Hardware-aware Low-latency Quantum Compilation with Data-driven Lightweight Error Detection for Early Fault-Tolerant Systems
Pith reviewed 2026-06-28 01:34 UTC · model grok-4.3
The pith
Joint hardware-aware compilation and error detection improves quantum algorithm success probability by up to 68 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
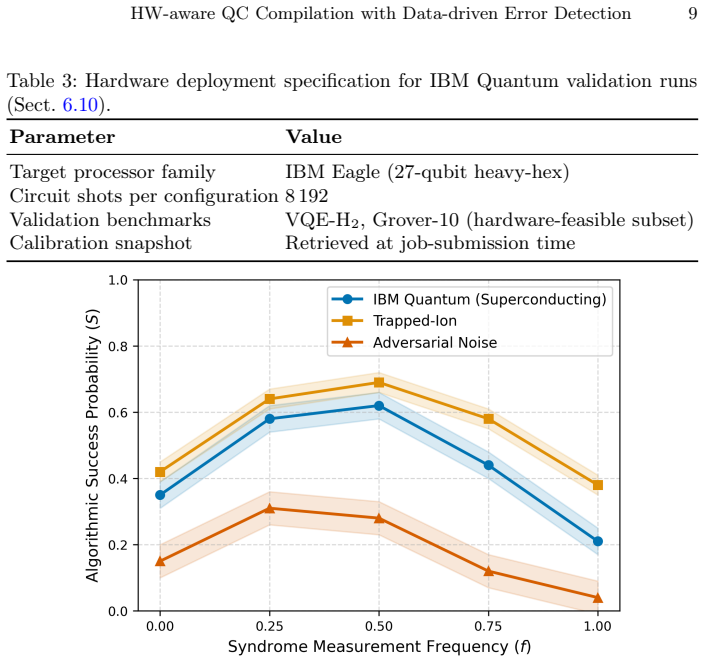
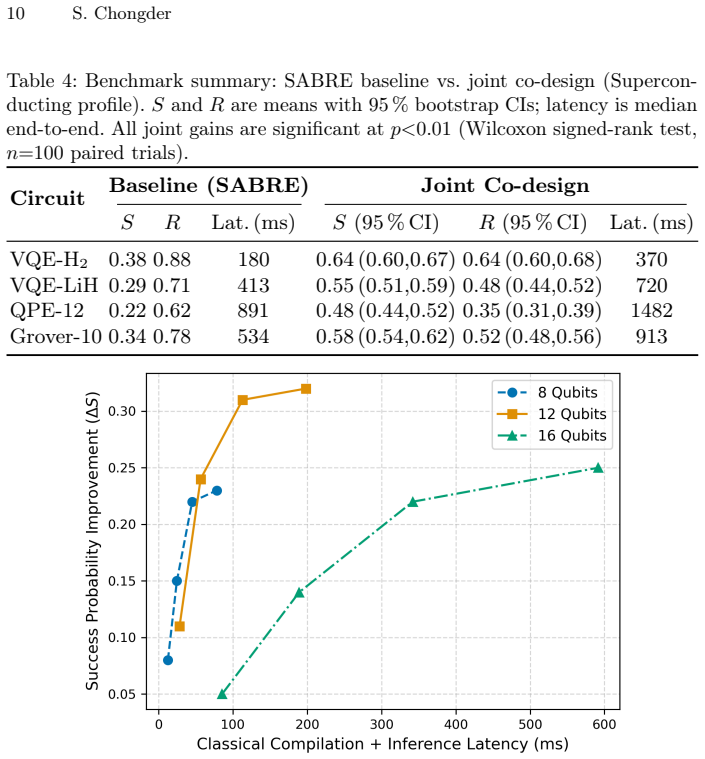
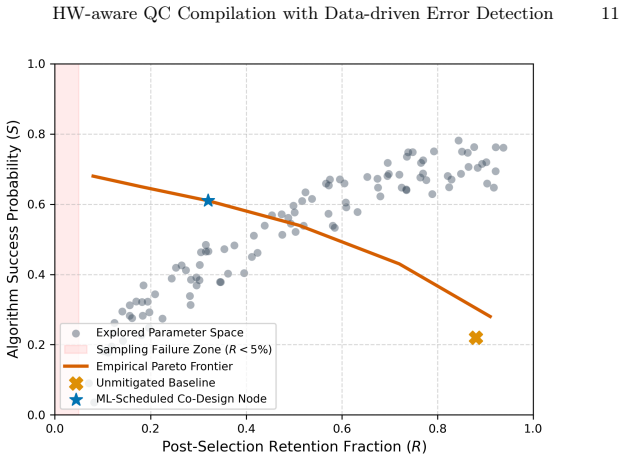
The paper claims that an integrated hardware-aware compilation and data-driven quantum error-detection framework, which jointly optimises qubit mapping, SWAP insertion, and syndrome-schedule placement via a noise-weighted cost function and a learned multi-objective scheduler, raises algorithmic success probability by up to 68 percent (95 percent CI: 60 percent to 76 percent) over SABRE on an 8-qubit VQE instance with post-selection, as shown in GPU-accelerated density-matrix simulations across multiple benchmarks, noise profiles, and circuit sizes from 6-20 qubits.
What carries the argument
The integrated hardware-aware compilation and data-driven QED framework that jointly optimises qubit mapping, SWAP insertion, and syndrome-schedule placement via a noise-weighted cost function and a learned multi-objective scheduler.
If this is right
- Algorithmic success probability increases by up to 68 percent on 8-qubit VQE with post-selection.
- The gains hold across VQE, phase-estimation, and Grover circuits of 6-20 qubits and depths 10-160.
- Joint optimization outperforms isolated compilation and error-detection approaches under three noise profiles.
- The method operates within latency constraints while using lightweight detection.
Where Pith is reading between the lines
- Similar joint optimization may extend to other algorithms not tested in the simulations.
- Scaling the scheduler to larger systems could require additional noise-model refinements.
- Integration with existing quantum software stacks might reduce deployment time on real devices.
- The approach could inform hybrid classical-quantum workflows that incorporate post-selection routinely.
Load-bearing premise
The learned multi-objective scheduler trained on simulated noise profiles will transfer to real hardware without large additional calibration overhead, and the density-matrix simulations accurately capture the relevant error mechanisms for the chosen benchmarks.
What would settle it
Executing the 8-qubit VQE instance on physical quantum hardware using the proposed compilation and observing success probability improvement below the 60 percent lower bound of the reported confidence interval.
Figures





read the original abstract
Noisy intermediate-scale quantum (NISQ) processors are entering an early fault-tolerance regime where full quantum error correction carries prohibitive resource costs, yet lightweight error detection can meaningfully improve algorithmic success rates. Existing compilation and error-detection toolchains treat these concerns in isolation, with no principled way to balance detection overhead against success probability under latency constraints. We present an integrated hardware-aware compilation and data-driven quantum error-detection (QED) framework that jointly optimises qubit mapping, SWAP insertion, and syndrome-schedule placement via a noise-weighted cost function and a learned multi-objective scheduler. Simulation experiments on an HPC cluster using GPU-accelerated density-matrix simulation (NVIDIA cuQuantum SDK) across VQE, phase-estimation, and Grover benchmarks, three noise profiles, and circuit sizes of 6-20 qubits (depths 10-160), show that joint co-design raises algorithmic success probability by up to 68 percent (95 percent CI: 60 percent to 76 percent) over SABRE on an 8-qubit VQE instance with post-selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an integrated hardware-aware compilation and data-driven quantum error-detection framework that jointly optimizes qubit mapping, SWAP insertion, and syndrome-schedule placement via a noise-weighted cost function and a learned multi-objective scheduler. GPU-accelerated density-matrix simulations across VQE, phase estimation, and Grover benchmarks (6-20 qubits, depths 10-160), three noise profiles, and post-selection show that the joint co-design raises algorithmic success probability by up to 68% (95% CI: 60-76%) over SABRE on an 8-qubit VQE instance.
Significance. If the reported gains hold and the learned policy generalizes, the co-design approach could provide a practical method for balancing lightweight error detection overhead against latency and success probability in early fault-tolerant regimes. The use of GPU-accelerated cuQuantum simulations with explicit confidence intervals and multiple benchmarks is a methodological strength that supports reproducibility.
major comments (3)
- [Abstract and §4] Abstract and §4 (Simulation Experiments): The headline 68% relative improvement (95% CI 60-76%) is obtained exclusively from density-matrix simulations under three synthetic noise profiles; no device-level experiments or calibration data are reported to test transfer to real hardware, which is load-bearing for the paper's title and motivation of hardware-aware compilation for early fault-tolerant systems.
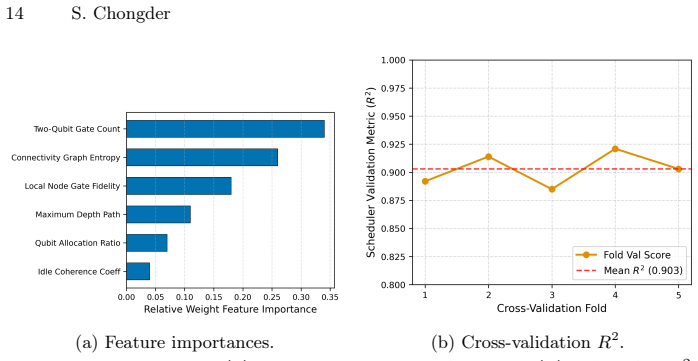
- [§3.1 and §3.2] §3.1 (Noise-weighted Cost Function) and §3.2 (Scheduler Training): The cost function weights and scheduler are trained and evaluated on the same three simulated noise profiles; while not circular by construction, the manuscript does not report held-out noise models or sensitivity analysis to assess robustness when the assumed error mechanisms (e.g., absence of crosstalk or leakage) differ from hardware.
- [§5 and §6] §5 (Results) and §6 (Discussion): The three noise profiles are not characterized in detail (e.g., no parameters for T1/T2, gate error rates, or inclusion of non-Markovian effects), and the discussion does not quantify how mismatch between these profiles and real-device noise would affect the reported success-probability gains.
minor comments (2)
- [Abstract] Abstract: The range of circuit depths (10-160) and number of independent noise realizations used for the confidence intervals could be stated explicitly to aid quick assessment of statistical power.
- [§3] Notation: The definition of the multi-objective scheduler's loss function could be clarified with an explicit equation showing how the noise weights enter the objective, to avoid ambiguity when comparing to SABRE.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the methodological strengths of the work. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Simulation Experiments): The headline 68% relative improvement (95% CI 60-76%) is obtained exclusively from density-matrix simulations under three synthetic noise profiles; no device-level experiments or calibration data are reported to test transfer to real hardware, which is load-bearing for the paper's title and motivation of hardware-aware compilation for early fault-tolerant systems.
Authors: We agree that the reported gains derive from controlled density-matrix simulations rather than real-device runs. The hardware-aware designation in the title and framework refers to the incorporation of hardware-derived noise parameters (T1/T2, gate errors) into the cost function and scheduler; the simulations are designed to isolate the effect of the co-design under those models. Real-hardware validation remains an important next step outside the scope of the current methodological contribution. We will revise the abstract, §1, and §6 to explicitly qualify all quantitative claims as simulation results and to frame hardware transfer as future work. revision: partial
-
Referee: [§3.1 and §3.2] §3.1 (Noise-weighted Cost Function) and §3.2 (Scheduler Training): The cost function weights and scheduler are trained and evaluated on the same three simulated noise profiles; while not circular by construction, the manuscript does not report held-out noise models or sensitivity analysis to assess robustness when the assumed error mechanisms (e.g., absence of crosstalk or leakage) differ from hardware.
Authors: The three profiles were selected to span distinct error-rate regimes representative of early fault-tolerant hardware. Because the scheduler learns a policy conditioned on the noise model, training and evaluation on the same profiles is the natural setting for the reported experiments. We acknowledge the value of explicit robustness checks; a revised manuscript will add a sensitivity analysis that perturbs error rates and introduces limited crosstalk/leakage terms to quantify degradation in success probability. revision: yes
-
Referee: [§5 and §6] §5 (Results) and §6 (Discussion): The three noise profiles are not characterized in detail (e.g., no parameters for T1/T2, gate error rates, or inclusion of non-Markovian effects), and the discussion does not quantify how mismatch between these profiles and real-device noise would affect the reported success-probability gains.
Authors: We will expand §5 to tabulate the exact T1/T2 values, single- and two-qubit gate error rates, and readout error probabilities for each profile, together with the Markovian assumption. In §6 we will add a quantitative discussion, supported by additional simulation sweeps, estimating how unmodeled effects such as crosstalk or non-Markovian noise would reduce the observed success-probability gains. revision: yes
Circularity Check
No significant circularity; success gains measured against external SABRE baseline on simulated benchmarks.
full rationale
The paper's central result is a measured improvement (up to 68% relative) in algorithmic success probability over the independent SABRE compiler, obtained from density-matrix simulations under fixed noise profiles. The learned scheduler is trained on those profiles, but the headline metric is a comparative evaluation against an external baseline rather than a quantity defined by or fitted to the same data by construction. No self-definitional equations, fitted-input-called-prediction steps, self-citation load-bearing uniqueness claims, or ansatz smuggling appear in the abstract or described derivation. The work is therefore self-contained against its stated external benchmark.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise-weighted cost function weights
axioms (1)
- domain assumption Density-matrix simulation with cuQuantum accurately models the target hardware noise for 6-20 qubit circuits.
Reference graph
Works this paper leans on
-
[1]
Preskill, J.: Quantum computing in the NISQ era and beyond. Quantum2, 79 (2018). doi:10.22331/q-2018-08-06-79
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[2]
Li, G., Ding, Y., Xie, Y.: Tackling the qubit mapping problem for NISQ- era quantum devices. In: Proc. ASPLOS 2019, pp. 1001–1014. ACM (2019). doi:10.1145/3297858.3304023
-
[3]
Murali, P., Baker, J.M., Javadi-Abhari, A., Chong, F.T., Martonosi, M.: Noise- adaptive compiler mappings for noisy intermediate-scale quantum computers. In: Proc. ASPLOS 2019, pp. 1015–1029. ACM (2019). doi:10.1145/3297858.3304075
-
[4]
Javadi-Abhari, A., et al.: Quantum computing with Qiskit. arXiv:2405.08810 (2024)
Pith/arXiv arXiv 2024
-
[5]
Bayraktar, H., et al.: cuQuantum SDK: a high-performance library for acceler- ating quantum science. In: Proc. IEEE QCE 2023, pp. 1050–1061. IEEE (2023). doi:10.1109/QCE57702.2023.00119
-
[6]
Faj, J., Peng, I., Wahlgren, J., Markidis, S.: Quantum computer simulations at warp speed. arXiv:2307.14860 (2023)
arXiv 2023
-
[7]
Temme, K., Bravyi, S., Gambetta, J.M.: Error mitigation for short- depth quantum circuits. Phys. Rev. Lett.119, 180509 (2017). doi:10.1103/PhysRevLett.119.180509
work page internal anchor Pith review doi:10.1103/physrevlett.119.180509 2017
-
[8]
Ginsberg, T., Patel, V.: Quantum error detection for early-term fault-tolerant quantum algorithms. arXiv:2503.10790 (2025)
arXiv 2025
-
[9]
Chao, R., Reichardt, B.W.: Quantum error correction with only two extra qubits. Phys. Rev. Lett.121, 050502 (2018). doi:10.1103/PhysRevLett.121.050502
-
[10]
Nation, P.D., Treinish, M.: Suppressing quantum circuit errors due to system vari- ability. PRX Quantum4, 010327 (2023). doi:10.1103/PRXQuantum.4.010327
-
[11]
XGBoost: A scalable tree boosting system
Chen, T., Guestrin, C.: XGBoost: a scalable tree boosting system. In: Proc. KDD 2016, pp. 785–794. ACM (2016). doi:10.1145/2939672.2939785
-
[12]
Peruzzo, A., et al.: A variational eigenvalue solver on a photonic quantum proces- sor. Nat. Commun.5, 4213 (2014). doi:10.1038/ncomms5213
-
[13]
Kitaev, A.Yu.: Quantum computations: algorithms and er- ror correction. Russian Math. Surveys52(6), 1191–1249 (1997). doi:10.1070/RM1997v052n06ABEH002155
-
[14]
Grover, L.K.: A fast quantum mechanical algorithm for database search. In: Proc. STOC 1996, pp. 212–219. ACM (1996). doi:10.1145/237814.237866
-
[15]
Endo,S.,Benjamin,S.C.,Li,Y.:Practicalquantumerrormitigationfornear-future applications. Phys. Rev. X8, 031027 (2018). doi:10.1103/PhysRevX.8.031027
-
[16]
Tan, B., Cong, J.: Optimality study of existing quantum computing mapping techniques. IEEE Trans. Comput.70(9), 1363–1373 (2021). doi:10.1109/TC.2020.3009140
-
[17]
In: Proc
Zhang, P., et al.: Time-optimal qubit mapping. In: Proc. ASPLOS 2021, pp. 360–
2021
-
[18]
ACM (2021). doi:10.1145/3445814.3446706
-
[19]
Sivarajah, S., Dilkes, S., Cowtan, A., Simmons, W., Edgington, A., Duncan, R.: t|ket⟩: a retargetable compiler for NISQ devices. Quantum Sci. Technol.6, 014003 (2021). doi:10.1088/2058-9565/ab8e92
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.