MailoHLS: Multi-Adapter Structure-Aware Learning for Pareto-Driven HLS Pragma Optimization
Pith reviewed 2026-06-27 20:28 UTC · model grok-4.3
The pith
A hybrid LLM-GNN model with objective adapters optimizes HLS pragmas to near-Pareto designs across seen and unseen kernels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
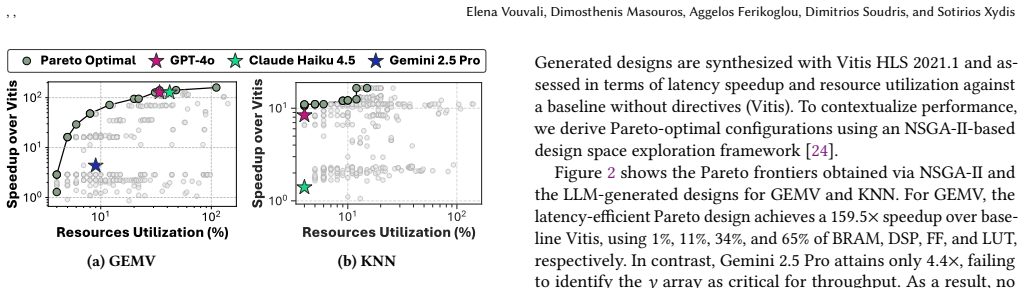
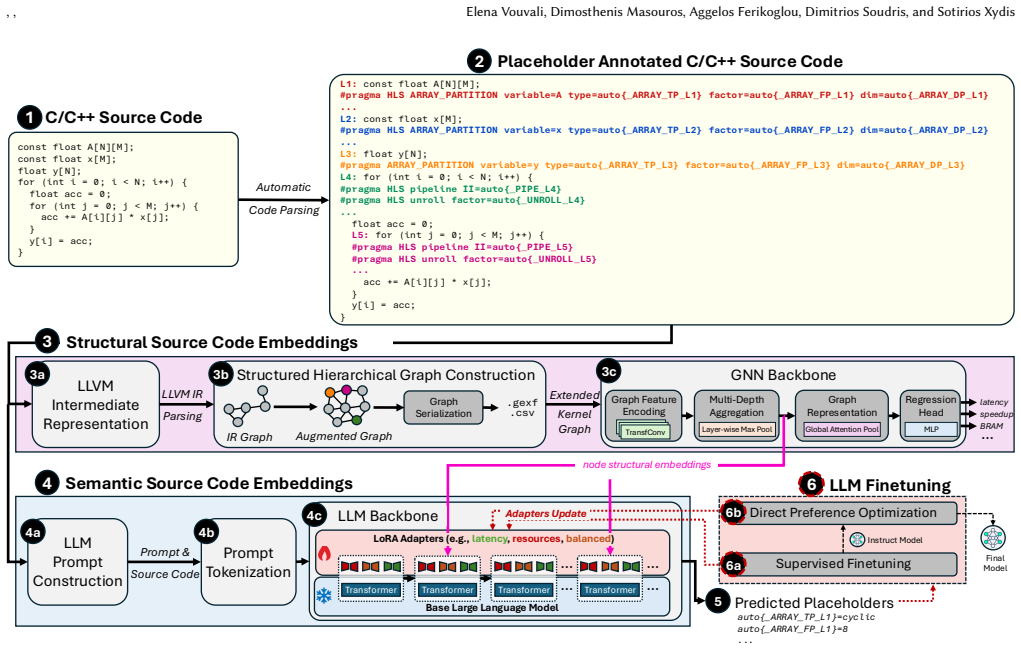
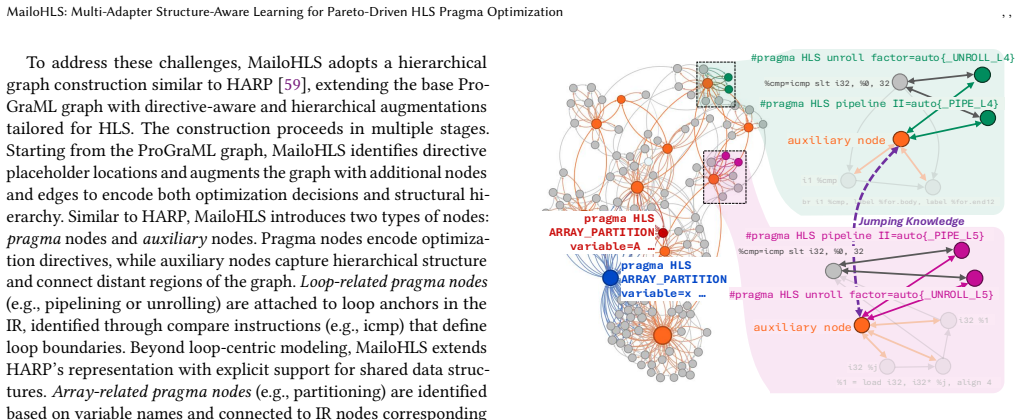
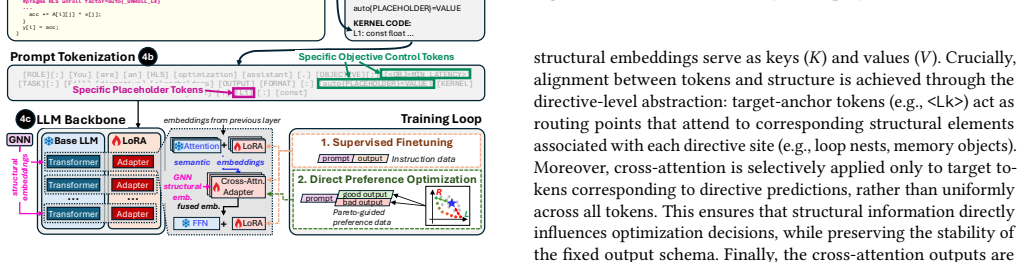
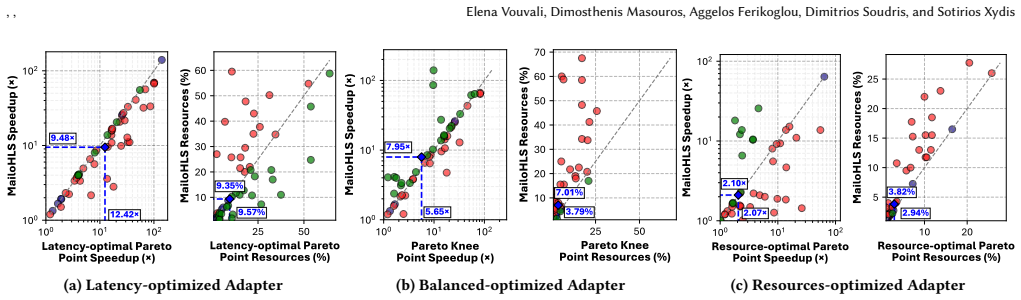
MailoHLS is a hybrid framework that combines LLM-based semantic reasoning with GNN-based structural modeling for objective-aware directive optimization. By integrating structural embeddings via cross-attention and leveraging PEFT with objective-conditioned LoRA adapters and Pareto-driven optimization, MailoHLS enables joint reasoning over code semantics, structure, and design trade-offs. Across seen and unseen kernels, MailoHLS achieves up to 12.42x and 8.4x speedup (9.48x and 4.97x geometric mean) for latency optimization, consistently producing near-Pareto-optimal designs. On fully unseen applications, it reaches up to 10.2x speedup (6.58x geometric mean), outperforming high-end LLMs and p
What carries the argument
Cross-attention fusion of LLM semantic embeddings and GNN structural embeddings, conditioned on objectives through separate LoRA adapters and driven by Pareto search.
If this is right
- The approach yields up to 12.42x latency speedup on seen kernels and 10.2x on fully unseen applications while staying near the Pareto front.
- Objective-conditioned adapters allow the same base model to handle multiple, conflicting design goals without separate retraining.
- Structural embeddings from GNNs compensate for the sequential nature of LLM representations when modeling dataflow and memory dependencies.
- Pareto-driven search during inference produces designs that outperform both prior heuristic and learning-based methods on multi-objective HLS tasks.
Where Pith is reading between the lines
- The same fusion pattern could be tested on other directive-based compiler problems such as OpenMP or CUDA pragma selection.
- The results suggest that explicit multi-objective conditioning during adaptation may be more effective than post-hoc ranking for trade-off problems in code generation.
- If the cross-attention layer proves critical, simpler concatenation baselines could be run to quantify how much structural information is actually transferred.
- Extending the method to include dynamic memory access patterns extracted at runtime might further improve accuracy on data-intensive kernels.
Load-bearing premise
That cross-attention between LLM semantic embeddings and GNN structural embeddings, together with objective-conditioned adapters and Pareto search, will jointly capture program structure, memory behavior, and conflicting objectives well enough to generalize beyond the training kernels.
What would settle it
Evaluating the trained model on a fresh collection of complex, previously unseen HLS kernels and finding that speedups fall to the level of plain LLM prompting or that produced designs lie far from the true Pareto frontier would falsify the generalization and superiority claims.
Figures





read the original abstract
High-Level Synthesis (HLS) enables rapid development of FPGA accelerators, yet achieving high-quality results (QoR) remains challenging due to the large and irregular design space induced by compiler directives (a.k.a pragmas). Selecting effective configurations requires reasoning over complex interactions between program structure, memory behavior, and often conflicting objectives such as latency and resource utilization. Prior model-driven approaches exhibit limited generalization across kernels and fail to capture higher-level optimization intent. Recently, Large Language Models (LLMs) capture code semantics and high-level intent, but their sequential representations hinder modeling of structural dependencies and global trade-offs, leading to suboptimal HLS designs. We present MailoHLS, a hybrid framework that combines LLM-based semantic reasoning with GNN-based structural modeling for objective-aware directive optimization. By integrating structural embeddings via cross-attention and leveraging PEFT with objective-conditioned LoRA adapters and Pareto-driven optimization, MailoHLS enables joint reasoning over code semantics, structure, and design trade-offs. Across seen and unseen kernels, MailoHLS achieves up to 12.42x and 8.4x speedup (9.48x and 4.97x geometric mean) for latency optimization, consistently producing near-Pareto-optimal designs. On fully unseen applications, it reaches up to 10.2x speedup (6.58x geometric mean), outperforming high-end LLMs and prior approaches while narrowing the gap to the Pareto frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MailoHLS, a hybrid framework that combines LLM-based semantic reasoning with GNN-based structural modeling for HLS pragma optimization in FPGA design. It integrates cross-attention between LLM embeddings and GNN structural embeddings, uses objective-conditioned LoRA adapters via PEFT, and applies Pareto-driven search to handle trade-offs between latency and resource utilization. The central empirical claims are speedups of up to 12.42x (9.48x geo-mean) on seen kernels and 10.2x (6.58x geo-mean) on fully unseen applications, outperforming high-end LLMs and prior model-driven methods while producing near-Pareto-optimal designs.
Significance. If the generalization and performance claims hold after proper validation, the work would represent a meaningful advance in automated HLS design-space exploration by addressing limitations of prior approaches in capturing structural dependencies and multi-objective trade-offs. The combination of cross-attention, objective-conditioned adapters, and Pareto search is a plausible direction for improving over purely LLM or GNN baselines, and the reported narrowing of the gap to the Pareto frontier would be a useful practical contribution if reproducible.
major comments (2)
- [Abstract] Abstract: the headline generalization results (10.2x max / 6.58x geo-mean on unseen applications) are load-bearing for the central claim yet rest on an unverified assumption that cross-attention + objective-conditioned LoRA jointly capture program structure, memory behavior, and conflicting objectives beyond the training distribution. No dataset size, kernel diversity metrics, or selection criteria for 'unseen' kernels are supplied, preventing assessment of whether the unseen set shares pragma spaces or memory patterns with training data.
- [Abstract] Abstract: the paper reports consistent outperformance over prior model-driven methods and LLMs, but supplies no ablation isolating the contribution of cross-attention versus the Pareto-driven search component, nor any quantitative validation details (training procedure, validation split, or how the Pareto frontier is constructed). These omissions make the data-to-claim link impossible to evaluate.
minor comments (1)
- [Abstract] Abstract: geometric-mean speedups are stated without the number of kernels evaluated or any measure of variance, which would clarify consistency across the reported 'seen' and 'unseen' sets.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we provide point-by-point responses to the major comments and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline generalization results (10.2x max / 6.58x geo-mean on unseen applications) are load-bearing for the central claim yet rest on an unverified assumption that cross-attention + objective-conditioned LoRA jointly capture program structure, memory behavior, and conflicting objectives beyond the training distribution. No dataset size, kernel diversity metrics, or selection criteria for 'unseen' kernels are supplied, preventing assessment of whether the unseen set shares pragma spaces or memory patterns with training data.
Authors: We acknowledge that the abstract does not supply dataset size, kernel diversity metrics, or selection criteria for the unseen kernels. We will revise the abstract to include these details from our experimental setup, specifically noting the training dataset composition and the criteria used to ensure the unseen applications are distinct in pragma spaces and memory patterns. revision: yes
-
Referee: [Abstract] Abstract: the paper reports consistent outperformance over prior model-driven methods and LLMs, but supplies no ablation isolating the contribution of cross-attention versus the Pareto-driven search component, nor any quantitative validation details (training procedure, validation split, or how the Pareto frontier is constructed). These omissions make the data-to-claim link impossible to evaluate.
Authors: We agree that the abstract does not include ablations or validation details. We will revise the abstract to briefly summarize the ablation studies isolating cross-attention and Pareto search, as well as the training and validation procedures and Pareto frontier construction method. revision: yes
Circularity Check
No circularity: empirical results on kernel benchmarks
full rationale
The paper reports measured speedups (e.g., 12.42x, 10.2x) from a trained hybrid model evaluated on seen and unseen kernels. No equations, fitted parameters, or derivations are shown that reduce these performance numbers to definitions or self-referential fits of the same quantities. The central claims rest on experimental generalization rather than any of the enumerated circular patterns; the abstract and provided text contain no self-definitional loops, fitted-input predictions, or load-bearing self-citations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Uri Alon and Eran Yahav. 2021. On the Bottleneck of Graph Neural Networks and its Practical Implications. In9th International Conference on Learning Rep- resentations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=i80OPhOCVH2
2021
-
[2]
Amazon Web Services. 2016. EC2 Instances (F1) with Programmable Hard- ware. https://aws.amazon.com/blogs/aws/developer-preview-ec2-instances-f1- with-programmable-hardware/. Accessed: 2025-10-25
2016
-
[3]
Anthropic. 2024. Model Card and Evaluations for Claude 3. https://www- cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_ Card_Claude_3.pdf. Accessed: 2026-04-03
2024
-
[4]
Yunsheng Bai, Atefeh Sohrabizadeh, Zijian Ding, Rongjian Liang, Weikai Li, Ding Wang, Haoxing Ren, Yizhou Sun, and Jason Cong. 2024. Learning to Compare Hardware Designs for High-Level Synthesis. InProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, MLCAD 2024, Salt Lake City, UT, USA, September 9-11, 2024, Hussam Amrouch...
-
[5]
Yunsheng Bai, Atefeh Sohrabizadeh, Zongyue Qin, Ziniu Hu, Yizhou Sun, and Jason Cong. 2023. Towards a comprehensive benchmark for high-level synthesis targeted to fpgas.Advances in Neural Information Processing Systems36 (2023), 45288–45299
2023
-
[6]
Yunsheng Bai, Atefeh Sohrabizadeh, Yizhou Sun, and Jason Cong. 2022. Improving GNN-based accelerator design automation with meta learning. InDAC ’22: 59th ACM/IEEE Design Automation Conference, San Francisco, California, USA, July 10 - 14, 2022, Rob Oshana (Ed.). ACM, 1347–1350. https://doi.org/10.1145/3489517. 3530629
-
[7]
Suhail Basalama and Jason Cong. 2025. Stream-HLS: Towards Automatic Dataflow Acceleration. InProceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA 2025, Monterey, CA, USA, 27 February 2025 - 1 March 2025, Andrew Putnam and Jing Li (Eds.). ACM, 103–114. https: //doi.org/10.1145/3706628.3708878
-
[8]
Christophe Bobda, Joel Mandebi Mbongue, Paul Chow, Mohammad Ewais, Naif Tarafdar, Juan Camilo Vega, Ken Eguro, Dirk Koch, Suranga Handagala, Miriam Leeser, et al. 2022. The future of FPGA acceleration in datacenters and the cloud. ACM Transactions on Reconfigurable Technology and Systems (TRETS)15, 3 (2022), 1–42
2022
-
[9]
Vinay Chamola, Sambit Patra, Neeraj Kumar, and Mohsen Guizani. 2020. FPGA for 5G: Re-configurable hardware for next generation communication.IEEE Wireless Communications27, 3 (2020), 140–147
2020
-
[10]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al . 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
-
[11]
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. 2024. Self- Play Fine-Tuning Converts Weak Language Models to Strong Language Models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine...
2024
-
[12]
Yuze Chi, Weikang Qiao, Atefeh Sohrabizadeh, Jie Wang, and Jason Cong. 2022. Democratizing domain-specific computing.Commun. ACM66, 1 (2022), 74–85
2022
-
[13]
Luca Collini, Siddharth Garg, and Ramesh Karri. 2025. C2hlsc: Leveraging large language models to bridge the software-to-hardware design gap.ACM Transac- tions on Design Automation of Electronic Systems30, 6 (2025), 1–24
2025
-
[14]
Jason Cong, Zhenman Fang, Michael Lo, Hanrui Wang, Jingxian Xu, and Shao- chong Zhang. 2018. Understanding performance differences of FPGAs and GPUs. In2018 IEEE 26th annual international symposium on field-programmable custom computing machines (FCCM). IEEE, 93–96
2018
-
[15]
Jason Cong, Bin Liu, Stephen Neuendorffer, Juanjo Noguera, Kees Vissers, and Zhiru Zhang. 2011. High-level synthesis for FPGAs: From prototyping to de- ployment.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems30, 4 (2011), 473–491
2011
-
[16]
Jason Cong, Bin Liu, Stephen Neuendorffer, Juanjo Noguera, Kees A. Vissers, and Zhiru Zhang. 2011. High-Level Synthesis for FPGAs: From Prototyping to Deployment.IEEE Trans. Comput. Aided Des. Integr. Circuits Syst.30, 4 (2011), 473–491. https://doi.org/10.1109/TCAD.2011.2110592
-
[17]
Fisches, Tal Ben-Nun, Torsten Hoefler, Michael F
Chris Cummins, Zacharias V. Fisches, Tal Ben-Nun, Torsten Hoefler, Michael F. P. O’Boyle, and Hugh Leather. 2021. ProGraML: A Graph-based Program Representa- tion for Data Flow Analysis and Compiler Optimizations. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (Proceedings of Machine Learn...
2021
-
[18]
Steve Dai, Yuan Zhou, Hang Zhang, Ecenur Ustun, Evangeline FY Young, and Zhiru Zhang. 2018. Fast and accurate estimation of quality of results in high- level synthesis with machine learning. In2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). IEEE, 129–132
2018
-
[19]
Dimitrios Danopoulos, Konstantinos Anagnostopoulos, Christoforos Kachris, and Dimitrios Soudris. 2021. FPGA Acceleration of Generative Adversarial Networks for Image Reconstruction. In2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST). IEEE, 1–5
2021
-
[20]
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 2022. 8-bit Optimizers via Block-wise Quantization. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenRe- view.net. https://openreview.net/forum?id=shpkpVXzo3h
2022
-
[21]
Aggelos Ferikoglou, Andreas Kakolyris, Vasilis Kypriotis, Dimosthenis Masouros, Dimitrios Soudris, and Sotirios Xydis. 2023. CollectiveHLS: Ultrafast Knowledge- Based HLS Design Optimization.IEEE Embedded Systems Letters16, 2 (2023), 235–238
2023
-
[22]
Aggelos Ferikoglou, Andreas Kakolyris, Vasilis Kypriotis, Dimosthenis Masouros, Dimitrios Soudris, and Sotirios Xydis. 2024. Data-driven HLS optimization for re- configurable accelerators. InProceedings of the 61st ACM/IEEE Design Automation Conference. 1–6
2024
-
[23]
Aggelos Ferikoglou, Andreas Kakolyris, Dimosthenis Masouros, Dimitrios Soudris, and Sotirios Xydis. 2024. CollectiveHLS: A collaborative approach to high-level synthesis design optimization.ACM Transactions on Reconfigurable Technology and Systems18, 1 (2024), 1–32. 12 MailoHLS: Multi-Adapter Structure-Aware Learning for Pareto-Driven HLS Pragma Optimization , ,
2024
-
[24]
Aggelos Ferikoglou, Despoina Tomkou, Dimosthenis Masouros, Dimitrios Soudris, and Sotirios Xydis. 2026. GN ΩSIS: Lessons Learned in Generating a High-Level Synthesis Dataset.ACM Transactions on Architecture and Code Optimization(2026)
2026
-
[25]
Lorenzo Ferretti, Giovanni Ansaloni, and Laura Pozzi. 2018. Cluster-based heuris- tic for high level synthesis design space exploration.IEEE Transactions on Emerg- ing Topics in Computing9, 1 (2018), 35–43
2018
-
[26]
Lorenzo Ferretti, Giovanni Ansaloni, and Laura Pozzi. 2018. Lattice-traversing design space exploration for high level synthesis. In2018 IEEE 36th International Conference on Computer Design (ICCD). IEEE, 210–217
2018
-
[27]
Lorenzo Ferretti, Andrea Cini, Georgios Zacharopoulos, Cesare Alippi, and Laura Pozzi. 2022. Graph neural networks for high-level synthesis design space explo- ration.ACM Transactions on Design Automation of Electronic Systems28, 2 (2022), 1–20
2022
-
[28]
Lorenzo Ferretti, Jihye Kwon, Giovanni Ansaloni, Giuseppe Di Guglielmo, Luca Carloni, and Laura Pozzi. 2021. Db4hls: A database of high-level synthesis design space explorations.IEEE Embedded Systems Letters13, 4 (2021), 194–197
2021
-
[29]
Lorenzo Ferretti, Jihye Kwon, Giovanni Ansaloni, Giuseppe Di Guglielmo, Luca P Carloni, and Laura Pozzi. 2020. Leveraging prior knowledge for effective design- space exploration in high-level synthesis.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems39, 11 (2020), 3736–3747
2020
-
[30]
Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan Celine Lin. 2023. Gpt4aigchip: Towards next-generation ai accelerator design automation via large language models. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 1–9
2023
-
[31]
Mingzhe Gao, Jieru Zhao, Zhe Lin, and Minyi Guo. 2024. Hierarchical Source- to-Post-Route QoR Prediction in High-Level Synthesis with GNNs. InDesign, Automation & Test in Europe Conference & Exhibition, DATE 2024, Valencia, Spain, March 25-27, 2024. IEEE, 1–6. https://doi.org/10.23919/DATE58400.2024.10546555
-
[32]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wen- feng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming - The Rise of Code Intelligence.CoRRabs/2401.14196 (2024). https://doi.org/10.48550/ARXIV.2401.14196 arXiv:2401.14196
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14196 2024
-
[33]
Charles Hong, Sahil Bhatia, Altan Haan, Shengjun Kris Dong, Dima Nikiforov, Alvin Cheung, and Yakun Sophia Shao. 2024. Llm-aided compilation for tensor accelerators. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 1–14
2024
-
[34]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[35]
Raisa Islam and Imtiaz Ahmed. 2024. Gemini-the most powerful LLM: Myth or Truth. In2024 5th Information Communication Technologies Conference (ICTC). IEEE, 303–308
2024
-
[36]
Varshney, Caiming Xiong, and Richard Socher
Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. 2019. CTRL: A Conditional Transformer Language Model for Controllable Generation.CoRRabs/1909.05858 (2019). arXiv:1909.05858 http: //arxiv.org/abs/1909.05858
Pith/arXiv arXiv 2019
-
[37]
Chris Lattner and Vikram S. Adve. 2004. LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. In2nd IEEE / ACM International Symposium on Code Generation and Optimization (CGO 2004), 20-24 March 2004, San Jose, CA, USA. IEEE Computer Society, 75–88. https://doi.org/10.1109/CGO. 2004.1281665
work page doi:10.1109/cgo 2004
-
[38]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[39]
Weikai Li, Ding Wang, Zijian Ding, Atefeh Sohrabizadeh, Zongyue Qin, Jason Cong, and Yizhou Sun. 2025. Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, Toby Walsh, Julie Shah, and Zico...
-
[40]
Zhe Lin, Jieru Zhao, Sharad Sinha, and Wei Zhang. 2020. HL-Pow: A learning- based power modeling framework for high-level synthesis. In2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 574–580
2020
-
[41]
Anushree Mahapatra and Benjamin Carrion Schafer. 2014. Machine-learning based simulated annealer method for high level synthesis design space explo- ration. InProceedings of the 2014 Electronic System Level Synthesis Conference (ESLsyn). IEEE, 1–6
2014
-
[42]
Hosein Mohammadi Makrani, Hossein Sayadi, Tinoosh Mohsenin, Setareh Rafati- rad, Avesta Sasan, and Houman Homayoun. 2019. Xppe: cross-platform perfor- mance estimation of hardware accelerators using machine learning. InProceedings of the 24th Asia and South Pacific Design Automation Conference. 727–732
2019
-
[43]
Dimosthenis Masouros, Aggelos Ferikoglou, Georgios Zervakis, Sotirios Xydis, and Dimitrios Soudris. 2024. Late Breaking Results: Language-level QoR modeling for High-Level Synthesis. InProceedings of the 61st ACM/IEEE Design Automation Conference, DAC 2024, San Francisco, CA, USA, June 23-27, 2024, Vivek De (Ed.). ACM, 351:1–351:2. https://doi.org/10.1145...
-
[44]
Emmet Murphy and Lana Josipovic. 2024. Balor: HLS Source Code Evalua- tor Based on Custom Graphs and Hierarchical GNNs. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, ICCAD 2024, Newark Liberty International Airport Marriott, NJ, USA, October 27-31, 2024, Jin- jun Xiong and Robert Wille (Eds.). ACM, 227:1–227:9. http...
arXiv 2024
-
[45]
Mostafa W Numan, Braden J Phillips, Gavin S Puddy, and Katrina Falkner. 2020. Towards automatic high-level code deployment on reconfigurable platforms: A survey of high-level synthesis tools and toolchains.IEEE Access8 (2020), 174692–174722
2020
-
[46]
Kenta Oono and Taiji Suzuki. 2020. Graph Neural Networks Exponentially Lose Expressive Power for Node Classification. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net. https://openreview.net/forum?id=S1ldO2EFPr
2020
-
[47]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023). https: //doi.org/10.48550/ARXIV.2303.08774 arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[48]
Jingyu Pan, Guanglei Zhou, Chen-Chia Chang, Isaac Jacobson, Jiang Hu, and Yiran Chen. 2025. A survey of research in large language models for electronic design automation.ACM Transactions on Design Automation of Electronic Systems 30, 3 (2025), 1–21
2025
-
[49]
Alexandros Papakonstantinou, Yun Liang, John A Stratton, Karthik Gururaj, Deming Chen, Wen-Mei W Hwu, and Jason Cong. 2011. Multilevel granularity parallelism synthesis on FPGAs. In2011 IEEE 19th Annual International Sympo- sium on Field-Programmable Custom Computing Machines. IEEE, 178–185
2011
-
[50]
Neha Prakriya, Zijian Ding, Yizhou Sun, and Jason Cong. 2025. LIFT: LLM-Based Pragma Insertion for HLS via GNN Supervised Fine-Tuning.CoRRabs/2504.21187 (2025). https://doi.org/10.48550/ARXIV.2504.21187 arXiv:2504.21187
-
[51]
Andrew Putnam, Adrian M Caulfield, Eric S Chung, Derek Chiou, Kypros Con- stantinides, John Demme, Hadi Esmaeilzadeh, Jeremy Fowers, Gopi Prashanth Gopal, Jan Gray, et al. 2014. A reconfigurable fabric for accelerating large-scale datacenter services.ACM SIGARCH Computer Architecture News42, 3 (2014), 13–24
2014
-
[52]
Zongyue Qin, Yunsheng Bai, Atefeh Sohrabizadeh, Zijian Ding, Ziniu Hu, Yizhou Sun, and Jason Cong. 2024. Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis. InProceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, MLCAD 2024, Salt Lake City, UT, USA, September 9-11, 2024...
-
[53]
Manning, Ste- fano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Ste- fano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Pro- cessing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, Dece...
2023
-
[54]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.CoRR abs/1910.10683 (2019). arXiv:1910.10683 http://arxiv.org/abs/1910.10683
Pith/arXiv arXiv 2019
-
[55]
Kyle Rupnow, Yun Liang, Yinan Li, and Deming Chen. 2011. A study of high-level synthesis: Promises and challenges. In2011 9th IEEE International Conference on ASIC. IEEE, 1102–1105
2011
-
[56]
Benjamin Carrion Schafer and Zi Wang. 2019. High-level synthesis design space exploration: Past, present, and future.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems39, 10 (2019), 2628–2639
2019
-
[57]
Anirban Sengupta and Saumya Bhadauria. 2015. User power-delay budget driven PSO based design space exploration of optimal k-cycle transient fault secured datapath during high level synthesis. InSixteenth International Symposium on Quality Electronic Design. IEEE, 289–292
2015
-
[58]
Atefeh Sohrabizadeh, Yunsheng Bai, Yizhou Sun, and Jason Cong. 2022. Au- tomated Accelerator Optimization Aided by Graph Neural Networks. InFPGA ’22: The 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Virtual Event, USA, 27 February 2022 - 1 March 2022, Michael Adler and Paolo Ienne (Eds.). ACM, 50. https://doi.org/10.1145/34904...
-
[59]
Atefeh Sohrabizadeh, Yunsheng Bai, Yizhou Sun, and Jason Cong. 2023. Robust GNN-Based Representation Learning for HLS. InIEEE/ACM International Confer- ence on Computer Aided Design, ICCAD 2023, San Francisco, CA, USA, October 28 - Nov. 2, 2023. IEEE, 1–9. https://doi.org/10.1109/ICCAD57390.2023.10323853
-
[60]
Sneha Swaroopa, Rijoy Mukherjee, Anushka Debnath, and Rajat Subhra Chakraborty. 2025. Evaluating Large Language Models for Automatic Register Transfer Logic Generation for Combinational Circuits via High-Level Synthesis. Foundatiosn and Trends in Electronic Design Automation14, 4 (2025), 295–314
2025
-
[61]
Despoina Tomkou, Aggelos Ferikoglou, Dimosthenis Masouros, Sotirios Xydis, and Dimitrios Soudris. 2026. Linking High-Level Synthesis with FPGA Runtime 13 , , Elena Vouvali, Dimosthenis Masouros, Aggelos Ferikoglou, Dimitrios Soudris, and Sotirios Xydis Orchestration. In17th Workshop on Parallel Programming and Run-Time Manage- ment Techniques for Many-Cor...
2026
-
[62]
Ecenur Ustun, Chenhui Deng, Debjit Pal, Zhijing Li, and Zhiru Zhang. 2020. Accurate operation delay prediction for FPGA HLS using graph neural networks. InProceedings of the 39th international conference on computer-aided design. 1–9
2020
-
[63]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
2017
-
[64]
2024.vLLM Documentation: Dynamically Serving LoRA Adapters
vLLM Team. 2024.vLLM Documentation: Dynamically Serving LoRA Adapters. https://docs.vllm.ai/en/stable/features/lora/#dynamically-serving- lora-adapters Accessed: 2024-05-22
2024
-
[65]
Zishen Wan, Bo Yu, Thomas Yuang Li, Jie Tang, Yuhao Zhu, Yu Wang, Arijit Ray- chowdhury, and Shaoshan Liu. 2021. A survey of fpga-based robotic computing. IEEE Circuits and Systems Magazine21, 2 (2021), 48–74
2021
-
[66]
Hanyu Wang, Xinrui Wu, Zijian Ding, Su Zheng, Chengyue Wang, Neha Prakriya, Tony Nowatzki, Yizhou Sun, and Jason Cong. 2025. LLM-DSE: Searching Accel- erator Parameters with LLM Agents.arXiv preprint arXiv:2505.12188(2025)
arXiv 2025
-
[67]
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Fran...
-
[68]
Nan Wu, Hang Yang, Yuan Xie, Pan Li, and Cong Hao. 2022. High-level synthesis performance prediction using GNNs: benchmarking, modeling, and advancing. In DAC ’22: 59th ACM/IEEE Design Automation Conference, San Francisco, California, USA, July 10 - 14, 2022, Rob Oshana (Ed.). ACM, 49–54. https://doi.org/10.1145/ 3489517.3530408
arXiv 2022
-
[69]
Chenwei Xiong, Cheng Liu, Huawei Li, and Xiaowei Li. 2024. HLSPilot: LLM- based High-Level Synthesis. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, ICCAD 2024, Newark Liberty International Airport Marriott, NJ, USA, October 27-31, 2024, Jinjun Xiong and Robert Wille (Eds.). ACM, 226:1–226:9. https://doi.org/10.1145/...
-
[70]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How Powerful are Graph Neural Networks?. In7th International Conference on Learning Rep- resentations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=ryGs6iA5Km
2019
-
[71]
Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. 2018. Representation Learning on Graphs with Jumping Knowledge Networks. InProceedings of the 35th International Con- ference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018 (Proceedings of Machine Learning Research),...
2018
-
[72]
Sotirios Xydis, Gianluca Palermo, Vittorio Zaccaria, and Cristina Silvano. 2014. SPIRIT: Spectral-aware Pareto iterative refinement optimization for supervised high-level synthesis.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems34, 1 (2014), 155–159
2014
-
[73]
Sotirios Xydis, Kiamal Pekmestzi, Dimitrios Soudris, and George Economakos
-
[74]
Compiler-in-the-loop exploration during datapath synthesis for higher quality delay-area trade-offs.ACM Trans. Des. Autom. Electron. Syst.18, 1, Article 11 (Jan. 2013), 35 pages. https://doi.org/10.1145/2390191.2390202
-
[75]
Hanchen Ye, Cong Hao, Jianyi Cheng, Hyunmin Jeong, Jack Huang, Stephen Neuendorffer, and Deming Chen. 2022. Scalehls: A new scalable high-level synthesis framework on multi-level intermediate representation. In2022 IEEE international symposium on high-performance computer architecture (HPCA). IEEE, 741–755. 14
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.