Benchmarking Living-Screen-Native GUI Agents on Short-Video Platforms
Pith reviewed 2026-06-28 07:17 UTC · model grok-4.3
The pith
Current GUI agents cannot handle living screens on short-video platforms because none reach human cost-accuracy performance due to failures in observation control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that living-screen-native tasks on short-video platforms expose a gap in current GUI agents, with the LivingScreen benchmark demonstrating that models' dominant errors stem from improper observation lengths, preventing them from attaining human cost-accuracy performance.
What carries the argument
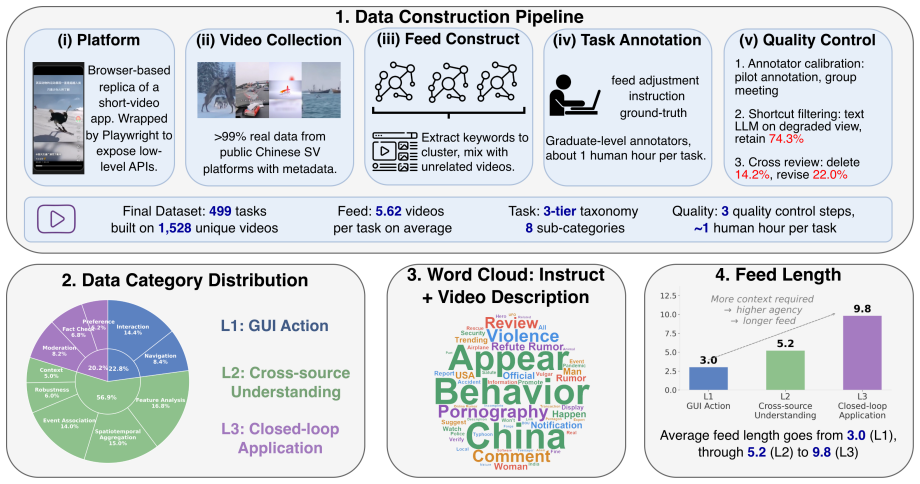
LivingScreen benchmark that supplies a browser-based environment, three-tier task suite, and joint accuracy-efficiency metrics to evaluate agents on dynamic short-video interfaces.
If this is right
- Observation control becomes a required capability axis for future GUI agents.
- Models must learn to decide when to stop observing to close the efficiency gap with humans.
- Over- and under-observation errors can be used as diagnostic signals for targeted agent improvements.
- The benchmark supplies a concrete standard for comparing agents on real dynamic interfaces.
Where Pith is reading between the lines
- Agents could gain from internal timers or predictive models that estimate content relevance over time.
- The same evaluation approach could apply to other continuous interfaces such as live streams or interactive media.
- Joint accuracy-efficiency metrics may become standard for measuring agent performance in time-sensitive apps.
Load-bearing premise
The browser-based environment together with the three-tier task suite and joint accuracy-efficiency metrics faithfully represent real short-video platform interactions without simulation artifacts that distort model comparisons.
What would settle it
A model equipped with explicit observation control that reaches or exceeds human cost-accuracy scores on the LivingScreen tasks.
Figures



read the original abstract
GUI agents today assume a static screen, where the world is frozen between two actions. However, real interfaces such as short-video applications violate this assumption, as their content keeps playing, and a competent user must decide what to watch and for how long. We formalize this task as Living-Screen-Native GUI agents and introduce LivingScreen, the first benchmark instantiating it on short-video platforms, with a faithful browser-based environment, a three-tier task suite, and metrics that jointly score accuracy and information efficiency. Evaluating extensive frontier models, we find that none reaches the human cost-accuracy performance, and that their dominant failure mode is over- and under-observation, pointing to observation control as a missing capability axis for future GUI agents. All data and code will be available at https://github.com/BITHLP/LivingScreen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'Living-Screen-Native GUI agents' to address dynamic, continuously updating interfaces (e.g., short-video platforms) that violate the static-screen assumption of prior GUI agents. It presents the LivingScreen benchmark, consisting of a browser-based environment, a three-tier task suite, and joint accuracy-efficiency metrics. Evaluation of frontier models shows none reach human cost-accuracy performance, with dominant failures in over- and under-observation, and concludes that observation control is a missing capability axis. All data and code are to be released.
Significance. If the benchmark environment and tasks are shown to faithfully reproduce native short-video dynamics, the work identifies a concrete, previously unmeasured limitation in GUI agents and supplies an open benchmark for future progress on observation control. The explicit release of data and code strengthens reproducibility.
major comments (2)
- [Abstract] Abstract: The central empirical claim that 'none reaches the human cost-accuracy performance' and that 'dominant failure mode is over- and under-observation' rests on the assertion of a 'faithful browser-based environment.' No validation (timing logs, content-equivalence checks, or latency comparisons against native apps) is described, which directly affects whether the reported observation failures can be attributed to model limitations rather than simulation artifacts.
- [Methodology / Evaluation] Task suite and human baseline (methodology section): Details on task construction, human baseline collection protocol, exclusion criteria, and statistical tests for the 'no model matches human' result are absent from the abstract and not verifiable here; without them the cross-model comparison and the claim that observation control is the primary gap cannot be assessed for robustness.
minor comments (1)
- [Abstract] The three-tier task suite is referenced but its precise definitions, difficulty progression, and relation to the joint accuracy-efficiency metric are not summarized in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional evidence and detail would strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that 'none reaches the human cost-accuracy performance' and that 'dominant failure mode is over- and under-observation' rests on the assertion of a 'faithful browser-based environment.' No validation (timing logs, content-equivalence checks, or latency comparisons against native apps) is described, which directly affects whether the reported observation failures can be attributed to model limitations rather than simulation artifacts.
Authors: We agree that the abstract asserts faithfulness without accompanying validation evidence. The full manuscript describes the browser-based environment but does not include the requested checks. In revision we will add an explicit validation subsection (or appendix) reporting timing logs, content-equivalence metrics, and latency comparisons against native apps to support the claim that observed failures are attributable to model behavior rather than simulation artifacts. revision: yes
-
Referee: [Methodology / Evaluation] Task suite and human baseline (methodology section): Details on task construction, human baseline collection protocol, exclusion criteria, and statistical tests for the 'no model matches human' result are absent from the abstract and not verifiable here; without them the cross-model comparison and the claim that observation control is the primary gap cannot be assessed for robustness.
Authors: The full manuscript contains a methodology section that describes the three-tier task suite and human baseline collection. However, these details are not summarized in the abstract and the statistical tests are not explicitly highlighted. We will revise by expanding the abstract or adding a concise methodology summary, and by reporting the human-collection protocol, exclusion criteria, and statistical tests used for the cross-model comparisons. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper is a benchmark study introducing LivingScreen for GUI agents on short-video platforms. It contains no equations, derivations, fitted parameters, or mathematical claims that could reduce to inputs by construction. Central claims rest on empirical evaluation of models in a described environment rather than any self-definitional, fitted-prediction, or self-citation-load-bearing steps. No load-bearing uniqueness theorems or ansatzes are invoked. This is a standard honest non-finding for an empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human cost-accuracy performance constitutes the appropriate reference point for evaluating agent competence on this task.
- domain assumption Joint scoring of accuracy and information efficiency is the right way to measure success for living-screen agents.
invented entities (1)
-
Living-Screen-Native GUI agents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[2]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[3]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[5]
Proceedings of the IEEE international conference on computer vision , pages=
Vqa: Visual question answering , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[6]
International Conference on Learning Representations , volume=
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. International Conference on Learning Representations , volume=
-
[7]
European Conference on Computer Vision , pages=
MMBench: Is Your Multi-modal Model an All-Around Player? , author=. European Conference on Computer Vision , pages=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Advances in Neural Information Processing Systems , volume=
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
International Conference on Learning Representations , volume=
Muirbench: A comprehensive benchmark for robust multi-image understanding , author=. International Conference on Learning Representations , volume=
-
[11]
Advances in Neural Information Processing Systems , volume=
Longvideobench: A benchmark for long-context interleaved video-language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
arXiv preprint arXiv:2508.19542 , year=
CVBench: Benchmarking Cross-Video Synergies for Complex Multimodal Reasoning , author=. arXiv preprint arXiv:2508.19542 , year=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Crossvid: A comprehensive benchmark for evaluating cross-video reasoning in multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
arXiv preprint arXiv:2601.15016 , year=
LiViBench: An Omnimodal Benchmark for Interactive Livestream Video Understanding , author=. arXiv preprint arXiv:2601.15016 , year=
-
[17]
International Conference on Learning Representations , volume=
Webarena: A realistic web environment for building autonomous agents , author=. International Conference on Learning Representations , volume=
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Advances in Neural Information Processing Systems , volume=
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2105.13231 , year=
Androidenv: A reinforcement learning platform for android , author=. arXiv preprint arXiv:2105.13231 , year=
-
[21]
International Conference on Learning Representations , volume=
Androidworld: A dynamic benchmarking environment for autonomous agents , author=. International Conference on Learning Representations , volume=
-
[22]
arXiv preprint arXiv:2401.16158 , year=
Mobile-agent: Autonomous multi-modal mobile device agent with visual perception , author=. arXiv preprint arXiv:2401.16158 , year=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cogagent: A visual language model for gui agents , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
International Conference on Learning Representations , volume=
OS-ATLAS: Foundation action model for generalist GUI agents , author=. International Conference on Learning Representations , volume=
-
[25]
arXiv preprint arXiv:2501.12326 , year=
Ui-tars: Pioneering automated gui interaction with native agents , author=. arXiv preprint arXiv:2501.12326 , year=
-
[26]
arXiv preprint arXiv:2508.15144 , year=
Mobile-agent-v3: Fundamental agents for gui automation , author=. arXiv preprint arXiv:2508.15144 , year=
-
[27]
5: Multi-platform fundamental gui agents , author=
Mobile-agent-v3. 5: Multi-platform fundamental gui agents , author=. arXiv preprint arXiv:2602.16855 , year=
-
[28]
arXiv preprint arXiv:2512.23044 , year=
Video-browsecomp: Benchmarking agentic video research on open web , author=. arXiv preprint arXiv:2512.23044 , year=
-
[29]
arXiv e-prints , pages=
Videodeepresearch: Long video understanding with agentic tool using , author=. arXiv e-prints , pages=
-
[30]
Advances in Neural Information Processing Systems , volume=
Deep video discovery: Agentic search with tool use for long-form video understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Videotree: Adaptive tree-based video representation for llm reasoning on long videos , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[32]
Playwright: Fast and reliable end-to-end testing for modern web apps , year =
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
FakeSV: A Multimodal Benchmark with Rich Social Context for Fake News Detection on Short Video Platforms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[34]
Shuming Ma and Lei Cui and Damai Dai and Furu Wei and Xu Sun , title =
-
[35]
arXiv preprint arXiv:2505.11842 , year=
Video-SafetyBench: A Benchmark for Safety Evaluation of Video LVLMs , author=. arXiv preprint arXiv:2505.11842 , year=
-
[36]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[37]
, author=
Information foraging. , author=. Psychological review , volume=. 1999 , publisher=
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.