by THUML. These models have built-in feature learning and do NOT require preprocessing or feature extraction steps. PRIORITY MODELS (use these first): - TimesNe...
-
[10]
Scikit-learn (Library: sklearn) Applicable Data Type: Tabular Data Description: General-purpose machine learning library Anomaly Detection Models: IsolationForest, LocalOutlierFactor, OneClassSVM, EllipticEnvelope For Classification Tasks (task_type: classification, multi_class_classification, multi_label_classification) Scikit-learn (Library: sklearn) Ap...
-
[11]
Each category (data_preprocessing, feature_extraction, anomaly_algorithm) must use EXACTLY ONE method
-
[12]
At least ONE category must use a DIFFERENT method from previous variants
-
[13]
Parameter-only changes are NOT allowed - must change method names
-
[14]
ResNet/WideResNet patch features, PatchCore- style backbone)
Diversity in preprocessing/feature_extraction: Some variants MAY use alternatives (e.g. ResNet/WideResNet patch features, PatchCore- style backbone). Do NOT use YOLOv5/YOLOv8 or object detection models for image anomaly detection. You are a planner for a machine learning system. {intro} {context} {variant_guidance} {sop_middle_block} {efficiency_block} PLAN STEPS
-
[15]
none" is often enough when there are no special requirements. For time series with TSLib models: USE [
data_preprocessing: EXACTLY ONE method. You may use any preprocessing you deem appropriate (e.g. none, MinMaxScaler, StandardScaler, fill_median, or others). " none" is often enough when there are no special requirements. For time series with TSLib models: USE ["none"]
-
[16]
Image: PatchCore, CNN_backbone, pretrained CNN patch features (no YOLOv/object detection)
feature_extraction: EXACTLY ONE method. Image: PatchCore, CNN_backbone, pretrained CNN patch features (no YOLOv/object detection). Graph: graph_statistical_features. Tabular: PCA, statistical_features. Do NOT use PyGOD (pygod) for graphs. TSLib: USE ["none"]
-
[17]
metrics": [
anomaly_algorithm: EXACTLY ONE algorithm ( match task_type: supervised/unsupervised/ time_series). Use any algorithm you think suitable (e.g. from PyOD, sklearn, xgboost, tslib, darts, etc.). Step format: step_id, agent_type, order, dependencies, methods (EXACTLY ONE per category), method_params Output JSON (example with simple preprocessing/ extraction):...
-
[18]
Tensor - PyOD models: Use'decision_scores_'(plural ), returns numpy.ndarray - Example: anomaly_scores = model
PyGOD vs PyOD API Difference: - PyGOD models (e.g., DOMINANT): Use' decision_score_'(singular), returns torch. Tensor - PyOD models: Use'decision_scores_'(plural ), returns numpy.ndarray - Example: anomaly_scores = model. decision_score_ # for PyGOD - Example: anomaly_scores = model. decision_scores_ # for PyOD
-
[19]
PyOD AutoEncoder Parameter Names (CRITICAL): - PyOD AutoEncoder uses'hidden_neuron_list' (NOT'hidden_neurons') - PyOD AutoEncoder uses'epoch_num'(NOT' epochs') - PyOD AutoEncoder uses'lr'(NOT' learning_rate') - PyOD AutoEncoder uses'optimizer_name'(NOT 'optimizer') - PyOD AutoEncoder uses' hidden_activation_name'(NOT'activation'or 'hidden_activation') - C...
-
[20]
PyOD VAE Parameter Names (CRITICAL): - PyOD VAE uses'encoder_neuron_list'(NOT' encoder_neurons') - PyOD VAE uses'decoder_neuron_list'(NOT' decoder_neurons') - PyOD VAE uses'lr'(NOT'learning_rate') - Correct example: VAE(encoder_neuron_list =[32, 16], decoder_neuron_list=[16, 32], lr =0.001, epoch_num=100, contamination=0.05) - WRONG: VAE(encoder_neurons=[...
-
[21]
PyOD CBLOF beta parameter (CRITICAL): - CBLOF requires beta in range [1, 2147483647]
PyOD Models WITHOUT random_state (CRITICAL): - COPOD, HBOS, ECOD do NOT support' random_state'parameter - do NOT pass it - WRONG: COPOD(contamination=0.05, random_state=42) # TypeError - CORRECT: COPOD(contamination=0.05, n_jobs =-1) - CORRECT: HBOS(n_bins=10, contamination =0.05) - CORRECT: ECOD(contamination=0.1) 4b. PyOD CBLOF beta parameter (CRITICAL)...
-
[22]
PyOD ECOD contamination (CRITICAL): - ECOD'contamination'MUST be a float (e.g., 0.1), NOT the string'auto' - WRONG: ECOD(contamination='auto') # AttributeError:'str'object has no attribute'eval' - CORRECT: ECOD(contamination=0.1)
-
[23]
numpy() if torch.is_tensor(anomaly_scores): anomaly_scores = anomaly_scores.cpu()
PyTorch Tensor to NumPy Conversion (MANDATORY ): - PyGOD/PyTorch models return torch.Tensor, but numpy functions (np.sum, np.mean, etc.) require numpy arrays - ALWAYS convert tensors before using numpy functions: if torch.is_tensor(anomaly_labels): anomaly_labels = anomaly_labels.cpu(). numpy() if torch.is_tensor(anomaly_scores): anomaly_scores = anomaly_...
-
[24]
float64) if dtype mismatches occur {DATASET_SPECIFIC_SECTION} E) TRAIN-TEST SPLIT RULES CRITICAL: The dataloader already returns separated train_x, train_y, test_x, test_y
Data Type Consistency: - Ensure all arrays passed to sklearn functions have consistent dtypes (float32 or float64) - Convert PyTorch tensors to numpy before sklearn operations - Use .astype(np.float32) or .astype(np. float64) if dtype mismatches occur {DATASET_SPECIFIC_SECTION} E) TRAIN-TEST SPLIT RULES CRITICAL: The dataloader already returns separated t...
-
[25]
Merging and re-splitting would: - Cause data leakage (test data may contain training samples) - Break the original train/test distribution - Lead to incorrect evaluation results
NEVER merge train and test data then re-split: The dataloader has already separated the data. Merging and re-splitting would: - Cause data leakage (test data may contain training samples) - Break the original train/test distribution - Lead to incorrect evaluation results
-
[26]
Use train and test data separately: - For preprocessing: Fit scalers/ preprocessors on train_df, then transform test_df - For feature extraction: Fit extractors on train_df, then transform test_df - For training: Use processed train data only - For evaluation: Use processed test data only
-
[27]
The is_supervised flag determines how to handle labels: - is_supervised=True: Extract labels from train_df and test_df, use for supervised training/evaluation - is_supervised=False or None: Ignore labels (for unsupervised anomaly detection)
-
[28]
{ metrics_timestamp}
Label column identification: - All dataloaders return label column as' anomaly_label'(check for'anomaly_label', then'Normal/Attack', then'label', else use last column) - Extract labels from train_df and test_df separately: train_y = train_df[' anomaly_label'], test_y = test_df[' anomaly_label'] F) EVALUATION METRICS + JSON SAVE (MANDATORY) Metrics computa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.