Illusions of the Gold Standard: A Large-scale Analysis of Human Evaluation Protocols for Long-form Text Generation
Pith reviewed 2026-06-27 20:18 UTC · model grok-4.3
The pith
Human evaluation protocols for long-form text generation in recent NLP conference papers are often incompletely reported, creating ambiguity about what was measured and by whom.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A systematic review of human evaluation protocols in *CL publications reveals widespread under-reporting of important aspects of study design, who contributed judgments, and how judgments should be interpreted, which produces ambiguity about what was actually measured and how the results should be understood.
What carries the argument
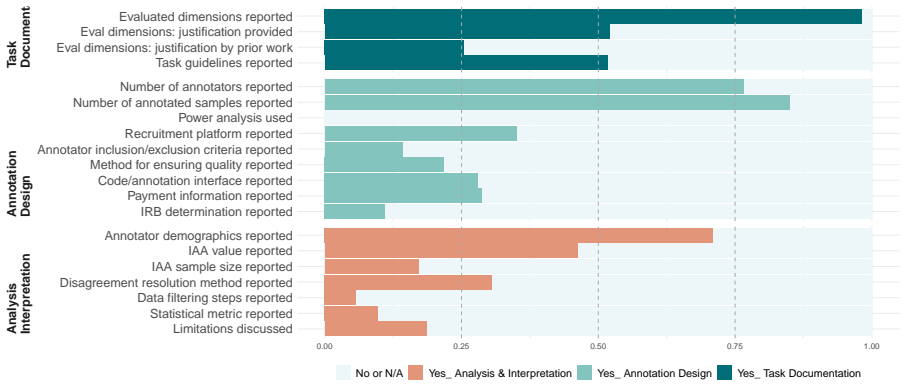
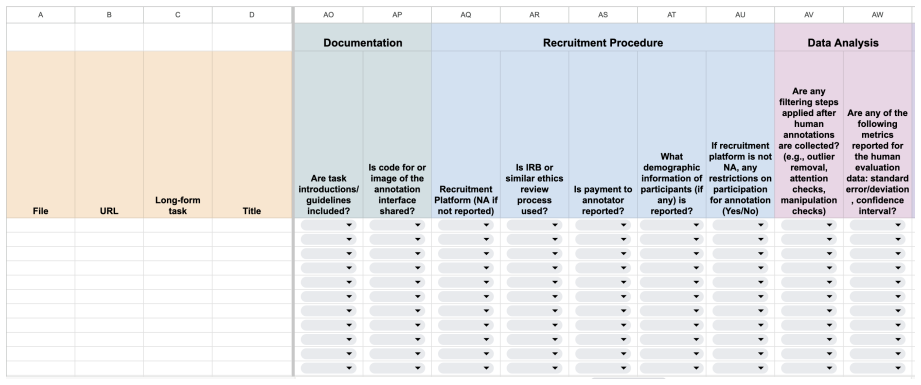
A set of 20 reportable criteria related to reproducibility of human evaluation studies, applied to check what details papers include about design, participants, and judgment processes.
If this is right
- Adopting the 20 criteria would make it easier to interpret and compare human evaluation results across different papers.
- Papers would need to document participant recruitment, training, and agreement measures more consistently.
- Ambiguity in current evaluations would decrease if journals and conferences required explicit reporting on these points.
- Future comparisons of generation systems could rest on clearer evidence of evaluation quality.
Where Pith is reading between the lines
- The same under-reporting pattern likely appears in evaluations of short-form or other generation tasks outside the long-form focus.
- Conferences could reduce ambiguity by adding checklist items based on the 20 criteria during submission.
- Greater transparency might shift research incentives toward more careful study design rather than just reporting results.
Load-bearing premise
The authors' chosen set of 20 criteria is enough to determine whether a human evaluation study is reproducible and interpretable.
What would settle it
A re-analysis of the same papers that applies a different or expanded list of criteria and finds high rates of complete reporting on the missing items.
Figures










read the original abstract
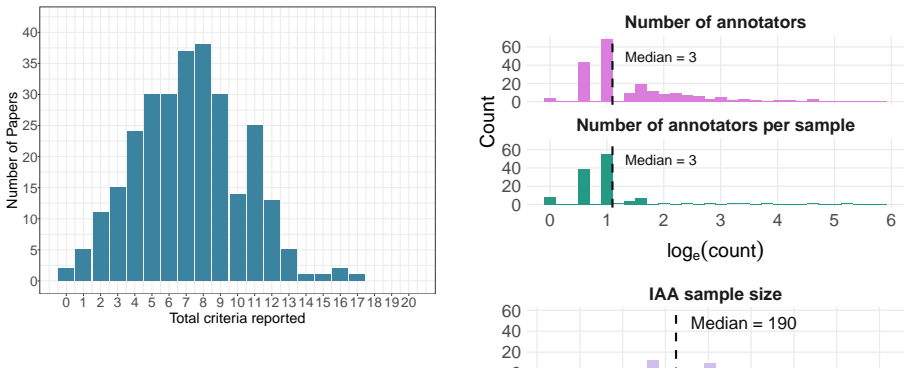
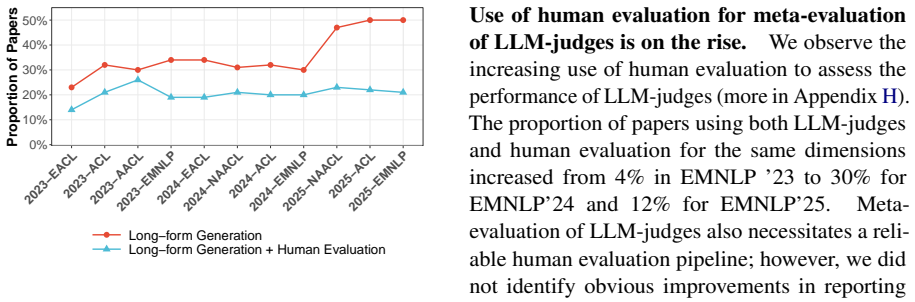
Human evaluation plays a critical role in assessing the quality of generated text. However, the reliability and reproducibility of these evaluations depend on transparent and well-documented protocols -- details that are frequently missing in current practice. In this work, we conduct a large-scale analysis of human evaluation protocols for evaluating long-form generation tasks in *CL conference publications from 2023--2025, including a full manual review of 284 papers and LLM-assisted analysis for another 1.8k+ papers. We define a set of 20 reportable criteria related to reproducibility of human evaluation studies, and apply these criteria to systematically examine reporting norms and practices within the community. We find widespread under-reporting of important aspects of human evaluation study design, leading to ambiguity about what was measured and how, who contributed judgments, and how judgments should be interpreted. Based on these findings, we outline actionable recommendations to support more transparent and reproducible reporting in future research. Our analysis code and annotated dataset can be found at: https://github.com/larchlab/Illusions-of-the-Gold-Standard
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale observational analysis of human evaluation protocols for long-form text generation in *CL conference papers (2023–2025). It performs a full manual review of 284 papers plus LLM-assisted analysis of an additional 1.8k+ papers against a fixed set of 20 reportable criteria for reproducibility. The central claim is that widespread under-reporting of study-design details creates ambiguity about what was measured, who provided judgments, and how results should be interpreted; the authors provide recommendations and release code plus an annotated dataset.
Significance. If the central observational claim holds, the work is significant because human evaluation remains a primary method for assessing long-form generation quality, and documented under-reporting directly affects reproducibility and interpretability in the field. The explicit release of analysis code and the annotated dataset is a clear strength that supports verification and follow-up studies. The findings could usefully inform community guidelines, provided the 20 criteria are shown to be well-aligned with existing reporting standards.
major comments (2)
- [Section defining the 20 criteria] Section defining the 20 criteria: the manuscript presents these criteria as capturing 'important aspects' necessary for reproducibility and interpretability, yet provides no external validation (e.g., expert survey, comparison against ACL or prior meta-study reporting guidelines, or inter-rater agreement on criterion importance). Because the prevalence statistics and the downstream claim of 'widespread under-reporting of important aspects' rest directly on this author-defined set, the absence of such validation makes the quantitative conclusions sensitive to the particular framing chosen.
- [LLM-assisted analysis section] LLM-assisted analysis section (1.8k+ papers): the extension from the 284 manually reviewed papers to the larger corpus is load-bearing for the 'widespread' claim, but the manuscript does not report prompt details, few-shot examples, or measured agreement/error rates between the LLM outputs and the manual annotations. Without these, systematic biases in the automated labeling could materially affect the reported under-reporting rates.
minor comments (2)
- [Table 1] Table 1 (or equivalent summary table of criteria): the mapping from each criterion to the specific ambiguity it addresses (measurement, contributors, or interpretation) could be made more explicit to help readers trace how missing items produce the claimed ambiguities.
- [Data and code release] The GitHub link is provided, but the README should include a clear description of how the 284 manual annotations were performed (annotator background, resolution process) to strengthen reproducibility of the core dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Section defining the 20 criteria] Section defining the 20 criteria: the manuscript presents these criteria as capturing 'important aspects' necessary for reproducibility and interpretability, yet provides no external validation (e.g., expert survey, comparison against ACL or prior meta-study reporting guidelines, or inter-rater agreement on criterion importance). Because the prevalence statistics and the downstream claim of 'widespread under-reporting of important aspects' rest directly on this author-defined set, the absence of such validation makes the quantitative conclusions sensitive to the particular framing chosen.
Authors: We agree that additional justification for the criteria would strengthen the work. The 20 criteria were synthesized from recurring elements in prior NLP literature on human evaluation reproducibility and reporting standards. In revision we will add a new subsection explicitly mapping each criterion to relevant ACL guidelines and earlier meta-studies, together with a brief rationale for inclusion. While we did not conduct a new expert survey, this explicit alignment will reduce sensitivity to the chosen framing and make the prevalence claims more robust. revision: partial
-
Referee: [LLM-assisted analysis section] LLM-assisted analysis section (1.8k+ papers): the extension from the 284 manually reviewed papers to the larger corpus is load-bearing for the 'widespread' claim, but the manuscript does not report prompt details, few-shot examples, or measured agreement/error rates between the LLM outputs and the manual annotations. Without these, systematic biases in the automated labeling could materially affect the reported under-reporting rates.
Authors: We concur that full transparency on the LLM-assisted labeling is required. The original submission omitted these details for brevity. The revised manuscript will include the complete prompts, few-shot examples, and a dedicated error-analysis subsection reporting agreement rates (and disagreement categories) between the LLM and the manual annotations on a held-out validation set. This addition will allow readers to evaluate potential biases directly. revision: yes
Circularity Check
No significant circularity in observational literature analysis
full rationale
The paper performs a manual and LLM-assisted review of reporting practices in other papers by first defining an explicit set of 20 criteria and then counting their presence or absence. No equations, fitted parameters, predictions, or self-citation chains exist that reduce any central claim to its own inputs by construction. The analysis is self-contained empirical observation against transparently stated criteria; the absence of any enumerated circularity pattern (self-definitional, fitted-input prediction, load-bearing self-citation, etc.) yields a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The defined set of 20 reportable criteria adequately captures key aspects of human evaluation reproducibility.
Reference graph
Works this paper leans on
-
[1]
Scientific reports , volume=
Expert evaluation of large language models for clinical dialogue summarization , author=. Scientific reports , volume=. 2025 , publisher=
2025
-
[2]
A Critical Evaluation of Evaluations for Long-form Question Answering
Xu, Fangyuan and Song, Yixiao and Iyyer, Mohit and Choi, Eunsol. A Critical Evaluation of Evaluations for Long-form Question Answering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.181
-
[3]
Responsible AI Considerations in Text Summarization Research: A Review of Current Practices
Liu, Yu Lu and Cao, Meng and Blodgett, Su Lin and Cheung, Jackie Chi Kit and Olteanu, Alexandra and Trischler, Adam. Responsible AI Considerations in Text Summarization Research: A Review of Current Practices. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.413
-
[4]
Automated Metrics for Medical Multi-Document Summarization Disagree with Human Evaluations
Wang, Lucy Lu and Otmakhova, Yulia and DeYoung, Jay and Truong, Thinh Hung and Kuehl, Bailey and Bransom, Erin and Wallace, Byron C. Automated Metrics for Medical Multi-Document Summarization Disagree with Human Evaluations. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/...
-
[5]
O pen R eviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews
Idahl, Maximilian and Ahmadi, Zahra. O pen R eviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations). 2025. doi:10.18653/v1/2025.naacl-demo.44
-
[6]
First Conference on Language Modeling , year=
Fine-grained hallucination detection and editing for language models , author=. First Conference on Language Modeling , year=
-
[7]
Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
Heds 3.0: The human evaluation data sheet version 3.0 , author=. Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
-
[8]
NPJ digital medicine , volume=
A framework for human evaluation of large language models in healthcare derived from literature review , author=. NPJ digital medicine , volume=. 2024 , publisher=
2024
-
[9]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts , pages=
Human-centered evaluation of language technologies , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts , pages=
2024
-
[10]
Proceedings of the 2nd Workshop on Human Evaluation of NLP Systems (HumEval) , pages=
The human evaluation datasheet: A template for recording details of human evaluation experiments in NLP , author=. Proceedings of the 2nd Workshop on Human Evaluation of NLP Systems (HumEval) , pages=
-
[11]
Proceedings of the Fourth Workshop on Insights from Negative Results in NLP , pages=
Missing information, unresponsive authors, experimental flaws: The impossibility of assessing the reproducibility of previous human evaluations in NLP , author=. Proceedings of the Fourth Workshop on Insights from Negative Results in NLP , pages=
-
[12]
Computational Linguistics , volume=
Common flaws in running human evaluation experiments in NLP , author=. Computational Linguistics , volume=. 2024 , publisher=
2024
-
[13]
University of Chicago Coase-Sandor Institute for Law & Economics Research Paper , number=
Judge AI: Assessing large language models in judicial decision-making , author=. University of Chicago Coase-Sandor Institute for Law & Economics Research Paper , number=
-
[14]
Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges , author=. Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
-
[15]
LLM s instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern \'a ndez, Raquel and Gatt, Albert and Ghaleb, Esam and Giulianelli, Mario and Hanna, Michael and Koller, Alexander and Martins, Andre and Mondorf, Philipp and Neplenbroek, Vera and Pezzelle, Sandro and Plank, Barbara and Schlangen, David and Suglia, Alessandro a...
-
[16]
Advances in Neural Information Processing Systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
npj Health Systems , volume=
Human evaluation of large language models in healthcare: gaps, challenges, and the need for standardization , author=. npj Health Systems , volume=. 2025 , publisher=
2025
-
[18]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Escalation risks from language models in military and diplomatic decision-making , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[19]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Can language model moderators improve the health of online discourse? , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[20]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Internlm-law: An open-sourced chinese legal large language model , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[21]
arXiv preprint arXiv:2405.05860 , year=
The perspectivist paradigm shift: Assumptions and challenges of capturing human labels , author=. arXiv preprint arXiv:2405.05860 , year=
-
[22]
Nature human behaviour , volume=
A manifesto for reproducible science , author=. Nature human behaviour , volume=. 2017 , publisher=
2017
-
[23]
2022 , url =
Shaurya Rohatgi , title =. 2022 , url =
2022
-
[24]
On Context Utilization in Summarization with Large Language Models
Ravaut, Mathieu and Sun, Aixin and Chen, Nancy and Joty, Shafiq. On Context Utilization in Summarization with Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.153
-
[25]
ArXiv , year=
How Reliable Are Automatic Evaluation Methods for Instruction-Tuned LLMs? , author=. ArXiv , year=
-
[26]
arXiv preprint arXiv:2312.07559 , year=
Paperqa: Retrieval-augmented generative agent for scientific research , author=. arXiv preprint arXiv:2312.07559 , year=
-
[27]
arXiv e-prints , pages=
A foundation model for human-AI collaboration in medical literature mining , author=. arXiv e-prints , pages=
-
[28]
arXiv preprint arXiv:2411.14199 , year=
Openscholar: Synthesizing scientific literature with retrieval-augmented lms , author=. arXiv preprint arXiv:2411.14199 , year=
-
[29]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[30]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[31]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[32]
Clinical Natural Language Processing Workshop , year=
Generating medically-accurate summaries of patient-provider dialogue: A multi-stage approach using large language models , author=. Clinical Natural Language Processing Workshop , year=
-
[33]
Conference on Empirical Methods in Natural Language Processing , year=
Hierarchical Catalogue Generation for Literature Review: A Benchmark , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[34]
Annual Meeting of the Association for Computational Linguistics , year=
Multi-News: A Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[35]
Annual Meeting of the Association for Computational Linguistics , year=
Hierarchical Transformers for Multi-Document Summarization , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[36]
Annual Meeting of the Association for Computational Linguistics , year=
Summ ^N : A Multi-Stage Summarization Framework for Long Input Dialogues and Documents , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[37]
ArXiv , year=
Leveraging Long-Context Large Language Models for Multi-Document Understanding and Summarization in Enterprise Applications , author=. ArXiv , year=
-
[38]
, author=
A Hierarchical Decoder with Three-level Hierarchical Attention to Generate Abstractive Summaries of Interleaved Texts. , author=. arXiv: Computation and Language , year=
-
[39]
ArXiv , year=
uMedSum: A Unified Framework for Advancing Medical Abstractive Summarization , author=. ArXiv , year=
-
[40]
, author=
Roles of Document Structure, Cognitive Strategy, and Awareness in Searching for Information. , author=. Reading Research Quarterly , year=
-
[41]
, author=
The Effects of Text Structure Instruction on Middle-Grade Students' Comprehension and Production of Expository Text. , author=. Reading Research Quarterly , year=
-
[42]
and Yang, Qiang and Xie, Xing , title =
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and Ye, Wei and Zhang, Yue and Chang, Yi and Yu, Philip S. and Yang, Qiang and Xie, Xing , title =. ACM Trans. Intell. Syst. Technol. , month = mar, articleno =. 2024 , issue_date =. doi:10.1145/36412...
-
[43]
Elhady, Ahmed and Elsayed, Khaled and Agirre, Eneko and Artetxe, Mikel. Improving Factuality in Clinical Abstractive Multi-Document Summarization by Guided Continued Pre-training. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. do...
-
[44]
arXiv preprint arXiv:2305.14251 , year=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. arXiv preprint arXiv:2305.14251 , year=
-
[45]
arXiv preprint arXiv:2501.03545 , year=
Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation , author=. arXiv preprint arXiv:2501.03545 , year=
-
[46]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Embrace Divergence for Richer Insights: A Multi-document Summarization Benchmark and a Case Study on Summarizing Diverse Information from News Articles , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[47]
medRxiv , pages=
Synthetic Data Distillation Enables the Extraction of Clinical Information at Scale , author=. medRxiv , pages=. 2024 , publisher=
2024
-
[48]
and Villarroel, Mauricio and Clifford, Gari D
Lee, Joon and Scott, Daniel J. and Villarroel, Mauricio and Clifford, Gari D. and Saeed, Mohammed and Mark, Roger G. , booktitle=. Open-access MIMIC-II database for intensive care research , year=
-
[49]
ArXiv , year=
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission , author=. ArXiv , year=
-
[50]
Lee, Jinhyuk and Yoon, Wonjin and Kim, Sungdong and Kim, Donghyeon and Kim, Sunkyu and So, Chan Ho and Kang, Jaewoo , title =. Bioinformatics , volume =. 2019 , month =. doi:10.1093/bioinformatics/btz682 , url =
-
[51]
TOPICAL : TOPIC Pages A utomagica L ly
Giorgi, John and Singh, Amanpreet and Downey, Doug and Feldman, Sergey and Wang, Lucy. TOPICAL : TOPIC Pages A utomagica L ly. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations). 2024. doi:10.18653/v1/2024.naacl-demo.1
-
[52]
What`s in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization
Adams, Griffin and Alsentzer, Emily and Ketenci, Mert and Zucker, Jason and Elhadad, No \'e mie. What`s in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021...
-
[53]
2015 26th international workshop on database and expert systems applications (dexa) , pages=
Clinical decision support systems: a survey of NLP-based approaches from unstructured data , author=. 2015 26th international workshop on database and expert systems applications (dexa) , pages=. 2015 , organization=
2015
-
[54]
Journal of Intelligent Connectivity and Emerging Technologies , volume=
Natural language processing for clinical decision support systems: A review of recent advances in healthcare , author=. Journal of Intelligent Connectivity and Emerging Technologies , volume=
-
[55]
Journal of biomedical informatics , volume=
What can natural language processing do for clinical decision support? , author=. Journal of biomedical informatics , volume=. 2009 , publisher=
2009
-
[56]
A Novel System for Extractive Clinical Note Summarization using EHR Data
Liang, Jennifer and Tsou, Ching-Huei and Poddar, Ananya. A Novel System for Extractive Clinical Note Summarization using EHR Data. Proceedings of the 2nd Clinical Natural Language Processing Workshop. 2019. doi:10.18653/v1/W19-1906
-
[57]
Generating SOAP Notes from Doctor-Patient Conversations Using Modular Summarization Techniques
Krishna, Kundan and Khosla, Sopan and Bigham, Jeffrey and Lipton, Zachary C. Generating SOAP Notes from Doctor-Patient Conversations Using Modular Summarization Techniques. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Paper...
-
[58]
Yim, Wen-wai and Yetisgen, Meliha. Towards Automating Medical Scribing : Clinic Visit D ialogue2 N ote Sentence Alignment and Snippet Summarization. Proceedings of the Second Workshop on Natural Language Processing for Medical Conversations. 2021. doi:10.18653/v1/2021.nlpmc-1.2
-
[59]
DERA : Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
Nair, Varun and Schumacher, Elliot and Tso, Geoffrey and Kannan, Anitha. DERA : Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents. Proceedings of the 6th Clinical Natural Language Processing Workshop. 2024. doi:10.18653/v1/2024.clinicalnlp-1.12
-
[60]
JMIR medical education , volume=
How does ChatGPT perform on the United States Medical Licensing Examination (USMLE)? The implications of large language models for medical education and knowledge assessment , author=. JMIR medical education , volume=. 2023 , publisher=
2023
-
[61]
Cureus , volume=
Overview of early ChatGPT’s presence in medical literature: insights from a hybrid literature review by ChatGPT and human experts , author=. Cureus , volume=. 2023 , publisher=
2023
-
[62]
ArXiv , year=
Bio-SIEVE: Exploring Instruction Tuning Large Language Models for Systematic Review Automation , author=. ArXiv , year=
-
[63]
Athanasios Lagopoulos and Grigorios Tsoumakas , title =. CoRR , volume =. 2020 , url =. 2011.09752 , timestamp =
arXiv 2020
-
[64]
Benchmarking Large Language Models for News Summarization
Zhang, Tianyi and Ladhak, Faisal and Durmus, Esin and Liang, Percy and McKeown, Kathleen and Hashimoto, Tatsunori B. Benchmarking Large Language Models for News Summarization. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00632
-
[65]
On Learning to Summarize with Large Language Models as References
Liu, Yixin and Shi, Kejian and He, Katherine and Ye, Longtian and Fabbri, Alexander and Liu, Pengfei and Radev, Dragomir and Cohan, Arman. On Learning to Summarize with Large Language Models as References. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
-
[66]
Summarizing, Simplifying, and Synthesizing Medical Evidence using GPT -3 (with Varying Success)
Shaib, Chantal and Li, Millicent and Joseph, Sebastian and Marshall, Iain and Li, Junyi Jessy and Wallace, Byron. Summarizing, Simplifying, and Synthesizing Medical Evidence using GPT -3 (with Varying Success). Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.119
-
[67]
Koh, Huan Yee and Ju, Jiaxin and Liu, Ming and Pan, Shirui , title =. ACM Comput. Surv. , month = dec, articleno =. 2022 , issue_date =. doi:10.1145/3545176 , abstract =
-
[68]
Conference on Empirical Methods in Natural Language Processing , year=
DocAsRef: An Empirical Study on Repurposing Reference-based Summary Quality Metrics as Reference-free Metrics , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[69]
Nenkova, Ani and Passonneau, Rebecca and McKeown, Kathleen , title =. ACM Trans. Speech Lang. Process. , month = may, pages =. 2007 , issue_date =. doi:10.1145/1233912.1233913 , abstract =
-
[70]
Jangra, Anubhav and Mukherjee, Sourajit and Jatowt, Adam and Saha, Sriparna and Hasanuzzaman, Mohammad , title =. ACM Comput. Surv. , month = jul, articleno =. 2023 , issue_date =. doi:10.1145/3584700 , abstract =
-
[71]
Annual Meeting of the Association for Computational Linguistics , year=
A Simple Theoretical Model of Importance for Summarization , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[72]
ArXiv , year=
Earlier Isn’t Always Better: Sub-aspect Analysis on Corpus and System Biases in Summarization , author=. ArXiv , year=
-
[73]
Journal of Medical Internet Research , year=
Potential Roles of Large Language Models in the Production of Systematic Reviews and Meta-Analyses , author=. Journal of Medical Internet Research , year=
-
[74]
BMJ Open , year=
Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry , author=. BMJ Open , year=
-
[75]
Energies , year=
The Resilience of Critical Infrastructure Systems: A Systematic Literature Review , author=. Energies , year=
-
[76]
Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Hierarchical summarization: Scaling up multi-document summarization , author=. Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[77]
Generating (Factual?) Narrative Summaries of RCTs: Experiments with Neural Multi-Document Summarization , author=. AMIA ... Annual Symposium proceedings. AMIA Symposium , year=
-
[78]
Proceedings of the conference
What’s in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization , author=. Proceedings of the conference. Association for Computational Linguistics. North American Chapter. Meeting , year=
-
[79]
Trends in cognitive sciences , volume=
Hierarchical process memory: memory as an integral component of information processing , author=. Trends in cognitive sciences , volume=. 2015 , publisher=
2015
-
[80]
F.I.M. Craik , abstract =. Memory: Levels of Processing , editor =. International Encyclopedia of the Social & Behavioral Sciences , publisher =. 2001 , isbn =. doi:https://doi.org/10.1016/B0-08-043076-7/01508-4 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.