Incremental Computation for Efficient Programmable Inference in Probabilistic Programs
Pith reviewed 2026-06-28 02:30 UTC · model grok-4.3
The pith
Probabilistic programs compile to incremental densities that accelerate Monte Carlo inference algorithms including for nonparametric models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
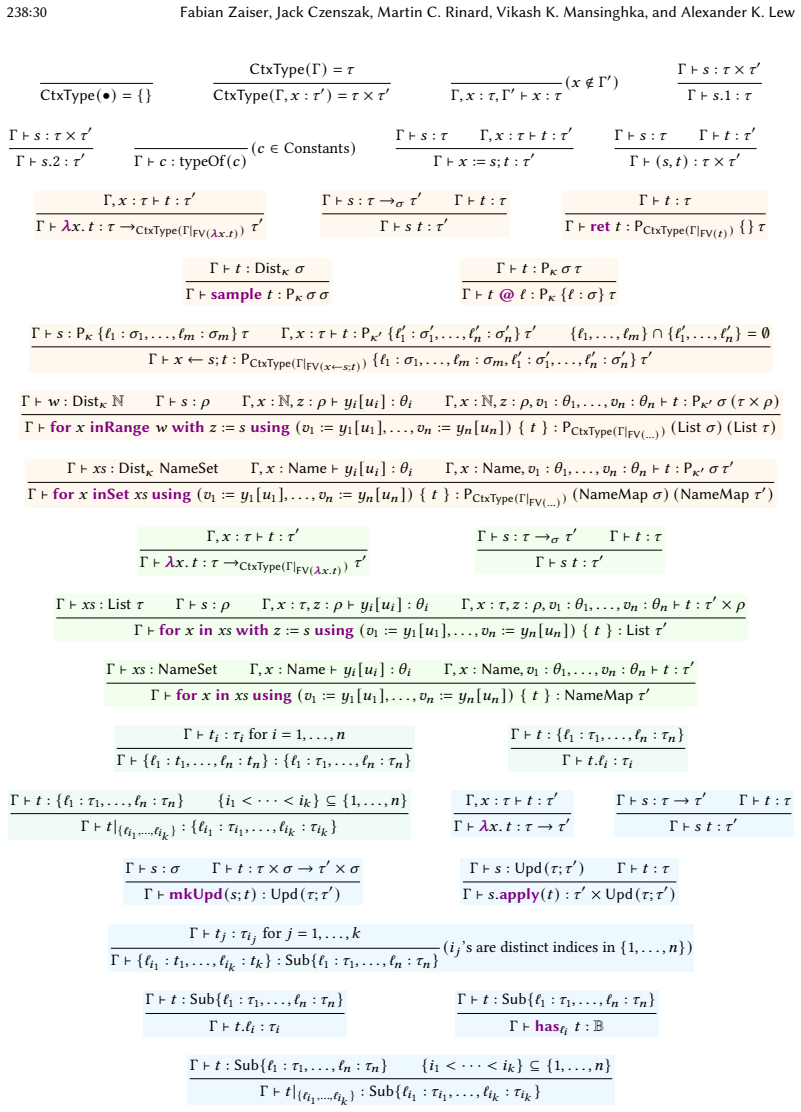
Expressive probabilistic programs can be compiled to deterministic programs that compute their density functions, which can then be compositionally incrementalized using the incremental λ-calculus. The resulting incremental densities accelerate Monte Carlo inference algorithms, including for nonparametric models not well supported by existing systems. The decomposition into separate density and incrementalization steps permits modular denotational logical relations arguments for the correctness of each step independently.
What carries the argument
The incremental λ-calculus technique for compositionally incrementalizing functional programs, applied after compiling probabilistic programs to deterministic density functions.
If this is right
- Incremental densities accelerate a broad range of Monte Carlo inference algorithms.
- The method supports nonparametric models not well supported by existing systems.
- Decomposition into density and incrementalization steps enables modular correctness proofs via logical relations.
- Asymptotic runtime improvements occur in the size of the dataset on a range of models and inference algorithms.
Where Pith is reading between the lines
- The modular correctness technique could transfer to incrementalization in other probabilistic programming systems.
- Efficiency gains might allow scaling inference to datasets larger than those feasible with current ad-hoc methods.
- The compilation-plus-incrementalization split could be combined with other program transformations such as automatic differentiation.
Load-bearing premise
Expressive probabilistic programs can be compiled to deterministic programs that compute their density functions, and the incremental λ-calculus applies compositionally to these without breaking the semantics needed for inference.
What would settle it
A case where running the incrementalized density computation produces different inference results from the non-incremental version, or where runtime fails to improve asymptotically with dataset size on the range of models tested in the prototype.
Figures







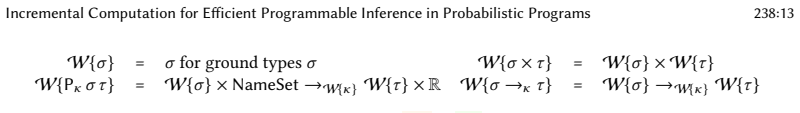
















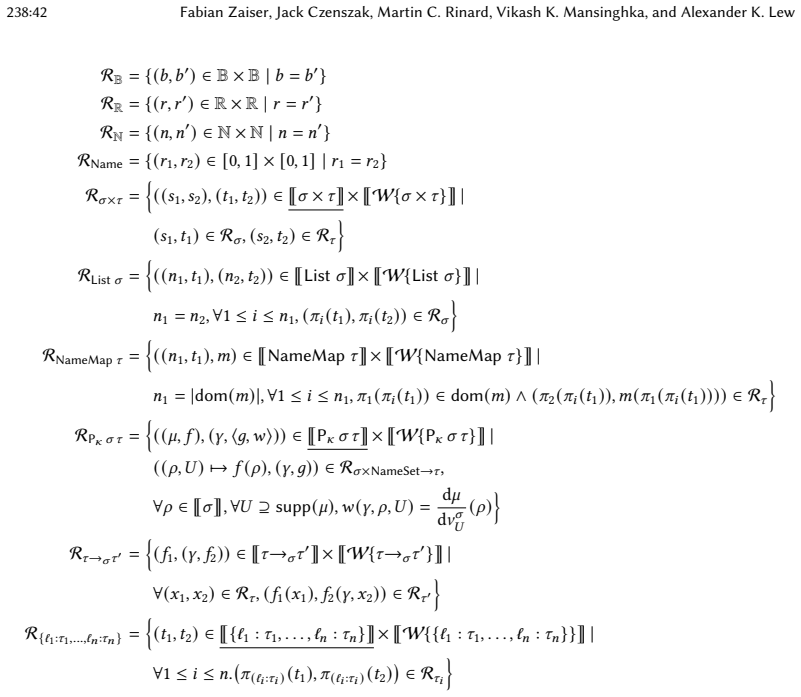





read the original abstract
Inference in probabilistic programs generally requires evaluating many possible program executions to find those of high posterior density. To scale inference to large datasets, it is crucial that expensive intermediate results are shared across these many evaluations, rather than recomputed from scratch. This paper presents a new approach to realizing this sharing, based on \textit{incremental computation}, a technique for efficiently recomputing (deterministic) program outputs when program inputs change. First, we show how expressive probabilistic programs can be compiled to deterministic ones that compute their density functions. Then, building on the incremental $\lambda$-calculus, we develop a general technique for compositionally incrementalizing expressive functional programs, and apply it to these densities. The resulting incremental densities can be used to accelerate a broad range of Monte Carlo inference algorithms, including for nonparametric models not well supported by existing systems. Furthermore, our decomposition of incremental density computation into separate density and incrementalization steps allows for modular reasoning about correctness -- a key pain point in existing systems, where ad-hoc incrementalization features are a known source of soundness bugs. We develop denotational logical relations arguments for the correctness of each step independently, and implement the approach in a Julia prototype, finding that it leads to asymptotic runtime improvements in the size of the dataset on a range of models and inference algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that expressive probabilistic programs can be compiled to deterministic programs computing their density functions; these densities can then be incrementalized compositionally via the incremental λ-calculus. The resulting incremental densities accelerate Monte Carlo inference algorithms (including for nonparametric models). The approach decomposes density computation and incrementalization, enabling independent denotational logical-relations proofs of correctness for each step; a Julia prototype is reported to deliver asymptotic runtime improvements with dataset size on a range of models and algorithms.
Significance. If the compilation and incrementalization steps are shown to preserve the necessary semantics, the work supplies a modular, formally justified route to efficient sharing in programmable inference. The separation into independently verifiable phases directly addresses known soundness risks in ad-hoc incremental features of existing systems, and the claimed applicability to nonparametric models would fill a gap in current tooling.
minor comments (2)
- The abstract states that the Julia prototype yields 'asymptotic runtime improvements in the size of the dataset'; the full manuscript should include explicit big-O statements or scaling plots with dataset size as the independent variable to make this claim precise.
- The logical-relations arguments are described at a high level; if the paper contains the full definitions of the relations and the key lemmas, they should be cross-referenced to the relevant theorems so readers can locate the modular proofs without searching the text.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation to accept the paper.
Circularity Check
No significant circularity
full rationale
The paper's core derivation decomposes incremental density computation into two independent steps—compiling probabilistic programs to deterministic density functions, then applying a general incrementalization technique from the incremental λ-calculus—with separate denotational logical-relations arguments supplied for the correctness of each step. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the stated approach; the Julia prototype supplies external empirical validation of asymptotic improvements. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The incremental λ-calculus provides a general technique for compositionally incrementalizing expressive functional programs.
Reference graph
Works this paper leans on
-
[1]
Umut A. Acar. 2005.Self-Adjusting Computation. Ph. D. Dissertation. Carnegie Mellon University
2005
-
[2]
Umut A. Acar. 2009. Self-adjusting computation: (an overview). InProceedings of the 2009 ACM SIGPLAN Symposium on Partial Evaluation and Semantics-based Program Manipulation, PEPM 2009, Savannah, GA, USA, January 19-20, 2009, Germán Puebla and Germán Vidal (Eds.). ACM, 1–6. doi:10.1145/1480945.1480946
-
[3]
Christophe Andrieu and Gareth O. Roberts. 2009. The pseudo-marginal approach for efficient Monte Carlo computations. The Annals of Statistics37, 2 (2009), 697–725. doi:10.1214/07-AOS574
-
[4]
John Baez and Alexander Hoffnung. 2011. Convenient categories of smooth spaces.Trans. Amer. Math. Soc.363, 11 (2011), 5789–5825
2011
-
[5]
Becker, Mathieu Huot, George Matheos, Xiaoyan Wang, Karen Chung, Colin Smith, Sam Ritchie, Rif A
McCoy R. Becker, Mathieu Huot, George Matheos, Xiaoyan Wang, Karen Chung, Colin Smith, Sam Ritchie, Rif A. Saurous, Alexander K. Lew, Martin C. Rinard, and Vikash K. Mansinghka. 2026. Probabilistic Programming with Vectorized Programmable Inference.Proc. ACM Program. Lang.10, POPL (2026), 2523–2554. doi:10.1145/3776729
-
[6]
Blei, Andrew Y
David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet allocation.Journal of Machine Learning Research3, Jan (2003), 993–1022
2003
-
[7]
Markus Böck and Jürgen Cito. 2025. Static Factorisation of Probabilistic Programs With User-Labelled Sample Statements and While Loops.CoRRabs/2508.20922 (2025). arXiv:2508.20922 doi:10.48550/ARXIV.2508.20922
-
[8]
George E. P. Box and George C. Tiao. 1968. A Bayesian approach to some outlier problems.Biometrika55, 1 (1968), 119–129
1968
-
[9]
Giarrusso, Tillmann Rendel, and Klaus Ostermann
Yufei Cai, Paolo G. Giarrusso, Tillmann Rendel, and Klaus Ostermann. 2014. A theory of changes for higher-order languages: incrementalizing 𝜆-calculi by static differentiation. InACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11, 2014, Michael F. P. O’Boyle and Keshav Pingali (Eds....
-
[10]
Simon Castellan and Hugo Paquet. 2019. Probabilistic Programming Inference via Intensional Semantics. InProgram- ming Languages and Systems - 28th European Symposium on Programming, ESOP 2019, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2019, Prague, Czech Republic, April 6-11, 2019, Proceedings (Lecture Notes ...
-
[11]
Cusumano-Towner
Marco F. Cusumano-Towner. 2020.Gen: a high-level programming platform for probabilistic inference. Ph. D. Dissertation. Massachusetts Institute of Technology
2020
-
[12]
Cusumano-Towner, Benjamin Bichsel, Timon Gehr, Martin T
Marco F. Cusumano-Towner, Benjamin Bichsel, Timon Gehr, Martin T. Vechev, and Vikash K. Mansinghka. 2018. Incremental inference for probabilistic programs. InProceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2018. ACM, 571–585. doi:10.1145/3192366.3192399
-
[13]
Marco F. Cusumano-Towner, Alexander K. Lew, and Vikash K. Mansinghka. 2020. Automating Involutive MCMC using Probabilistic and Differentiable Programming. arXiv:2007.09871 [stat.CO] https://arxiv.org/abs/2007.09871
arXiv 2020
-
[14]
Marco F. Cusumano-Towner, Feras A. Saad, Alexander K. Lew, and Vikash K. Mansinghka. 2019. Gen: a general-purpose probabilistic programming system with programmable inference. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2019, Phoenix, AZ, USA, June 22-26, 2019, Kathryn S. McKinley and Kathleen F...
-
[15]
Swaraj Dash, Younesse Kaddar, Hugo Paquet, and Sam Staton. 2023. Affine monads and lazy structures for Bayesian programming.Proc. ACM Program. Lang.7, POPL (2023), 1338–1368. doi:10.1145/3571239
-
[16]
Jean Diebolt and Christian P. Robert. 1994. Estimation of finite mixture distributions through Bayesian sampling. Journal of the Royal Statistical Society: Series B (Methodological)56, 2 (1994), 363–375
1994
-
[17]
Hong Ge, Kai Xu, and Zoubin Ghahramani. 2018. Turing: A Language for Flexible Probabilistic Inference. InProceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics (AISTATS) (Proceedings of Machine Learning Research, Vol. 84). PMLR, 1682–1690. Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 238. Publication dat...
2018
-
[18]
Giarrusso, Yann Régis-Gianas, and Philipp Schuster
Paolo G. Giarrusso, Yann Régis-Gianas, and Philipp Schuster. 2019. Incremental𝜆-Calculus in Cache-Transfer Style - Static Memoization by Program Transformation. InProgramming Languages and Systems - 28th European Symposium on Programming, ESOP 2019, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2019, Prague, Czec...
-
[19]
Hammer, Jana Dunfield, Kyle Headley, Nicholas Labich, Jeffrey S
Matthew A. Hammer, Jana Dunfield, Kyle Headley, Nicholas Labich, Jeffrey S. Foster, Michael W. Hicks, and David Van Horn. 2015. Incremental computation with names. InProceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, OOPSLA 2015, part of SPLASH 2015, Pittsburgh, PA, USA, Octob...
-
[20]
Hammer, Yit Phang Khoo, Michael Hicks, and Jeffrey S
Matthew A. Hammer, Yit Phang Khoo, Michael Hicks, and Jeffrey S. Foster. 2014. Adapton: composable, demand-driven incremental computation. InACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11, 2014, Michael F. P. O’Boyle and Keshav Pingali (Eds.). ACM, 156–166. doi:10.1145/2594291.2594324
-
[21]
Chris Heunen, Ohad Kammar, Sam Staton, and Hongseok Yang. 2017. A convenient category for higher-order probability theory. In32nd Annual ACM/IEEE Symposium on Logic in Computer Science, LICS 2017. IEEE Computer Society, 1–12. doi:10.1109/LICS.2017.8005137
-
[22]
Wonyeol Lee, Hangyeol Yu, Xavier Rival, and Hongseok Yang. 2020. Towards Verified Stochastic Variational Inference for Probabilistic Programs.Proc. ACM Program. Lang.4, POPL (2020), 16:1–16:33. doi:10.1145/3371084
-
[23]
Alexander K. Lew, Marco F. Cusumano-Towner, Benjamin Sherman, Michael Carbin, and Vikash K. Mansinghka. 2020. Trace types and denotational semantics for sound programmable inference in probabilistic languages.Proc. ACM Program. Lang.4, POPL (2020), 19:1–19:32. doi:10.1145/3371087
-
[24]
Jianlin Li, Leni Aniva, Pengyuan Shi, and Yizhou Zhang. 2023. Type-Preserving, Dependence-Aware Guide Generation for Sound, Effective Amortized Probabilistic Inference.Proc. ACM Program. Lang.7, POPL (2023), 1454–1482. doi:10. 1145/3571243
2023
-
[25]
Sangho Lim, Hyoungjin Lim, Wonyeol Lee, Xavier Rival, and Hongseok Yang. 2026. Optimising Density Computations in Probabilistic Programs via Automatic Loop Vectorisation.Proc. ACM Program. Lang.10, POPL (2026), 597–627. doi:10.1145/3776663
-
[26]
1998.Categories for the Working Mathematician(2nd ed.)
Saunders Mac Lane. 1998.Categories for the Working Mathematician(2nd ed.). Graduate Texts in Mathematics, Vol. 5. Springer
1998
-
[27]
1994.Sheaves in Geometry and Logic: A First Introduction to Topos Theory
Saunders Mac Lane and Ieke Moerdijk. 1994.Sheaves in Geometry and Logic: A First Introduction to Topos Theory. Springer
1994
-
[28]
Vikash Mansinghka, Daniel Selsam, and Yura N. Perov. 2014. Venture: a higher-order probabilistic programming platform with programmable inference.CoRRabs/1404.0099 (2014). arXiv:1404.0099 http://arxiv.org/abs/1404.0099
Pith/arXiv arXiv 2014
-
[29]
Mansinghka, Ulrich Schaechtle, Shivam Handa, Alexey Radul, Yutian Chen, and Martin C
Vikash K. Mansinghka, Ulrich Schaechtle, Shivam Handa, Alexey Radul, Yutian Chen, and Martin C. Rinard. 2018. Probabilistic programming with programmable inference. InProceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI 2018, Philadelphia, PA, USA, June 18-22, 2018, Jeffrey S. Foster and Dan Grossman (Eds....
-
[30]
Cristina Matache, Sean K. Moss, and Sam Staton. 2022. Concrete categories and higher-order recursion. In37th Annual ACM/IEEE Symposium on Logic in Computer Science, LICS 2022. ACM, 57:1–57:14. doi:10.1145/3531130.3533370
-
[31]
Lew, Matin Ghavamizadeh, Stuart Russell, Marco F
George Matheos, Alexander K. Lew, Matin Ghavamizadeh, Stuart Russell, Marco F. Cusumano-Towner, and Vikash Mansinghka. 2021. Transforming Worlds: Automated Involutive MCMC for Open-Universe Probabilistic Models. In Third Symposium on Advances in Approximate Bayesian Inference. https://openreview.net/forum?id=8Itm8dQnJRc
2021
-
[32]
Kazutaka Matsuda, Samantha Frohlich, Meng Wang, and Nicolas Wu. 2023. Embedding by Unembedding.Proc. ACM Program. Lang.7, ICFP (2023), 1–47. doi:10.1145/3607830
-
[33]
Brian Milch and Stuart Russell. 2006. General-Purpose MCMC inference over relational structures. InProceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence (UAI’06). AUAI Press, 349–358
2006
-
[34]
Miller and Matthew T
Jeffrey W. Miller and Matthew T. Harrison. 2018. Mixture models with a prior on the number of components.J. Amer. Statist. Assoc.113, 521 (2018), 340–356
2018
-
[35]
Eugenio Moggi. 1989. Computational Lambda-Calculus and Monads. InProceedings of the Fourth Annual Symposium on Logic in Computer Science (LICS 1989). IEEE Computer Society, 14–23. doi:10.1109/LICS.1989.39155
-
[36]
Eugenio Moggi. 1991. Notions of computation and monads.Information and computation93, 1 (1991), 55–92
1991
-
[37]
Akimasa Morihata. 2020. Short Cut to Incremental Typed Functional Programs (Extended Abstract). InWPTE 2020: 7th International Workshop on Rewriting Techniques for Program Transformations and Evaluation. http://maude.ucm.es/ wpte20/papers/WPTE_2020_morihata.pdf Informal proceedings
2020
-
[38]
Radford M. Neal. 2000. Markov chain sampling methods for Dirichlet process mixture models.Journal of computational and graphical statistics9, 2 (2000), 249–265. Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 238. Publication date: June 2026. Incremental Computation for Efficient Programmable Inference in Probabilistic Programs 238:25
2000
-
[39]
Daniel Ritchie, Andreas Stuhlmüller, and Noah D. Goodman. 2016. C3: Lightweight Incrementalized MCMC for Probabilistic Programs using Continuations and Callsite Caching. InProceedings of the 19th International Conference on Artificial Intelligence and Statistics, AISTATS 2016, Cadiz, Spain, May 9-11, 2016 (JMLR Workshop and Conference Proceedings, Vol. 51...
2016
-
[40]
Marcin Sabok, Sam Staton, Dario Stein, and Michael Wolman. 2021. Probabilistic programming semantics for name generation.Proc. ACM Program. Lang.5, POPL (2021), 1–29. doi:10.1145/3434292
-
[41]
Moss, Chris Heunen, and Zoubin Ghahramani
Adam Ścibior, Ohad Kammar, Matthijs Vákár, Sam Staton, Hongseok Yang, Yufei Cai, Klaus Ostermann, Sean K. Moss, Chris Heunen, and Zoubin Ghahramani. 2018. Denotational validation of higher-order Bayesian inference.Proc. ACM Program. Lang.2, POPL (2018), 60:1–60:29. doi:10.1145/3158148
-
[42]
Steven L. Scott. 2002. Bayesian methods for Hidden Markov Models: Recursive computing in the 21st century.J. Amer. Statist. Assoc.97, 457 (2002), 337–351
2002
-
[43]
Sam Staton. 2017. Commutative Semantics for Probabilistic Programming. InProgramming Languages and Systems - 26th European Symposium on Programming, ESOP 2017 (Lecture Notes in Computer Science, Vol. 10201). Springer, 855–879. doi:10.1007/978-3-662-54434-1_32
-
[44]
Joseph Tassarotti and Jean-Baptiste Tristan. 2023. Verified Density Compilation for a Probabilistic Programming Language.Proc. ACM Program. Lang.7, PLDI (2023), 615–637. doi:10.1145/3591245
-
[45]
Arora, Yucen Lily Li, Kinjal Divesh Shah, David Noursi, Michael Tingley, Narjes Torabi, Sepehr Masouleh, Eric Lippert, and Erik Meijer
Nazanin Khosravani Tehrani, Nimar S. Arora, Yucen Lily Li, Kinjal Divesh Shah, David Noursi, Michael Tingley, Narjes Torabi, Sepehr Masouleh, Eric Lippert, and Erik Meijer. 2020. Bean Machine: A Declarative Probabilistic Programming Language For Efficient Programmable Inference. InInternational Conference on Probabilistic Graphical Models, PGM 2020, 23-25...
2020
-
[46]
Matthijs Vákár, Ohad Kammar, and Sam Staton. 2019. A domain theory for statistical probabilistic programming.Proc. ACM Program. Lang.3, POPL (2019), 36:1–36:29. doi:10.1145/3290349
-
[47]
Matthijs Vákár and Luke Ong. 2018. On s-finite measures and kernels. arXiv:1810.01837 https://arxiv.org/abs/1810.01837
Pith/arXiv arXiv 2018
-
[48]
Di Wang, Jan Hoffmann, and Thomas Reps. 2021. Sound Probabilistic Inference via Guide Types. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, PLDI 2021. ACM, 788–803. doi:10.1145/3453483.3454077
-
[49]
Lingfeng Yang, Pat Hanrahan, and Noah D. Goodman. 2014. Generating Efficient MCMC Kernels from Probabilistic Programs. InProceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, AISTATS 2014, Reykjavik, Iceland, April 22-25, 2014 (JMLR Workshop and Conference Proceedings). JMLR.org, 1068–1076. http: //proceedings....
2014
-
[50]
Incremental Computation for Efficient Programmable Inference in Probabilistic Programs
Fabian Zaiser, Jack Czenszak, Martin Rinard, Vikash Mansinghka, and Alexander Lew. 2026.Artifact for: “Incremental Computation for Efficient Programmable Inference in Probabilistic Programs” (PLDI 2026). doi:10.5281/zenodo.19080766 Received 2025-11-14; accepted 2026-04-03 Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 238. Publication date: June 202...
-
[51]
toVisit contains only iterations not yet processed
where 𝛾 ′ 1 =𝛾 ′ [𝑥↦→ ⟦𝑠⟧ (𝛾 ′)]. To apply Theo- rem C.2, we define admissible caches 𝐴 ˆ𝛾 :={(𝑢 𝑥, 𝑢𝑦) |𝑢 𝑥 ∈ U ⟦𝑠⟧tpl , ˆ𝛾 CtxType(Γ){𝜎 , 𝑢𝑦 ∈ U ⟦𝑡⟧tpl ,( ˆ𝛾,⟦𝑠⟧tpl ( ˆ𝛾) ) CtxType(Γ,𝑥:𝜎){𝜏 } The cache update function is 𝑢:=𝝀(𝑑𝛾,(𝑢 𝑥, 𝑢𝑦)).(dx, 𝑢 ′ 𝑥 ):=𝑢 𝑥 .apply(𝑑𝛾);(dy, 𝑢 ′ 𝑦):=𝑢 𝑦 .apply((𝑑𝛾,dx));(dy,(𝑢 ′ 𝑥, 𝑢′ 𝑦)) Stepping 𝑢𝑥 with d ˆ𝛾 yields (dv, ...
2026
-
[52]
By validity of each collectionUpds𝑗, stepping it yields (dy 𝑗,collectionUpds ′ 𝑗 ) with (⟦𝑦𝑗 ⟧ (𝛾),dy 𝑗,⟦𝑦 𝑗 ⟧ (𝛾′)) ∈ Proc
∈ C 𝜌 where 𝑧′ 0 =⟦𝑠⟧ (𝛾 ′), and also seedUpd′ ∈ U ⟦𝑠⟧tpl , ˆ𝛾 ′ CtxType(Γ){𝜌 , so clause 2 of the admissible-cache definition is preserved. By validity of each collectionUpds𝑗, stepping it yields (dy 𝑗,collectionUpds ′ 𝑗 ) with (⟦𝑦𝑗 ⟧ (𝛾),dy 𝑗,⟦𝑦 𝑗 ⟧ (𝛾′)) ∈ Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 238. Publication date: June 2026. Incrementa...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.