AeroSpectra Sentinel: An Auditable LLM Prompt-Chaining Decision-Support Workflow for Acute Asthma Risk Assessment from Respiratory Sounds and Clinical Signals
Pith reviewed 2026-06-27 19:09 UTC · model grok-4.3
The pith
A workflow fuses respiratory sound ML screening at 91% accuracy with five-stage LLM prompt chaining and guardrails to support auditable acute asthma risk assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
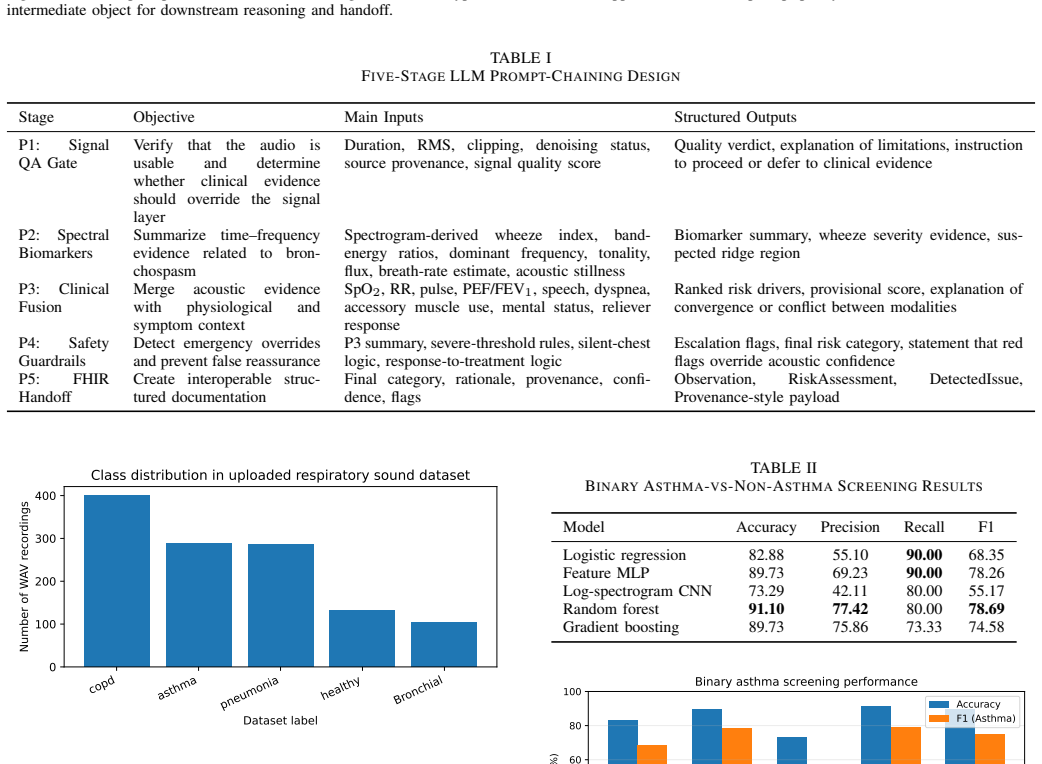
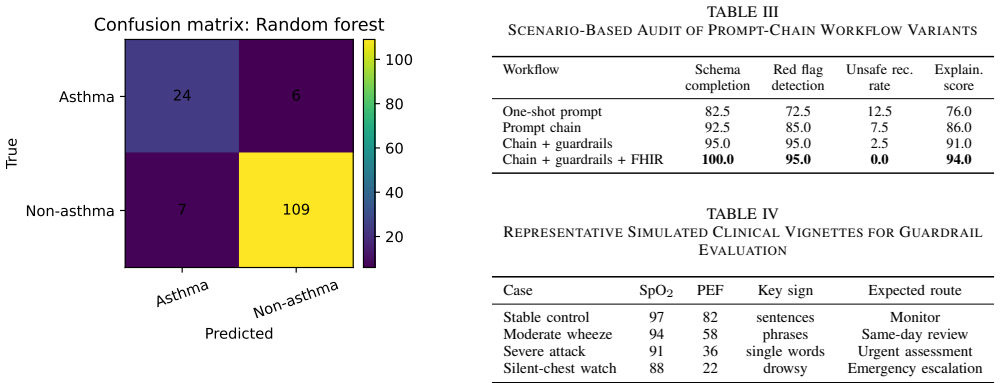
The central claim is that the AeroSpectra Sentinel workflow, which separates signal acquisition, STFT-based acoustic feature extraction, ML screening, clinical guardrails, and a five-stage LLM prompt-chaining process, enables both high-accuracy binary asthma screening (91.10% accuracy and 78.69% F1-score via random forest on 584 recordings) and stronger simulated safety plus documentation consistency via the guardrail-plus-schema variant on 40 vignettes, all while remaining auditable and client-side.
What carries the argument
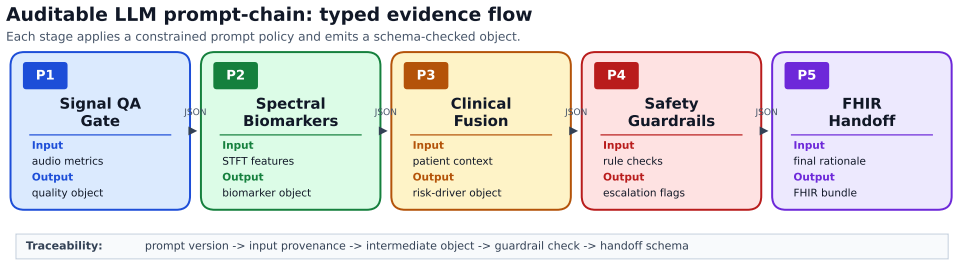
The five-stage LLM prompt-chaining process with clinical guardrails and FHIR schema validation, which separates acoustic screening from auditable clinical reasoning and reporting.
If this is right
- The random forest on acoustic features can distinguish asthma from non-asthma at 91.10% accuracy on the tested subset.
- Adding guardrails and FHIR schema validation to prompt chaining produces stronger safety and documentation consistency than one-shot or plain chaining.
- The staged workflow allows separation of signal preprocessing, ML screening, and LLM reasoning for auditability.
- The system generates FHIR-ready reports suitable for clinical decision support.
- Multiclass classification on the same data reaches 77.40% accuracy and 77.23% macro-F1.
Where Pith is reading between the lines
- If the accuracy holds on broader data, the workflow could integrate into mobile apps for preliminary asthma screening before clinician review.
- The client-side design implies reduced data transmission risks compared to fully cloud-based systems.
- Retraining the ML component on condition-specific datasets could extend the approach to related respiratory assessments.
- The emphasis on guardrails suggests a template for making other LLM medical workflows more controllable.
Load-bearing premise
That results from a public respiratory sound dataset subset and performance on simulated clinical vignettes will generalize to reliable, safe operation with real patients and live clinical signals.
What would settle it
A drop in random forest binary accuracy below 80% or failure of the guardrail-plus-schema variant to maintain safety and consistency when tested on a new collection of real patient recordings paired with live clinical signals and vignettes.
Figures



read the original abstract
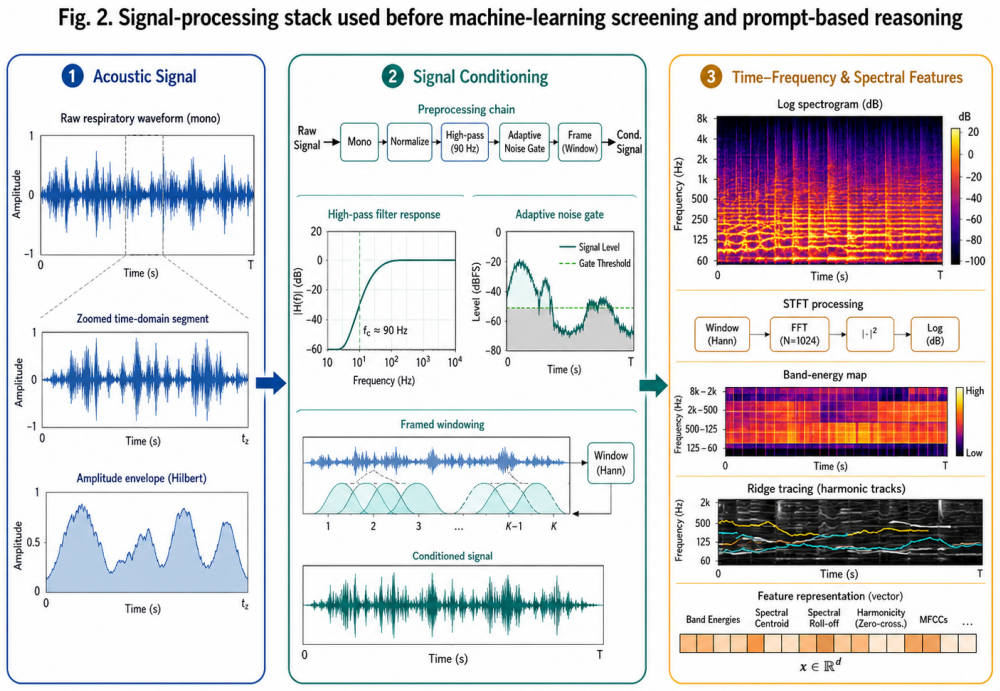
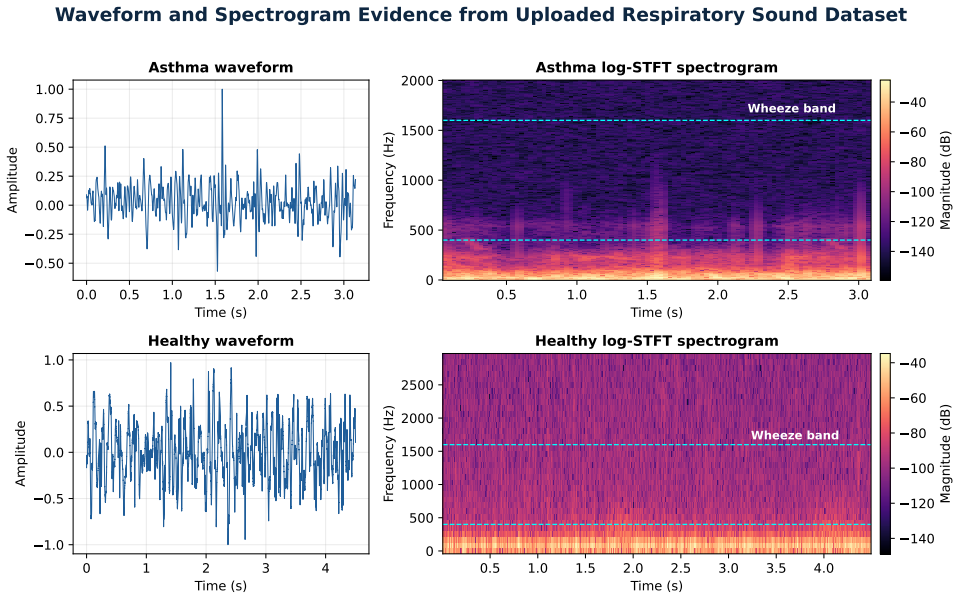
Acute asthma risk assessment requires rapid interpretation of respiratory sounds, oxygenation, airflow limitation, speech ability, work of breathing, mental status, and response to reliever therapy. Conventional audio-only classifiers can detect wheeze-like patterns but often lack transparent clinical reasoning and safe escalation logic. This paper presents AeroSpectra Sentinel, a client-side research prototype and decision-support workflow that combines short-time Fourier transform (STFT) respiratory sound analysis, lightweight machine-learning screening, clinical feature fusion, and a five-stage large language model (LLM) prompt-chaining process. The workflow separates signal acquisition, preprocessing, acoustic feature extraction, ML screening, clinical guardrails, and FHIR-ready reporting. We evaluated the audio screening component on a public respiratory sound dataset containing 1,211 WAV recordings from five labels. Using a stratified subset of 584 recordings, a random forest achieved 91.10% binary accuracy and 78.69% F1-score for asthma-vs-non-asthma screening, while a feature-based multilayer perceptron achieved 89.73% accuracy and 78.26% F1-score. A compact log-spectrogram CNN achieved 73.29% accuracy and 55.17% F1-score. Multiclass classification achieved 77.40% accuracy and 77.23% macro-F1. To evaluate the LLM workflow, we conducted a scenario-based audit on 40 simulated clinical vignettes comparing one-shot prompting, prompt chaining, prompt chaining with guardrails, and prompt chaining with guardrails plus FHIR schema validation. The guardrail-plus-schema variant achieved the strongest simulated safety and documentation consistency. AeroSpectra Sentinel is intended as a research prototype, not as a diagnostic medical device or clinically validated risk-assessment product.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AeroSpectra Sentinel, a client-side research prototype workflow for acute asthma risk assessment that integrates STFT-based respiratory sound analysis, lightweight ML screening (random forest achieving 91.10% binary accuracy and 78.69% F1-score on a stratified 584-recording subset from a 1,211-recording public dataset), clinical feature fusion, and a five-stage LLM prompt-chaining process with guardrails and FHIR schema validation. The LLM component is evaluated via a scenario-based audit on 40 simulated clinical vignettes, where the guardrail-plus-schema variant is reported to achieve the strongest simulated safety and documentation consistency. The work explicitly positions itself as a research prototype rather than a clinically validated device.
Significance. If the proxy results hold under real conditions, the work contributes an auditable, modular client-side framework combining audio ML with LLM chaining for respiratory decision support, with credit due for reporting concrete metrics on a named public dataset and for the emphasis on guardrails and schema validation. The significance remains modest because the central safety and escalation claims rest entirely on simulated vignettes without real-patient data, limiting immediate implications for clinical use.
major comments (3)
- [Abstract and LLM workflow evaluation] Abstract and LLM workflow evaluation section: the claim that the guardrail-plus-schema variant achieved the strongest simulated safety and documentation consistency rests on 40 vignettes without reported quantitative metrics, error bars, vignette construction details, or comparison to expert judgments, which is load-bearing for the LLM component's contribution to safe escalation logic.
- [Audio screening evaluation] Audio screening evaluation section: the random forest results (91.10% accuracy, 78.69% F1 on 584 recordings) lack specification of patient-independent splits or the exact label distribution in the stratified subset drawn from the five-class public corpus, undermining assessment of generalization to live clinical signals.
- [Overall workflow description] Overall workflow description: no external clinical cohort, prospective deployment data, or real-patient validation is provided to support transfer from the public dataset subset and simulated vignettes to acute asthma presentations, which is load-bearing for the decision-support workflow claim.
minor comments (2)
- [Abstract] The abstract could more explicitly quantify the limitations of the simulated vignette evaluation to prevent overinterpretation of the safety results.
- [Methods] Notation for the five-stage prompt-chaining process and the distinction between guardrails and schema validation could be clarified with a diagram or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the prototype nature of the work. We address each major comment below with planned revisions to improve transparency and methodological detail while preserving the manuscript's scope as a research prototype.
read point-by-point responses
-
Referee: [Abstract and LLM workflow evaluation] Abstract and LLM workflow evaluation section: the claim that the guardrail-plus-schema variant achieved the strongest simulated safety and documentation consistency rests on 40 vignettes without reported quantitative metrics, error bars, vignette construction details, or comparison to expert judgments, which is load-bearing for the LLM component's contribution to safe escalation logic.
Authors: We agree that the current description of the LLM evaluation is insufficiently detailed. The evaluation consists of a scenario-based audit on 40 simulated vignettes, and the manuscript does not report quantitative metrics, error bars, or expert comparisons. In revision we will expand the LLM workflow evaluation section to describe vignette construction criteria, the specific safety and consistency scoring rubric applied, and any available per-variant counts or qualitative observations. We will also add an explicit statement that the audit is simulated and not a substitute for expert or real-world validation. revision: partial
-
Referee: [Audio screening evaluation] Audio screening evaluation section: the random forest results (91.10% accuracy, 78.69% F1 on 584 recordings) lack specification of patient-independent splits or the exact label distribution in the stratified subset drawn from the five-class public corpus, undermining assessment of generalization to live clinical signals.
Authors: We accept this criticism. The manuscript will be revised to state whether the 584-recording stratified subset used patient-independent partitioning and to report the exact per-class counts (asthma vs. non-asthma and the original five-class breakdown) in both the training and test portions. revision: yes
-
Referee: [Overall workflow description] Overall workflow description: no external clinical cohort, prospective deployment data, or real-patient validation is provided to support transfer from the public dataset subset and simulated vignettes to acute asthma presentations, which is load-bearing for the decision-support workflow claim.
Authors: We agree that the work contains no real-patient cohort or prospective data. The manuscript already positions AeroSpectra Sentinel as a research prototype rather than a clinically validated device. We will strengthen the limitations and future-work paragraphs to more explicitly discuss the gap between public-dataset/simulated results and live clinical deployment, and to outline the additional validation steps required before any clinical use. revision: partial
Circularity Check
No circularity; all claims are direct empirical measurements on external public data and simulations
full rationale
The manuscript contains no derivation chain, first-principles predictions, or fitted-parameter reductions. Central results consist of (a) random-forest, MLP, and CNN accuracy/F1 numbers obtained by training and testing on a stratified 584-recording subset of the publicly available 1,211-recording respiratory-sound corpus, and (b) comparative safety/consistency scores on 40 hand-crafted simulated vignettes for four LLM prompting variants. These are straightforward hold-out or scenario-based evaluations; no quantity is defined in terms of itself, no input is relabeled as a prediction, and no load-bearing premise rests on self-citation. The paper therefore satisfies the self-contained empirical criterion and receives the lowest circularity score.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,
J. Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” inAdvances in Neural Information Processing Systems, 2022
2022
-
[2]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models,
D. Zhou et al., “Least-to-Most Prompting Enables Complex Reasoning in Large Language Models,” inInternational Conference on Learning Representations, 2023
2023
-
[3]
Self-Refine: Iterative Refinement with Self- Feedback,
A. Madaan et al., “Self-Refine: Iterative Refinement with Self- Feedback,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[4]
Few shot chain-of-thought driven reasoning to prompt LLMs for open ended medical question answering
S. S. Nachane et al., “Few-shot Chain-of-Thought Driven Reasoning to Prompt LLMs for Open-Ended Medical Question Answering,”arXiv preprint arXiv:2403.04890, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Diagnostic Reasoning Prompts Reveal the Potential for Large Language Model Interpretability in Medicine,
J. Cross, M. Choma, and J. Onofrey, “Diagnostic Reasoning Prompts Reveal the Potential for Large Language Model Interpretability in Medicine,”npj Digital Medicine, vol. 7, no. 1, 2024
2024
-
[6]
Evaluating Large Language Model Workflows in Clinical Decision Support: A Multi-Task Assessment,
S. E. Davis et al., “Evaluating Large Language Model Workflows in Clinical Decision Support: A Multi-Task Assessment,”npj Digital Medicine, 2025
2025
-
[7]
A Respiratory Sound Database for the Development of Automated Classification,
B. M. Rocha et al., “A Respiratory Sound Database for the Development of Automated Classification,” inPrecision Medicine Powered by pHealth and Connected Health. Springer, 2018, pp. 51–55
2018
-
[8]
Classification and Recognition of Lung Sounds Using Artificial Intelligence: A Review,
M. A. Rahman et al., “Classification and Recognition of Lung Sounds Using Artificial Intelligence: A Review,”Big Data and Cognitive Com- puting, vol. 8, no. 10, p. 127, 2024
2024
-
[9]
Detection of Wheeze Sounds in Respiratory Disorders: A Deep Learning Approach,
I. Saritas and N. Aydin, “Detection of Wheeze Sounds in Respiratory Disorders: A Deep Learning Approach,”International Journal of Ap- plied Mathematics Electronics and Computers, 2024
2024
-
[10]
Global Strategy for Asthma Man- agement and Prevention: 2025 Update,
Global Initiative for Asthma, “Global Strategy for Asthma Man- agement and Prevention: 2025 Update,” 2025. [Online]. Available: https://ginasthma.org/2025-gina-strategy-report/
2025
-
[11]
FHIR Provenance Resource,
HL7 International, “FHIR Provenance Resource,” 2026. [Online]. Avail- able: https://build.fhir.org/provenance.html
2026
-
[12]
FHIR RiskAssessment and DetectedIssue Re- sources,
HL7 International, “FHIR RiskAssessment and DetectedIssue Re- sources,” 2026. [Online]. Available: https://hl7.org/fhir/
2026
-
[13]
Asthma Detection Dataset Version 2,
M. T. Musaed, “Asthma Detection Dataset Version 2,” Kaggle dataset, 2024
2024
-
[14]
CNN Architectures for Large-Scale Audio Classifi- cation,
S. Hershey et al., “CNN Architectures for Large-Scale Audio Classifi- cation,” inProc. IEEE ICASSP, 2017, pp. 131–135
2017
-
[15]
Audio Set: An Ontology and Human-Labeled Dataset for Audio Events,
J. F. Gemmeke et al., “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events,” inProc. IEEE ICASSP, 2017, pp. 776–780
2017
-
[16]
Automatic Adventitious Respiratory Sound Analysis: A Systematic Review,
R. X. A. Pramono, S. A. Bowyer, and E. Rodriguez-Villegas, “Automatic Adventitious Respiratory Sound Analysis: A Systematic Review,”PLOS ONE, vol. 12, no. 5, 2017
2017
-
[17]
Classification of Lung Sounds Using Convolutional Neural Networks,
M. Aykanat, O. Kilic, B. Kurt, and S. Saryal, “Classification of Lung Sounds Using Convolutional Neural Networks,”EURASIP Journal on Image and Video Processing, vol. 2017, no. 1, 2017
2017
-
[18]
Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks,
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge- Intensive NLP Tasks,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[19]
Self-Consistency Improves Chain of Thought Rea- soning in Language Models,
X. Wang et al., “Self-Consistency Improves Chain of Thought Rea- soning in Language Models,” inInternational Conference on Learning Representations, 2023
2023
-
[20]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” inInternational Conference on Learning Representations, 2023
2023
-
[21]
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,
P. Liu et al., “Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,”ACM Computing Surveys, vol. 55, no. 9, 2023
2023
-
[22]
SMART on FHIR: A Standards-Based, Interoperable Apps Platform for Electronic Health Records,
K. D. Mandl, I. S. Kohane, and J. C. Mandel, “SMART on FHIR: A Standards-Based, Interoperable Apps Platform for Electronic Health Records,”Journal of the American Medical Informatics Association, vol. 23, no. 5, pp. 899–908, 2016
2016
-
[23]
CDS Hooks Specification,
HL7 International, “CDS Hooks Specification,” 2024. [Online]. Avail- able: https://cds-hooks.hl7.org/
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.