TempoVLA: Learning Speed-Controllable Vision-Language-Action Policies
Pith reviewed 2026-06-28 01:12 UTC · model grok-4.3
The pith
TempoVLA equips a single vision-language-action model with an explicit speed condition for controllable robot execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
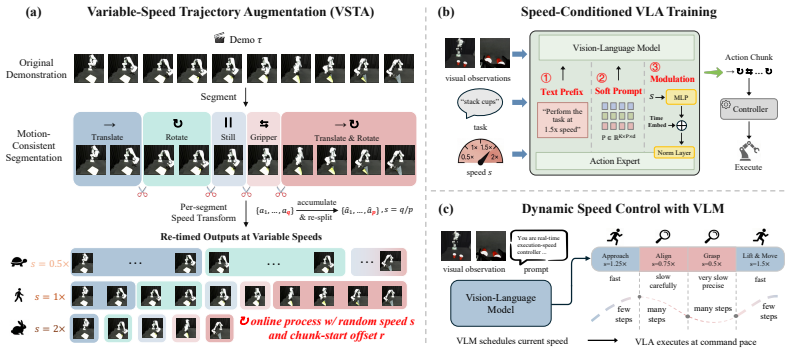
TempoVLA is a single VLA policy whose execution speed is controlled by an explicit condition, achieved through a data-side Variable-Speed Trajectory Augmentation (VSTA) that re-times demonstrations to any target speed by merging or splitting actions while preserving motion semantics, and a model-side conditioning mechanism that feeds the speed to the policy.
What carries the argument
The speed condition fed into the policy, paired with VSTA which re-times trajectories by merging or splitting actions to match requested speeds.
If this is right
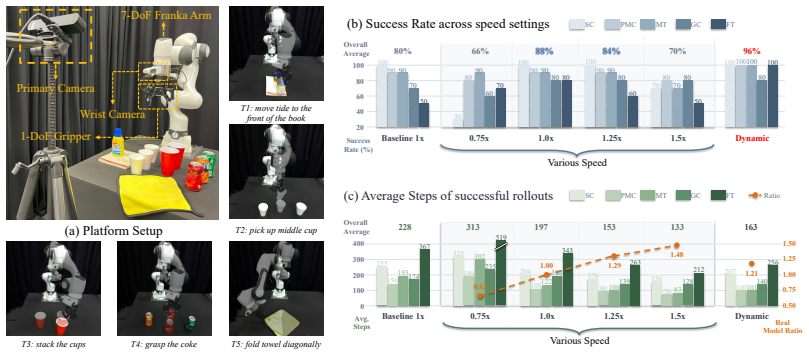
- TempoVLA achieves flexible speed control in both acceleration and deceleration directions.
- VSTA boosts the default 1× performance through better data utilization.
- Paired with a large multimodal model, TempoVLA enables dynamic speed control that accelerates in low-risk phases and decelerates in high-risk ones.
Where Pith is reading between the lines
- The conditioning approach might extend to controlling other action properties such as contact force.
- Similar re-timing augmentation could apply to other sequential policies where timing matters.
- Combining the speed signal with online risk estimation could produce adaptive behaviors in unstructured environments.
Load-bearing premise
The magnitude of each predicted action already governs how fast the robot moves.
What would settle it
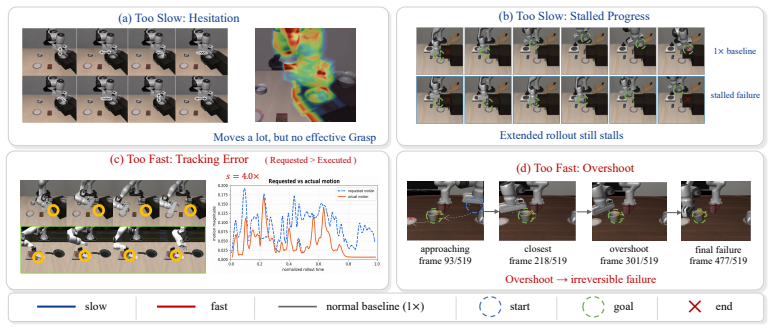
An experiment where varying the speed condition leaves actual execution speed unchanged, or where VSTA re-timing produces large motion deviations from the original trajectories.
Figures




read the original abstract
Robot manipulation alternates between low-risk transit phases that call for fast execution and high-risk contact stages that demand slow, precise motion. Yet existing Vision-Language-Action models (VLAs) only inherit a single fixed speed from training demonstrations. Prior efforts to accelerate VLAs through model compression, KV-cache reuse, or reinforcement learning only shift the policy from one fixed speed to another, and leave deceleration almost unexplored. We observe that the magnitude of each predicted action already governs how fast the robot moves, opening a direct route to controllable execution speed. We turn this observation into TempoVLA, a single VLA whose execution speed is controlled by an explicit condition. TempoVLA combines two coupled components. (1) A data-side Variable-Speed Trajectory Augmentation (VSTA) that re-times demonstration to any target speed by merging or splitting actions while preserving its motion semantics. (2) A model-side conditioning mechanism that feeds the speed to the policy. Statistics show that VSTA reaches the requested speed with negligible motion error. Experiments in simulation and on real-world tasks demonstrate that TempoVLA achieves flexible speed control in both directions, while VSTA additionally boosts the default $1\times$ performance via better data utilization. Furthermore, by cooperating with a large multimodal model, TempoVLA realizes dynamic speed control, accelerating through low-risk phases and decelerating for high-risk ones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TempoVLA, a single Vision-Language-Action (VLA) policy whose execution speed is made controllable via an explicit conditioning input. It rests on the observation that action magnitude already governs robot speed and proposes two coupled components: (1) Variable-Speed Trajectory Augmentation (VSTA) that re-times demonstrations to arbitrary target speeds by merging/splitting actions while preserving motion semantics, and (2) a model-side speed-conditioning mechanism. The abstract claims that VSTA achieves requested speeds with negligible motion error, that TempoVLA enables flexible bidirectional speed control in simulation and real tasks, that VSTA improves default 1× performance through better data utilization, and that integration with a large multimodal model enables dynamic speed adjustment (accelerating low-risk phases, decelerating high-risk ones).
Significance. If the central claims hold after validation, the work would be significant for practical robot manipulation, where tasks alternate between fast transit and slow precise contact phases; existing VLAs are limited to a single fixed speed inherited from demonstrations. The VSTA data-augmentation strategy is a concrete strength that demonstrably improves default-speed performance via better utilization of existing trajectories. No machine-checked proofs or open reproducible code are mentioned.
major comments (2)
- [Abstract] Abstract: The foundational observation that 'the magnitude of each predicted action already governs how fast the robot moves' is stated without any quantitative support (e.g., measured correlation between action norm and end-effector velocity on fixed trajectories, or ablation across absolute-position vs. delta action representations). This assumption is load-bearing for the conditioning mechanism and for the claim of bidirectional control; if actions are absolute positions or the low-level controller runs at fixed rate, magnitude changes would not produce the claimed speed changes.
- [Abstract] Abstract: The claim that 'Statistics show that VSTA reaches the requested speed with negligible motion error' and that TempoVLA achieves flexible control 'in both directions' is presented without any tables, error bars, ablation studies, or quantitative metrics. The absence of these data prevents verification of the central claim that VSTA preserves motion semantics while achieving requested speeds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript to incorporate additional quantitative support where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The foundational observation that 'the magnitude of each predicted action already governs how fast the robot moves' is stated without any quantitative support (e.g., measured correlation between action norm and end-effector velocity on fixed trajectories, or ablation across absolute-position vs. delta action representations). This assumption is load-bearing for the conditioning mechanism and for the claim of bidirectional control; if actions are absolute positions or the low-level controller runs at fixed rate, magnitude changes would not produce the claimed speed changes.
Authors: We agree that explicit quantitative validation of this observation would strengthen the manuscript. The assumption is based on the delta-action formulation standard in our VLA setup (detailed in Section 3), which allows magnitude to modulate velocity. In the revision we will add a correlation analysis and ablation on action representations to Section 3.1, with a brief reference in the abstract. revision: yes
-
Referee: [Abstract] Abstract: The claim that 'Statistics show that VSTA reaches the requested speed with negligible motion error' and that TempoVLA achieves flexible control 'in both directions' is presented without any tables, error bars, ablation studies, or quantitative metrics. The absence of these data prevents verification of the central claim that VSTA preserves motion semantics while achieving requested speeds.
Authors: The quantitative results, tables, error bars, and ablations supporting these claims appear in Sections 4.1–4.2 of the full manuscript. To make the abstract self-contained, we will revise it to include key metrics (e.g., speed error values) while retaining the summary style. revision: yes
Circularity Check
No significant circularity; speed control via explicit conditioning and data augmentation is independent of inputs
full rationale
The derivation relies on an empirical observation that action magnitude affects execution speed, followed by VSTA (re-timing demonstrations by merging/splitting actions) for data augmentation at variable speeds and an explicit speed-conditioning mechanism in the policy. Neither component reduces by construction to a fitted parameter or self-referential definition; the method augments training data and learns conditional behavior, which is externally falsifiable via execution metrics. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The approach is self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The magnitude of each predicted action governs how fast the robot moves.
- domain assumption Re-timing demonstrations by merging or splitting actions preserves motion semantics.
Forward citations
Cited by 1 Pith paper
-
Learning Action Priors for Cross-embodiment Robot Manipulation
A two-stage framework pretrains an action module with temporal motion priors from unconditioned trajectories using flow-matching, then transfers it to VLA training via decoder reuse and distillation, yielding better p...
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
K. Pertsch, K. Black, N. Brown, D. Driess, C. Finn, J. Mahler, O. Mees, D. Sadigh, et al.π 0.5: A vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[5]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[6]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: A dif- fusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, 2025
2025
-
[7]
J. Wen, Y . Zhu, J. Li, M. Zhu, K. Wu, Z. Xu, R. Cheng, C. Shen, Y . Peng, F. Feng, and J. Tang. TinyVLA: Towards fast, data-efficient vision-language-action models for robotic manipula- tion.arXiv preprint arXiv:2409.12514, 2024
Pith/arXiv arXiv 2024
-
[8]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. SmolVLA: A vision-language-action model for af- fordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[9]
Y . Yang, Y . Wang, Z. Wen, Z. Luo, C. Zou, Z. Zhang, C. Wen, and L. Zhang. EfficientVLA: Training-free acceleration and compression for vision-language-action models.arXiv preprint arXiv:2506.10100, 2025
arXiv 2025
-
[10]
K. Pertsch, K. Black, N. Brown, M. Y . Galliker, D. Driess, S. Nair, and S. Levine. FAST: Effi- cient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[11]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[12]
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
Pith/arXiv arXiv 2025
-
[13]
Y . Liu, H. Yu, J. Zhao, B. Li, D. Zhang, M. Li, W. Wu, Y . Hu, J. Xie, J. Guo, et al. Learning native continuation for action chunking flow policies.arXiv preprint arXiv:2602.12978, 2026
Pith/arXiv arXiv 2026
-
[14]
D. D. Yuan, T. Z. Zhao, K. Burns, and C. Finn. SpeedTuning: Speeding up policy execution with lightweight reinforcement learning. InIEEE International Conference on Robotics and Automation, pages 1184–1192, 2025. doi:10.1109/ICRA55743.2025.11128753
-
[15]
Y . Ma, Y . Zhou, Y . Yang, T. Wang, and H. Fan. Running vlas at real-time speed.arXiv preprint arXiv:2510.26742, 2025. 9
arXiv 2025
-
[16]
C. Yang, Y . Hu, Y . Ma, Y . Yang, J. Tan, and H. Fan. Realtime-VLA V2: Learning to run vlas fast, smooth, and accurate.arXiv preprint arXiv:2603.26360, 2026
arXiv 2026
-
[17]
W. Song, J. Chen, S. Chen, J. Wang, P. Ding, H. Zhao, Y . Qin, X. Zheng, D. Wang, Y . Wang, and H. Li. Fast-dVLA: Accelerating discrete diffusion vla to real-time performance.arXiv preprint arXiv:2603.25661, 2026
Pith/arXiv arXiv 2026
-
[18]
H. Park, D. Lim, S. Kim, and S. Park. Proleptic temporal ensemble for improving the speed of robot tasks generated by imitation learning.arXiv preprint arXiv:2410.16981, 2024
arXiv 2024
-
[19]
Z. Wu, J. Ye, Z. Zhang, Y . Sun, H. Lin, J. Luo, H. Ren, L. Yuan, and Y . Yu. Speedup patch: Learning a plug-and-play policy to accelerate embodied manipulation.arXiv preprint arXiv:2603.20658, 2026
arXiv 2026
-
[20]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[21]
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
- [22]
-
[23]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth-Maron, M. Gimenez, Y . Sulsky, J. Kay, J. T. Springenberg, et al. A generalist agent.arXiv preprint arXiv:2205.06175, 2022
Pith/arXiv arXiv 2022
- [24]
-
[25]
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauza, T. Davchev, Y . Zhou, A. Gupta, A. Raju, et al. RoboCat: A self-improving generalist agent for robotic manipulation. arXiv preprint arXiv:2306.11706, 2023
arXiv 2023
-
[26]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spa- tialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[27]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[28]
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, W. Zhang, H. Cui, Z. Zhang, and H. Wang. GraspVLA: a grasping foundation model pre-trained on billion-scale synthetic action data.arXiv preprint arXiv:2505.03233, 2025
Pith/arXiv arXiv 2025
-
[29]
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, L. Yi, W. Zeng, and X. Jin. DreamVLA: A vision-language-action model dreamed with comprehen- sive world knowledge.arXiv preprint arXiv:2507.04447, 2025
Pith/arXiv arXiv 2025
-
[30]
C. Cheang, S. Chen, Z. Cui, Y . Hu, L. Huang, T. Kong, H. Li, Y . Li, Y . Liu, X. Ma, et al. GR-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Pith/arXiv arXiv 2025
-
[31]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 10
Pith/arXiv arXiv 2025
-
[32]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[33]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[34]
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo. Em- bodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[35]
StarVLA-Community. StarVLA: A lego-like codebase for vision-language-action model de- veloping.arXiv preprint arXiv:2604.05014, 2026
Pith/arXiv arXiv 2026
-
[36]
D. Jing, G. Wang, J. Liu, W. Tang, Z. Sun, Y . Yao, Z. Wei, Y . Liu, Z. Lu, and M. Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Pith/arXiv arXiv 2025
-
[37]
A. Padalkar, A. Pollet, A. Jain, et al. Open x-embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[38]
A. Khazatsky, K. Pertsch, et al. DROID: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[39]
Walke, K
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, et al. BridgeData V2: A dataset for robot learning at scale. InConfer- ence on Robot Learning, 2023
2023
-
[40]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems Datasets and Benchmarks, 2023
2023
-
[41]
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martin-Martin. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
Pith/arXiv arXiv 2021
-
[42]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on Robot Learning, 2020
2020
-
[43]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning, 2023
2023
-
[44]
Dasari, F
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn. RoboNet: Large-scale multi-robot learning. InConference on Robot Learning, 2019
2019
- [45]
-
[46]
Nasiriany, S
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[47]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[48]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023. 11
2023
-
[49]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023
2023
-
[50]
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, K. Ghasemipour, C. Finn, and A. Wahid. ALOHA unleashed: A simple recipe for robot dexterity.arXiv preprint arXiv:2410.13126, 2024
arXiv 2024
-
[51]
L. Guo, Z. Xue, Z. Xu, and H. Xu. DemoSpeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration.arXiv preprint arXiv:2506.05064, 2025
arXiv 2025
-
[52]
T. Nam and S. J. Hwang. SpeedAug: Policy acceleration via tempo-enriched policy and RL fine-tuning.arXiv preprint arXiv:2512.00062, 2025
Pith/arXiv arXiv 2025
-
[53]
B. Kim, J. Pahk, C. Lee, J. Kim, J. Lee, T. T. Kim, K. Shim, J. K. Lee, and B.-T. Zhang. ESPADA: Execution speedup via semantics aware demonstration data downsampling for imi- tation learning.arXiv preprint arXiv:2512.07371, 2025
Pith/arXiv arXiv 2025
-
[54]
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousik, and D. Xu. SAIL: Faster-than-demonstration execution of imitation learning policies.arXiv preprint arXiv:2506.11948, 2025
arXiv 2025
-
[55]
Ratliff, M
N. Ratliff, M. Zucker, J. A. Bagnell, and S. Srinivasa. Chomp: Gradient optimization tech- niques for efficient motion planning. In2009 IEEE international conference on robotics and automation, pages 489–494. IEEE, 2009
2009
-
[56]
N. D. Ratliff, J. Issac, D. Kappler, S. Birchfield, and D. Fox. Riemannian motion policies. arXiv preprint arXiv:1801.02854, 2018
Pith/arXiv arXiv 2018
-
[57]
Sundaralingam, S
B. Sundaralingam, S. K. S. Hari, A. Fishman, C. Garrett, K. Van Wyk, V . Blukis, A. Millane, H. Oleynikova, A. Handa, F. Ramos, et al. Curobo: Parallelized collision-free robot motion generation. InIEEE International Conference on Robotics and Automation (ICRA), pages 8112–8119. IEEE, 2023
2023
-
[58]
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning.arXiv preprint arXiv:2604.02523, 2026
Pith/arXiv arXiv 2026
-
[59]
Shoemake
K. Shoemake. Animating rotation with quaternion curves. InProceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), pages 245–254, 1985
1985
-
[60]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. PaliGemma: A versatile 3B VLM for transfer. arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[61]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 12 A Hyperparameters Table 4: Training hyperparameters ofπ 0.5 on LIBERO. Hyperparameter Value GPUs 32×H20 Total Batch Size 512 Optimizer AdamW Scheduler Cosine Decay Learning ...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.