VASO: Formally Verifiable Self-Evolving Skills for Physical AI Agents
Pith reviewed 2026-06-28 05:35 UTC · model grok-4.3
The pith
Formal counterexamples from model checkers can update reusable LLM-generated robot skill contracts to satisfy temporal safety specifications without changing model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
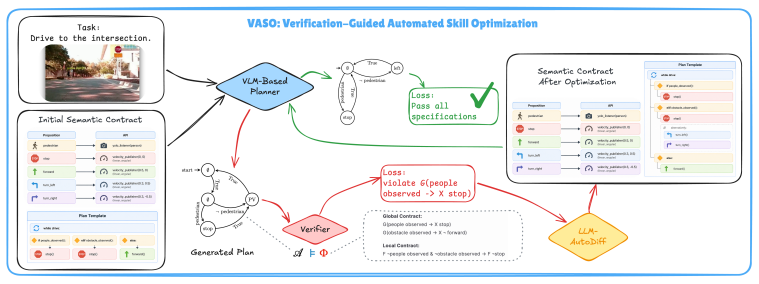
VASO represents each skill as a semantic contract with two coupled interfaces: a formal interface that aligns robot states, observations, and control commands with logical propositions for model checking, and a planner-facing interface that guides executable behavior. A model checker filters logically inconsistent contracts and verifies plans against global and local temporal specifications. When verification fails, the counterexample trace is translated into a textual gradient that revises the reusable skill contract while keeping foundation-model weights frozen.
What carries the argument
The semantic contract with a formal interface for model checking and a planner-facing interface, where counterexample traces are converted into textual gradients that update the contract.
If this is right
- Reusable skills satisfy both global and local temporal specifications beyond the executions used during evolution.
- Inconsistent skill contracts can be filtered before any physical execution occurs.
- Skill evolution occurs through verification feedback rather than execution traces or model-weight changes.
- The same evolved contracts can be reused across different tasks while preserving formal guarantees.
Where Pith is reading between the lines
- The method may scale to other embodied systems such as manipulation or navigation tasks that share similar state-observation-command mappings.
- Combining the formal feedback loop with limited real-world execution data could further reduce the number of updates needed.
- The approach suggests a route for maintaining formal safety properties when skills are composed into longer-horizon plans.
Load-bearing premise
The formal interface that aligns robot states, observations, and control commands with logical propositions accurately captures physical behavior and temporal safety contracts under untested conditions.
What would settle it
A physical robot executing a VASO-updated skill that violates a temporal safety specification approved by the model checker would falsify the central claim.
Figures





read the original abstract
Reusable robot skills are becoming the basic units through which embodied agents turn open-ended instructions into long-horizon physical behavior. We argue that, while foundation models have collapsed the cost of creating these skills, the cost of trusting them has not. Existing skill-evolution loops refine skills through execution feedback, unit tests, environment reward, or LLM self-critique, but these signals provide only trace-level evidence: they show that a skill worked on sampled executions, not that skill-induced plans satisfy temporal safety contracts under untested conditions. We introduce VASO, a framework for verification-guided self-evolution of LLM-generated robot skill contracts. In VASO, each skill is represented as a semantic contract with two coupled interfaces: a formal interface that aligns robot states, observations, and control commands with logical propositions for model checking, and a planner-facing interface that guides executable behavior generation. A model checker first filters logically inconsistent skill contracts, then verifies plans induced by the skill against global and local temporal specifications. When verification fails, VASO translates the counterexample trace into a textual gradient that updates the reusable skill contract while keeping foundation-model weights frozen. On Clearpath Jackal and PX4 quadcopter tasks, VASO reaches 97.2% formal-specification compliance using fewer than 100 optimization samples, outperforming execution-feedback, prompt-optimization, and fine-tuning baselines. To our knowledge, VASO is the first framework that closes the loop between formal verification and self-evolving LLM-generated skills for physical AI agents: formal counterexamples become optimization feedback for reusable robot skill contracts, rather than merely verifying one-off plans, tuning planner prompts, or fine-tuning model weights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VASO, a framework for verification-guided self-evolution of LLM-generated robot skill contracts. Each skill is a semantic contract with a formal interface (aligning states/observations/commands to logical propositions for model checking) and a planner-facing interface. A model checker filters inconsistent contracts and verifies induced plans against temporal specifications; counterexamples are translated into textual gradients that update the reusable contract while keeping foundation-model weights frozen. On Clearpath Jackal and PX4 quadcopter tasks, VASO reports 97.2% formal-specification compliance using fewer than 100 optimization samples and outperforms execution-feedback, prompt-optimization, and fine-tuning baselines. The central claim is that this is the first framework to close the loop between formal verification and self-evolving LLM skills for physical agents.
Significance. If the formal interface produces sound abstractions and the counterexample-to-text translation yields effective updates, the result would be significant: it supplies stronger (temporal-contract) evidence than trace-level signals while avoiding weight updates, and it demonstrates a concrete mechanism for turning model-checker output into reusable skill improvement. The approach also keeps the foundation model frozen, which is a practical strength for deployment.
major comments (2)
- [Abstract / Method description] The central claim that counterexamples become effective optimization feedback for reusable contracts rests on the formal interface producing sound and complete abstractions of continuous robot dynamics (Abstract). No construction details, soundness argument, or example mapping from continuous states to propositions is supplied, so it is impossible to determine whether the reported 97.2% compliance generalizes or whether the loop can produce spurious updates on untested trajectories.
- [Experiments section] The experimental claim of outperforming baselines with <100 samples (Abstract) is load-bearing for the practicality argument, yet the manuscript supplies no protocol details on how samples are counted, how many independent runs were performed, or the precise definition of the temporal specifications used for verification.
minor comments (2)
- Notation for the two interfaces (formal vs. planner-facing) should be introduced with explicit symbols or diagrams to avoid ambiguity when describing the translation step.
- The abstract states the result is achieved 'on Clearpath Jackal and PX4 quadcopter tasks' but does not list the exact tasks or the global/local temporal specifications; adding a short table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which highlight areas where additional clarity will strengthen the manuscript. We address each major comment below and will revise the paper accordingly to provide the requested details on the formal interface and experimental protocol.
read point-by-point responses
-
Referee: [Abstract / Method description] The central claim that counterexamples become effective optimization feedback for reusable contracts rests on the formal interface producing sound and complete abstractions of continuous robot dynamics (Abstract). No construction details, soundness argument, or example mapping from continuous states to propositions is supplied, so it is impossible to determine whether the reported 97.2% compliance generalizes or whether the loop can produce spurious updates on untested trajectories.
Authors: We agree that the current description of the formal interface would benefit from greater detail. In the revised manuscript we will expand Section 3.2 to include: (1) an explicit example of the state-to-proposition mapping for both the Jackal navigation and quadcopter flight tasks, (2) the discrete-event abstraction used to model continuous dynamics, and (3) a brief argument for soundness based on conservative over-approximation of reachable sets. These additions will allow readers to assess generalization and the risk of spurious updates. revision: yes
-
Referee: [Experiments section] The experimental claim of outperforming baselines with <100 samples (Abstract) is load-bearing for the practicality argument, yet the manuscript supplies no protocol details on how samples are counted, how many independent runs were performed, or the precise definition of the temporal specifications used for verification.
Authors: We acknowledge the need for these protocol details. The revised Experiments section will add a dedicated paragraph specifying: sample counting (each contract update iteration counts as one sample), number of independent runs (five per task with different random seeds), and the exact LTL formulas employed (e.g., □◇goal ∧ □¬obstacle for navigation). We will also report variance across runs. revision: yes
Circularity Check
No circularity: derivation relies on external model checker
full rationale
The paper presents VASO as a framework that uses an external model checker to verify skill contracts and generate counterexample-based textual updates. No load-bearing step reduces to a self-definition, fitted input renamed as prediction, or self-citation chain. The central claim (counterexamples yield effective updates) depends on the soundness of the formal interface, which is an external assumption rather than a constructed equivalence. The method is self-contained against the stated benchmarks of execution feedback and prompt optimization.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022
Pith/arXiv arXiv 2022
-
[2]
Liang, W
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. In2023 IEEE International conference on robotics and automation (ICRA), pages 9493–9500. IEEE, 2023
2023
-
[3]
Singh, V
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models, 2022
2022
-
[4]
C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y . Su. Llm-planner: Few-shot grounded planning for embodied agents with large language models, 2022
2022
-
[5]
Z. Hu, F. Lucchetti, C. Schlesinger, Y . Saxena, A. Freeman, S. Modak, A. Guha, and J. Biswas. Deploying and evaluating llms to program service mobile robots.IEEE Robotics Autom. Lett., 9(3):2853–2860, 2024
2024
-
[6]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
Pith/arXiv arXiv 2023
-
[7]
Z. Wang, D. Fried, and G. Neubig. Trove: Inducing verifiable and efficient toolboxes for solving programmatic tasks.arXiv preprint arXiv:2401.12869, 2024
arXiv 2024
-
[8]
M. Chen, Y . Li, Y . Yang, S. Yu, B. Lin, and X. He. Automanual: Constructing instruction manuals by llm agents via interactive environmental learning. InNeurIPS, 2024
2024
-
[9]
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, L. Fan, and A. Anandkumar. Eureka: Human-level reward design via coding large language models. In ICLR, 2024
2024
-
[10]
ECNU-ICALK and S. A. Laboratory. Autoskill: Experience-driven lifelong learning via skill self-evolution.arXiv preprint arXiv:2603.01145, 2026
arXiv 2026
-
[11]
B. L. et al. Llm+p: Empowering large language models with optimal planning proficiency, 2023
2023
-
[12]
R. Wang, Z. Yang, Z. Zhao, X. Tong, Z. Hong, and K. Qian. Llm-based robot task planning with exceptional handling for general purpose service robots. In2024 43rd Chinese Control Conference (CCC), pages 4439–4444. IEEE, 2024
2024
-
[13]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[14]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
-
[15]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[16]
J. X. Liu, Z. Yang, I. Idrees, S. Liang, B. Schornstein, S. Tellex, and A. Shah. Grounding complex natural language commands for temporal tasks in unseen environments. InConference on Robot Learning, pages 1084–1110. PMLR, 2023. 9
2023
-
[17]
D. S. Grigorev, A. K. Kovalev, and A. I. Panov. Verifyllm: Llm-based pre-execution task plan verification for robots. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 18489–18496. IEEE, 2025
2025
-
[18]
Y . Hao, Y . Chen, Y . Zhang, and C. Fan. Large language models can solve real-world planning rigorously with formal verification tools. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3434–3483, 2025
2025
-
[19]
N. P. Bhatt, Y . Yang, R. Siva, D. Milan, Z. Wang, and U. Topcu. Know where you’re uncertain when planning with multimodal foundation models: A formal framework. InEighth Conference on Machine Learning and Systems, Santa Clara, CA, USA, 2025
2025
-
[20]
Y . Yang, C. Neary, and U. Topcu. Multimodal pretrained models for verifiable sequential decision-making: Planning, grounding, and perception. InInternational Conference on Au- tonomous Agents and Multiagent Systems, pages 2011–2019, New Zealand, 2024. ACM
2011
-
[21]
M. Yuksekgonul, F. Bianchi, J. Boen, S. Liu, Z. Huang, C. Guestrin, and J. Zou. Textgrad: Automatic" differentiation" via text.arXiv preprint arXiv:2406.07496, 2024
Pith/arXiv arXiv 2024
- [22]
-
[23]
Khattab, A
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts. Dspy: Compiling declarative language model calls into self-improving pipelines.The Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
Y . Yang, J. Hong, G. J. Perin, Z. Fan, L. Yin, Z. Wang, and U. Topcu. Lad-vf: Llm-automatic differentiation enables fine-tuning-free robot planning from formal methods feedback.Interna- tional Conference on Robotics and Automation, 2026
2026
-
[25]
Yang and N
Y . Yang and N. P. B. et al. Fine-tuning language models using formal methods feedback: A use case in autonomous systems. InConference on Machine Learning and Systems, CA, USA,
-
[26]
N. Stiennon, L. Ouyang, J. Wu, D. M. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize from human feedback.arXiv preprint arXiv:2009.01325, 2020
Pith/arXiv arXiv 2009
-
[27]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems, 36:53728–53741, 2023
2023
-
[28]
Z. Hu, J. J. Li, A. Guha, and J. Biswas. Robo-instruct: Simulator-augmented instruction align- ment for finetuning codellms, 2024. URLhttps://arxiv.org/abs/2405.20179
arXiv 2024
-
[29]
Y . Yang, Z. Gong, W. Huang, Q. Yang, Z. Zhou, Z. Huang, Y . Li, X. Gao, Q. Dai, B. Liu, K. Qiu, Y . Yang, D. Chen, X. Yang, and C. Luo. Skillopt: Executive strategy for self-evolving agent skills, 2026. URLhttps://arxiv.org/abs/2605.23904
Pith/arXiv arXiv 2026
-
[30]
A. C. et al. NuSMV 2: An opensource tool for symbolic model checking. InComputer Aided Verification, volume 2404 ofLecture Notes in Computer Science, pages 359–364, NY , USA,
-
[31]
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liu, et al. A survey on in-context learning.arXiv preprint arXiv:2301.00234, 2022
Pith/arXiv arXiv 2022
-
[32]
D. Roy, X. Zhang, R. Bhave, C. Bansal, P. Las-Casas, R. Fonseca, and S. Rajmohan. Explor- ing llm-based agents for root cause analysis. InCompanion proceedings of the 32nd ACM international conference on the foundations of software engineering, pages 208–219, 2024. 10 A Additional Implementation Details For skill generation, we synthesize a prompt to guid...
2024
-
[33]
A set of low-level APIs or control commands
-
[34]
A set of global logical specifications derive a robotic skill specification with the following sections:
-
[35]
- The Local Contract must define skill-specific logical behavior using temporal logic
Semantic Contract Requirements: - The Global Contract must preserve the provided global logical specifications. - The Local Contract must define skill-specific logical behavior using temporal logic. - The Semantic Contract must bridge atomic propositions and executable Python code. For the Semantic Contract: - Generate proposition-aligned Python APIs whos...
-
[36]
set_velocity)
A reusable helper layer if needed (e.g. set_velocity)
-
[37]
A Python plan template demonstrating safe execution of the skill
-
[38]
""Send linear and angular velocity commands
Runtime assertions enforcing global safety constraints Output format: ## Skill: <skill_name> ### Global Contract Logical formula ### Local Contract Logical formula ### Semantic Contract #### Proposition-aligned APIs 11 Example: python APIs #### Plan Template Example: python program A user needs to provide a set of APIs or control commands and a set of glo...
-
[39]
G(people_observed -> X stop)
-
[40]
G(obstacle_observed -> X ! forward)
-
[41]
G(speed < 0.5) 6 7# Local Contract
-
[42]
F !people_observed & !obstacle_observed -> F !stop
-
[43]
F obstacle_observed -> turn_left | turn_right 10 11=====PX4 (Drone)====== 12# Global Contract
-
[44]
G(max_altitude < 10)
-
[45]
G(velocity_change <= 1)
-
[46]
G(linear_velocity <= 1) 13 16 17# Local Contract
-
[47]
F (linear_velocity == 0 & altitude == 0)
-
[48]
G (altitude == 0 -> linear_velocity == 0)
-
[49]
We show the prompts VLM-based planners under identical system specifications and temporal logic constraints
F (linear_velocity > 0) Listing 2: A set of specifications we verified during empirical evaluation. We show the prompts VLM-based planners under identical system specifications and temporal logic constraints. Listing 3 directly instructs the model to generate executable plans while satisfying the safety specifi- cations. Listing 3: Prompt exampkes for the...
-
[50]
Observe the current state, goal, obstacles, and previous command
-
[51]
Reason about the next safest subgoal
-
[52]
Check all hard constraints before choosing an action
-
[53]
Planning rules: - Never violate constraints to complete the task
Act by outputting a valid velocity command. Planning rules: - Never violate constraints to complete the task. - Prefer [0,0,0] when uncertain, blocked, or missing critical information. - Keep vd = 0 unless altitude change is required. - Do not climb if altitude is close to 10 m. - Reduce speed near obstacles or targets. - Insert [0,0,0] or intermediate ve...
-
[54]
Drive straight for 3 meters and stop
-
[55]
Move forward 5 meters, then turn left by 90 degrees
-
[56]
Travel 4 meters down the hallway and stop at the doorway
-
[57]
Move forward for 2 meters and rotate right by 45 degrees
-
[58]
Out-of-domain prompts:
Navigate 6 meters ahead while maintaining a straight path. Out-of-domain prompts:
-
[59]
Follow an L-shaped path: move 3 meters forward, turn right 90 degrees, then move 2 meters
-
[60]
Drive in a square pattern with side length 2 meters and stop at the starting position
-
[61]
Go 5 meters forward, make a left turn, and continue another 3 meters
-
[62]
Move to the hallway entrance, then rotate left to face the kitchen
-
[63]
Listing 7: In-domain and held-out prompts for thefind-objectskill (Jackal)
Traverse a zig-zag route by alternating 45-degree left and right turns every 2 meters. Listing 7: In-domain and held-out prompts for thefind-objectskill (Jackal). 15 Skill: find-object In-domain prompts:
-
[64]
Search for a chair and stop once it is detected
-
[65]
Find a backpack near the hallway
-
[66]
Navigate until a bottle is observed
-
[67]
Search the room for a trash bin and stop when found
-
[68]
Out-of-domain prompts:
Move through the environment until a person is detected. Out-of-domain prompts:
-
[69]
Locate a chair positioned near the doorway and stop 1 meter away
-
[70]
Search for a bottle while navigating around obstacles
-
[71]
Move through the corridor until a backpack is found
-
[72]
Find a person and stop immediately after detection
-
[73]
Listing 8: In-domain and held-out prompts for thebypass-objectskill (Jackal)
Search for a trash bin while avoiding furnitures. Listing 8: In-domain and held-out prompts for thebypass-objectskill (Jackal). Skill: bypass-object In-domain prompts:
-
[74]
Move forward for 5 meters while avoiding obstacles
-
[75]
Navigate to the doorway and bypass chairs blocking the path
-
[76]
Travel 4 meters while safely avoiding detected obstacles
-
[77]
Continue moving straight and reroute if an obstacle appears
-
[78]
Out-of-domain prompts:
Reach the hallway entrance while avoiding chairs or boxes. Out-of-domain prompts:
-
[79]
Move 6 meters forward while bypassing chairs
-
[80]
Navigate around a chair and continue to move ahead
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.