Do speech foundation models perceive speaker similarity as humans do?
Pith reviewed 2026-06-28 00:04 UTC · model grok-4.3
The pith
The distances between speaker embeddings in speech foundation models align with human judgments of speaker similarity under specific configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The numerical distance between speaker embeddings in speech foundation models can align with human-perceived speaker similarity, and specific factors in model configuration contribute to embeddings that better mirror human perception.
What carries the argument
Speaker embeddings whose numerical distances are compared against human subjective similarity scores, with analysis of model configuration factors that affect the match.
Load-bearing premise
Human subjective similarity scores collected from listeners accurately represent true human perception of speaker similarity and can serve as a reliable benchmark for model evaluation.
What would settle it
A new collection of human similarity ratings that shows no correlation with the embedding distances from the models and configurations identified as best-matching in the study.
Figures

read the original abstract
This study presents a comparative analysis between the speaker embeddings of speech foundation models and human subjective perception of speaker similarity. Human listeners have the ability to judge speaker similarity on a continuous scale discerning how similar two voices are. In contrast, speech foundation models embed speaker characteristics into numerical representation. However, a question remains: does the numerical distance between speaker embeddings in these models truly align with the similarity perceived by humans? To address this, we conduct a comprehensive investigation using more than 40 models to compare model-derived distances with human-perceived similarity scores. Furthermore, we identify which factors in model configuration contribute most to a speaker embedding that mirrors human perception. Our findings provide insights for the development of more perceptually grounded speech foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that numerical distances between speaker embeddings produced by more than 40 speech foundation models can be compared against human subjective similarity scores collected from listeners; the study identifies model-configuration factors (architecture, training data, etc.) that produce embeddings whose distances better match human perception of speaker similarity.
Significance. If the reported alignments are robust, the work supplies concrete, actionable guidance for training perceptually grounded speaker embeddings, which would benefit downstream applications such as speaker verification, diarization, and voice conversion that rely on human-like similarity judgments. The breadth of the model survey (40+) is a positive feature if the human benchmark is shown to be reliable.
major comments (2)
- [Methods (human similarity collection)] Methods section (human data collection): the central claim that model distances 'align with human-perceived speaker similarity' rests on the collected subjective scores being a stable, unbiased proxy. The manuscript must report (a) number of raters per pair, (b) inter-rater reliability statistics (e.g., ICC or Krippendorff’s alpha), (c) rating scale and instructions, and (d) controls for non-speaker cues (accent, lexical content, recording conditions). Absence of these metrics leaves open the possibility that reported correlations reflect noise or confounds rather than genuine perceptual correspondence.
- [Results] Results section (correlation analysis): the paper must demonstrate that the reported alignment is not driven by a small subset of models or by particular acoustic conditions in the stimuli. Provide per-model correlation coefficients together with confidence intervals and a breakdown by speaker gender, accent, or utterance length; without this, the claim that specific configuration factors 'contribute most' cannot be evaluated for robustness.
minor comments (2)
- [Abstract] Abstract and introduction: the phrase 'human subjective similarity scores' is used without an immediate forward reference to the collection protocol; add a parenthetical citation to the Methods subsection on the first occurrence.
- [Notation / Methods] Notation: clarify whether 'numerical distance' refers to cosine distance, Euclidean distance, or another metric, and state this consistently in all figures and tables that report alignment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: Methods section (human data collection): the central claim that model distances 'align with human-perceived speaker similarity' rests on the collected subjective scores being a stable, unbiased proxy. The manuscript must report (a) number of raters per pair, (b) inter-rater reliability statistics (e.g., ICC or Krippendorff’s alpha), (c) rating scale and instructions, and (d) controls for non-speaker cues (accent, lexical content, recording conditions). Absence of these metrics leaves open the possibility that reported correlations reflect noise or confounds rather than genuine perceptual correspondence.
Authors: We agree that these details are necessary to establish the reliability of the human similarity scores. The original manuscript described the data collection procedure at a high level but did not include the requested quantitative metrics or explicit controls. In the revised version we will expand the Methods section to report (a) the number of raters per pair, (b) inter-rater reliability (Krippendorff’s alpha), (c) the precise rating scale and instructions given to listeners, and (d) the steps taken to control for non-speaker cues such as accent, lexical content, and recording conditions. revision: yes
-
Referee: Results section (correlation analysis): the paper must demonstrate that the reported alignment is not driven by a small subset of models or by particular acoustic conditions in the stimuli. Provide per-model correlation coefficients together with confidence intervals and a breakdown by speaker gender, accent, or utterance length; without this, the claim that specific configuration factors 'contribute most' cannot be evaluated for robustness.
Authors: We accept that additional robustness checks are required. The revised Results section will include per-model Pearson (or Spearman) correlation coefficients with bootstrap confidence intervals. We will also add stratified analyses showing correlations broken down by speaker gender, accent, and utterance length to confirm that the reported alignments and the identified configuration factors are not driven by a small subset of models or specific stimulus properties. revision: yes
Circularity Check
No circularity: external human scores serve as independent benchmark
full rationale
The paper extracts speaker embeddings from >40 foundation models, computes numerical distances, and directly correlates them against separately collected human subjective similarity ratings. No equations define a target quantity in terms of itself, no parameters are fitted on a subset then relabeled as predictions, and no self-citations supply uniqueness theorems or ansatzes that close the loop. The central claim therefore rests on an external, falsifiable comparison rather than internal redefinition or renaming.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human listeners judge speaker similarity on a continuous scale.
Reference graph
Works this paper leans on
-
[1]
degree of similarity
Introduction Speech carries speaker information, which human listeners can effortlessly perceive [1]. Beyond simple speaker verification discerning whether two voices belong to the same speaker, hu- mans possess the ability to judge the degree of similarity or dissimilarity between different speakers [2]. Thisperceptual speaker similarity[3] represents a ...
-
[2]
Perceptual speaker similarity The perceptual speaker similarity score is derived by present- ing pairs of voices from two different speakers to human listen- ers
Related work 2.1. Perceptual speaker similarity The perceptual speaker similarity score is derived by present- ing pairs of voices from two different speakers to human listen- ers. The listeners were asked to quantify the degree of similar- ity. For instance, a previous work [3] asked multiple listeners to provide ratings on a7-point scale ranging from−3(...
-
[3]
Do speech foundation models perceive speaker similarity as humans do?
Methodology 3.1. Perceptual similarity LetSdenote a set of speakers. For any speaker pair(i, j)∈ Swherei̸=j, we define the perceptual similarity score as arXiv:2606.05739v3 [cs.SD] 17 Jun 2026 c(human) i,j ∈R. The complete set of these scores is represented as W (human) ={c (human) i,j |i, j∈S, i̸=j}. When represented as a weighted undirected graph, we de...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
higher is better,
Experiments 4.1. Experimental settings Perceptual similarity.We used two speech datasets contain- ing perceptual similarity scores: JVS (49males and51fe- males) [14] and VCTK (52females) 1 [15, 17]. In each dataset, 1Scores on VCTK male speakers are not publicly available. perceptual similarity scores in the range of[−3,3]are provided for all intra-gender...
-
[5]
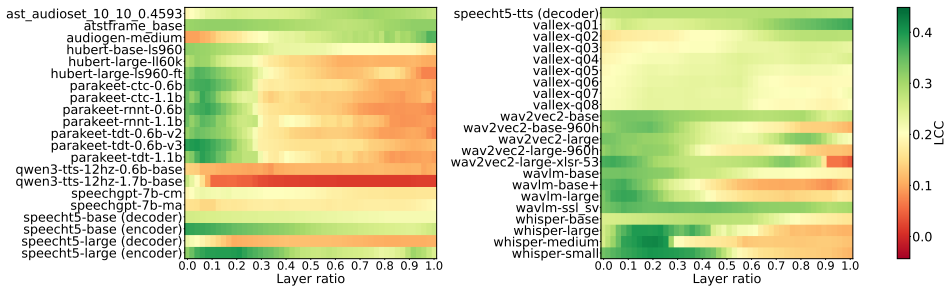
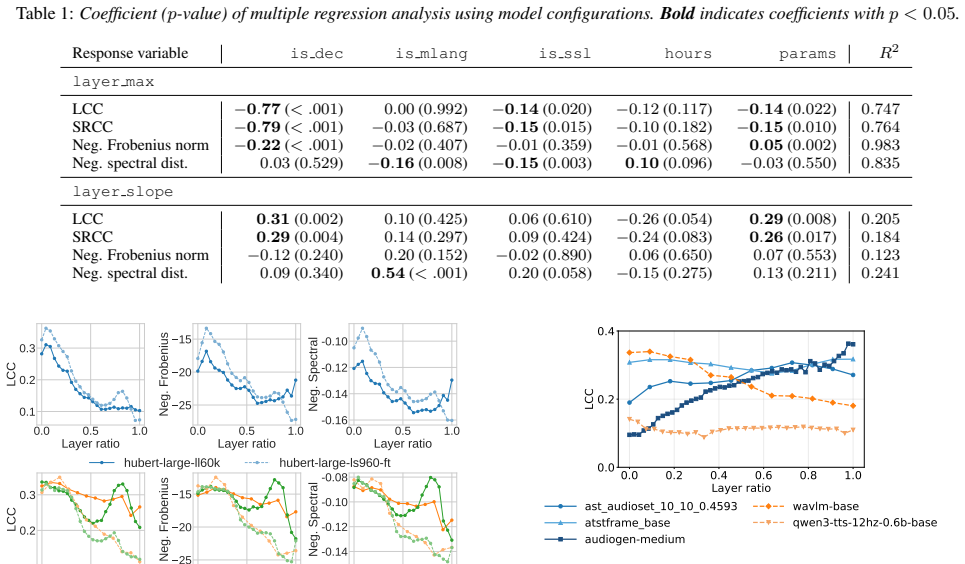
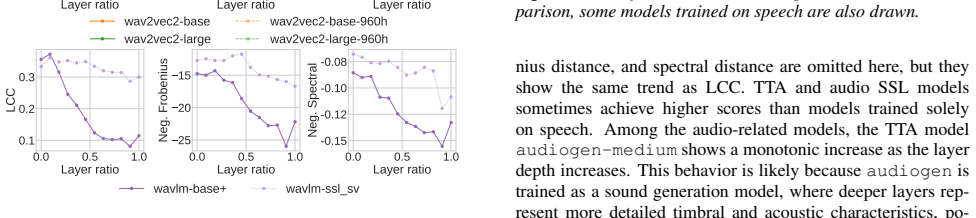
The results show that speech foundation models partially align with human perception, and that this alignment varies depend- ing on model configuration
Conclusion This study examined whether speaker representations in speech foundation models reflect human perceptual speaker similarity. The results show that speech foundation models partially align with human perception, and that this alignment varies depend- ing on model configuration. We also observed that layer-wise behavior depends on model configura...
-
[6]
Acknowledgments This work was supported by JST FOREST JPMJFR226V , JSPS KAKENHI 23K28108, and Moonshot R&D Grant Number JP- MJPS2011
-
[7]
Generative AI use disclosure ChatGPT was used for language polishing
-
[8]
V oice- selective areas in human auditory cortex,
P. Belin, R. Zatorre, P. Lafaille, P. Ahad, and B. Pike, “V oice- selective areas in human auditory cortex,”Nature, vol. 403, pp. 309–12, 2000
2000
-
[9]
Mea- surement of perceptual speaker similarity for sentence speech in ATR speech database,
T. Kitamura, T. Nakama, H. Ohmura, and H. Kawamoto, “Mea- surement of perceptual speaker similarity for sentence speech in ATR speech database,”Journal of the Acoustical Society of Japan, vol. 71, no. 10, pp. 516–525, 2015, (in Japanese)
2015
-
[10]
Perceptual-similarity- aware deep speaker representation learning for multi-speaker gen- erative modeling,
Y . Saito, S. Takamichi, and H. Saruwatari, “Perceptual-similarity- aware deep speaker representation learning for multi-speaker gen- erative modeling,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1033–1048, 2021
2021
-
[11]
A comparison of voice similar- ity through acoustics, human perception and deep neural network (DNN) speaker verification systems,
S. Liu, M. Babel, and J. Zhu, “A comparison of voice similar- ity through acoustics, human perception and deep neural network (DNN) speaker verification systems,” inInterspeech, 2024, pp. 3674–3678
2024
-
[12]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inNeurIPS, vol. 33, 2020, pp. 12 449–12 460
2020
-
[13]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[14]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[15]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inICML, 2023
2023
-
[16]
Fast conformer with linearly scalable attention for efficient speech recognition,
D. Rekesh, S. Kriman, S. Majumdar, V . Noroozi, H. Juang, O. Hrinchuk, A. Kumar, and B. Ginsburg, “Fast conformer with linearly scalable attention for efficient speech recognition,”ASRU, pp. 1–8, 2023
2023
-
[17]
Large-scale self-supervised speech representation learning for automatic speaker verification,
Z. Chen, S. Chen, Y . Wu, Y . Qian, C. Wang, S. Liu, Y . Qian, and M. Zeng, “Large-scale self-supervised speech representation learning for automatic speaker verification,” inICASSP, 2022, pp. 6147–6151
2022
-
[18]
Towards supervised per- formance on speaker verification with self-supervised learning by leveraging large-scale asr models,
V . Miara, T. Lepage, and R. Dehak, “Towards supervised per- formance on speaker verification with self-supervised learning by leveraging large-scale asr models,” inInterspeech, 2024, pp. 2660–2664
2024
-
[19]
A. Y . F. Chiu, K. C. Fung, R. T. Y . Li, J. Li, and T. Lee, “A large-scale probing analysis of speaker-specific at- tributes in self-supervised speech representations,”arXiv preprint arXiv:2501.05310, 2025
-
[20]
What do self-supervised speech and speaker models learn? new findings from a cross model layer-wise analysis,
T. Ashihara, M. Delcroix, T. Moriya, K. Matsuura, T. Asami, and Y . Ijima, “What do self-supervised speech and speaker models learn? new findings from a cross model layer-wise analysis,” in ICASSP, 2024, pp. 10 166–10 170
2024
-
[21]
JVS corpus: free japanese multi-speaker voice corpus,
S. Takamichi, K. Mitsui, Y . Saito, T. Koriyama, N. Tanji, and H. Saruwatari, “JVS corpus: free japanese multi-speaker voice corpus,”arXiv preprint arXiv:1908.06248, 2019
-
[22]
CSTR VCTK Cor- pus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Cor- pus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),” 2019
2019
-
[23]
On the encoding of gender in transformer-based asr representations,
A. Krishnan, B. M. Abdullah, and D. Klakow, “On the encoding of gender in transformer-based asr representations,” inInterspeech, 2024, p. 3090–3094
2024
-
[24]
DNN-based speaker embedding using subjective inter-speaker similarity for multi- speaker modeling in speech synthesis,
Y . Saito, S. Takamichi, and H. Saruwatari, “DNN-based speaker embedding using subjective inter-speaker similarity for multi- speaker modeling in speech synthesis,” inISCA SSW, 2019, pp. 97–102
2019
-
[25]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-TTS technical report,”arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
SpeechT5: Unified-modal encoder-decoder pre-training for spoken language processing,
J. Ao, R. Wang, L. Zhou, C. Wang, S. Ren, Y . Wu, S. Liu, T. Ko, Q. Li, Y . Zhang, Z. Wei, Y . Qian, J. Li, and F. Wei, “SpeechT5: Unified-modal encoder-decoder pre-training for spoken language processing,” inACL, 2022, pp. 5723–5738
2022
-
[27]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of the Associa- tion for Computational Linguistics: EMNLP, 2023, pp. 15 757– 15 773
2023
-
[28]
Z. Zhang, L. Zhou, C. Wang, S. Chen, Y . Wu, S. Liu, Z. Chen, Y . Yan, H. Liu, J. Jiaoet al., “Speak foreign languages with your native tongue: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023
-
[29]
AudioGen: Tex- tually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “AudioGen: Tex- tually guided audio generation,” inICLR, 2023
2023
-
[30]
AST: Audio spectrogram transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “AST: Audio spectrogram transformer,” inInterspeech, 2021, pp. 571–575
2021
-
[31]
Self-supervised audio teacher- student transformer for both clip-level and frame-level tasks,
X. Li, N. Shao, and X. Li, “Self-supervised audio teacher- student transformer for both clip-level and frame-level tasks,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 32, pp. 1336–1351, 2024
2024
-
[32]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” inASRU, 2021, pp. 914–921
2021
-
[33]
Speech representation analysis based on inter- and intra-model similarities,
Y . El Kheir, A. Ali, and S. A. Chowdhury, “Speech representation analysis based on inter- and intra-model similarities,” inICASSP Workshops, 2024, pp. 848–852
2024
-
[34]
A layer-wise analysis of mandarin and english suprasegmentals in ssl speech models,
A. Fuente and D. Jurafsky, “A layer-wise analysis of mandarin and english suprasegmentals in ssl speech models,” inInterspeech, 2024, pp. 1290–1294
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.