SharedRequest: Privacy-Preserving Model-Agnostic Inference for Large Language Models
Pith reviewed 2026-06-28 05:28 UTC · model grok-4.3
The pith
SharedRequest protects LLM prompt privacy by mixing original prompts with noisy variants and grouping similar instructions into batches without model changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SharedRequest reformulates privacy protection at the batch level rather than the individual-prompt level by obscuring sensitive information through mixing original prompts with noisy variants and grouping semantically equivalent instructions to amortize the inference cost over a large batch of queries with minimal impact on LLM response quality; the design requires no access to model parameters or architectural modification.
What carries the argument
The shared-prompt mechanism that mixes original prompts with noisy variants and groups semantically equivalent instructions for batched inference.
If this is right
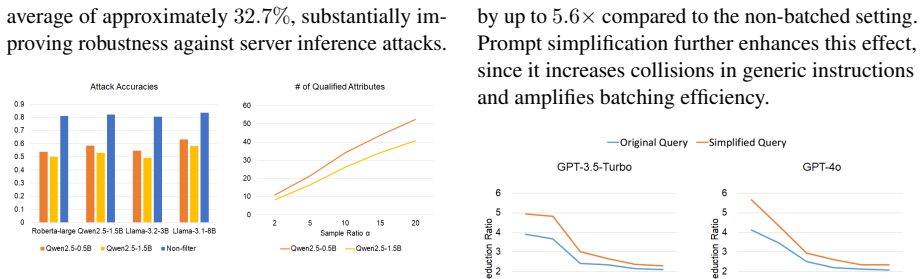
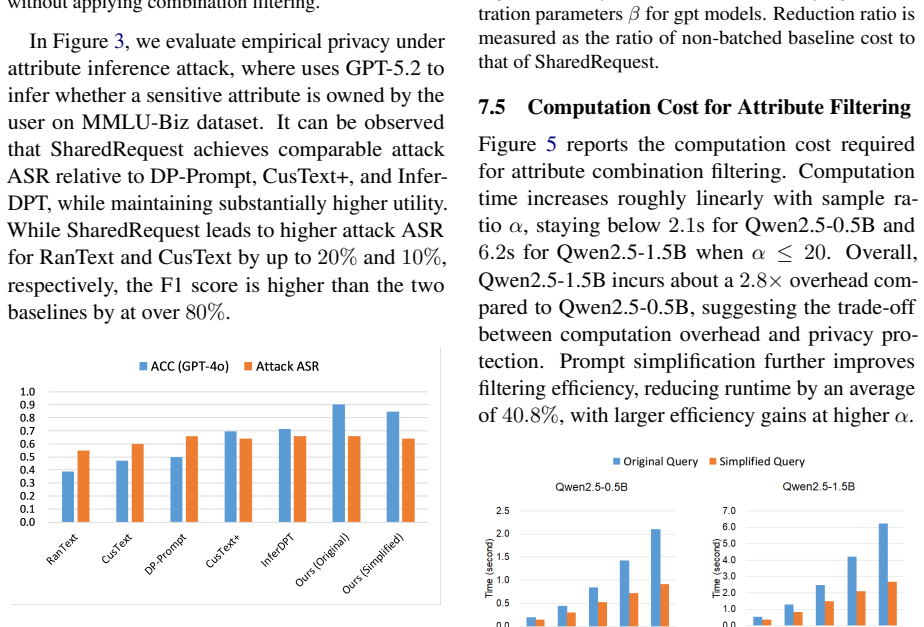
- Achieves over 20 percent higher utility than prior differential privacy baselines.
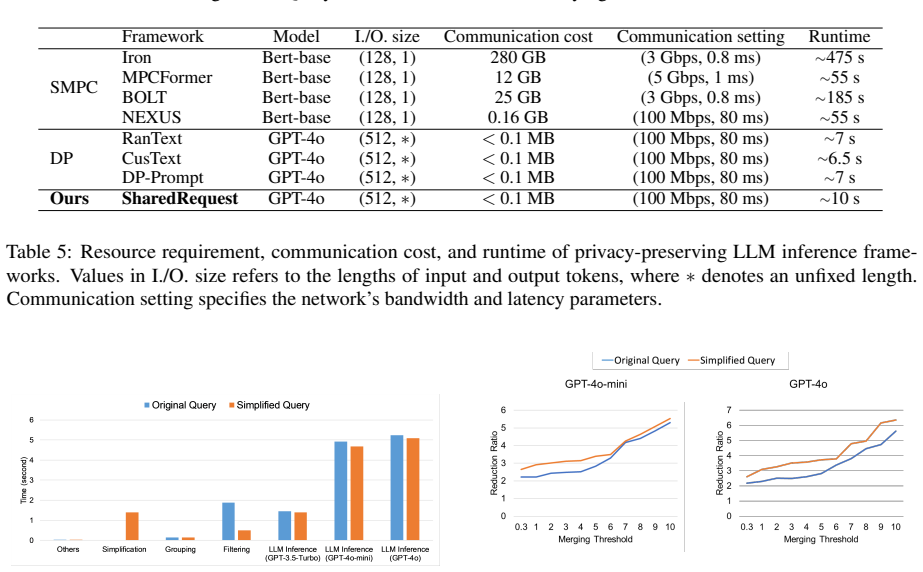
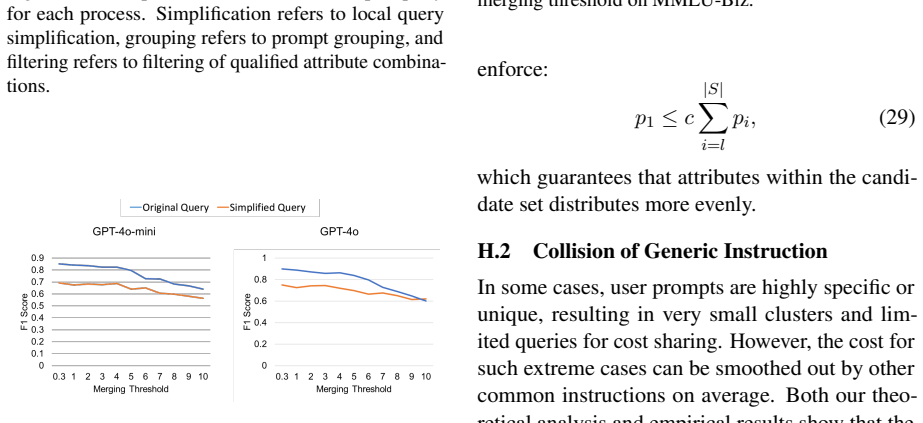
- Reduces query cost by up to 5 times compared with non-batched inference.
- Operates without access to model parameters or any architectural modification.
- Applies to any public LLM because it is model-agnostic.
- Maintains response quality while operating at the batch level.
Where Pith is reading between the lines
- The batch-level mixing strategy may scale to other generative services that accept text instructions if the grouping step can be automated reliably.
- High-volume query settings could see larger cost savings than the reported 5 times factor once batch sizes grow.
- Real deployments would benefit from measuring whether the noisy variants introduce detectable patterns that an adversary could exploit over repeated uses.
Load-bearing premise
Mixing original prompts with noisy variants sufficiently obscures sensitive information and grouping semantically equivalent instructions can be done reliably with minimal degradation to response quality.
What would settle it
A test in which an adversary reconstructs the original prompt from the batched responses at a rate exceeding the claimed privacy level, or measured utility falls below the reported 20 percent gain over differential privacy baselines.
Figures







read the original abstract
With the widespread deployment of public large language models (LLMs) such as ChatGPT, protecting user prompt privacy has become an increasingly critical issue. Existing privacy-preserving inference methods sacrifice either utility or efficiency, and often require model-specific modifications that limit their compatibility. In this paper, we propose SharedRequest, a model-agnostic framework for privacy-preserving LLM inference that reformulates privacy protection at the batch level rather than the individual-prompt level. The key idea is to obscure sensitive information by mixing original prompts with noisy variants, while grouping semantically equivalent instructions to amortize the inference cost over a large batch of queries with minimal impact on LLM response quality. This design is independent of the LLM architecture, requiring no access to model parameters or architectural modification. Empirical results demonstrate that SharedRequest achieves over $20\%$ higher utility compared to prior differential privacy baselines, and its shared-prompt mechanism reduces query cost by up to $5\times$ compared to non-batched inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SharedRequest, a model-agnostic framework for privacy-preserving LLM inference. It reformulates protection at the batch level by mixing original user prompts with noisy variants to obscure sensitive information and by grouping semantically equivalent instructions to amortize inference cost over large batches. The approach requires no model access or architectural changes. The central empirical claims are over 20% higher utility than prior differential privacy baselines and up to 5× reduction in query cost relative to non-batched inference.
Significance. If the empirical results and privacy properties hold under rigorous evaluation, the work would offer a practical, architecture-independent alternative to existing prompt-privacy techniques that often trade utility or require model modifications. The batch-level reformulation and cost-amortization idea address real deployment constraints for public LLM services.
major comments (3)
- [Abstract, §4] Abstract and §4 (Evaluation): the headline claims of >20% utility improvement and 5× cost reduction are presented without any description of datasets, metrics (e.g., ROUGE, human preference scores), baseline implementations, or statistical significance tests. This absence prevents verification that the reported gains are attributable to the proposed mixing and grouping mechanisms rather than experimental artifacts.
- [§3] §3 (Proposed Method): the privacy mechanism relies on mixing original prompts with noisy variants and semantic grouping, yet no formal differential privacy definition, noise distribution, or ε-bound is supplied. Consequently, it is impossible to determine whether the construction meets any standard privacy notion or merely provides heuristic obfuscation whose leakage could be comparable to the baselines it claims to surpass.
- [§3.2] §3.2 (Shared-Prompt Mechanism): the assumption that semantically equivalent instructions can be grouped reliably with “minimal impact on LLM response quality” is stated without a quantitative characterization of grouping error or an ablation showing how grouping accuracy trades off against both utility and privacy leakage.
minor comments (2)
- [§3] Notation for the noisy-variant generation and the batch-construction procedure should be formalized with explicit algorithms or pseudocode rather than prose descriptions.
- [Abstract] The abstract’s phrasing “over 20% higher utility” should be replaced by the precise metric and the exact numerical improvement once the evaluation section is expanded.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating planned revisions where appropriate to strengthen the presentation of our results and method.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Evaluation): the headline claims of >20% utility improvement and 5× cost reduction are presented without any description of datasets, metrics (e.g., ROUGE, human preference scores), baseline implementations, or statistical significance tests. This absence prevents verification that the reported gains are attributable to the proposed mixing and grouping mechanisms rather than experimental artifacts.
Authors: We agree that additional detail on the experimental setup is needed for full verifiability. In the revised manuscript we will expand §4 (and update the abstract if space permits) to explicitly describe the datasets, evaluation metrics including ROUGE and human preference scores, how baselines were implemented, and the statistical significance tests performed. These additions will clarify that the reported improvements stem from the batch-level mixing and grouping mechanisms. revision: yes
-
Referee: [§3] §3 (Proposed Method): the privacy mechanism relies on mixing original prompts with noisy variants and semantic grouping, yet no formal differential privacy definition, noise distribution, or ε-bound is supplied. Consequently, it is impossible to determine whether the construction meets any standard privacy notion or merely provides heuristic obfuscation whose leakage could be comparable to the baselines it claims to surpass.
Authors: SharedRequest is presented as a practical, model-agnostic obfuscation technique operating at the batch level rather than a formal differential privacy construction. The current manuscript does not claim or derive an ε-DP guarantee; privacy is achieved heuristically through prompt mixing and semantic grouping. We will revise §3 to state this distinction explicitly, discuss the resulting privacy properties relative to the DP baselines, and avoid any implication of formal DP guarantees. revision: yes
-
Referee: [§3.2] §3.2 (Shared-Prompt Mechanism): the assumption that semantically equivalent instructions can be grouped reliably with “minimal impact on LLM response quality” is stated without a quantitative characterization of grouping error or an ablation showing how grouping accuracy trades off against both utility and privacy leakage.
Authors: We acknowledge that the grouping component requires more rigorous quantification. In the revision we will add an ablation study in §3.2 (or a new subsection) that measures grouping error, reports its effect on response quality/utility, and examines any impact on privacy leakage. This will provide the quantitative characterization requested. revision: yes
Circularity Check
No circularity: empirical framework with no derivation chain or self-referential equations
full rationale
The paper proposes a batch-level prompt-mixing framework and reports empirical utility/cost gains versus baselines. No equations, derivations, fitted parameters presented as predictions, uniqueness theorems, or self-citations that reduce claims to inputs by construction appear in the provided text. The central results are experimental comparisons; the mixing and grouping steps are described as design choices whose effectiveness is measured externally rather than defined into existence. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mixing prompts with noisy variants obscures sensitive information at the batch level
- domain assumption Semantically equivalent instructions can be grouped reliably without model access and with minimal quality loss
Reference graph
Works this paper leans on
-
[1]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DemandSage , author=
CHATGPT statistics 2025 , url=. DemandSage , author=. 2025 , month=
2025
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ACM Transactions on Intelligent Systems and Technology (TIST) , volume=
Federated machine learning: Concept and applications , author=. ACM Transactions on Intelligent Systems and Technology (TIST) , volume=. 2019 , publisher=
2019
-
[5]
2012 International Conference on Computing Sciences , pages=
Digital signature , author=. 2012 International Conference on Computing Sciences , pages=. 2012 , organization=
2012
-
[6]
2010 , publisher=
Digital signatures , author=. 2010 , publisher=
2010
-
[7]
14th USENIX symposium on networked systems design and implementation (NSDI 17) , pages=
Prio: Private, robust, and scalable computation of aggregate statistics , author=. 14th USENIX symposium on networked systems design and implementation (NSDI 17) , pages=
-
[8]
2017 IEEE symposium on security and privacy (SP) , pages=
Secureml: A system for scalable privacy-preserving machine learning , author=. 2017 IEEE symposium on security and privacy (SP) , pages=. 2017 , organization=
2017
-
[9]
ISWC (3) , year=
Data Privacy Vocabulary (DPV)-Version 2.0 , author=. ISWC (3) , year=
-
[10]
The University of Chicago Law Review , volume=
Implementing personalized law , author=. The University of Chicago Law Review , volume=. 2019 , publisher=
2019
-
[11]
International Review of Law, Computers & Technology , volume=
Privacy notices versus informational self-determination: Minding the gap , author=. International Review of Law, Computers & Technology , volume=. 2014 , publisher=
2014
-
[12]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[13]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2305.11176 , year=
Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model , author=. arXiv preprint arXiv:2305.11176 , year=
-
[15]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
AMistral Small 3 , year=
-
[17]
arXiv preprint arXiv:2305.18396 , year=
LLMs Can Understand Encrypted Prompt: Towards Privacy-Computing Friendly Transformers , author=. arXiv preprint arXiv:2305.18396 , year=
-
[18]
arXiv preprint arXiv:2206.00216 , year=
The-x: Privacy-preserving transformer inference with homomorphic encryption , author=. arXiv preprint arXiv:2206.00216 , year=
-
[19]
arXiv preprint arXiv:2309.06746 , year=
DP-Forward: Fine-tuning and inference on language models with differential privacy in forward pass , author=. arXiv preprint arXiv:2309.06746 , year=
-
[20]
International Conference on Machine Learning , pages=
Split-and-Denoise: Protect large language model inference with local differential privacy , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[21]
23rd annual symposium on foundations of computer science (sfcs 1982) , pages=
Protocols for secure computations , author=. 23rd annual symposium on foundations of computer science (sfcs 1982) , pages=. 1982 , organization=
1982
-
[22]
International Conference on Machine Learning , pages=
De-mark: Watermark Removal in Large Language Models , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[23]
arXiv preprint arXiv:2509.24043 , year=
An Ensemble Framework for Unbiased Language Model Watermarking , author=. arXiv preprint arXiv:2509.24043 , year=
-
[24]
arXiv preprint arXiv:2511.11483 , year=
ImAgent: A Unified Multimodal Agent Framework for Test-Time Scalable Image Generation , author=. arXiv preprint arXiv:2511.11483 , year=
-
[25]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
FakeRadar: Probing Forgery Outliers to Detect Unknown Deepfake Videos , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[26]
arXiv preprint arXiv:2510.12041 , year=
Improving Text-to-Image Generation with Input-Side Inference-Time Scaling , author=. arXiv preprint arXiv:2510.12041 , year=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
DeepShield: Fortifying Deepfake Video Detection with Local and Global Forgery Analysis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
2015 IEEE Trustcom/BigDataSE/Ispa , volume=
Trusted execution environment: What it is, and what it is not , author=. 2015 IEEE Trustcom/BigDataSE/Ispa , volume=. 2015 , organization=
2015
-
[29]
International colloquium on automata, languages, and programming , pages=
Differential privacy , author=. International colloquium on automata, languages, and programming , pages=. 2006 , organization=
2006
-
[30]
2023 , note =
legal‑qa‑v1: A collection of legal Q&A pairs , howpublished =. 2023 , note =
2023
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
FedDiv: Collaborative noise filtering for federated learning with noisy labels , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
arXiv preprint arXiv:2105.11653 , year=
Scaling hierarchical agglomerative clustering to billion-sized datasets , author=. arXiv preprint arXiv:2105.11653 , year=
-
[33]
Communications of the ACM , volume=
A method for obtaining digital signatures and public-key cryptosystems , author=. Communications of the ACM , volume=. 1978 , publisher=
1978
-
[34]
Investigating ChatGPT Search: Insights from 80 Million Clickstream Records , url =
Kelly, Brenna and Harsel, Luke , month =. Investigating ChatGPT Search: Insights from 80 Million Clickstream Records , url =. 2025 , organization =
2025
-
[35]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
A Customized Text Sanitization Mechanism with Differential Privacy , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[36]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
Differential Privacy for Text Analytics via Natural Text Sanitization , author=. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=. 2021 , organization=
2021
-
[37]
Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Accelerating exact k-means algorithms with geometric reasoning , author=. Proceedings of the fifth ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[38]
kdd , volume=
A density-based algorithm for discovering clusters in large spatial databases with noise , author=. kdd , volume=
-
[39]
2024 , eprint=
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs , author=. 2024 , eprint=
2024
-
[40]
Proceedings of the 13th international conference on web search and data mining , pages=
Privacy-and utility-preserving textual analysis via calibrated multivariate perturbations , author=. Proceedings of the 13th international conference on web search and data mining , pages=
-
[41]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[42]
arXiv preprint arXiv:2306.08223 , year=
Protecting User Privacy in Remote Conversational Systems: A Privacy-Preserving framework based on text sanitization , author=. arXiv preprint arXiv:2306.08223 , year=
-
[43]
arXiv preprint arXiv:2309.03057 , year=
Hide and Seek (HaS): A Lightweight Framework for Prompt Privacy Protection , author=. arXiv preprint arXiv:2309.03057 , year=
-
[44]
ACM Computing Surveys , volume=
Named entity recognition and classification in historical documents: A survey , author=. ACM Computing Surveys , volume=. 2023 , publisher=
2023
-
[45]
Neural Architectures for Named Entity Recognition
Neural architectures for named entity recognition , author=. arXiv preprint arXiv:1603.01360 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
, author=
t-Plausibility: Generalizing words to desensitize text. , author=. Trans. Data Priv. , volume=
-
[47]
International conference on machine learning , pages=
Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[48]
Advances in Neural Information Processing Systems , volume=
Iron: Private inference on transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
arXiv preprint arXiv:2009.05886 , year=
Differentially private language models benefit from public pre-training , author=. arXiv preprint arXiv:2009.05886 , year=
-
[50]
arXiv preprint arXiv:2110.06500 , year=
Differentially private fine-tuning of language models , author=. arXiv preprint arXiv:2110.06500 , year=
-
[51]
2023 , eprint=
Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models , author=. 2023 , eprint=
2023
-
[52]
2023 , eprint=
Privacy-Preserving Prompt Tuning for Large Language Model Services , author=. 2023 , eprint=
2023
-
[53]
Information Sciences , volume=
Constructing plausible innocuous pseudo queries to protect user query intention , author=. Information Sciences , volume=. 2015 , publisher=
2015
-
[54]
1999 , publisher=
The McKinsey Way , author=. 1999 , publisher=
1999
-
[55]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[56]
Transactions of the Association for Computational Linguistics , volume=
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies , author=. Transactions of the Association for Computational Linguistics , volume=. 2021 , publisher=
2021
-
[57]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
HotpotQA: A dataset for diverse, explainable multi-hop question answering , author=. arXiv preprint arXiv:1809.09600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[59]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. arXiv preprint arXiv:1810.04805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[61]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[62]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[64]
See https://vicuna
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , year=
2023
-
[65]
2018 , publisher=
Natural Language Processing and Computational Linguistics: A practical guide to text analysis with Python, Gensim, spaCy, and Keras , author=. 2018 , publisher=
2018
-
[66]
Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics (demonstrations) , pages=
FLAIR: An easy-to-use framework for state-of-the-art NLP , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics (demonstrations) , pages=
2019
-
[67]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=. 2019 , organization=
2019
-
[68]
arXiv preprint arXiv:2312.01500 , year=
Unsupervised Approach to Evaluate Sentence-Level Fluency: Do We Really Need Reference? , author=. arXiv preprint arXiv:2312.01500 , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Rlaif: Scaling reinforcement learning from human feedback with ai feedback , author=. arXiv preprint arXiv:2309.00267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[73]
BloombergGPT: A Large Language Model for Finance
Bloomberggpt: A large language model for finance , author=. arXiv preprint arXiv:2303.17564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
ACM Computing Surveys (Csur) , volume=
A survey on homomorphic encryption schemes: Theory and implementation , author=. ACM Computing Surveys (Csur) , volume=. 2018 , publisher=
2018
-
[75]
2015 , publisher=
Secure multiparty computation , author=. 2015 , publisher=
2015
-
[76]
Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
Differentially Private Representation for NLP: Formal Guarantee and An Empirical Study on Privacy and Fairness , author=. Findings of the Association for Computational Linguistics: EMNLP 2020 , pages=
2020
-
[77]
Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Towards differentially private text representations , author=. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[78]
IEEE Transactions on Dependable and Secure Computing , year=
Inferdpt: Privacy-preserving inference for black-box large language models , author=. IEEE Transactions on Dependable and Secure Computing , year=
-
[79]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multihop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[80]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Locally Differentially Private Document Generation Using Zero Shot Prompting , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.