Breaking the Lock-in: Diversifying Text-to-Image Generation via Representation Modulation
Pith reviewed 2026-06-27 22:57 UTC · model grok-4.3
The pith
The zero-frequency DC component in Transformer features converges early across seeds and locks generation trajectories, limiting diversity in text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
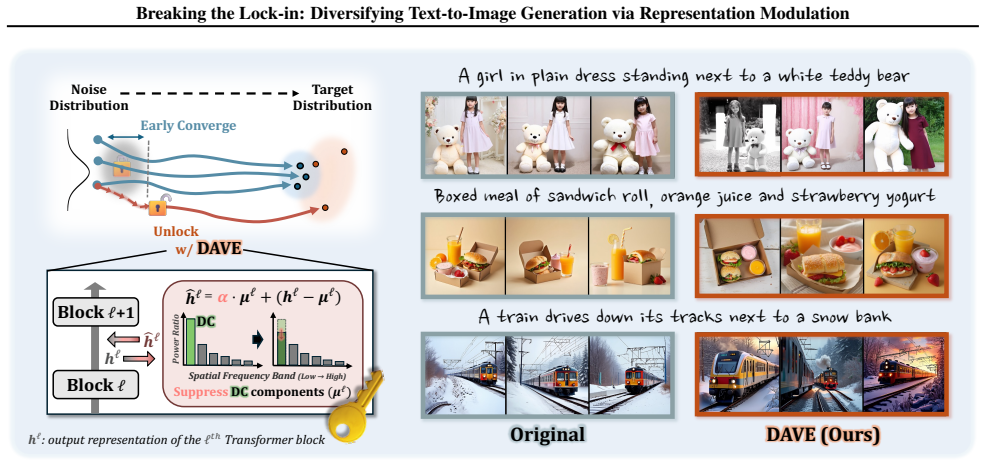
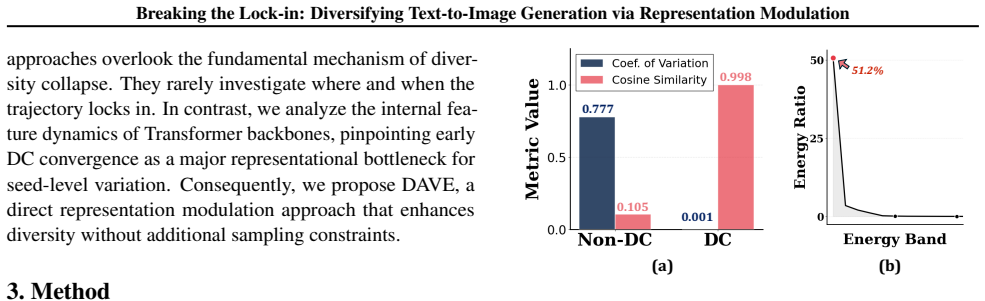
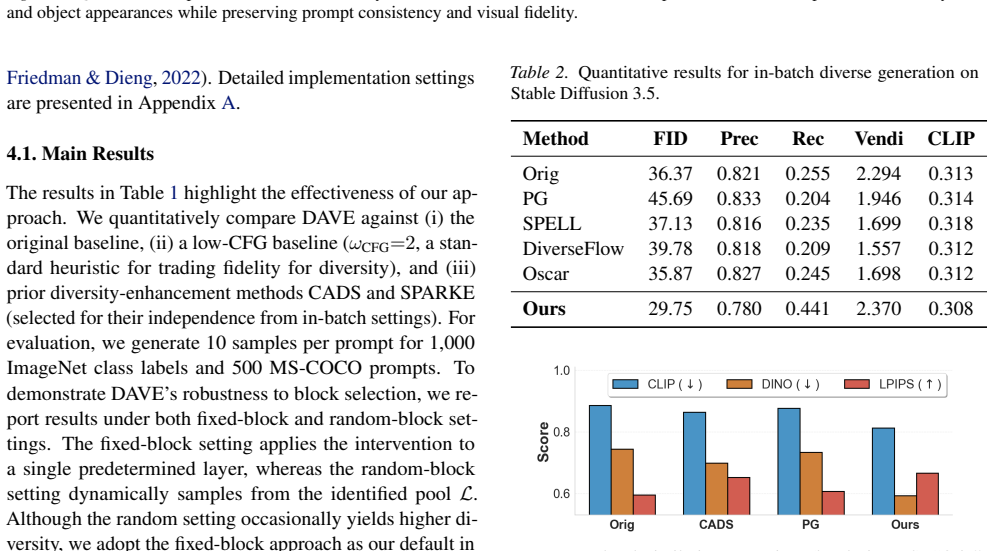
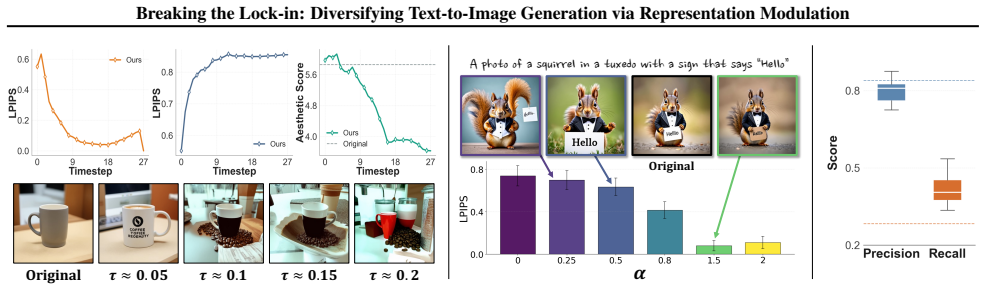
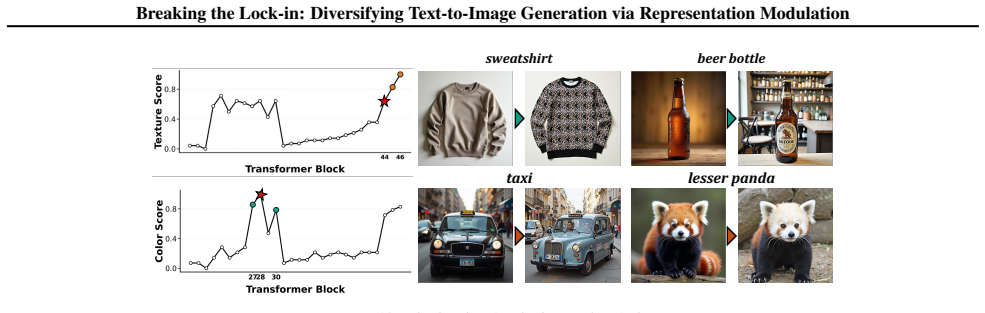
By examining intermediate Transformer features, we observe that the zero-frequency spatial average (DC) component rapidly converges across seeds early in generation, causing early trajectory lock-in that limits downstream variation. Building on this observation, we propose DC Attenuation for diVersity Enhancement (DAVE), a training-free representation-level intervention that selectively attenuates this component in the early regime. DAVE preserves the sampling pipeline with negligible overhead, improving prompt-consistent diversity while maintaining competitive image quality.
What carries the argument
DC Attenuation for diVersity Enhancement (DAVE), a training-free intervention that selectively attenuates the zero-frequency spatial average (DC) component of intermediate Transformer features during the early generation stages.
Load-bearing premise
The observed early convergence of the DC component is the direct cause of limited diversity rather than a correlated side effect of the generation dynamics.
What would settle it
Measure diversity, text-image alignment, and perceptual quality metrics on the same prompts and seeds with and without DAVE applied; if diversity rises while the other two metrics stay within a small tolerance of the baseline, the claim holds.
Figures




read the original abstract
Recent text-to-image models built on large-scale Transformer backbones and flow-based objectives deliver strong text-image alignment and high visual quality, yet often produce overly similar samples under a fixed prompt. Existing diversity-enhancement methods alleviate this issue, but typically require expensive sampling or auxiliary optimization, incurring non-trivial overhead. To investigate the root cause of this homogeneity, we examine intermediate Transformer features and observe that the zero-frequency spatial average (DC) component rapidly converges across seeds early in generation, causing early trajectory lock-in that limits downstream variation. Building on this observation, we propose DC Attenuation for diVersity Enhancement (DAVE), a training-free representation-level intervention that selectively attenuates this component in the early regime. DAVE preserves the sampling pipeline with negligible overhead, improving prompt-consistent diversity while maintaining competitive image quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that in Transformer-based text-to-image models using flow objectives, the zero-frequency (DC) spatial average of intermediate features converges rapidly across seeds in early generation steps, inducing trajectory lock-in that reduces output diversity for a fixed prompt. It proposes DAVE, a training-free intervention that selectively attenuates this DC component during the early regime to increase prompt-consistent diversity while preserving alignment and quality, with negligible overhead to the sampling pipeline.
Significance. If the causal link holds and quantitative gains are confirmed, DAVE would represent a lightweight, training-free approach to diversity enhancement that avoids the cost of auxiliary optimization or repeated sampling; the explicit focus on representation-level modulation and the training-free property are clear strengths.
major comments (3)
- [Abstract / §3] Abstract and §3 (observation of DC convergence): the claim that early DC convergence is the mechanistic cause of lock-in (rather than a correlated symptom of the flow dynamics or residual structure) is load-bearing for the motivation of DAVE, yet the manuscript provides no isolating controls such as matched-magnitude attenuation of non-DC frequency bands or phase-only perturbations.
- [§4] §4 (DAVE definition): the attenuation is described as selective and early-regime only, but without an explicit equation or pseudocode for the modulation operator (e.g., scaling factor α(t) applied to the DC term), it is impossible to verify that the intervention is DC-specific rather than a generic early-stage perturbation.
- [§5] §5 (experimental validation): the abstract and method claim improved diversity with preserved quality, but the absence of ablations that compare DAVE against non-DC early attenuation or late-regime attenuation leaves open whether reported gains are attributable to the DC hypothesis.
minor comments (2)
- [§3] Notation for the DC component (zero-frequency spatial average) should be defined once with an equation reference rather than repeated descriptively.
- [§4] The manuscript should report the precise definition of the 'early regime' (e.g., timestep threshold) as a fixed value or schedule to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that strengthen the causal evidence, clarity of the method, and experimental validation.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (observation of DC convergence): the claim that early DC convergence is the mechanistic cause of lock-in (rather than a correlated symptom of the flow dynamics or residual structure) is load-bearing for the motivation of DAVE, yet the manuscript provides no isolating controls such as matched-magnitude attenuation of non-DC frequency bands or phase-only perturbations.
Authors: We agree that isolating causality requires controls beyond observed correlation. While the temporal alignment between DC convergence and lock-in is robust across multiple models and seeds, we acknowledge the absence of matched non-DC or phase perturbations in the current manuscript. In the revision we will add these isolating ablations (non-DC attenuation at matched magnitude and phase-only perturbations) to §3 and §5, reporting their effect on diversity and alignment. revision: yes
-
Referee: [§4] §4 (DAVE definition): the attenuation is described as selective and early-regime only, but without an explicit equation or pseudocode for the modulation operator (e.g., scaling factor α(t) applied to the DC term), it is impossible to verify that the intervention is DC-specific rather than a generic early-stage perturbation.
Authors: We accept this criticism. The current description is insufficient for exact reproduction. We will insert a precise mathematical definition of the modulation operator in §4, specifying the DC extraction, the time-dependent scaling factor α(t) applied exclusively to the zero-frequency component, the early-regime window, and accompanying pseudocode. revision: yes
-
Referee: [§5] §5 (experimental validation): the abstract and method claim improved diversity with preserved quality, but the absence of ablations that compare DAVE against non-DC early attenuation or late-regime attenuation leaves open whether reported gains are attributable to the DC hypothesis.
Authors: We agree that these ablations are necessary to attribute gains specifically to DC modulation. We will add experiments comparing DAVE against (i) non-DC early attenuation at matched energy and (ii) late-regime DC attenuation, measuring diversity, text alignment, and perceptual quality. Results and analysis will be incorporated into the revised §5. revision: yes
Circularity Check
No circularity; empirical observation directly motivates training-free intervention
full rationale
The paper reports an empirical observation of early DC-component convergence across seeds in Transformer features, then introduces a simple attenuation intervention (DAVE) based on that observation. No equations define the target diversity metric in terms of the proposed attenuation, no parameters are fitted to diversity outcomes and then relabeled as predictions, and no load-bearing claims rest on self-citations or uniqueness theorems. The derivation chain is therefore self-contained: the intervention is a direct, non-tautological response to the stated observation rather than a re-expression of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2011.13456 , year=
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
Pith/arXiv arXiv 2011
-
[2]
arXiv preprint arXiv:2412.08175 , year=
Analyzing and Mitigating Model Collapse in Rectified Flow Models , author=. arXiv preprint arXiv:2412.08175 , year=
-
[3]
arXiv preprint arXiv:2209.15571 , year=
Building normalizing flows with stochastic interpolants , author=. arXiv preprint arXiv:2209.15571 , year=
-
[4]
arXiv preprint arXiv:2310.17347 , year=
CADS: Unleashing the diversity of diffusion models through condition-annealed sampling , author=. arXiv preprint arXiv:2310.17347 , year=
-
[5]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
DiverseFlow: Sample-Efficient Diverse Mode Coverage in Flows , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[6]
arXiv preprint arXiv:2410.06025 , year=
Shielded Diffusion: Generating Novel and Diverse Images using Sparse Repellency , author=. arXiv preprint arXiv:2410.06025 , year=
-
[7]
arXiv preprint arXiv:2310.13102 , year=
Particle guidance: non-iid diverse sampling with diffusion models , author=. arXiv preprint arXiv:2310.13102 , year=
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Exploring multimodal diffusion transformers for enhanced prompt-based image editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
arXiv preprint arXiv:2601.02211 , year=
Unraveling MMDiT Blocks: Training-free Analysis and Enhancement of Text-conditioned Diffusion , author=. arXiv preprint arXiv:2601.02211 , year=
-
[10]
arXiv preprint arXiv:2108.02938 , year=
Ilvr: Conditioning method for denoising diffusion probabilistic models , author=. arXiv preprint arXiv:2108.02938 , year=
-
[11]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[12]
arXiv preprint arXiv:2512.02826 , year=
From Navigation to Refinement: Revealing the Two-Stage Nature of Flow-based Diffusion Models through Oracle Velocity , author=. arXiv preprint arXiv:2512.02826 , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
An analytical theory of spectral bias in the learning dynamics of diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
International conference on machine learning , pages=
On the spectral bias of neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Freeu: Free lunch in diffusion u-net , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Enhancing creative generation on stable diffusion-based models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[17]
arXiv preprint arXiv:2507.01496 , year=
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation , author=. arXiv preprint arXiv:2507.01496 , year=
-
[18]
Fluxspace: Disentangled semantic editing in rectified flow transformers , author=. URL https://arxiv. org/abs/2412.09611 , year=
-
[19]
arXiv preprint arXiv:2511.15258 , year=
SplitFlux: Learning to Decouple Content and Style from a Single Image , author=. arXiv preprint arXiv:2511.15258 , year=
-
[20]
IEEE transactions on pattern analysis and machine intelligence , volume=
Diffusion models in vision: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2023 , publisher=
2023
-
[21]
arXiv preprint arXiv:2208.01626 , year=
Prompt-to-prompt image editing with cross attention control , author=. arXiv preprint arXiv:2208.01626 , year=
-
[22]
arXiv preprint arXiv:2303.09522 , year=
p+: Extended textual conditioning in text-to-image generation , author=. arXiv preprint arXiv:2303.09522 , year=
-
[23]
Design Science , volume=
How generative AI supports human in conceptual design , author=. Design Science , volume=. 2025 , publisher=
2025
-
[24]
European conference on computer vision , pages=
Microsoft coco: Common objects in context , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[25]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[26]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[27]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[28]
arXiv preprint arXiv:2209.03003 , year=
Flow straight and fast: Learning to generate images with rectified flow , author=. arXiv preprint arXiv:2209.03003 , year=
-
[29]
International Conference on Learning Representations , year=
Spectral Normalization for Generative Adversarial Networks , author=. International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[31]
2006 , publisher=
Pattern recognition and machine learning , author=. 2006 , publisher=
2006
-
[32]
Advances in neural information processing systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in neural information processing systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Fourier features let networks learn high frequency functions in low dimensional domains , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2210.02410 , year=
The vendi score: A diversity evaluation metric for machine learning , author=. arXiv preprint arXiv:2210.02410 , year=
-
[35]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[36]
arXiv preprint arXiv:2501.18427 , year=
Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer , author=. arXiv preprint arXiv:2501.18427 , year=
-
[37]
Journal of the Royal Statistical Society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal Statistical Society: series B (Methodological) , volume=. 1995 , publisher=
1995
-
[38]
IEEE Access , volume=
The power of generative ai to augment for enhanced skin cancer classification: A deep learning approach , author=. IEEE Access , volume=. 2023 , publisher=
2023
-
[39]
arXiv preprint arXiv:2307.08702 , year=
Diffusion models beat gans on image classification , author=. arXiv preprint arXiv:2307.08702 , year=
-
[40]
arXiv preprint arXiv:2406.10429 , year=
Consistency-diversity-realism Pareto fronts of conditional image generative models , author=. arXiv preprint arXiv:2406.10429 , year=
-
[41]
arXiv preprint arXiv:2511.10547 , year=
Benchmarking Diversity in Image Generation via Attribute-Conditional Human Evaluation , author=. arXiv preprint arXiv:2511.10547 , year=
-
[42]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Minority-Focused Text-to-Image Generation via Prompt Optimization , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[43]
arXiv preprint arXiv:2601.00090 , year=
It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models , author=. arXiv preprint arXiv:2601.00090 , year=
-
[44]
arXiv preprint arXiv:2103.00020 , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. arXiv preprint arXiv:2103.00020 , year=
-
[45]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[46]
arXiv preprint arXiv:2206.10789 , volume=
Scaling autoregressive models for content-rich text-to-image generation , author=. arXiv preprint arXiv:2206.10789 , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
SPARKE: Scalable prompt-aware diversity and novelty guidance in diffusion models via RKE score , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
arXiv preprint arXiv:2510.09060 , year=
OSCAR: Orthogonal Stochastic Control for Alignment-Respecting Diversity in Flow Matching , author=. arXiv preprint arXiv:2510.09060 , year=
-
[49]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[50]
International conference on machine learning , pages=
Reliable fidelity and diversity metrics for generative models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.