RecurGuard: Runtime Monitoring for Reasoning-Token Consumption Attacks
Pith reviewed 2026-06-27 19:43 UTC · model grok-4.3
The pith
RecurGuard detects reasoning-token consumption attacks by tracking recurrence rate, volume growth, and progress toward the query in model traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
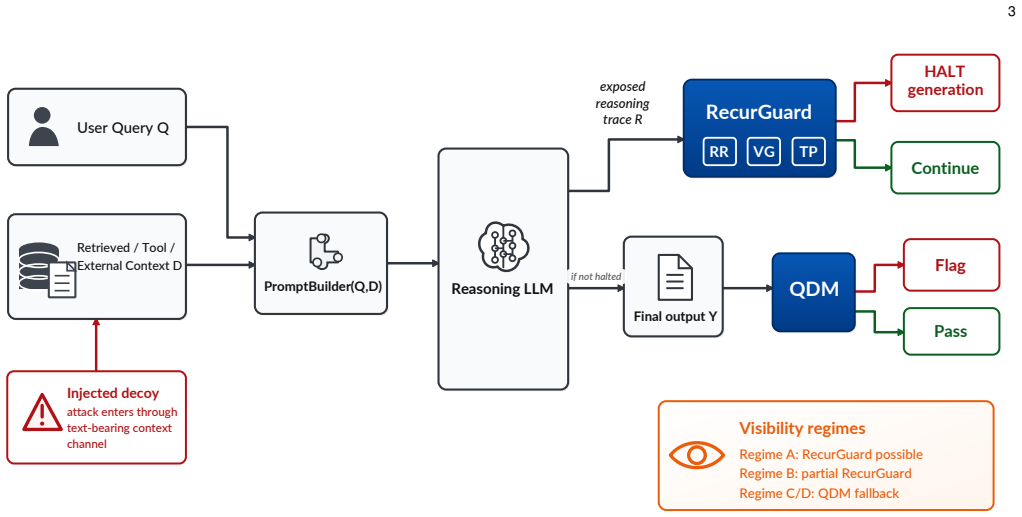
RecurGuard detects reasoning-chain consumption attacks when reasoning traces are exposed. It analyzes traces as they are generated and tracks three signals: recurrence rate, volume growth, and progress toward the user's query. If all three signals remain anomalous over three consecutive chunks, RecurGuard terminates generation early. On DS-R1-Qwen-7B it detects 99% of OverThink attacks and 92% of ExtendAttack instances while maintaining near-zero false positive rates on question answering, code generation, mathematics, and summarization. When traces are unavailable, QDM provides a post-hoc fallback based on the final output.
What carries the argument
RecurGuard, a runtime monitor that tracks recurrence rate, volume growth, and progress toward the user's query across reasoning-trace chunks to trigger early termination.
If this is right
- Early termination on anomalous traces prevents both denial of service and excess token billing from decoy-task attacks.
- Near-zero false positives on question answering, code generation, mathematics, and summarization allow safe deployment on normal workloads.
- Detection holds at 99% for OverThink and 92% for ExtendAttack on the tested model under the reported conditions.
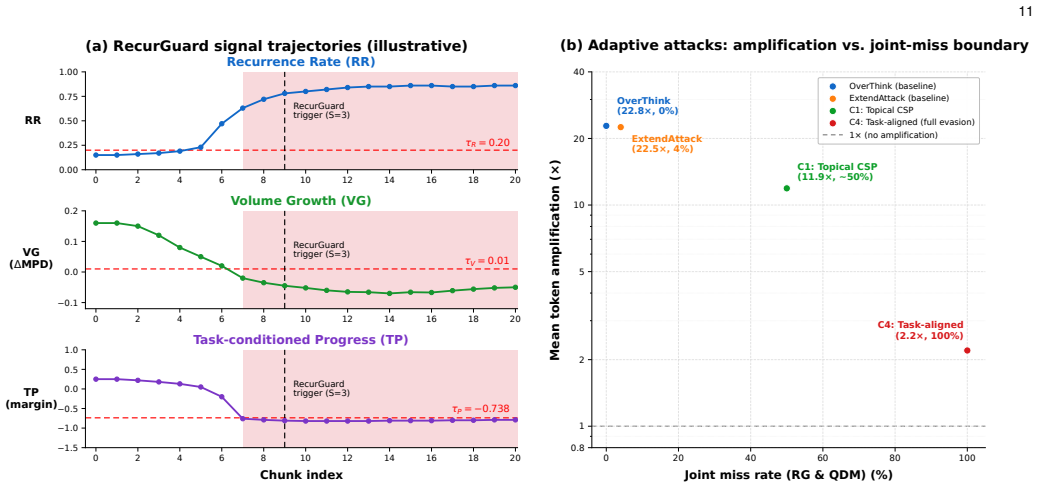
- Adaptive topical attacks retain 11.9x amplification at roughly 50% joint miss rate, while full semantic evasion drops amplification from 22.8x to 2.2x.
- QDM supplies a post-hoc fallback when reasoning traces are not exposed.
Where Pith is reading between the lines
- Platform-level integration of such monitors could cap the economic damage users suffer from token-wasting attacks without requiring model retraining.
- Pairing trace-based monitoring with input classifiers might raise the bar for attackers who must now evade both stages.
- The three-signal approach could be tested on closed models that expose partial traces or on new attack families that target different reasoning patterns.
- Limits shown in adaptive tests suggest that detection rates will vary with how much semantic freedom attackers are given in prompt construction.
Load-bearing premise
The three signals of recurrence rate, volume growth, and progress toward the user's query remain reliable indicators of attacks even when adversaries adapt the injected decoy tasks to evade detection.
What would settle it
An adaptive attack that produces reasoning traces keeping recurrence rate, volume growth, and query-progress signals within normal ranges for three or more consecutive chunks, yet still consumes far more tokens than a normal answer and withholds a final response, would falsify the detection claim.
Figures
read the original abstract
Reasoning-capable large language models can be induced to spend their generation budget on injected decoy tasks rather than answering the user's question, causing denial of service when no final answer is produced and denial of wallet when excess output tokens are billed. Input-side safety classifiers often miss these attacks because the injected prompts can appear syntactically benign. We build RecurGuard, a runtime monitor for detecting reasoning-chain consumption attacks when reasoning traces are exposed by the model. RecurGuard analyzes reasoning traces as they are generated and tracks three signals: recurrence rate, volume growth, and progress toward the user's query. If all three signals remain anomalous over three consecutive chunks, RecurGuard terminates generation early. We evaluate RecurGuard against OverThink and ExtendAttack across open-weight reasoning models and conduct adaptive stress tests on DS-R1-Qwen-7B. On this model, RecurGuard detects 99% of OverThink attacks and 92% of ExtendAttack instances while maintaining near-zero false positive rates on question answering, code generation, mathematics, and summarization. Adaptive evaluation reveals the limit of the defense: topical attacks retain 11.9x amplification with an approximately 50% joint miss rate, whereas full semantic evasion reduces amplification from 22.8x to 2.2x. When reasoning traces are unavailable, QDM provides a post-hoc fallback monitor based on the final output.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RecurGuard, a runtime monitor that analyzes exposed reasoning traces from LLMs to detect token-consumption attacks (OverThink and ExtendAttack) by tracking three signals—recurrence rate, volume growth, and progress toward the user's query—terminating generation after three consecutive anomalous chunks. It reports 99% detection on OverThink and 92% on ExtendAttack with near-zero false positives on benign tasks across open-weight models, plus a post-hoc QDM fallback when traces are unavailable; adaptive evaluations on DS-R1-Qwen-7B show topical decoys retain 11.9x amplification at ~50% joint miss rate while full semantic evasion drops amplification to 2.2x.
Significance. If the empirical results hold under the stated methodology, the work provides a concrete, deployable defense against an emerging class of reasoning-chain DoS/wallet attacks that bypass input classifiers, together with an explicit stress-test of its own limits under adaptation; the combination of runtime monitoring, multi-signal detection, and honest reporting of evasion cases is a useful contribution to LLM security.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation section: the headline detection rates (99% OverThink, 92% ExtendAttack) and near-zero FPs are stated without any description of how anomaly thresholds for the three signals were selected, what statistical tests were applied, or the precise definition of 'consecutive anomalous chunks,' which directly affects reproducibility and the load-bearing claim of reliable detection.
- [Adaptive evaluation] Adaptive evaluation paragraph: the reported ~50% joint miss rate for topical decoy tasks (retaining 11.9x amplification) demonstrates that the three signals can be jointly circumvented by semantically coherent but non-recurrent content; this finding is load-bearing because it directly qualifies the central assumption that recurrence rate, volume growth, and query-progress remain reliable indicators under adaptation.
- [Method / RecurGuard description] Implementation details: no pseudocode, threshold formulas, or chunking procedure is supplied for the three signals, leaving the concrete monitor definition underspecified relative to the quantitative claims.
minor comments (2)
- [Adaptive evaluation] The distinction between 'topical attacks' and 'full semantic evasion' in the adaptive results should be defined more precisely (e.g., what constitutes a 'decoy task' in each case) to allow readers to replicate the stress test.
- [Abstract] When reasoning traces are unavailable the QDM fallback is mentioned only briefly; a short description of its decision rule would clarify the scope of the defense.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, agreeing to revisions that improve reproducibility while noting where the manuscript already provides the relevant information.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the headline detection rates (99% OverThink, 92% ExtendAttack) and near-zero FPs are stated without any description of how anomaly thresholds for the three signals were selected, what statistical tests were applied, or the precise definition of 'consecutive anomalous chunks,' which directly affects reproducibility and the load-bearing claim of reliable detection.
Authors: We agree that the current description lacks sufficient detail on threshold selection and the exact definition of consecutive anomalous chunks, which impacts reproducibility. In the revised manuscript we will add an explicit subsection in the evaluation describing how thresholds were set empirically from the distribution of signals on benign traces (using upper percentiles), confirm that no formal statistical hypothesis tests were performed beyond empirical validation across the test sets, and define 'three consecutive anomalous chunks' as three successive chunks in which recurrence rate, volume growth, and query-progress signals all exceed their thresholds simultaneously. revision: yes
-
Referee: [Adaptive evaluation] Adaptive evaluation paragraph: the reported ~50% joint miss rate for topical decoy tasks (retaining 11.9x amplification) demonstrates that the three signals can be jointly circumvented by semantically coherent but non-recurrent content; this finding is load-bearing because it directly qualifies the central assumption that recurrence rate, volume growth, and query-progress remain reliable indicators under adaptation.
Authors: The manuscript already reports the ~50% joint miss rate and retained 11.9x amplification for topical decoys (as well as the drop to 2.2x under full semantic evasion) precisely to qualify the reliability of the three signals under adaptation. This honest reporting of the defense limits is presented as a core contribution rather than an unaddressed weakness; therefore no revision is required on this point. revision: no
-
Referee: [Method / RecurGuard description] Implementation details: no pseudocode, threshold formulas, or chunking procedure is supplied for the three signals, leaving the concrete monitor definition underspecified relative to the quantitative claims.
Authors: We agree the monitor implementation is currently underspecified. The revised manuscript will add (1) pseudocode for the full RecurGuard procedure, (2) explicit formulas for the three signals (recurrence rate as the fraction of repeated reasoning steps within a chunk, volume growth as the relative token-count increase per chunk, and query progress as cosine similarity of chunk embeddings to the user query), and (3) the chunking procedure (fixed 64-token windows aligned to reasoning steps). These additions will make the detection logic fully reproducible. revision: yes
Circularity Check
No circularity: RecurGuard detection logic is defined independently of evaluation outcomes
full rationale
The paper defines RecurGuard via three explicit signals (recurrence rate, volume growth, progress toward query) and a simple threshold rule (anomalous over three chunks). Detection rates (99% OverThink, 92% ExtendAttack) and FP rates are reported as direct empirical results from running the monitor on attack and benign datasets. No equations, fitted parameters, or self-citations reduce these performance numbers to the input data or prior author work by construction. Adaptive tests are presented as separate evidence of limits, confirming the derivation chain remains non-circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- anomaly thresholds for recurrence, volume, and progress
- consecutive anomalous chunks required
axioms (2)
- domain assumption Reasoning traces are exposed by the model and faithfully reflect generation behavior
- domain assumption The three signals jointly distinguish attack-induced consumption from legitimate reasoning
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
A. Yanget al., “Qwen3 technical report,” arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Not what you’ve signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 2023
2023
-
[4]
OWASP LLM10:2025 unbounded consumption,
OWASP Foundation, “OWASP LLM10:2025 unbounded consumption,” https://genai.owasp.org/llmrisk/ llm102025-unbounded-consumption/, 2025
2025
-
[5]
OverThink: Slowdown attacks on reasoning LLMs,
A. Kumar, J. Roh, A. Naseh, M. Karpinska, M. Iyyer, A. Houmansadr, and E. Bagdasarian, “OverThink: Slowdown attacks on reasoning LLMs,” arXiv:2502.02542, 2025
-
[6]
ExtendAttack: Attacking servers of LRMs via extending reasoning,
Z. Zhu, Y. Liu, Z. Xu, Y. Ma, H. Gao, N. Chen, Y. Guo, W. Qu, H. Xu, Z. Kang, X. Zhu, and J. Zhang, “ExtendAttack: Attacking servers of LRMs via extending reasoning,” arXiv:2506.13737, 2025, accepted to AAAI 2026
-
[7]
arXiv preprint arXiv:2411.17713 , year=
I. Fedorovet al., “Llama Guard 3-1B-INT4: Compact and efficient safeguard for human-AI conversations,” arXiv:2411.17713, 2024
-
[8]
SQuAD: 100,000+ questions for machine comprehension of text,
P . Rajpurkar, J. Zhang, K. Lopyrev, and P . Liang, “SQuAD: 100,000+ questions for machine comprehension of text,” inProceedings of EMNLP, 2016
2016
-
[9]
Evaluating Large Language Models Trained on Code
M. Chenet al., “Evaluating large language models trained on code,” arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Building with extended thinking,
Anthropic, “Building with extended thinking,” https://platform. claude.com/docs/en/build-with-claude/extended-thinking, 2026, accessed June 2026
2026
-
[11]
Sentence-BERT: Sentence embed- dings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embed- dings using siamese BERT-networks,” inProceedings of EMNLP- IJCNLP, 2019
2019
-
[12]
sentence-transformers/all-MiniLM- L6-v2,
SentenceTransformers, “sentence-transformers/all-MiniLM- L6-v2,” https://huggingface.co/sentence-transformers/ all-MiniLM-L6-v2, 2026, accessed June 2026
2026
-
[13]
Transformers: State-of-the- art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P . Cistac, T. Rault, R. Louf, M. Funtowicz, J. Davison, S. Shleifer, P . von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, and A. M. Rush, “Transformers: State-of-the- art natural language processing,” inProceedings of EMNLP: System Demonstrations, 2020
2020
-
[14]
Model system cards,
Anthropic, “Model system cards,” https://www.anthropic.com/ system-cards, 2026, accessed June 2026
2026
-
[15]
A. Grattafioriet al., “The Llama 3 herd of models,” arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Get to the point: Summa- rization with pointer-generator networks,
A. See, P . J. Liu, and C. D. Manning, “Get to the point: Summa- rization with pointer-generator networks,” inProceedings of ACL, 2017
2017
-
[18]
Teaching machines to read and comprehend,
K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P . Blunsom, “Teaching machines to read and comprehend,” inAdvances in Neural Information Processing Systems, 2015
2015
-
[19]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,” inProceedings of ACL, 2017
2017
-
[20]
Answer convergence as a signal for early stopping in reasoning,
X. Liu and L. Wang, “Answer convergence as a signal for early stopping in reasoning,” arXiv:2506.02536, 2025
-
[21]
Zero-Shot Embedding Drift Detection: A Lightweight Defense Against Prompt Injections in LLMs
A. Sekar, M. Agarwal, R. Sharma, A. Tanaka, J. Zhang, A. Damerla, and K. Zhu, “Zero-shot embedding drift detection: A lightweight defense against prompt injections in LLMs,” arXiv:2601.12359, 2026, accepted to NeurIPS 2025 Lock-LLM Workshop
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Probable inference, the law of succession, and statistical inference,
E. B. Wilson, “Probable inference, the law of succession, and statistical inference,”Journal of the American Statistical Association, vol. 22, no. 158, pp. 209–212, 1927
1927
-
[23]
Note on the sampling error of the difference between correlated proportions or percentages,
Q. McNemar, “Note on the sampling error of the difference between correlated proportions or percentages,”Psychometrika, vol. 12, no. 2, pp. 153–157, 1947
1947
-
[24]
Claude API pricing,
Anthropic, “Claude API pricing,” https://platform.claude.com/ docs/en/about-claude/pricing, 2026, accessed May 31, 2026
2026
-
[25]
Sponge examples: Energy-latency attacks on neural networks,
I. Shumailov, Y. Zhao, D. Bates, N. Papernot, R. Mullins, and R. Anderson, “Sponge examples: Energy-latency attacks on neural networks,” inIEEE European Symposium on Security and Privacy, 2021
2021
-
[26]
Excessive reasoning attack on reasoning LLMs,
W. M. Si, M. Li, M. Backes, and Y. Zhang, “Excessive reasoning attack on reasoning LLMs,” arXiv:2506.14374, 2025
-
[27]
X. Liu, X. Wang, Y. Zhang, S. Kariyappa, C. Xiang, M. Chen, G. E. Suh, and C. Xiao, “ReasoningBomb: A stealthy denial-of-service attack by inducing pathologically long reasoning in large reasoning models,” arXiv:2602.00154, 2026
-
[28]
ThinkTrap: Denial-of-service attacks against black-box LLM services via infinite thinking,
Y. Li, J. Wang, H. Zhu, J. Lin, S. Chang, and M. Guo, “ThinkTrap: Denial-of-service attacks against black-box LLM services via infinite thinking,” arXiv:2512.07086, 2025
-
[29]
POT: Induc- ing overthinking in LLMs via black-box iterative optimization,
X. Li, T. Huang, R. Mu, X. Huang, and G. Jin, “POT: Induc- ing overthinking in LLMs via black-box iterative optimization,” arXiv:2508.19277, 2025
-
[30]
BadThink: Triggered overthinking attacks on chain-of-thought reasoning in large language models,
S. Liu, R. Li, L. Yu, L. Zhang, Z. Liu, and G. Jin, “BadThink: Triggered overthinking attacks on chain-of-thought reasoning in large language models,” arXiv:2511.10714, 2025
-
[31]
BadReasoner: Planting tunable overthinking backdoors into large reasoning models for fun or profit,
B. Yi, Z. Fei, J. Geng, T. Li, L. Nie, Z. Liu, and Y. Li, “BadReasoner: Planting tunable overthinking backdoors into large reasoning models for fun or profit,” arXiv:2507.18305, 2025
-
[32]
Z. Wang, Y. Zhang, J. Chen, Z. Zhou, R. Liang, R. Du, J. Jia, C. Wu, and Y. Liu, “RECUR: Resource exhaustion attack via recursive-entropy guided counterfactual utilization and reflection,” arXiv:2602.08214, 2026
-
[33]
X. Zhang, X. Jia, L. Chen, and S. Li, “CODE: A contradiction- based deliberation extension framework for overthinking attacks on retrieval-augmented generation,” arXiv:2601.13112, 2026
-
[34]
Sponge tool attack: Stealthy denial-of-efficiency against tool-augmented agentic reasoning,
Q. Li and X. Wang, “Sponge tool attack: Stealthy denial-of-efficiency against tool-augmented agentic reasoning,” arXiv:2601.17566, 2026
-
[35]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Universal adversarial triggers for attacking and analyzing NLP,
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh, “Universal adversarial triggers for attacking and analyzing NLP,” inProceedings of EMNLP-IJCNLP, 2019
2019
-
[37]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Are aligned neural networks adversarially aligned?
N. Carlini, M. Nasr, C. A. Choquette-Choo, M. Jagielski, I. Gao, A. Awadalla, P . W. Koh, D. Ippolito, K. Lee, F. Tramer, and L. Schmidt, “Are aligned neural networks adversarially aligned?” arXiv:2306.15447, 2023
-
[39]
Coercing LLMs to do and reveal (almost) anything,
J. Geiping, A. Stein, M. Shu, K. Saifullah, Y. Wen, and T. Gold- stein, “Coercing LLMs to do and reveal (almost) anything,” arXiv:2402.14020, 2024
-
[40]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
N. Jain, A. Schwarzschild, Y. Wen, G. Somepalli, J. Kirchenbauer, P .-y. Chiang, M. Goldblum, A. Saha, J. Geiping, and T. Goldstein, “Baseline defenses for adversarial attacks against aligned language models,” arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
Z. Li, Q. Dong, J. Ma, D. Zhang, K. Jia, and Z. Sui, “SelfBud- geter: Adaptive token allocation for efficient LLM reasoning,” arXiv:2505.11274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
THINK-Bench: Evaluating thinking efficiency and chain-of-thought quality of large reasoning models,
Z. Li, Y. Chang, and Y. Wu, “THINK-Bench: Evaluating thinking efficiency and chain-of-thought quality of large reasoning models,” arXiv:2505.22113, 2025
-
[43]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Y. Sui, Y.-N. Chuang, G. Wang, J. Zhang, T. Zhang, J. Yuan, H. Liu, A. Wen, S. Zhong, N. Zou, H. Chen, and X. Hu, “Stop overthinking: A survey on efficient reasoning for large language models,” arXiv:2503.16419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.