No Free Lunch for Synthetic Images under Data Scarcity Conditions
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
GANs and DDPMs maintain higher fidelity and utility than VAEs when differential privacy noise is added during training on scarce image data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
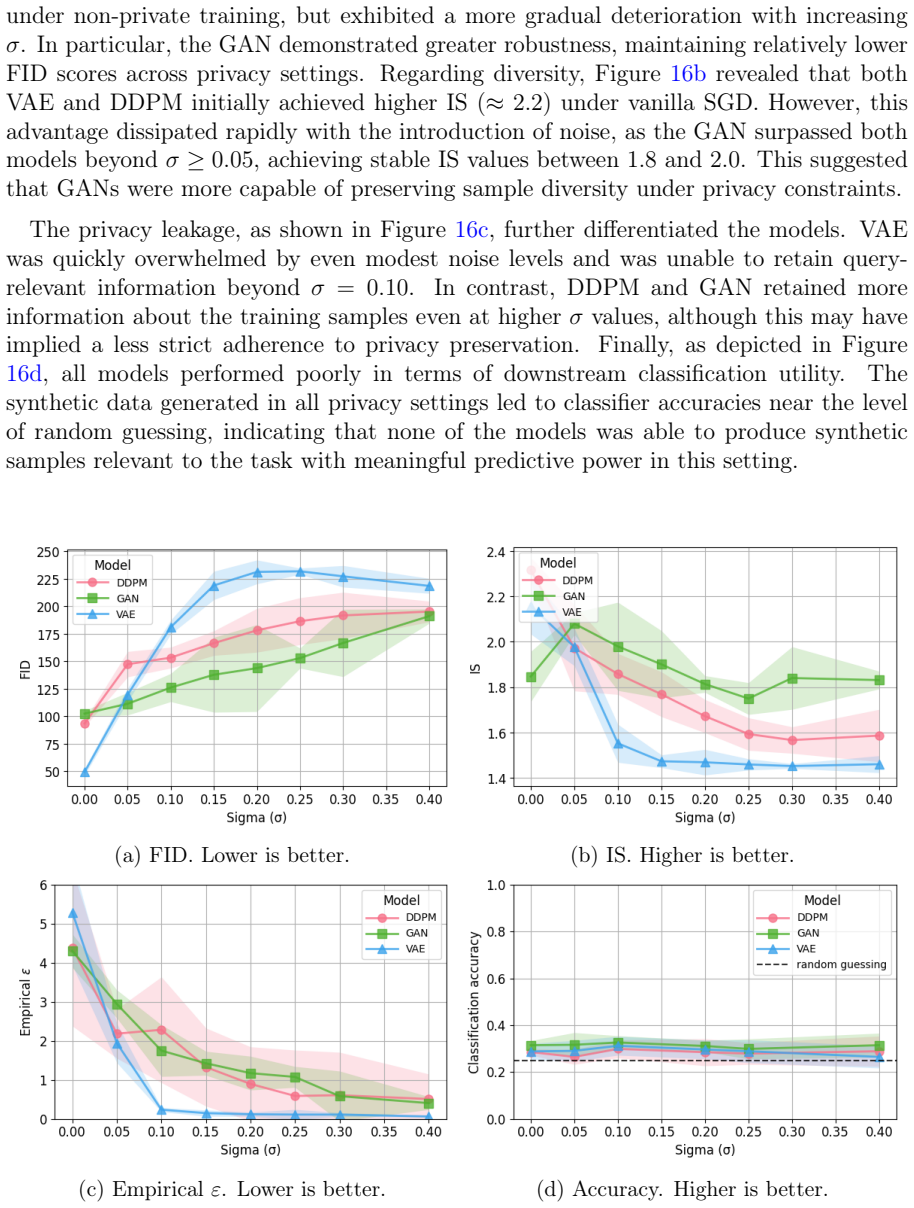
When differential privacy mechanisms are introduced during training, GAN and DDPM maintain higher fidelity and downstream utility across a range of noise levels, while VAE degrades more rapidly as privacy constraints increase.
What carries the argument
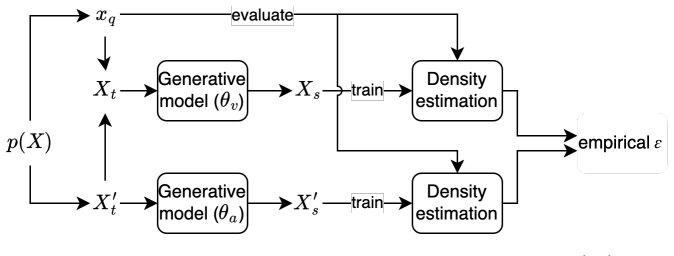
Joint evaluation framework that simultaneously measures fidelity, privacy, and utility of synthetic images produced by generative models.
If this is right
- GANs and DDPMs retain usable downstream performance longer than VAEs once privacy noise is introduced.
- No generative model achieves high scores on all three dimensions at once under strong privacy constraints.
- Medical imaging datasets show the same model ordering as general-purpose ones.
- Evaluation must track fidelity, privacy, and utility jointly rather than separately.
Where Pith is reading between the lines
- The observed robustness ordering could guide selection of generators for other privacy-sensitive domains such as tabular or time-series data.
- If the framework were applied to larger-scale models, the relative degradation rates might change.
- Alternative privacy mechanisms beyond the tested noise levels might alter which model appears most stable.
Load-bearing premise
The chosen metrics and the three image datasets together capture the fidelity-privacy-utility trade-offs without systematic bias.
What would settle it
Re-running the same models and privacy levels on a new dataset where VAE fidelity and utility remain equal to or above those of GAN and DDPM at high noise would contradict the robustness ordering.
Figures



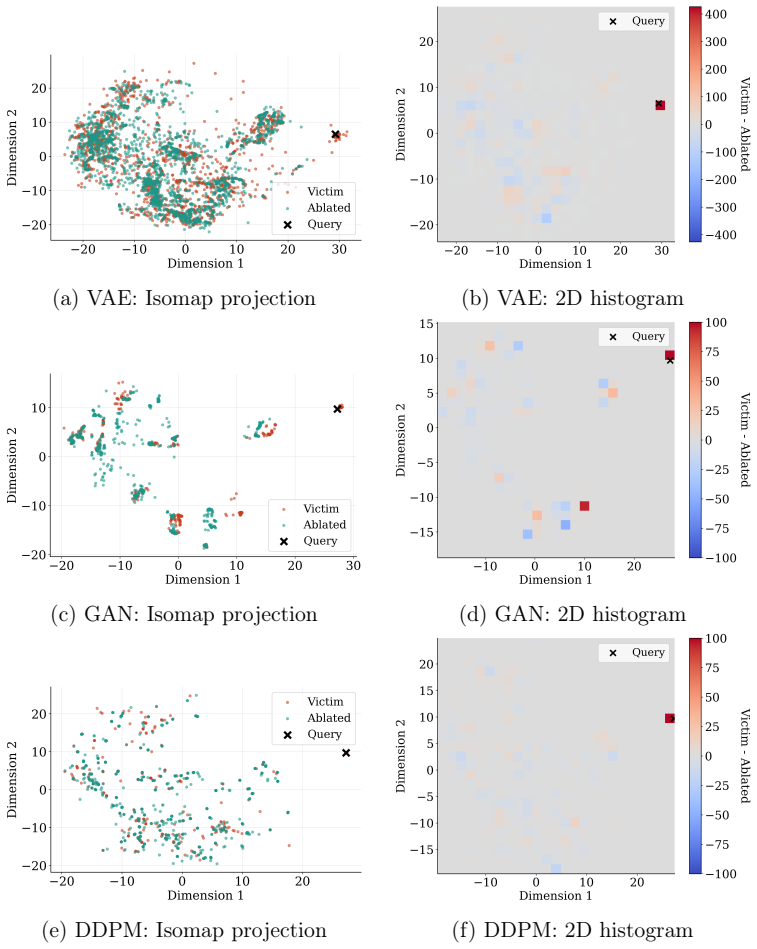








read the original abstract
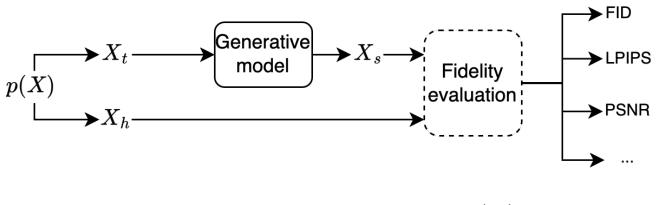
This study investigates the trade-offs between fidelity, privacy, and utility in synthetic data generation under conditions of data scarcity and privacy sensitivity. We propose an evaluation framework that jointly assesses these three dimensions and apply it to three widely used generative models, VAE, GAN, and DDPM. The evaluation spans three image datasets, MNIST, OCTMNIST, and OrganAMNIST, encompassing both general-purpose and medical imaging domains. Notable differences arise between the three models in their behaviour when differential privacy mechanisms are introduced during training. GAN and DDPM demonstrate greater robustness, maintaining higher fidelity and downstream utility across a range of noise levels, while VAE degrades more rapidly as privacy constraints increase. This study highlights the importance of a multidimensional evaluation of deep generative models, also noting that their behaviour significantly differs when privacy techniques are applied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates trade-offs between fidelity, privacy, and utility in synthetic image generation under data scarcity and privacy sensitivity. It proposes a joint evaluation framework applied to VAE, GAN, and DDPM across MNIST, OCTMNIST, and OrganAMNIST datasets. The central empirical claim is that GAN and DDPM exhibit greater robustness to differential privacy mechanisms during training, preserving higher fidelity and downstream task utility across noise levels, whereas VAE degrades more rapidly as privacy constraints tighten.
Significance. If the empirical results hold under rigorous controls, the work provides a useful multidimensional lens for selecting generative models in privacy-sensitive, data-scarce regimes such as medical imaging. The comparative robustness finding across model families is potentially actionable for practitioners, though its impact hinges on the transparency and reproducibility of the evaluation protocol, metric definitions, and statistical validation.
major comments (2)
- [Abstract / Methods (implied)] The abstract and provided description supply no concrete details on the differential privacy implementation (e.g., noise scale, clipping norms, or accountant method), the exact fidelity/utility metrics, statistical tests, or train/test splits. Without these, the load-bearing claim that GAN/DDPM are “more robust” cannot be verified or reproduced; this directly affects the central comparative result.
- [Evaluation framework (implied)] The joint evaluation framework is presented as comprehensive, yet no evidence is given that the chosen metrics are free of hidden biases or that they jointly capture the fidelity-privacy-utility space without trade-off artifacts. This assumption underpins the entire comparative analysis.
minor comments (2)
- [Abstract] Clarify whether the reported “noise levels” correspond to a single privacy budget ε or to multiple mechanisms; inconsistent terminology risks reader confusion.
- [Datasets (implied)] The datasets span general and medical domains; a brief justification for their selection and any domain-specific preprocessing would strengthen the generalizability claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reproducibility and evaluation rigor. We address each major comment below and will revise the manuscript to strengthen transparency without altering the core empirical findings.
read point-by-point responses
-
Referee: [Abstract / Methods (implied)] The abstract and provided description supply no concrete details on the differential privacy implementation (e.g., noise scale, clipping norms, or accountant method), the exact fidelity/utility metrics, statistical tests, or train/test splits. Without these, the load-bearing claim that GAN/DDPM are “more robust” cannot be verified or reproduced; this directly affects the central comparative result.
Authors: We agree that the abstract is intentionally concise and that the provided high-level description omits implementation specifics. The full manuscript contains these details in the Methods and Experimental Setup sections (including DP-SGD parameters via Opacus, accountant method, clipping norms, noise scales, FID/SSIM for fidelity, downstream accuracy for utility, and explicit train/test splits on MNIST/OCTMNIST/OrganAMNIST). To directly address verifiability, we will add a consolidated 'Reproducibility' subsection (or appendix table) listing all hyperparameters, metric formulas, and statistical procedures (e.g., 5-run averages with standard deviations). This revision will make the robustness claims fully reproducible. revision: yes
-
Referee: [Evaluation framework (implied)] The joint evaluation framework is presented as comprehensive, yet no evidence is given that the chosen metrics are free of hidden biases or that they jointly capture the fidelity-privacy-utility space without trade-off artifacts. This assumption underpins the entire comparative analysis.
Authors: The framework combines established metrics (FID and perceptual similarity for fidelity, epsilon-bounded DP for privacy, and task-specific accuracy for utility) drawn from prior literature on generative model evaluation under privacy constraints. While we do not claim the metrics are entirely bias-free (no finite set of metrics can be), we will expand the Evaluation Framework section with a short justification paragraph citing supporting references and include a brief sensitivity discussion on potential artifacts. If the referee has specific alternative metrics in mind, we are open to incorporating them as additional experiments. revision: partial
Circularity Check
Empirical study with no derivations or self-referential predictions
full rationale
The manuscript is a comparative empirical study applying an evaluation framework to VAE, GAN, and DDPM on three image datasets under differential privacy. No equations, derivations, fitted parameters relabeled as predictions, or load-bearing self-citations appear in the provided text or abstract. Claims rest on direct experimental outcomes rather than any chain that reduces to its own inputs by construction. The evaluation framework is introduced and applied without internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martín Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep Learning with Differential Privacy. https://arxiv.org/abs/1607.00133v2, July 2016
Pith/arXiv arXiv 2016
-
[2]
On the fidelity versus privacy and utility trade-off of synthetic patient data.iScience, 28(5):112382, May 2025
Tim Adams, Colin Birkenbihl, Karen Otte, Hwei Geok Ng, Jonas Adrian Rieling, Anatol-Fiete Näher, Ulrich Sax, Fabian Prasser, and Holger Fröhlich. On the fidelity versus privacy and utility trade-off of synthetic patient data.iScience, 28(5):112382, May 2025
2025
-
[3]
Apellániz, Ana Jiménez, Borja Arroyo Galende, Juan Parras, and Santi- ago Zazo
Patricia A. Apellániz, Ana Jiménez, Borja Arroyo Galende, Juan Parras, and Santi- ago Zazo. Synthetic Tabular Data Validation: A Divergence-Based Approach.IEEE Access, 12:103895–103907, 2024
2024
-
[4]
Schwartz
Mukund Balasubramanian and Eric L. Schwartz. The Isomap Algorithm and Topo- logical Stability.Science, 295(5552):7–7, January 2002
2002
-
[5]
A systematic review on overfitting control in shallow and deep neural networks.Artif
Mohammad Mahdi Bejani and Mehdi Ghatee. A systematic review on overfitting control in shallow and deep neural networks.Artif. Intell. Rev., 54(8):6391–6438, December 2021
2021
-
[6]
A mathematical theory of adaptive control processes.Proceedings of the National Academy of Sciences, 45(8):1288–1290, August 1959
Richard Bellman and Robert Kalaba. A mathematical theory of adaptive control processes.Proceedings of the National Academy of Sciences, 45(8):1288–1290, August 1959. 26
1959
-
[7]
Representation Learning: A Review and New Perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828, August 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation Learning: A Review and New Perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8):1798–1828, August 2013
2013
-
[8]
Willcocks
Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G. Willcocks. Deep Gen- erative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):7327–7347, November 2022
2022
-
[9]
Extracting Training Data from Large Language Models
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. Extracting Training Data from Large Language Models. In30th USENIX Security Symposium (USENIX Security 21), pages 2633–
-
[10]
USENIX Association, August 2021
2021
-
[11]
Antonia Creswell, Tom White, Vincent Dumoulin, Kai Arulkumaran, Biswa Sen- gupta, and Anil A. Bharath. Generative Adversarial Networks: An Overview.IEEE Signal Processing Magazine, 35(1):53–65, January 2018
2018
-
[12]
Saverio D’Amico, Daniele Dall’Olio, Claudia Sala, Lorenzo Dall’Olio, Elisabetta Sauta, Matteo Zampini, Gianluca Asti, Luca Lanino, Giulia Maggioni, Alessia Campagna, Marta Ubezio, Antonio Russo, Maria Elena Bicchieri, Elena Riva, Cristina A. Tentori, Erica Travaglino, Pierandrea Morandini, Victor Savevski, Ar- mando Santoro, Iñigo Prada-Luengo, Anders Kro...
2023
-
[13]
The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Magazine, 29(6):141–142, 2012
2012
-
[14]
Regulation (EU) 2025/327 of the European Parliament and of the Council on the European Health Data Space
Directorate-General for Health and Food Safety (DG SANTE), European Com- mission. Regulation (EU) 2025/327 of the European Parliament and of the Council on the European Health Data Space. https://eur-lex.europa.eu/legal- content/EN/TXT/?uri=CELEX
2025
-
[15]
DifferentiallyPrivate Diffusion Models.Transactions on Machine Learning Research, 2:1–25, May 2023
TimDockhorn, TianshiCao, ArashVahdat, andKarstenKreis. DifferentiallyPrivate Diffusion Models.Transactions on Machine Learning Research, 2:1–25, May 2023
2023
-
[16]
Gökcen Eraslan, Žiga Avsec, Julien Gagneur, and Fabian J. Theis. Deep learning: New computational modelling techniques for genomics.Nature Reviews Genetics, 20(7):389–403, July 2019
2019
-
[17]
prentice hall professional technical reference, 2002
David A Forsyth and Jean Ponce.Computer Vision: A Modern Approach. prentice hall professional technical reference, 2002
2002
-
[18]
Apellániz, Juan Parras, Santiago Zazo, and Silvia Uribe
Borja Arroyo Galende, Patricia A. Apellániz, Juan Parras, Santiago Zazo, and Silvia Uribe. Membership Inference Attacks and Differential Privacy: A study within the context of Generative Models.IEEE Open Journal of the Computer Society, pages 1–10, 2025. 27
2025
-
[19]
Mauro Giuffrè and Dennis L. Shung. Harnessing the power of synthetic data in healthcare: Innovation, application, and privacy.npj Digital Medicine, 6(1):1–8, October 2023
2023
-
[20]
Aldren Gonzales, Guruprabha Guruswamy, and Scott R. Smith. Synthetic data in health care: A narrative review.PLOS Digital Health, 2(1):e0000082, January 2023
2023
-
[21]
The MIT Press, October 2016
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. The MIT Press, October 2016
2016
-
[22]
Generative adversarial networks
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Commun. ACM, 63(11):139–144, October 2020
2020
-
[23]
A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse, February 2025
Zhongliang Guo, Chun Tong Lei, Lei Fang, Shuai Zhao, Yifei Qian, Jingyu Lin, Zeyu Wang, Cunjian Chen, Ognjen Arandjelović, and Chun Pong Lau. A Grey-box Attack against Latent Diffusion Model-based Image Editing by Posterior Collapse, February 2025
2025
-
[24]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InProceedings of the 34th International Conference on Neural Information Process- ing Systems, NIPS ’20, pages 6840–6851, Red Hook, NY, USA, December 2020. Curran Associates Inc
2020
-
[25]
Cohen, and Adrian Weller
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N. Cohen, and Adrian Weller. Synthetic Data – what, why and how?, 2024
2024
-
[26]
A scoping re- view of privacy and utility metrics in medical synthetic data.NPJ Digital Medicine, 8:60, January 2025
Bayrem Kaabachi, Jérémie Despraz, Thierry Meurers, Karen Otte, Mehmed Halilovic, Bogdan Kulynych, Fabian Prasser, and Jean Louis Raisaro. A scoping re- view of privacy and utility metrics in medical synthetic data.NPJ Digital Medicine, 8:60, January 2025
2025
-
[27]
Theoretical Analysis of Density Ratio Estimation.IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, E93-A(4):787–798, 2010
Takafumi Kanamori, Taiji Suzuki, and Masashi Sugiyama. Theoretical Analysis of Density Ratio Estimation.IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, E93-A(4):787–798, 2010
2010
-
[28]
No free lunch in data privacy
Daniel Kifer and Ashwin Machanavajjhala. No free lunch in data privacy. InPro- ceedings of the 2011 ACM SIGMOD International Conference on Management of Data, SIGMOD ’11, pages 193–204, New York, NY, USA, June 2011. Association for Computing Machinery
2011
-
[29]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. InPro- ceedings of the 2nd International Conference on Learning Representations (ICLR), 2014
2014
-
[30]
Lautrup, Tobias Hyrup, Arthur Zimek, and Peter Schneider-Kamp
Anton D. Lautrup, Tobias Hyrup, Arthur Zimek, and Peter Schneider-Kamp. Syn- theval: A framework for detailed utility and privacy evaluation of tabular synthetic data.Data Mining and Knowledge Discovery, 39(1):1–6, December 2024
2024
-
[31]
Convolutional networks for images, speech, and time series
Yann LeCun and Yoshua Bengio. Convolutional networks for images, speech, and time series. InThe Handbook of Brain Theory and Neural Networks, pages 255–258. MIT Press, Cambridge, MA, USA, October 1998. 28
1998
-
[32]
Cresswell, and Anthony L
Gabriel Loaiza-Ganem, Brendan Leigh Ross, Jesse C. Cresswell, and Anthony L. Caterini. Diagnosing and Fixing Manifold Overfitting in Deep Generative Models. Transactions on Machine Learning Research, 1:1–34, January 2022
2022
-
[33]
Machine Learning for Synthetic Data Generation: A Review, June 2024
Yingzhou Lu, Minjie Shen, Huazheng Wang, Xiao Wang, Capucine van Rechem, Tianfan Fu, and Wenqi Wei. Machine Learning for Synthetic Data Generation: A Review, June 2024
2024
-
[34]
Jun Lv, Jin Zhu, and Guang Yang. Which GAN? A comparative study of gen- erative adversarial network-based fast MRI reconstruction.Philosophical Trans- actions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 379(2200):20200203, May 2021
2021
-
[35]
P Mack and M Rosenblatt
Y. P Mack and M Rosenblatt. Multivariatek-nearest neighbor density estimates. Journal of Multivariate Analysis, 9(1):1–15, March 1979
1979
-
[36]
UMAP: Uni- form Manifold Approximation and Projection.Journal of Open Source Software, 3(29):861, 2018
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. UMAP: Uni- form Manifold Approximation and Projection.Journal of Open Source Software, 3(29):861, 2018
2018
-
[37]
Mendes, Aziz Barbar, and Marwa Refaie
Jorge M. Mendes, Aziz Barbar, and Marwa Refaie. Synthetic data generation: A privacy-preserving approach to accelerate rare disease research.Frontiers in Digital Health, 7, March 2025
2025
-
[38]
Rashidi, Samer Albahra, Brian P
Hooman H. Rashidi, Samer Albahra, Brian P. Rubin, and Bo Hu. A novel and fully automated platform for synthetic tabular data generation and validation.Scientific Reports, 14(1):23312, October 2024
2024
-
[39]
VariationalInferencewithNormalizingFlows
DaniloRezendeandShakirMohamed. VariationalInferencewithNormalizingFlows. InProceedings of the 32nd International Conference on Machine Learning, pages 1530–1538. PMLR, June 2015
2015
-
[40]
A Meta-Analysis of Overfitting in Machine Learning
Rebecca Roelofs, Vaishaal Shankar, Benjamin Recht, Sara Fridovich-Keil, Moritz Hardt, John Miller, and Ludwig Schmidt. A Meta-Analysis of Overfitting in Machine Learning. InAdvances in Neural Information Processing Systems, volume 32, pages 14854–14864. Curran Associates, Inc., December 2019
2019
-
[41]
U-Net: Convolutional Net- works for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Net- works for Biomedical Image Segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing
2015
-
[42]
An introduction to deep generative modeling
Lars Ruthotto and Eldad Haber. An introduction to deep generative modeling. GAMM-Mitteilungen, 44(2):e202100008, 2021
2021
-
[43]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan- tam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In2017 IEEE International Conference on Computer Vision (ICCV), pages 618–626, October 2017. 29
2017
-
[44]
Benchmark- ing Synthetic Tabular Data: A Multi-Dimensional Evaluation Framework, April 2025
Andrey Sidorenko, Michael Platzer, Mario Scriminaci, and Paul Tiwald. Benchmark- ing Synthetic Tabular Data: A Multi-Dimensional Evaluation Framework, April 2025
2025
-
[45]
Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. Stochastic gradient descent with differentially private updates. In2013 IEEE Global Conference on Signal and Information Processing, pages 245–248, December 2013
2013
-
[46]
Differ- entially Private Variational Autoencoders with Term-wise Gradient Aggregation
Tsubasa Takahashi, Shun Takagi, Hajime Ono, and Tatsuya Komatsu. Differ- entially Private Variational Autoencoders with Term-wise Gradient Aggregation. https://arxiv.org/abs/2006.11204v1, June 2020
arXiv 2006
-
[47]
PreventingoversmoothinginVAEviageneralizedvariance parameterization.Neurocomputing, 509:137–156, October 2022
Yuhta Takida, Wei-Hsiang Liao, Chieh-Hsin Lai, Toshimitsu Uesaka, Shusuke Taka- hashi, andYukiMitsufuji. PreventingoversmoothinginVAEviageneralizedvariance parameterization.Neurocomputing, 509:137–156, October 2022
2022
-
[48]
Terrell and David W
George R. Terrell and David W. Scott. Variable Kernel Density Estimation.The Annals of Statistics, 20(3):1236–1265, 1992
1992
-
[49]
Tsirikoglou, G
A. Tsirikoglou, G. Eilertsen, and J. Unger. A Survey of Image Synthesis Methods for Visual Machine Learning.Computer Graphics Forum, 39(6):426–451, 2020
2020
-
[50]
Department of Health and Human Services, Office for Civil Rights
U.S. Department of Health and Human Services, Office for Civil Rights. Notice of Proposed Rulemaking to Update the HIPAA Security Rule. https://www.federalregister.gov/documents/2025/01/01/2025-00001/notice-of- proposed-rulemaking-to-update-the-hipaa-security-rule, January 2025
2025
-
[51]
VisualizingDatausingt-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008
LaurensvanderMaatenandGeoffreyHinton. VisualizingDatausingt-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008
2008
-
[52]
VariableKernelDensityEstimationin High-Dimensional Feature Spaces.Proceedings of the AAAI Conference on Artificial Intelligence, 31(1), February 2017
ChristiaanvanderWaltandEtienneBarnard. VariableKernelDensityEstimationin High-Dimensional Feature Spaces.Proceedings of the AAAI Conference on Artificial Intelligence, 31(1), February 2017
2017
-
[53]
MedMNIST v2 - A large-scale lightweight benchmark for 2D and 3D biomedical image classification.Scientific Data, 10(1):41, January 2023
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. MedMNIST v2 - A large-scale lightweight benchmark for 2D and 3D biomedical image classification.Scientific Data, 10(1):41, January 2023
2023
-
[54]
No Free Lunch Theorem for Security and Utility in Federated Learning.ACM Trans
Xiaojin Zhang, Hanlin Gu, Lixin Fan, Kai Chen, and Qiang Yang. No Free Lunch Theorem for Security and Utility in Federated Learning.ACM Trans. Intell. Syst. Technol., 14(1):1:1–1:35, November 2022
2022
-
[55]
GenerativeModeling.Open Encyclopedia of Cognitive Science, July 2024
Jun-YanZhuandPhillipIsola. GenerativeModeling.Open Encyclopedia of Cognitive Science, July 2024. 30
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.