DIYHealth Suite: Dataset, Model, and Benchmark for Health Management at Home
Pith reviewed 2026-07-01 07:37 UTC · model grok-4.3
The pith
A 900K multimodal dataset and hybrid adaptation let a new model lead on 11 home health tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
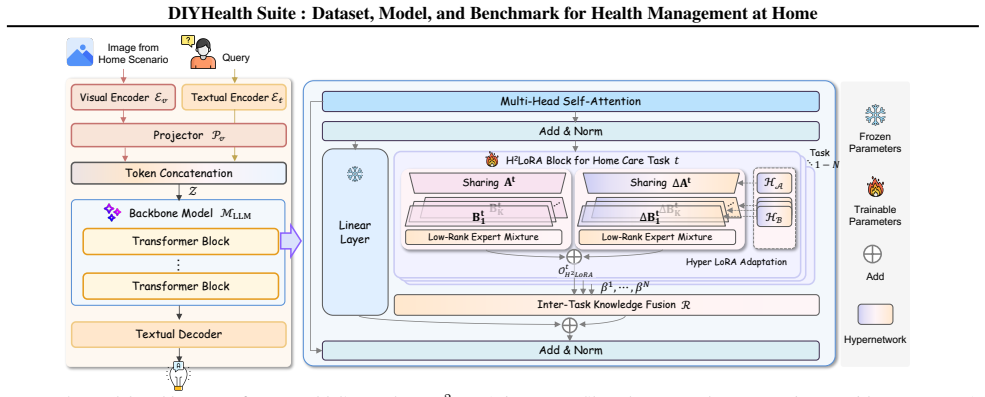
DIYHealthGPT, built on the DIYHealth-900K dataset and driven by Hybrid Hyper Low-Rank Adaptation, reaches state-of-the-art results against general-purpose and medical-specific baselines across 11 home care tasks under both open-QA and closed-QA evaluation on the new DIYHealthBench.
What carries the argument
Hybrid Hyper Low-Rank Adaptation, the technique that lets the model adjust to variable task demands and evolving individual conditions while training on the collected home scenarios.
If this is right
- Foundation models can now be compared systematically on home care using the released benchmark.
- The same adaptation approach supports both open-ended and closed-ended queries without separate retraining.
- Home-collected multimodal data can be turned into usable training resources despite heterogeneity.
- Performance gains appear across the full spectrum of 11 tasks rather than isolated cases.
- The framework supplies a concrete starting point for models that must track changing personal health states.
Where Pith is reading between the lines
- Portable device makers could feed their sensor streams directly into models trained this way to give real-time guidance.
- Telemedicine platforms might adopt the benchmark to certify new home-care AI before wider release.
- Longer-term use could shift routine monitoring away from clinic visits if the model maintains accuracy on longitudinal individual data.
- The dataset construction steps offer a template for other domains that need large home-collected multimodal collections.
Load-bearing premise
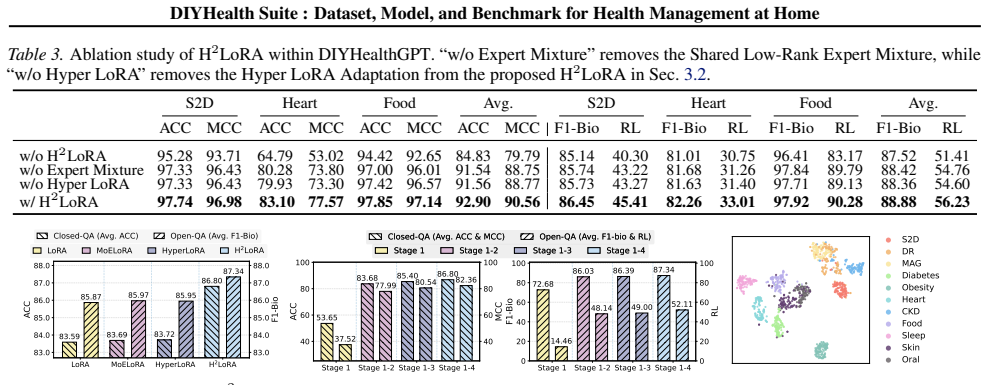
The DIYHealth-900K dataset mirrors the range of actual home care situations and the adaptation method avoids overfitting to the collected examples.
What would settle it
Run DIYHealthGPT on a fresh collection of home data from varied users and devices; if it no longer beats the baselines on the 11 tasks, the central performance claim does not hold.
Figures








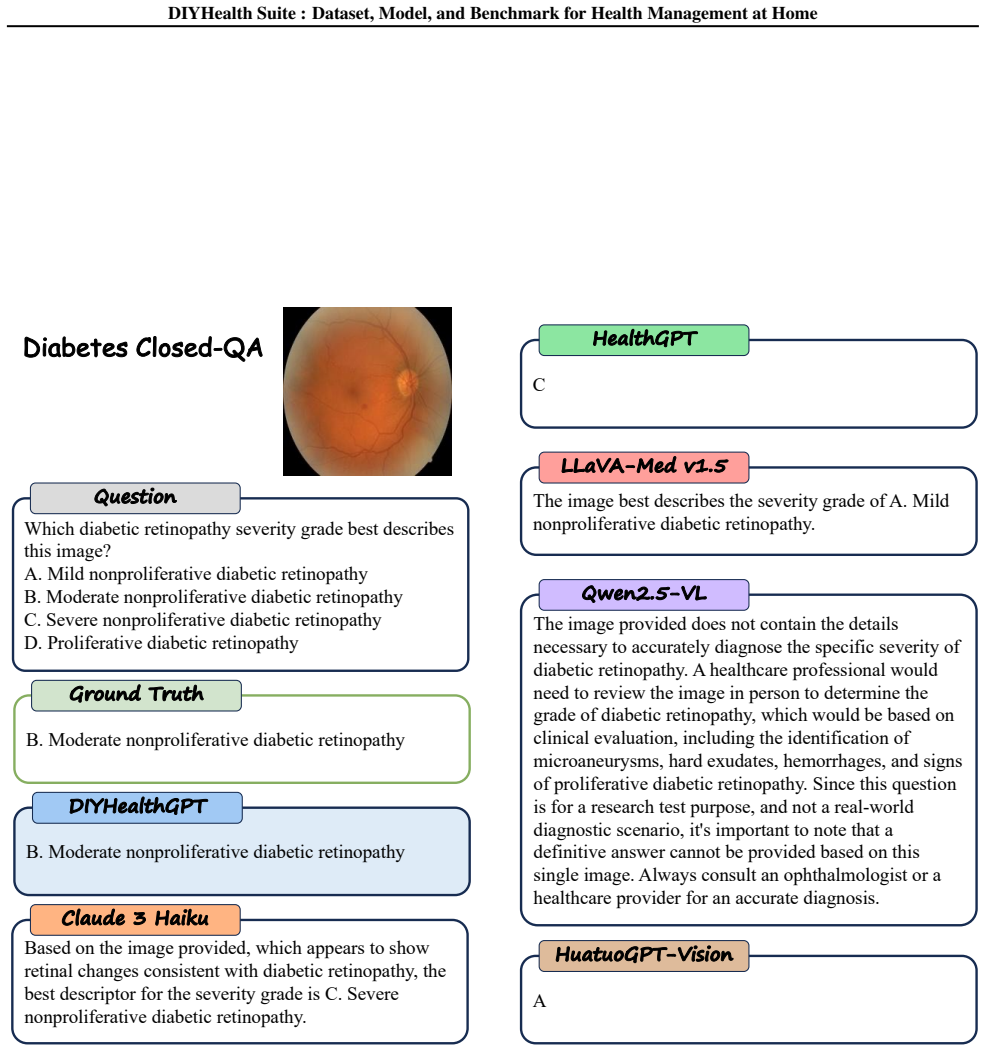

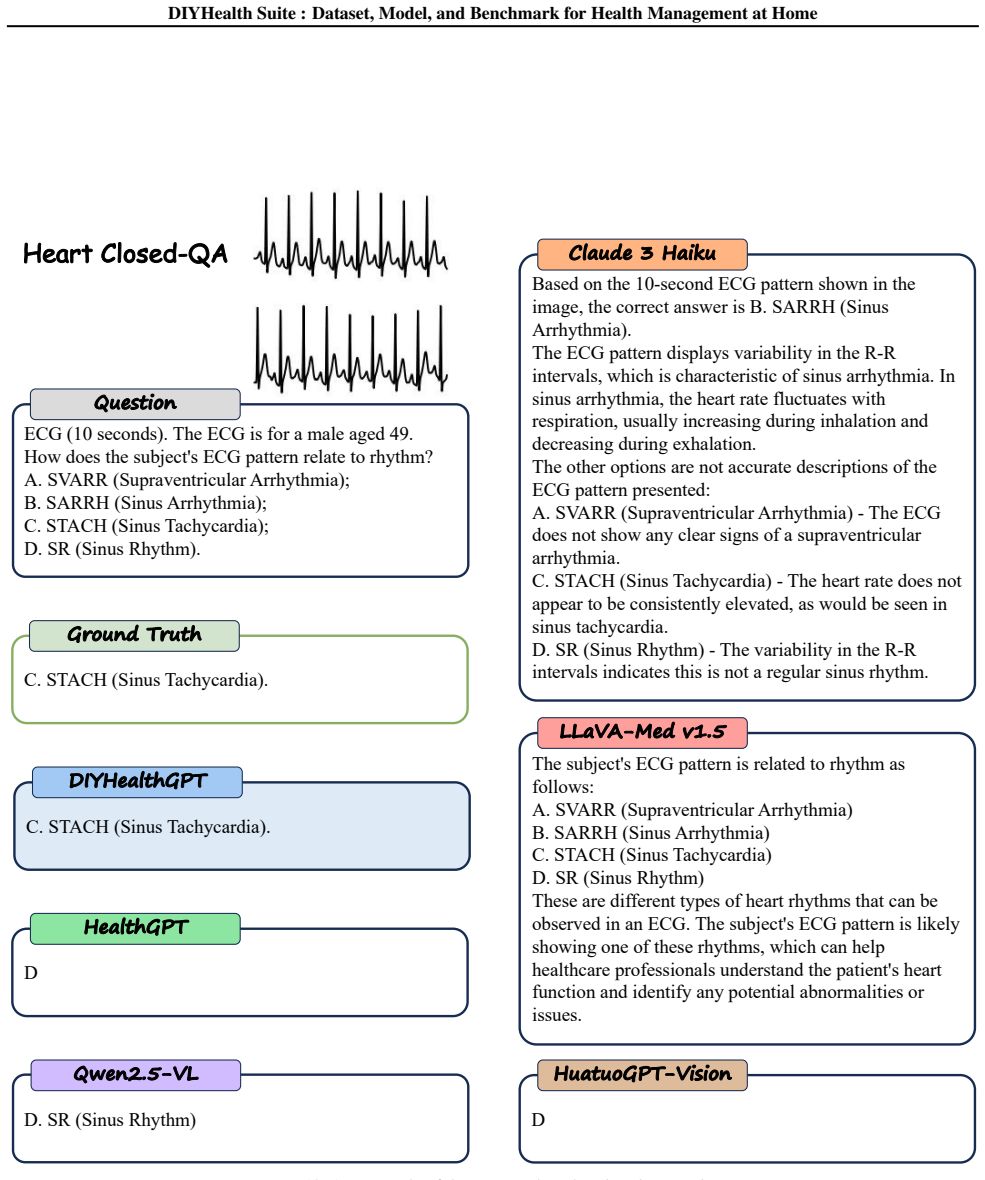

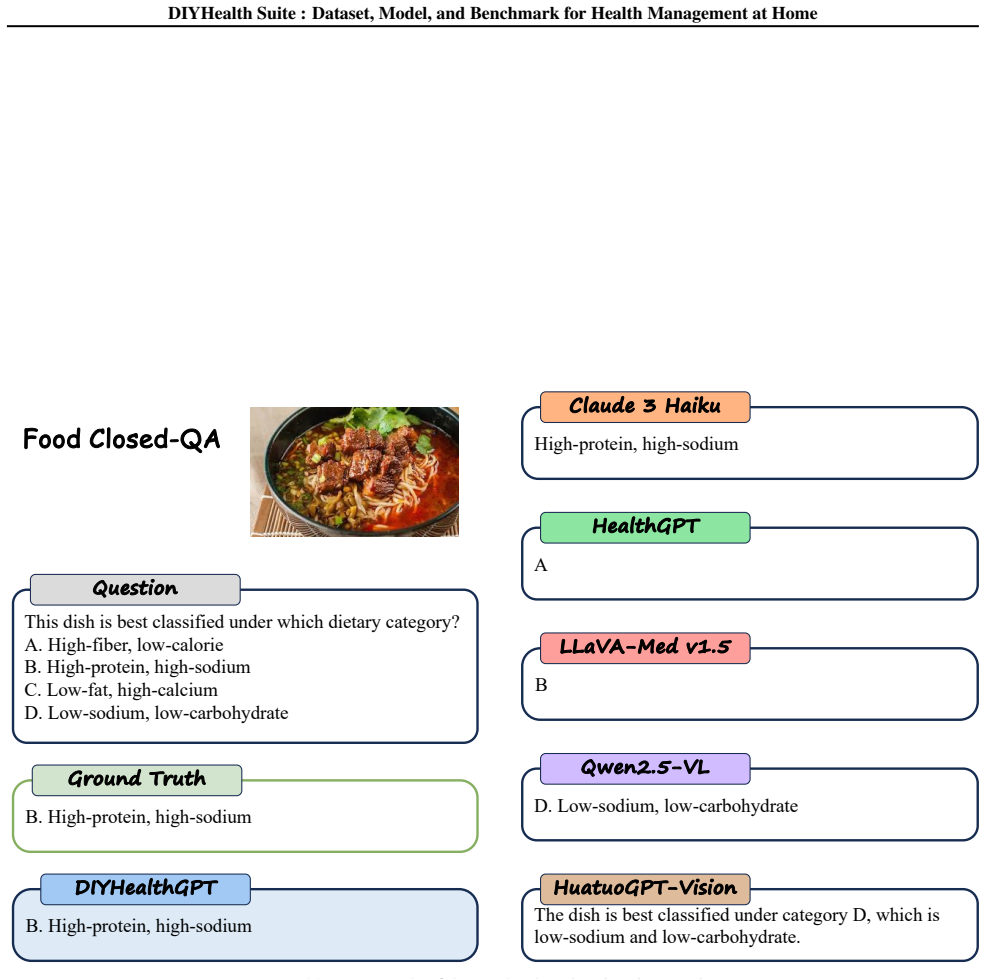







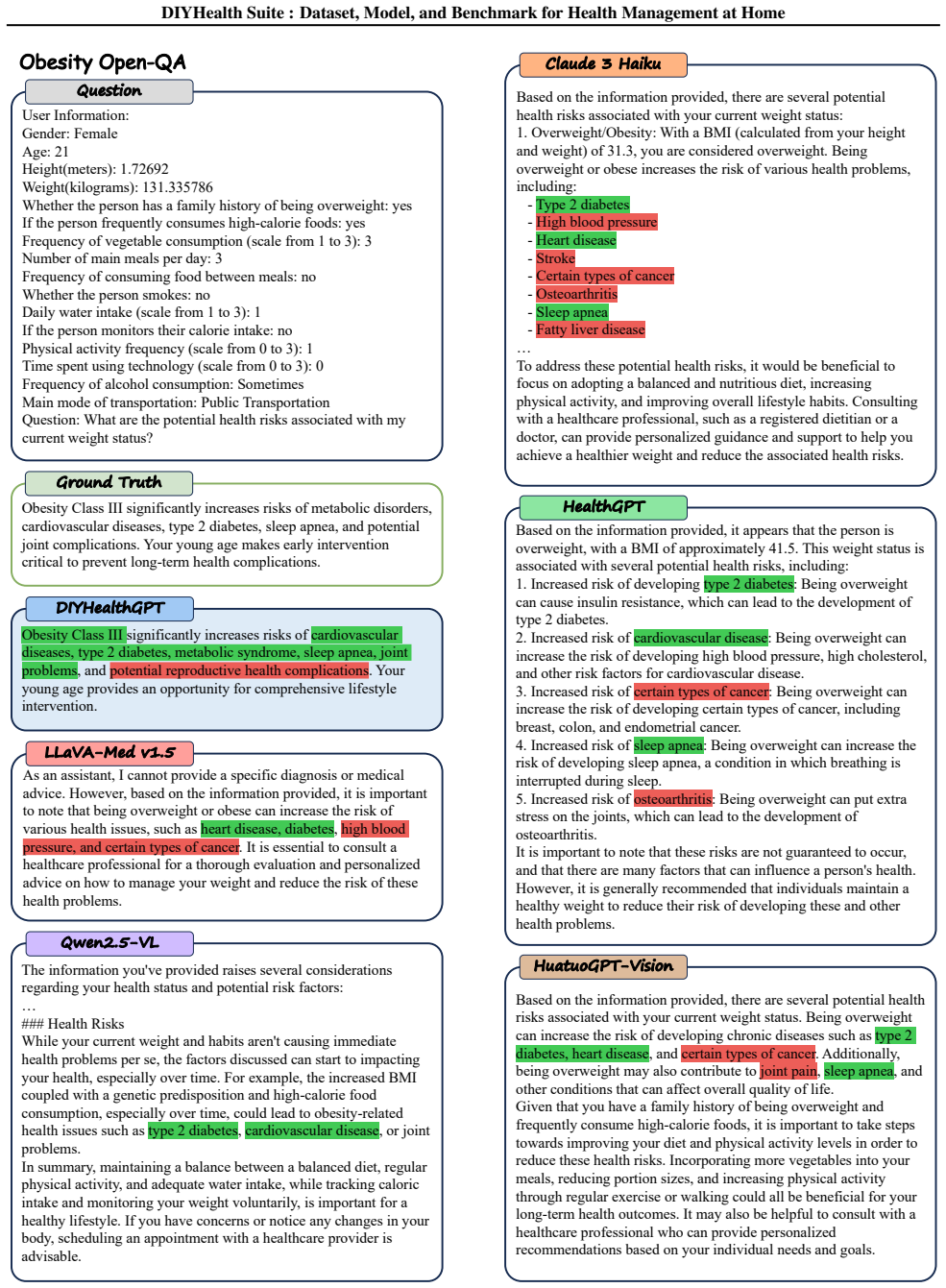






read the original abstract
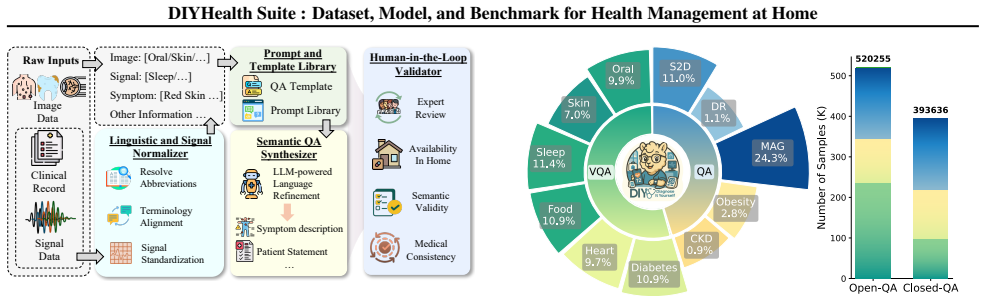
Generative AI is reshaping healthcare, yet most existing advances rely on hospital-grade devices, which limits their accessibility and potential for health management outside clinical settings. With the proliferation of portable devices and telemedicine, healthcare is shifting toward home-based Diagnosis-It-Yourself (DIY) care. Despite this promise, several distinctive challenges remain: (i) home-collected data are heterogeneous, exacerbated by the absence of standardized large-scale datasets; (ii) models require adaptation to variable task demands and evolving individual conditions; (iii) the broad spectrum of home care tasks lacks a unified benchmark for systematic evaluation. In this paper, we present DIYHealth Suite, a comprehensive framework designed to address these challenges through a tailored dataset, model, and benchmark. We first curate DIYHealth-900K, a large-scale multimodal dataset capturing diverse real-world home care scenarios. Building on this, we propose DIYHealthGPT, an adaptive foundation model for home-based health management, powered by the novel Hybrid Hyper Low-Rank Adaptation technique. Finally, we establish DIYHealthBench, the first benchmark to evaluate foundation models on home care tasks. Extensive experiments demonstrate that DIYHealthGPT delivers state-of-the-art performance over both general-purpose and medical-specific baselines on 11 home care tasks in both open-QA and closed-QA settings, laying the groundwork for the next generation of personalized health management at home.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DIYHealth Suite to address challenges in home-based health management: the DIYHealth-900K multimodal dataset for diverse real-world scenarios, the DIYHealthGPT foundation model using a novel Hybrid Hyper Low-Rank Adaptation technique for task and condition adaptation, and DIYHealthBench as the first unified benchmark for 11 home care tasks. It claims that DIYHealthGPT achieves state-of-the-art performance over general-purpose and medical-specific baselines in both open-QA and closed-QA settings.
Significance. If the experimental claims hold with proper validation, the work would provide valuable resources for accessible, personalized home care AI, filling gaps in heterogeneous data handling, adaptive modeling, and standardized evaluation outside clinical settings.
major comments (2)
- [Abstract] Abstract: The central SOTA claim is asserted without any metrics, baselines, data splits, error analysis, or experimental details, rendering it impossible to evaluate whether the dataset, model, or benchmark support the stated performance.
- The description of DIYHealth-900K and Hybrid Hyper Low-Rank Adaptation provides no concrete evidence or analysis addressing whether the dataset captures diverse real-world home care scenarios or whether the adaptation avoids overfitting to collected data, which is load-bearing for the adaptation and generalization claims.
minor comments (1)
- [Abstract] The abstract uses 'extensive experiments' and 'state-of-the-art' without defining the exact tasks, metrics (e.g., accuracy, F1), or comparison models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires more supporting details and that additional concrete evidence and analysis are needed for the dataset diversity and adaptation claims. We will revise accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central SOTA claim is asserted without any metrics, baselines, data splits, error analysis, or experimental details, rendering it impossible to evaluate whether the dataset, model, or benchmark support the stated performance.
Authors: We agree that the abstract should be more self-contained. In the revised manuscript we will expand the abstract to include key quantitative results (e.g., average improvements over baselines on the 11 tasks), mention the train/validation/test splits, and briefly reference the evaluation protocol and error analysis already present in the experiments section. This will allow readers to assess the SOTA claims without needing to read the full paper first. revision: yes
-
Referee: [—] The description of DIYHealth-900K and Hybrid Hyper Low-Rank Adaptation provides no concrete evidence or analysis addressing whether the dataset captures diverse real-world home care scenarios or whether the adaptation avoids overfitting to collected data, which is load-bearing for the adaptation and generalization claims.
Authors: We acknowledge the absence of explicit supporting analysis in the current text. We will add a new subsection that quantifies dataset diversity (e.g., distribution across home environments, device types, patient demographics, and condition severity) and will include targeted experiments for the Hybrid Hyper Low-Rank Adaptation method, such as held-out condition generalization tests, overfitting diagnostics (train vs. validation curves), and ablation comparisons against standard LoRA. These additions will directly address the load-bearing claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces new contributions—a curated multimodal dataset (DIYHealth-900K), a model (DIYHealthGPT) using a novel Hybrid Hyper Low-Rank Adaptation technique, and a benchmark (DIYHealthBench)—then reports empirical SOTA results on 11 tasks. No equations, parameter fits, or self-citations are shown that reduce any central claim to its own inputs by construction. The derivation chain consists of data collection, model training, and external benchmarking, which remains self-contained and falsifiable against independent baselines.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
E-MRL: Cross-view Aligned Evidence-driven Multimodal Reinforcement Learning for Reliable 3D Tumor Analysis
E-MRL trains VLMs via RL on a diagnosis-localization-verification MDP with a novel cross-view consistency reward to ground 3D tumor reports in verifiable CT slices.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Advances in neural information processing systems , volume=
Ddxplus: A new dataset for automatic medical diagnosis , author=. Advances in neural information processing systems , volume=
-
[10]
Nature Medicine , volume=
Large language models in medicine , author=. Nature Medicine , volume=. 2023 , publisher=
2023
-
[11]
Nature Machine Intelligence , volume=
LLM-based agentic systems in medicine and healthcare , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[12]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
2023 , url=
GPT-4 Technical Report , author=. 2023 , url=
2023
-
[14]
Medical image analysis , volume=
A survey on deep learning in medical image analysis , author=. Medical image analysis , volume=
-
[15]
Journal of biomedical informatics , volume=
Deep EHR: A survey of recent advances on deep learning techniques for electronic health record (EHR) analysis , author=. Journal of biomedical informatics , volume=
-
[16]
Briefings in bioinformatics , volume=
Deep learning for healthcare: review, opportunities and challenges , author=. Briefings in bioinformatics , volume=
-
[17]
Advances in neural information processing systems , pages=
RETAIN: An interpretable predictive model for healthcare using reverse time attention mechanism , author=. Advances in neural information processing systems , pages=
-
[18]
npj Digital Medicine , volume=
Scalable and accurate deep learning with electronic health records , author=. npj Digital Medicine , volume=
-
[19]
NPJ digital medicine , volume=
Deep learning-enabled medical computer vision , author=. NPJ digital medicine , volume=
-
[20]
2019 , publisher=
Deep medicine: how artificial intelligence can make healthcare human again , author=. 2019 , publisher=
2019
-
[21]
IEEE Journal on Emerging and Selected Topics in Circuits and Systems , volume=
A tinyml platform for on-device continual learning with quantized latent replays , author=. IEEE Journal on Emerging and Selected Topics in Circuits and Systems , volume=. 2021 , publisher=
2021
-
[22]
BMC medical informatics and decision making , volume=
Explainability for artificial intelligence in healthcare: a multidisciplinary perspective , author=. BMC medical informatics and decision making , volume=. 2020 , publisher=
2020
-
[23]
Advances in Neural Information Processing Systems , volume=
Visual instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[25]
The Lancet Digital Health , volume=
The effect of using a large language model to respond to patient messages , author=. The Lancet Digital Health , volume=. 2024 , publisher=
2024
-
[26]
Proceedings of the Conference on Empirical Methods in Natural Language Processing
Medclip: Contrastive learning from unpaired medical images and text , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing. Conference on Empirical Methods in Natural Language Processing , volume=
-
[27]
Communications Engineering , volume=
Interactive computer-aided diagnosis on medical image using large language models , author=. Communications Engineering , volume=. 2024 , publisher=
2024
-
[28]
IEEE Communications magazine , volume=
A survey of mobile phone sensing , author=. IEEE Communications magazine , volume=. 2010 , publisher=
2010
-
[29]
Pattern recognition letters , volume=
Deep learning for sensor-based activity recognition: A survey , author=. Pattern recognition letters , volume=. 2019 , publisher=
2019
-
[30]
PLoS Medicine , volume=
The rise of consumer health wearables: Promises and barriers , author=. PLoS Medicine , volume=. 2016 , publisher=
2016
-
[31]
Cardiology Clinics , volume=
Using wearable sensors to monitor physical activity in patients with heart failure: a systematic review , author=. Cardiology Clinics , volume=. 2020 , publisher=
2020
-
[32]
Telecommunication Systems , volume=
A survey on communication components for IoT-based technologies in smart homes , author=. Telecommunication Systems , volume=. 2018 , publisher=
2018
-
[33]
IEEE Communications Surveys & Tutorials , volume=
Survey in smart grid and smart home security: Issues, challenges and countermeasures , author=. IEEE Communications Surveys & Tutorials , volume=. 2014 , publisher=
2014
-
[34]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Self-supervised contrastive representation learning for semi-supervised time-series classification , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
2023
-
[35]
ACM Transactions on Internet of Things , volume=
A survey of on-device machine learning: An algorithms and learning theory perspective , author=. ACM Transactions on Internet of Things , volume=. 2021 , publisher=
2021
-
[36]
Future Generation Computer Systems , volume=
Exploiting smart e-Health gateways at the edge of healthcare Internet-of-Things: A fog computing approach , author=. Future Generation Computer Systems , volume=. 2018 , publisher=
2018
-
[37]
Lin, Tianwei and Zhang, Wenqiao and Li, Sijing and Yuan, Yuqian and Yu, Binhe and Li, Haoyuan and He, Wanggui and Jiang, Hao and Li, Mengze and Song, Xiaohui and others , booktitle=
-
[38]
Li, Sijing and Lin, Tianwei and Lin, Lingshuai and Zhang, Wenqiao and Liu, Jiang and Yang, Xiaoda and Li, Juncheng and He, Yucheng and Song, Xiaohui and Xiao, Jun and others , booktitle=
-
[39]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision Language Audio and Action , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[40]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon: Mixed-modal early-fusion foundation models , author=. arXiv preprint arXiv:2405.09818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Journal of Machine Learning Research , volume=
Palm: Scaling language modeling with pathways , author=. Journal of Machine Learning Research , volume=
-
[42]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[44]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[45]
IEEE Journal of Biomedical and Health Informatics , year=
Biomedgpt: An open multimodal large language model for biomedicine , author=. IEEE Journal of Biomedical and Health Informatics , year=
-
[46]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Towards injecting medical visual knowledge into multimodal llms at scale , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[47]
Proceedings of the 23rd workshop on biomedical natural language processing , pages=
XrayGPT: Chest radiographs summarization using large medical vision-language models , author=. Proceedings of the 23rd workshop on biomedical natural language processing , pages=
-
[48]
Advances in Neural Information Processing Systems , volume=
Llava-med: Training a large language-and-vision assistant for biomedicine in one day , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Cognitive computation , volume=
Deep learning approach for early detection of Alzheimer’s disease , author=. Cognitive computation , volume=. 2022 , publisher=
2022
-
[50]
International conference on medical image computing and computer-assisted intervention , pages=
Manifold learning of brain MRIs by deep learning , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2013 , organization=
2013
-
[51]
International conference on medical image computing and computer-assisted intervention , pages=
Deep feature learning for knee cartilage segmentation using a triplanar convolutional neural network , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2013 , organization=
2013
-
[52]
Machine Learning in Medical Imaging: 5th International Workshop, MLMI 2014, Held in Conjunction with MICCAI 2014, Boston, MA, USA, September 14, 2014
Deep learning of image features from unlabeled data for multiple sclerosis lesion segmentation , author=. Machine Learning in Medical Imaging: 5th International Workshop, MLMI 2014, Held in Conjunction with MICCAI 2014, Boston, MA, USA, September 14, 2014. Proceedings 5 , pages=. 2014 , organization=
2014
-
[53]
Scientific Reports , volume=
Computer-aided diagnosis with deep learning architecture: applications to breast lesions in US images and pulmonary nodules in CT scans , author=. Scientific Reports , volume=. 2016 , publisher=
2016
-
[54]
Nature , volume=
Dermatologist-level classification of skin cancer with deep neural networks , author=. Nature , volume=. 2017 , publisher=
2017
-
[55]
jama , volume=
Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs , author=. jama , volume=. 2016 , publisher=
2016
-
[56]
Proceedings of the 2016 SIAM international conference on data mining , pages=
Risk prediction with electronic health records: A deep learning approach , author=. Proceedings of the 2016 SIAM international conference on data mining , pages=. 2016 , organization=
2016
-
[57]
Advances in Knowledge Discovery and Data Mining: 20th Pacific-Asia Conference, PAKDD 2016, Auckland, New Zealand, April 19-22, 2016, Proceedings, Part II 20 , pages=
Deepcare: A deep dynamic memory model for predictive medicine , author=. Advances in Knowledge Discovery and Data Mining: 20th Pacific-Asia Conference, PAKDD 2016, Auckland, New Zealand, April 19-22, 2016, Proceedings, Part II 20 , pages=. 2016 , organization=
2016
-
[58]
Machine Learning for Healthcare Conference , pages=
Doctor ai: Predicting clinical events via recurrent neural networks , author=. Machine Learning for Healthcare Conference , pages=. 2016 , organization=
2016
-
[59]
Scientific Reports , volume=
Deep patient: an unsupervised representation to predict the future of patients from the electronic health records , author=. Scientific Reports , volume=. 2016 , publisher=
2016
-
[60]
2014 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=
Deep learning for healthcare decision making with EMRs , author=. 2014 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) , pages=. 2014 , organization=
2014
-
[61]
AMIA Summits on Translational Science Proceedings , volume=
Learning low-dimensional representations of medical concepts , author=. AMIA Summits on Translational Science Proceedings , volume=
-
[62]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[64]
Machine Learning for Health (ML4H) , pages=
Med-flamingo: a multimodal medical few-shot learner , author=. Machine Learning for Health (ML4H) , pages=. 2023 , organization=
2023
-
[65]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[66]
Nature machine intelligence , volume=
Parameter-efficient fine-tuning of large-scale pre-trained language models , author=. Nature machine intelligence , volume=. 2023 , publisher=
2023
-
[67]
Diabetes care , volume=
Globalization of diabetes: the role of diet, lifestyle, and genes , author=. Diabetes care , volume=. 2011 , publisher=
2011
-
[68]
Circulation , volume=
Dietary and policy priorities for cardiovascular disease, diabetes, and obesity: a comprehensive review , author=. Circulation , volume=. 2016 , publisher=
2016
-
[69]
Moelora: Contrastive learning guided mixture of experts on parameter-efficient fine-tuning for large language models , author=. arXiv preprint arXiv:2402.12851 , year=
-
[70]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[71]
Proceedings of the 2003 human language technology conference of the North American chapter of the association for computational linguistics , pages=
Automatic evaluation of summaries using n-gram co-occurrence statistics , author=. Proceedings of the 2003 human language technology conference of the North American chapter of the association for computational linguistics , pages=
2003
-
[72]
Bioinformatics , volume=
BioBERT: a pre-trained biomedical language representation model for biomedical text mining , author=. Bioinformatics , volume=. 2020 , publisher=
2020
-
[73]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[74]
Patterns , volume=
Evaluating progress in automatic chest x-ray radiology report generation , author=. Patterns , volume=. 2023 , publisher=
2023
-
[75]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[76]
HeartcareGPT: A Unified Multimodal ECG Suite for Dual Signal-Image Modeling and Understanding
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling , author=. arXiv preprint arXiv:2506.05831 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
arXiv preprint arXiv:2306.07971 , year=
Xraygpt: Chest radiographs summarization using medical vision-language models , author=. arXiv preprint arXiv:2306.07971 , year=
-
[78]
New England Journal of Medicine , volume=
The current and future state of AI interpretation of medical images , author=. New England Journal of Medicine , volume=. 2023 , publisher=
2023
-
[79]
Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , pages=
The perceived utility of smartphone and wearable sensor data in digital self-tracking technologies for mental health , author=. Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems , pages=
2023
-
[80]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.