SurgiQ: A Large-Scale Multi-Domain Benchmark for Evaluating Surgical Understanding in Large Language Models
Pith reviewed 2026-06-27 19:35 UTC · model grok-4.3
The pith
SurgiQ benchmark shows LLMs reach at most 68.1 percent accuracy on surgical questions, with general models ahead of biomedical ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
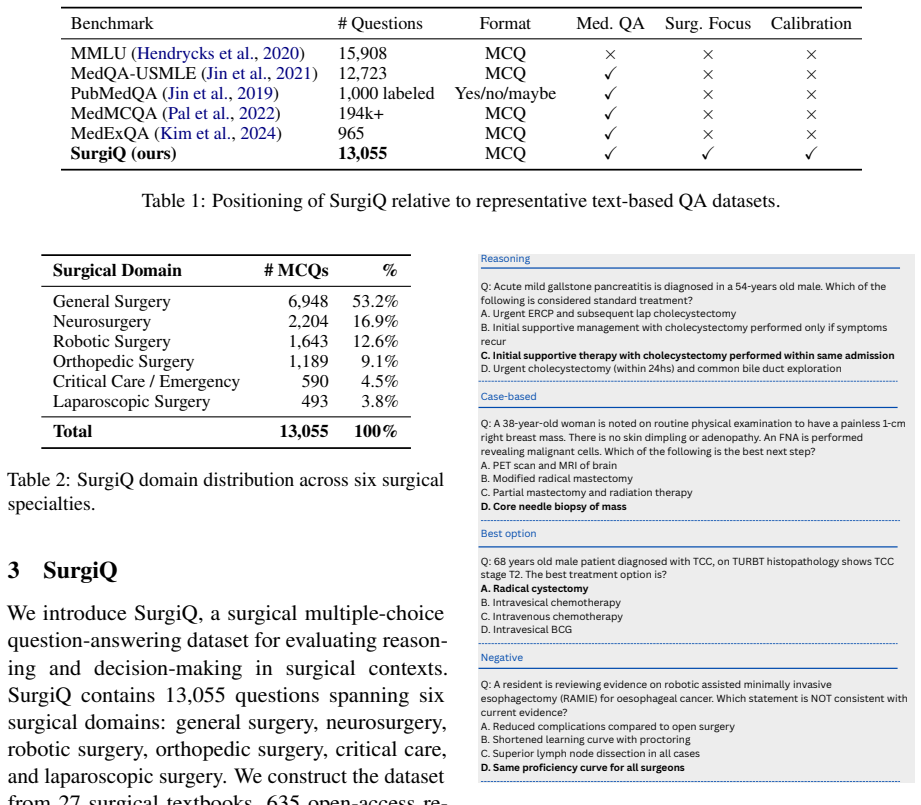
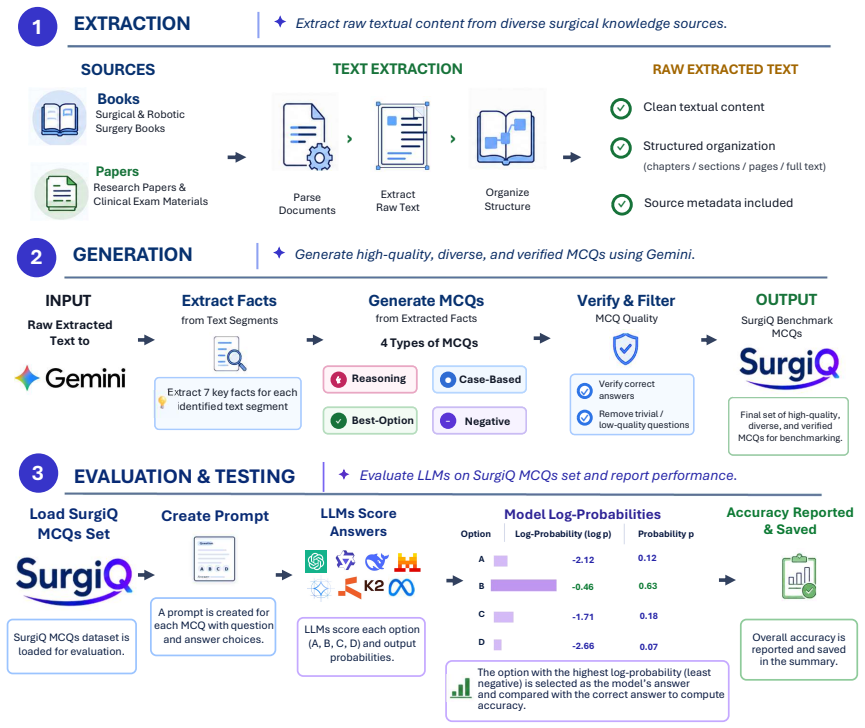
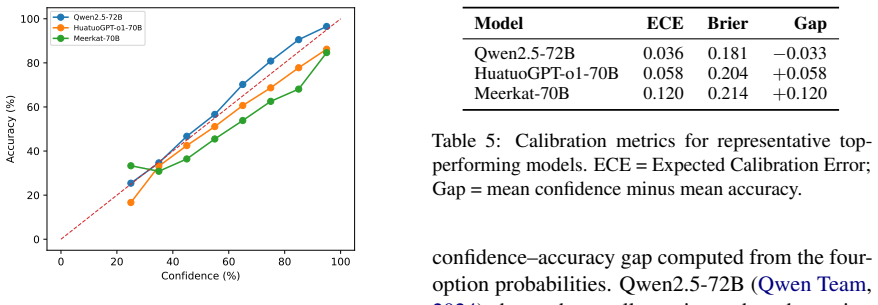
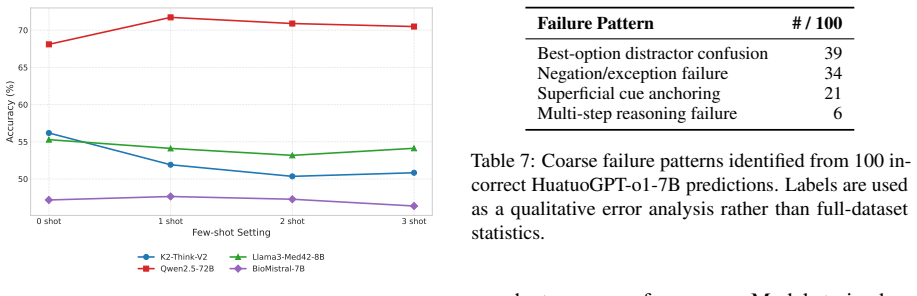
SurgiQ is a text-only benchmark of 13,055 questions spanning six surgical domains and four formats that require procedural reasoning, trade-off decisions, and negation handling. Evaluation under a unified log-likelihood protocol finds the best model at 68.1 percent accuracy, smaller models near random baseline, and general-purpose models such as Qwen2.5 ahead of most biomedical models, showing that medical specialization has not yet produced broad surgical coverage and that models remain prone to confident errors on plausible distractors.
What carries the argument
The SurgiQ benchmark, built by a multi-stage generation, verification, and expert-audit process from surgical sources, which supplies the questions used to measure surgical understanding.
If this is right
- Smaller models remain near the 25 percent random baseline.
- General-purpose models outperform most biomedical models on these questions.
- Even strong models make confident mistakes on clinically plausible distractors.
- Current medical specialization does not yet deliver broad surgical coverage.
Where Pith is reading between the lines
- Models may improve more from exposure to procedural decision sequences than from additional medical text fine-tuning.
- The same source-grounded construction method could be used to test understanding in other hands-on fields such as emergency procedures.
- Future work could add video or image inputs to check whether text-only scores understate or overstate real surgical capability.
Load-bearing premise
The pipeline that turns textbook and exam material into questions produces items that measure genuine surgical understanding without introducing systematic factual errors or biases.
What would settle it
If practicing surgeons score below 70 percent on the full set or if any model reaches 90 percent accuracy after ordinary medical training, the benchmark would fail to isolate surgical understanding.
Figures


read the original abstract
Reliable evaluation of large language models in surgery remains underdeveloped. Broad medical benchmarks test clinical knowledge, while surgery requires procedural reasoning, management trade-offs, negation handling, and selection among plausible operative decisions. We present SurgiQ, a text-only, source-grounded benchmark of 13,055 four-option multiple-choice questions spanning six surgical domains and four question formats: case-based, reasoning, best-option, and negative. SurgiQ is constructed from surgical textbooks, open-access papers, and examination material using a multi-stage generation, verification, and expert-audit pipeline. We evaluate 35 open-weight LLMs under a unified log-likelihood protocol. Our results show substantial remaining headroom: smaller models often remain near the 25\% random baseline, while the best model reaches 68.1\% accuracy. General-purpose models, especially Qwen2.5, outperform most biomedical models, suggesting that current medical specialization does not yet provide sufficiently broad surgical coverage. Calibration and error analysis further show that even strong models make confident mistakes on clinically plausible distractors, motivating more reliable and broader surgical LLM evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SurgiQ, a text-only benchmark of 13,055 four-option multiple-choice questions spanning six surgical domains and four formats (case-based, reasoning, best-option, negative). Questions are sourced from textbooks, open-access papers, and examination material via a multi-stage generation/verification/expert-audit pipeline. The authors evaluate 35 open-weight LLMs under a unified log-likelihood protocol, reporting that the best model reaches 68.1% accuracy while smaller models hover near the 25% random baseline, with general-purpose models (especially Qwen2.5) outperforming most biomedical models; they also provide calibration and error analysis showing confident mistakes on plausible distractors.
Significance. If the benchmark questions are shown to be valid and free of systematic construction artifacts, the work would be a useful contribution to domain-specific LLM evaluation by quantifying headroom in surgical reasoning and highlighting limitations of current medical fine-tuning. The scale, multi-domain coverage, and unified evaluation protocol are positive features.
major comments (2)
- [Benchmark Construction] Benchmark construction (multi-stage pipeline description): No quantitative metrics are reported on the expert-audit stage, such as question rejection rate, inter-rater agreement, or incidence of factual errors identified during audit. This is load-bearing for the central claims, because the headline results (68.1% peak accuracy and the general-purpose vs. biomedical model comparison) require that performance gaps reflect differences in surgical understanding rather than artifacts from question generation or distractor selection.
- [Experiments] Experiments and error analysis: The claim that even strong models make 'confident mistakes on clinically plausible distractors' is presented without supporting details on how distractor plausibility was verified or quantified during construction; this weakens interpretation of the calibration results and the motivation for broader surgical evaluation.
minor comments (1)
- [Results] Results section: Model comparison tables would benefit from explicit reporting of the number of questions per domain/format to allow readers to assess whether domain imbalance affects the aggregate accuracy figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional quantitative details on the construction pipeline would strengthen the paper's claims about benchmark validity. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction (multi-stage pipeline description): No quantitative metrics are reported on the expert-audit stage, such as question rejection rate, inter-rater agreement, or incidence of factual errors identified during audit. This is load-bearing for the central claims, because the headline results (68.1% peak accuracy and the general-purpose vs. biomedical model comparison) require that performance gaps reflect differences in surgical understanding rather than artifacts from question generation or distractor selection.
Authors: We agree that the absence of quantitative metrics on the expert-audit stage limits the strength of the validity argument. In the revised manuscript we will add the question rejection rate during audit, inter-rater agreement statistics (including any available Cohen's kappa or percentage agreement), and the count of factual errors identified and corrected. These will be placed in the benchmark construction section with a brief description of the audit protocol. revision: yes
-
Referee: [Experiments] Experiments and error analysis: The claim that even strong models make 'confident mistakes on clinically plausible distractors' is presented without supporting details on how distractor plausibility was verified or quantified during construction; this weakens interpretation of the calibration results and the motivation for broader surgical evaluation.
Authors: We accept that the current text does not sufficiently detail how distractor plausibility was verified. The revised version will expand the relevant section to describe the expert criteria used to judge clinical plausibility, any quantification performed during the multi-stage pipeline, and representative examples of distractors that were retained or revised. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential fits
full rationale
The paper presents SurgiQ as a constructed benchmark evaluated on 35 LLMs via log-likelihood. No equations, parameter fitting, predictions, or first-principles derivations appear in the abstract or described pipeline. Construction relies on external sources (textbooks, papers, exams) plus expert audit, but this is a one-way data-generation process with no reduction of outputs to inputs by definition or self-citation. Results (e.g., 68.1% max accuracy, general-purpose models outperforming biomedical ones) are direct empirical measurements, not forced by any internal loop. Self-citations, if present, are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The multi-stage generation, verification, and expert-audit pipeline from surgical textbooks, papers, and exams produces questions that accurately reflect surgical understanding.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[9]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[10]
Findings of the association for computational linguistics: NAACL 2024 , pages=
Agieval: A human-centric benchmark for evaluating foundation models , author=. Findings of the association for computational linguistics: NAACL 2024 , pages=
2024
-
[11]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[14]
Conference on health, inference, and learning , pages=
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering , author=. Conference on health, inference, and learning , pages=. 2022 , organization=
2022
-
[15]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[16]
arXiv preprint arXiv:2303.13375 , year=
Capabilities of gpt-4 on medical challenge problems , author=. arXiv preprint arXiv:2303.13375 , year=
-
[17]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and ichter, brian and Xia, Fei and Chi, Ed and Le, Quoc V and Zhou, Denny , booktitle =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =
-
[18]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[19]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graph of Thoughts: Solving Elaborate Problems with Large Language Models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[20]
arXiv preprint arXiv:2211.12588 , year=
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
-
[21]
Self-Refine: Iterative Refinement with Self-Feedback , url =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , booktitle =. Self-Refine: Iterative Refinem...
-
[22]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[23]
Nature Biomedical Engineering , volume=
Surgical data science for next-generation interventions , author=. Nature Biomedical Engineering , volume=. 2017 , doi=
2017
-
[24]
Annals of surgery , volume=
Robotic surgery: a current perspective , author=. Annals of surgery , volume=. 2004 , publisher=
2004
-
[25]
Pubmedqa: A dataset for biomedical research question answering , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[26]
Nature Medicine , volume=
Toward expert-level medical question answering with large language models , author=. Nature Medicine , volume=. 2025 , doi=
2025
-
[27]
arXiv preprint arXiv:2009.03300 , year=
Measuring Massive Multitask Language Understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[28]
Large Language Models Only Pass Primary School Exams in Indonesia: A Comprehensive Test on IndoMMLU , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2023.emnlp-main.760 , pages =
-
[29]
arXiv preprint arXiv:2302.13971 , year=
LLaMA: Open and Efficient Foundation Language Models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[30]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[31]
arXiv preprint arXiv:2309.16609 , year=
Qwen Technical Report , author=. arXiv preprint arXiv:2309.16609 , year=
-
[32]
2024 , eprint =
Qwen2.5 Technical Report , author =. 2024 , eprint =
2024
-
[33]
2025 , eprint =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
2025
-
[34]
arXiv preprint arXiv:2312.11805 , year=
Gemini: A Family of Highly Capable Multimodal Models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[35]
2025 , eprint =
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2025 , eprint =
2025
-
[36]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[37]
International Journal of Computer Assisted Radiology and Surgery , volume =
Surgical Process Modelling: A Review , author =. International Journal of Computer Assisted Radiology and Surgery , volume =
-
[38]
Springer Handbook of Robotics , pages =
Medical Robotics and Computer-Integrated Surgery , author =. Springer Handbook of Robotics , pages =. 2016 , publisher =
2016
-
[39]
Annals of Surgery , volume =
Artificial Intelligence in Surgery: Promises and Perils , author =. Annals of Surgery , volume =
-
[40]
, address =
Kim, Min P. , address =. Atlas of Minimally Invasive and Robotic Esophagectomy , year =. Atlas of Minimally Invasive and Robotic Esophagectomy , edition =
-
[41]
Bailey & Love's Short Practice of Surgery, 25th edn , volume =
Williams, Norman S and Bullstrode, Christopher JK and O'Connell, P Ronan , copyright =. Bailey & Love's Short Practice of Surgery, 25th edn , volume =. Annals of the Royal College of Surgeons of England , language =
-
[42]
Bariatric Robotic Surgery : A Comprehensive Guide , year =
Domene, Carlos Eduardo and Kim, Keith Chae and Puy, Ramon Vilallonga and Volpe, Paula , address =. Bariatric Robotic Surgery : A Comprehensive Guide , year =. Bariatric Robotic Surgery : A Comprehensive Guide , edition =
-
[43]
Pestana's Surgery Notes: Top 180 Vignettes of Surgical Diseases , author=
Dr. Pestana's Surgery Notes: Top 180 Vignettes of Surgical Diseases , author=. 2020 , publisher=
2020
-
[44]
, address =
Schlottmann, Francisco. , address =. Endoscopic, Laparoscopic and Robotic Techniques for Foregut Disorders , year =. Endoscopic, Laparoscopic and Robotic Techniques for Foregut Disorders , edition =
-
[45]
Essential Surgery: Problems Diagnosis and Management , volume =
Schofield, Philip F , issn =. Essential Surgery: Problems Diagnosis and Management , volume =. Annals of the Royal College of Surgeons of England , language =
-
[46]
Handbook of Robotic Surgery , year =
Zequi, St\^enio de Ca. Handbook of Robotic Surgery , year =. Handbook of Robotic Surgery , edition =
-
[47]
2020 , isbn =
USMLE Step 2 CK Lecture Notes 2021: Surgery , publisher =. 2020 , isbn =
2021
-
[48]
and Wiesel, Sam W
Miller, Mark D. and Wiesel, Sam W. and Albert, Todd J. , title =. 2021 , month = oct, isbn =
2021
-
[49]
, address =
Shu, Qiang. , address =. Pediatric Robotic Surgery , year =. Pediatric Robotic Surgery , edition =
-
[50]
Robotic Surgery and Nursing , year =
Wang, Gongxian and Zeng, Yu and Sheng, Xia , address =. Robotic Surgery and Nursing , year =. Robotic Surgery and Nursing , edition =
-
[51]
and Ferreira, Lydia Masako
Manzano, João Pádua. and Ferreira, Lydia Masako. , address =. Robotic Surgery Devices in Surgical Specialties , year =. Robotic Surgery Devices in Surgical Specialties , edition =
-
[52]
and Albala, David , address =
Persad, Raj and Goonewardene, Sanchia S. and Albala, David , address =. Robotic Surgery for Renal Cancer , year =. Robotic Surgery for Renal Cancer , edition =
-
[53]
and Ceccarelli, Graziano
Ceccarelli, Graziano. and Ceccarelli, Graziano. and Coratti, Andrea. , address =. Robotic Surgery of Colon and Rectum , year =. Robotic Surgery of Colon and Rectum , edition =
-
[54]
and Patel, Vipul R
Wiklund, Peter and Mottrie, Alexandre and Gundeti, Mohan S. and Patel, Vipul R. , address =. Robotic urologic surgery , year =. Robotic urologic surgery , edition =
-
[55]
and Dietz, Ulrich A
Kudsi, Omar Yusef. and Dietz, Ulrich A. and Fortelny, René. and Beldi, Guido. and Wiegering, Armin. , address =. Robotic Hernia Surgery , year =. Robotic Hernia Surgery , edition =
-
[56]
The SAGES Manual of Fluorescence-Guided Surgery , year =
Szoka, Nova and Renton, David and Horgan, Santiago and Horgan, Santiago and Szoka, Nova and Renton, David , address =. The SAGES Manual of Fluorescence-Guided Surgery , year =
-
[57]
and Perry, Kyle A
Grams, Jayleen. and Perry, Kyle A. and Tavakkoli, Ali. , address =. The SAGES Manual of Foregut Surgery , year =. The SAGES Manual of Foregut Surgery , edition =
-
[58]
Scott and Dakin, Gregory and Bates, Andrew and Bates, Andrew and Davis, Jr, S
Davis, Jr., S. Scott and Dakin, Gregory and Bates, Andrew and Bates, Andrew and Davis, Jr, S. Scott and Dakin, Gregory , address =. The SAGES Manual of Hernia Surgery , year =
-
[59]
Schwartz's Principles of Surgery , volume =
Orgoi, Sergelen and Biziya, Bat-Orgil and Lamid-Ochir, Bayarbaatar , issn =. Schwartz's Principles of Surgery , volume =. Central Asian journal of medical science , language =
-
[60]
and Grigorian, Areg
de Virgilio, Christian. and Grigorian, Areg. , address =. Surgery : a case based clinical review , year =. Surgery : a case based clinical review , edition =
-
[61]
, title =
Blackbourne, Lorne H. , title =. 2022 , month =
2022
-
[62]
2012 , isbn =
Surgical Critical Care and Emergency Surgery: Clinical Questions and Answers , publisher =. 2012 , isbn =
2012
-
[63]
and Sucandy, Iswanto
D'Hondt, Mathieu. and Sucandy, Iswanto. , address =. Textbook of Robotic Liver Surgery , year =. Textbook of Robotic Liver Surgery , edition =
-
[64]
2017 , month = dec, isbn =
The Mont Reid Surgical Handbook , edition =. 2017 , month = dec, isbn =
2017
-
[65]
and Kudsi, Omar Yusef
Samreen, Sarah. and Kudsi, Omar Yusef. and Oleynikov, Dmitry. and Patel, Ankit D. , address =. The SAGES Manual of Robotic Surgery. , year =
-
[66]
2011 , isbn =
Youmans Neurological Surgery , edition =. 2011 , isbn =
2011
-
[67]
arXiv preprint arXiv:2412.18925 , year=
HuatuoGPT-o1: Towards Medical Complex Reasoning with LLMs , author=. arXiv preprint arXiv:2412.18925 , year=
-
[68]
arXiv preprint arXiv:2404.00376 , year=
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks , author=. arXiv preprint arXiv:2404.00376 , year=
-
[69]
npj Digital Medicine , volume =
Small language models learn enhanced reasoning skills from medical textbooks , author =. npj Digital Medicine , volume =. 2025 , doi =
2025
-
[70]
arXiv preprint arXiv:2602.06965 , year=
MedMO: Grounding and Understanding Multimodal Large Language Models for Medical Images , author=. arXiv preprint arXiv:2602.06965 , year=
-
[71]
arXiv preprint arXiv:2408.06142 , year=
Med42-v2: A Suite of Clinical LLMs , author=. arXiv preprint arXiv:2408.06142 , year=
-
[72]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[73]
arXiv preprint arXiv:2512.06201 , year=
K2-V2: A 360-Open, Reasoning-Enhanced LLM , author=. arXiv preprint arXiv:2512.06201 , year=
-
[74]
arXiv preprint arXiv:2504.06196 , year=
TxGemma: Efficient and Agentic LLMs for Therapeutics , author=. arXiv preprint arXiv:2504.06196 , year=
-
[75]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving Open Language Models at a Practical Size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[76]
arXiv preprint arXiv:2507.05201 , year=
Medgemma technical report , author=. arXiv preprint arXiv:2507.05201 , year=
-
[77]
arXiv preprint arXiv:2601.08584 , year=
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
-
[78]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b Model Card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[79]
arXiv preprint arXiv:2311.16079 , year=
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models , author=. arXiv preprint arXiv:2311.16079 , year=
-
[80]
2024 , howpublished=
Llama3-OpenBioLLM-8B , author=. 2024 , howpublished=
2024
-
[81]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.