Auditing CoT Answer-Hijack Patches: Source-Control Certificates with Type-I Guarantees
Pith reviewed 2026-06-28 05:58 UTC · model grok-4.3
The pith
A three-stage audit turns activation patches into source-control certificates with Type-I error bounds at alpha_sel plus alpha_audit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The certificate emits an incorrect mechanism label with probability at most alpha = alpha_sel + alpha_audit under sample-split disjointness, with matching-rate sample complexity n_star = Theta(Delta^{-2} log(1/alpha)).
What carries the argument
The three-stage procedure of SELECT (clean-source band sweep with permutation calibration and held-out validation), FREEZE (lock the hook), and AUDIT (paired-bootstrap source contrasts at the frozen hook).
If this is right
- On Qwen2.5-7B and Llama3-8B, three few-shot/puzzle cells pass confirmatory K=1 localization with held-out gaps of +32.6, +45.1, and +17.7.
- Fixed-hook reruns recover 47.0 percent on Qwen-puzzle and 39.0 percent on Llama3-puzzle at n=100.
- Frozen MATH-500 transfer recovers 26.0 percent.
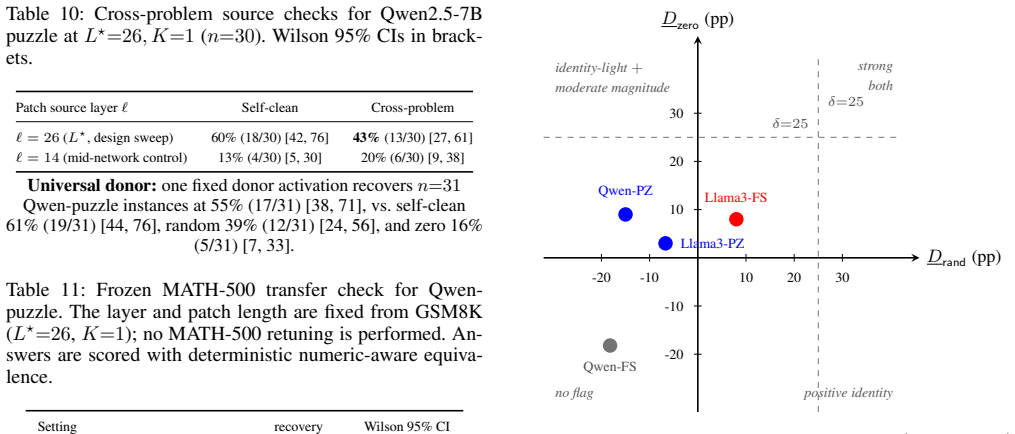
- After audit, Llama3-PZ and Qwen-PZ are identity-light with moderate magnitude while Llama3-FS remains a single-seed moderate-positive candidate.
Where Pith is reading between the lines
- The same audit template could be applied to other patching techniques to make localization claims statistically comparable across papers.
- Repeating the protocol on larger model families would test whether source-control certificates remain stable as scale increases.
- Embedding the audit inside existing interpretability toolkits would let practitioners reject unverified mechanism labels before publication.
Load-bearing premise
Permutation calibration in the SELECT stage combined with sample-split disjointness between SELECT and AUDIT stages produces a valid overall Type-I guarantee.
What would settle it
Apply the full three-stage procedure to a controlled dataset whose true source mechanism is already known and check whether the observed rate of incorrect labels stays below alpha.
Figures

read the original abstract
Chain-of-thought (CoT) answer-hijack templates can flip the final numeric answer of a 7B-8B language model on GSM8K or MATH-500 even when the visible reasoning trace looks fluent. Activation patching is the standard probe for locating where this hijack can be undone, and a successful clean-source patch is often read as evidence that the patched activation carries the recovered content. We show that this reading is unsound: clean-only localization profiles (peak, spread, thresholded band) underidentify the frozen-hook source contrast, and the clean-only profile is an intervention map, not a mediation certificate. We then construct an audit that turns each candidate patch into a source-control certificate with a pre-registered Type-I guarantee. The certificate runs in three stages: SELECT (clean-source band sweep with permutation calibration and held-out validation), FREEZE (lock the hook), and AUDIT (paired-bootstrap source contrasts at the frozen hook). It emits an incorrect mechanism label with probability at most alpha = alpha_sel + alpha_audit under sample-split disjointness. A matching-rate sample-complexity theorem (n_star = Theta(Delta^{-2} log(1/alpha))) bounds the audit cost. On Qwen2.5-7B and Llama3-8B, three few-shot/puzzle cells pass confirmatory K=1 localization with held-out gaps +32.6, +45.1, +17.7; fixed-hook reruns recover 47.0% (Qwen-puzzle) and 39.0% (Llama3-puzzle) at n=100; frozen MATH-500 transfer recovers 26.0%. After audit, Llama3-PZ and Qwen-PZ are identity-light with moderate magnitude (Qwen-PZ also layer-sensitive); Llama3-FS is a single-seed moderate-positive candidate (multi-seed replication queued); Qwen-FS is exploratory non-separation with a layer-sensitive flag. The method is a diagnostic auditing protocol, not an adaptive safety defense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that clean-only activation patching profiles underidentify the source contrast in CoT answer-hijack localization for 7B-8B LLMs on GSM8K/MATH-500, rendering them unsound as mediation certificates. It introduces a three-stage auditing protocol (SELECT with permutation calibration and held-out validation, FREEZE to lock the hook, AUDIT with paired-bootstrap contrasts) that issues source-control certificates with Type-I error control: the probability of an incorrect mechanism label is at most alpha = alpha_sel + alpha_audit under sample-split disjointness. A matching-rate sample-complexity theorem states n_star = Theta(Delta^{-2} log(1/alpha)). Experiments report confirmatory localization in three cells with held-out gaps of +32.6, +45.1, +17.7; recovery rates of 47.0% (Qwen-puzzle) and 39.0% (Llama3-puzzle) at n=100; 26.0% MATH-500 transfer; and post-audit characterizations of the passing cells.
Significance. If the Type-I guarantee and sample-complexity bound hold, the work supplies a statistically grounded auditing protocol that could elevate standards in mechanistic interpretability by replacing heuristic localization with certified source control. The explicit error-rate decomposition and practical recovery numbers on two model families are concrete strengths; the method is positioned as a diagnostic rather than a defense, which aligns with its scope.
major comments (1)
- [Abstract / Theorem statement] The central Type-I guarantee (probability of incorrect label ≤ alpha_sel + alpha_audit) and the sample-complexity theorem n_star = Theta(Delta^{-2} log(1/alpha)) are stated in the abstract and introduction, but the manuscript supplies neither the derivation steps nor the explicit assumptions (e.g., conditions on permutation calibration validity and the union bound under disjoint SELECT/AUDIT splits) needed to substantiate them. This is load-bearing for the primary claim.
minor comments (3)
- [Experiments] Recovery percentages (47.0%, 39.0%, 26.0%) are reported without error bars, confidence intervals, or baseline comparisons against random or non-audited patching; adding these would strengthen the experimental section.
- [Methods] The notation alpha_sel and alpha_audit is used before being defined; a single consolidated definition paragraph early in the methods would improve clarity.
- [Experiments] The description of the three few-shot/puzzle cells that pass confirmatory K=1 localization would benefit from explicit listing of the exact prompts or puzzle templates used.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the load-bearing nature of the Type-I guarantee and sample-complexity result. We agree that explicit derivation and assumptions are required and will revise the manuscript to include them.
read point-by-point responses
-
Referee: [Abstract / Theorem statement] The central Type-I guarantee (probability of incorrect label ≤ alpha_sel + alpha_audit) and the sample-complexity theorem n_star = Theta(Delta^{-2} log(1/alpha)) are stated in the abstract and introduction, but the manuscript supplies neither the derivation steps nor the explicit assumptions (e.g., conditions on permutation calibration validity and the union bound under disjoint SELECT/AUDIT splits) needed to substantiate them. This is load-bearing for the primary claim.
Authors: We agree with the referee that the derivation steps and explicit assumptions must be supplied. The current manuscript states the Type-I bound alpha = alpha_sel + alpha_audit and the matching-rate theorem but omits the full proof. In revision we will insert a new subsection (in Methods or Appendix) that (i) derives the error decomposition from the disjoint SELECT/AUDIT splits, (ii) states the exchangeability assumption required for permutation calibration to control alpha_sel, (iii) applies the union bound across the two stages, and (iv) specifies the conditions (bounded variance of the bootstrap contrast, minimum effect size Delta) under which n_star = Theta(Delta^{-2} log(1/alpha)) holds. This directly substantiates the primary claim. revision: yes
Circularity Check
No significant circularity; derivation relies on standard statistical primitives
full rationale
The paper's central claim is a Type-I error bound alpha = alpha_sel + alpha_audit for a three-stage SELECT-FREEZE-AUDIT procedure that uses permutation calibration in SELECT and paired-bootstrap contrasts in AUDIT, together with sample-split disjointness. The matching-rate sample complexity n_star = Theta(Delta^{-2} log(1/alpha)) is the standard form of a concentration inequality and is not derived from any fitted parameter or self-referential definition inside the paper. No self-citation is invoked as a load-bearing uniqueness theorem, no ansatz is smuggled via prior work, and no prediction is obtained by renaming a fitted input. The procedure is therefore self-contained against external statistical benchmarks (permutation tests and bootstrap) whose validity does not reduce to quantities constructed within the present manuscript.
Axiom & Free-Parameter Ledger
free parameters (2)
- alpha
- Delta
axioms (2)
- standard math Independence assumptions required for permutation calibration and paired bootstrap to control Type-I error
- domain assumption Sample splits between SELECT and AUDIT stages remain disjoint
invented entities (1)
-
source-control certificate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.26418 , year=
Chain-of-Thought Hijacking , author=. arXiv preprint arXiv:2510.26418 , year=
-
[2]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in. 2022 , note=
2022
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author =. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
International Conference on Learning Representations (ICLR) , year=
Towards Understanding Sycophancy in Language Models , author =. International Conference on Learning Representations (ICLR) , year=
-
[7]
arXiv preprint arXiv:2308.10248 , year=
Steering Language Models With Activation Engineering , author =. arXiv preprint arXiv:2308.10248 , year=
-
[8]
Transformer Circuits Thread , year=
In-context Learning and Induction Heads , author =. Transformer Circuits Thread , year=
-
[9]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year=
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[11]
International Conference on Learning Representations (ICLR) , year=
Mass-Editing Memory in a Transformer , author =. International Conference on Learning Representations (ICLR) , year=
-
[12]
arXiv preprint arXiv:2310.01405 , year=
Representation Engineering: A Top-Down Approach to AI Transparency , author =. arXiv preprint arXiv:2310.01405 , year=
-
[13]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Wang, Kevin Ro and Variengien, Alexandre and Conmy, Arthur and others , booktitle=. Interpretability in the Wild: a Circuit for Indirect Object Identification in. 2023 , note=
2023
-
[14]
International Conference on Machine Learning (ICML) , year=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author =. International Conference on Machine Learning (ICML) , year=
-
[15]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[17]
arXiv preprint arXiv:2407.21783 , year=
The. arXiv preprint arXiv:2407.21783 , year=
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Improving Alignment and Robustness with Circuit Breakers , author =. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[19]
arXiv preprint arXiv:2307.13702 , year=
Measuring Faithfulness in Chain-of-Thought Reasoning , author =. arXiv preprint arXiv:2307.13702 , year=
-
[20]
arXiv preprint arXiv:2410.06672 , year=
Studying Mechanistic Similarity Across Language Model Architectures , author=. arXiv preprint arXiv:2410.06672 , year=
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) Position Paper Track , year=
Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces! , author=. Advances in Neural Information Processing Systems (NeurIPS) Position Paper Track , year=
-
[22]
arXiv preprint arXiv:2507.16407 , year =
Lin, Shuzheng and Du, Xiaodong and Wang, Tao and others , title =. arXiv preprint arXiv:2507.16407 , year =
-
[23]
arXiv preprint arXiv:2307.15043 , year =
Zou, Andy and Wang, Zifan and Carlini, Nicholas and others , title =. arXiv preprint arXiv:2307.15043 , year =
-
[24]
Knowledge Editing in Language Models , author=
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[25]
2026 , note=
Huang, Zhengxian and Zhu, Wenjun and Qiu, Haoxuan and Ji, Xiaoyu and Xu, Wenyuan , journal=. 2026 , note=
2026
-
[26]
arXiv preprint arXiv:2603.28817 , year=
Token Activation-Based Defense Against Jailbreak Attacks for Small Language Models , author=. arXiv preprint arXiv:2603.28817 , year=
-
[27]
2025 , note=
Zhang, Shenyi and others , booktitle=. 2025 , note=
2025
-
[28]
arXiv preprint arXiv:2601.15801 , year=
Attributing and Exploiting Safety Vectors through Global Optimization in Large Language Models , author =. arXiv preprint arXiv:2601.15801 , year=
-
[29]
Not Just
Kumarappan, Adarsh and Mujoo, Ananya , journal=. Not Just. 2026 , note=
2026
-
[30]
arXiv preprint arXiv:2501.16497 , year=
Smoothed Embeddings for Robust Language Models , author=. arXiv preprint arXiv:2501.16497 , year=
-
[31]
arXiv preprint arXiv:2508.02087 , year=
Uncovering the Internal Origins of Sycophancy in Large Language Models , author=. arXiv preprint arXiv:2508.02087 , year=
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Causal Abstractions of Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[33]
, booktitle=
Wu, Zhengxuan and Geiger, Atticus and Icard, Thomas and Potts, Christopher and Goodman, Noah D. , booktitle=. Interpretability at Scale: Identifying Causal Mechanisms in
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.