PandaAI: A Practical Agent CQ2 for Neuro-symbolic Data Analysis And Integrated Decision-Making in Quantitative Finance
Pith reviewed 2026-06-27 22:48 UTC · model grok-4.3
The pith
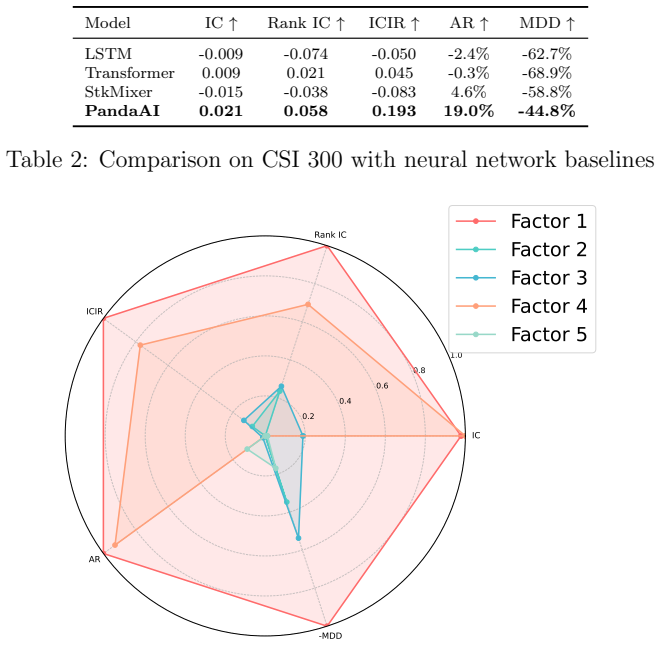
PandaAI deploys a closed-loop neuro-symbolic LLM agent that raises Rank IC by 18.2 percent and lowers maximum drawdown by 25.7 percent versus time-series models on CSI 300 data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PandaAI is a closed-loop neuro-symbolic LLM agent with market regime modeling and constrained alpha generation that fine-tunes a domain-specific model and integrates it modularly to bridge general reasoning with financial rigor. The agent navigates real-world markets with explicit risk awareness instead of optimizing isolated prediction metrics. On CSI 300 stock data it records an 18.2 percent higher Rank IC and 25.7 percent lower maximum drawdown than state-of-the-art time-series models, while its constrained generation and dual-channel adaptation supply a general paradigm for deploying LLMs in sequential financial decision-making.
What carries the argument
The closed-loop neuro-symbolic LLM agent equipped with market regime modeling and constrained alpha generation, which fine-tunes domain-specific reasoning and applies dual-channel adaptation to enforce financial constraints during output generation.
If this is right
- The agent can shift optimization from isolated prediction metrics to integrated, risk-aware sequential decisions.
- Constrained generation combined with dual-channel adaptation supplies a reusable method for limiting LLM outputs in finance.
- A modular closed-loop structure allows the system to adapt to changing market regimes during live operation.
- The same architecture offers a template for applying LLMs to other high-stakes sequential decision domains.
Where Pith is reading between the lines
- Extending the evaluation to additional asset classes such as futures or options could test whether the neuro-symbolic structure transfers beyond equities.
- Adding explicit handling of macroeconomic announcements might strengthen the agent's response to abrupt non-stationarity.
- Measuring the agent's behavior under different fine-tuning data volumes would clarify how much domain-specific training is required for the gains.
Load-bearing premise
The reported gains on CSI 300 data will generalize to other markets and periods, and the constrained generation will reduce unreliable outputs without creating new selection biases or overfitting.
What would settle it
Running the same evaluation protocol on a separate equity index such as the S&P 500 across a later time window and obtaining no measurable lift in Rank IC or reduction in maximum drawdown would show the gains do not hold.
Figures

read the original abstract
While deep learning has excelled in various domains, its application to sequential decision-making in finance remains challenging due to the low Signal-to-Noise Ratio (SNR) and non-stationarity of financial data. Leveraging the reasoning capabilities of Large Language Models (LLMs), we propose \textbf{PandaAI}, a closed-loop neuro-symbolic LLM agent with market regime modeling and constrained alpha generation, which bridges general LLM reasoning with financial rigor and suppresses the financial toxicity of LLM-generated outputs. To bridge the gap between general linguistic capability and financial rigor, we fine-tune a domain-specific LLM. Furthermore, we integrate this LLM into a modular architecture and form a closed-loop system. Unlike traditional models that optimize isolated prediction metrics, \textbf{PandaAI} is designed as a neuro-symbolic agent that navigates the complex, real-world financial environment with explicit risk awareness. Extensive experiments on CSI 300 stock data show that \textbf{PandaAI} achieves a $18.2\%$ higher Rank IC and $25.7\%$ lower maximum drawdown than state-of-the-art time-series models. Our constrained LLM generation and dual-channel adaptation method provide a general paradigm for LLM deployment in high-stakes sequential decision-making scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PandaAI, a closed-loop neuro-symbolic LLM agent for quantitative finance that combines a fine-tuned domain-specific LLM with market regime modeling, constrained alpha generation, and dual-channel adaptation. It claims this architecture bridges general LLM reasoning with financial rigor, suppresses financial toxicity, and outperforms state-of-the-art time-series models by achieving 18.2% higher Rank IC and 25.7% lower maximum drawdown on CSI 300 stock data.
Significance. If the empirical claims are substantiated, the work could establish a practical paradigm for deploying LLMs in high-stakes sequential decision-making under low SNR and non-stationarity, with explicit risk awareness and closed-loop integration of symbolic constraints.
major comments (2)
- [Abstract] Abstract and Experiments section: the headline claims of 18.2% Rank IC improvement and 25.7% lower maximum drawdown versus time-series SOTA are presented without data splits, number of trials, statistical significance tests on the deltas, or out-of-distribution evaluation on other markets or regimes.
- [Method] Method and Experiments sections: no ablation studies isolate the contribution of constrained LLM generation and dual-channel adaptation to toxicity suppression versus potential dataset-specific tuning or selection bias, which is load-bearing for the central neuro-symbolic advantage.
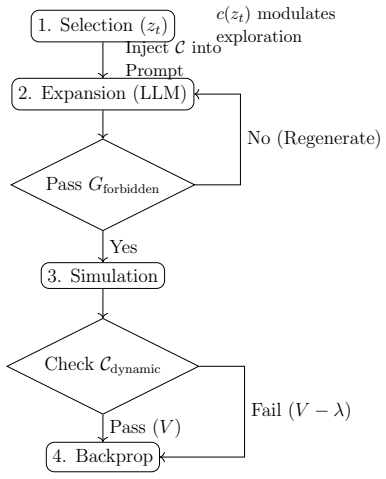
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the headline claims of 18.2% Rank IC improvement and 25.7% lower maximum drawdown versus time-series SOTA are presented without data splits, number of trials, statistical significance tests on the deltas, or out-of-distribution evaluation on other markets or regimes.
Authors: We agree that the headline empirical claims require supporting details on data splits, number of trials, and statistical significance tests. We will add these to the Experiments section and revise the abstract accordingly. For out-of-distribution evaluation, our work centers on CSI 300 as a representative low-SNR market; we will include a limitations discussion on generalization in the revision. revision: partial
-
Referee: [Method] Method and Experiments sections: no ablation studies isolate the contribution of constrained LLM generation and dual-channel adaptation to toxicity suppression versus potential dataset-specific tuning or selection bias, which is load-bearing for the central neuro-symbolic advantage.
Authors: We agree that ablation studies are necessary to isolate the contributions of constrained LLM generation and dual-channel adaptation. We will add these experiments to the revised manuscript to demonstrate their specific role in toxicity suppression and to address potential concerns about dataset-specific effects. revision: yes
Circularity Check
No circularity; empirical performance claims rest on experimental outcomes with no visible derivation chain or self-referential fitting
full rationale
The provided abstract and text describe an LLM-based agent architecture and report experimental metrics (18.2% Rank IC lift, 25.7% lower max drawdown on CSI 300) but contain no equations, parameter-fitting steps, or self-citations that reduce any claimed result to its own inputs by construction. The neuro-symbolic components are presented as design choices whose efficacy is asserted via external evaluation rather than internal redefinition or renormalization. No load-bearing derivation exists to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforce- ment learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforce- ment learning, 2025
2025
-
[2]
Bert: Pre- training of deep bidirectional transformers for language understanding, 2019
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre- training of deep bidirectional transformers for language understanding, 2019
2019
-
[3]
Stockmixer: a simple yet strong mlp-based architec- ture for stock price forecasting
Jinyong Fan and Yanyan Shen. Stockmixer: a simple yet strong mlp-based architec- ture for stock price forecasting. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Arti- ficial Intelligence, AAA...
2024
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
2024
-
[5]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guant- ing Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming – the rise of code intelligence, 2024
2024
-
[6]
Princeton university press, 2020
James D Hamilton.Time series analysis. Princeton university press, 2020
2020
-
[7]
Long short-term memory.Neural Com- putation, 9(8):1735–1780, 1997
Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory.Neural Com- putation, 9(8):1735–1780, 1997
1997
-
[8]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
2022
-
[9]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. InInternational conference on learning representations, 2021
2021
-
[10]
Berg, Wan-Yen Lo, Piotr Doll´ ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll´ ar, and Ross Girshick. Segment anything, 2023
2023
-
[11]
Genetic programming: on the programming of computers by means of natural selection cambridge.MA: MIT Press.[Google Scholar], 1992
John R Koza. Genetic programming: on the programming of computers by means of natural selection cambridge.MA: MIT Press.[Google Scholar], 1992. 13
1992
-
[12]
Revisiting catastrophic forgetting in large language model tuning
Hongyu Li, Liang Ding, Meng Fang, and Dacheng Tao. Revisiting catastrophic forgetting in large language model tuning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4297–4308, Miami, Florida, USA, November 2024. Association for Computational Linguistics
2024
-
[13]
Yang Li, Yangyang Yu, Haohang Li, Zhi Chen, and Khaldoun Khashanah. Trading- gpt: Multi-agent system with layered memory and distinct characters for enhanced financial trading performance.arXiv preprint arXiv:2309.03736, 2023
arXiv 2023
-
[14]
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625, 2023
Pith/arXiv arXiv 2023
-
[15]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[16]
Generative agents: Interactive simulacra of hu- man behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of hu- man behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[17]
Brenden K Petersen, Mikel Landajuela, T Nathan Mundhenk, Claudio P Santi- ago, Soo K Kim, and Joanne T Kim. Deep symbolic regression: Recovering math- ematical expressions from data via risk-seeking policy gradients.arXiv preprint arXiv:1912.04871, 2019
arXiv 1912
-
[18]
Xing, Sham M
Zhenting Qi, Fan Nie, Alexandre Alahi, James Zou, Himabindu Lakkaraju, Yilun Du, Eric P. Xing, Sham M. Kakade, and Hanlin Zhang. EvoLM: In search of lost lan- guage model training dynamics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
2017
-
[20]
Barra’s risk models.Barra Research Insights, pages 1–24, 1996
Aamir Sheikh. Barra’s risk models.Barra Research Insights, pages 1–24, 1996
1996
-
[21]
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
-
[22]
Yu Shi, Yitong Duan, and Jian Li. Navigating the alpha jungle: An llm-powered mcts framework for formulaic factor mining.arXiv preprint arXiv:2505.11122, 2025
arXiv 2025
-
[23]
Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize 14 from human feedback. InProceedings of the 34th International Conference on Neu- ral Information Processing Systems, NIPS ’20, Red Hook, NY, USA, 2020. Curran Associates Inc
2020
-
[24]
Deepscalper: A risk-aware reinforcement learning framework to capture fleeting in- traday trading opportunities
Shuo Sun, Wanqi Xue, Rundong Wang, Xu He, Junlei Zhu, Jian Li, and Bo An. Deepscalper: A risk-aware reinforcement learning framework to capture fleeting in- traday trading opportunities. InProceedings of the 31st ACM International Confer- ence on Information & Knowledge Management, pages 1858–1867, 2022
2022
-
[25]
Lafs: Landmark-based facial self-supervised learning for face recognition
Zhonglin Sun, Chen Feng, Ioannis Patras, and Georgios Tzimiropoulos. Lafs: Landmark-based facial self-supervised learning for face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1639–1649, June 2024
2024
-
[26]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, L ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[27]
Alpha-gpt: Human-ai interactive alpha mining for quantitative investment
Saizhuo Wang, Hang Yuan, Leon Zhou, Lionel Ni, Heung Yeung Shum, and Jian Guo. Alpha-gpt: Human-ai interactive alpha mining for quantitative investment. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 196–206, 2025
2025
-
[28]
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186, 2022
Pith/arXiv arXiv 2022
-
[29]
Vasilakos, and Thippa Reddy Gadekallu
Gokul Yenduri, Ramalingam M, Chemmalar Selvi G, Supriya Y, Gautam Srivastava, Praveen Kumar Reddy Maddikunta, Deepti Raj G, Rutvij H Jhaveri, Prabadevi B, Weizheng Wang, Athanasios V. Vasilakos, and Thippa Reddy Gadekallu. Generative pre-trained transformer: A comprehensive review on enabling technologies, potential applications, emerging challenges, and ...
2023
-
[30]
Generating synergistic formulaic alpha collections via reinforcement learning
Shuo Yu, Hongyan Xue, Xiang Ao, Feiyang Pan, Jia He, Dandan Tu, and Qing He. Generating synergistic formulaic alpha collections via reinforcement learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5476–5486, 2023
2023
-
[31]
A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist
Wentao Zhang, Lingxuan Zhao, Haochong Xia, Shuo Sun, Jiaze Sun, Molei Qin, Xinyi Li, Yuqing Zhao, Yilei Zhao, Xinyu Cai, et al. A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist. InProceedings of the 30th acm sigkdd conference on knowledge discovery and data mining, pages 4314–4325, 2024
2024
-
[32]
Doubleadapt: A meta-learning ap- proach to incremental learning for stock trend forecasting
Lifan Zhao, Shuming Kong, and Yanyan Shen. Doubleadapt: A meta-learning ap- proach to incremental learning for stock trend forecasting. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3492–3503, 2023. 15 6 Appendix Symbol Description zt Continuous latent market regime state at timet. CGlobal set of financial a...
2023
-
[33]
Selection (Regime-Adaptive):Nodes are selected using a modified UCT algo- rithm where the exploration constantcis not static but modulated by the market state zt: UCT(s) = Q(s) N(s) +c(z t)· s lnN(parent) N(s) (2) Here,c(z t) is inversely proportional to the market entropy detected byM. In stable regimes,c(z t) increases to encourage broad exploration; in...
-
[34]
Expansion (Constrained Generation):The LLM θ acts as the policy network π(a|s, zt). To operationalizeConstraints as A Priori Regularization, we clarify the relationship between the static syntax rulesG forbidden (in Algorithm 1) and the dynamic risk constraintsC(updated by ModuleU): specifically,G forbidden ⊂ C. During generation, we employ a”Prompt-Check...
-
[35]
Although obvious violations are filtereda priori, subtle financial toxicities (e.g., high correlation with existing factors) can only be detecteda posteriori
Simulation (Feedback & Soft Penalty):Candidates passing the expansion fil- ter undergo backtesting. Although obvious violations are filtereda priori, subtle financial toxicities (e.g., high correlation with existing factors) can only be detecteda posteriori. Thus, we define the node value functionV(f) with a penalty term for these residual violations: V(f...
-
[36]
6.2 Detailed Fine-TuningT The fine-tuning dataset is not publicly available due to privacy obligations to clients and restrictions imposed by non-disclosure agreements
Backpropagation:The evaluation signals are propagated to update the node statistics, progressively steering the LLM towards the ”valid and robust” subspace of the alpha universe. 6.2 Detailed Fine-TuningT The fine-tuning dataset is not publicly available due to privacy obligations to clients and restrictions imposed by non-disclosure agreements. 6.2.1 Sup...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.