TRIAGE: Dialectical Reasoning for Explainable Risk Prediction on Irregularly Sampled Medical Time Series with LLMs
Pith reviewed 2026-06-27 17:26 UTC · model grok-4.3
The pith
Dialectical reasoning allows LLMs to produce continuous calibrated risk scores with explicit clinical rationales for medical time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
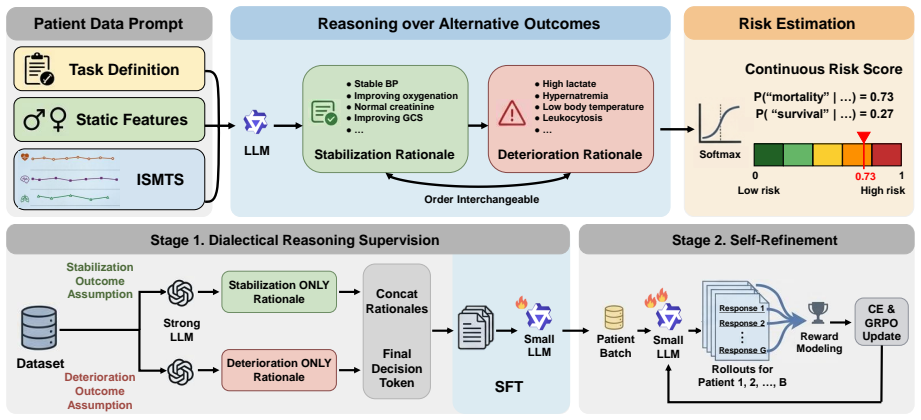
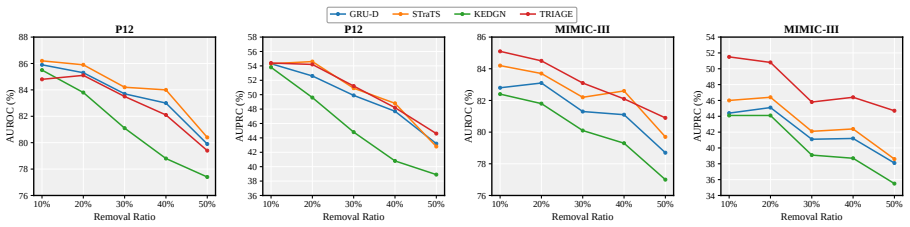
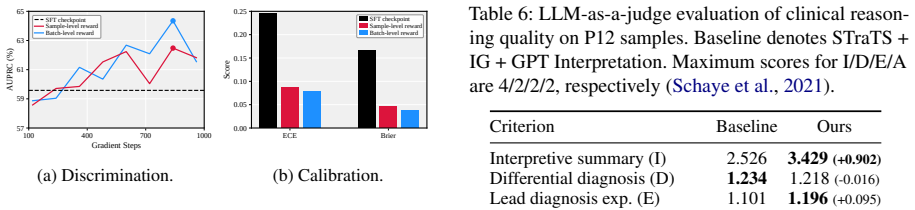
TRIAGE trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales. This dialectical formulation mitigates risk polarization, enabling a single LLM to yield continuous risk scores grounded in explicit clinical reasoning. Evaluated on three ISMTS benchmarks, it achieves an average AUPRC improvement of 3.3% and reduces calibration error by 81% compared to baselines, with rationales surpassing post-hoc explanations by 20% in clinical reasoning quality.
What carries the argument
The dialectical formulation that elicits outcome-specific rationales to prevent risk polarization.
If this is right
- A single LLM can generate both continuous risk scores and explicit reasoning without separate components.
- Average AUPRC improves by 3.3% on three ISMTS benchmarks.
- Calibration error drops by 81% compared to competitive baselines.
- Rationales receive 20% higher ratings in clinical reasoning quality by LLM-as-a-judge assessment.
Where Pith is reading between the lines
- Hospitals could use this to reduce alarm fatigue from binary alerts by providing graded scores with reasoning.
- The dialectical structure might apply to other LLM tasks where overconfident classification occurs, such as legal or financial forecasting.
- Real-time deployment in EHR systems would test whether continuous scores improve actual clinician decision-making over binary outputs.
- Extending to more than two competing outcomes could handle complex multi-class medical predictions.
Load-bearing premise
The LLM-as-a-judge evaluation of rationale quality accurately reflects clinical reasoning quality and the dialectical formulation does not introduce new forms of bias or polarization.
What would settle it
A study where practicing clinicians rate the generated rationales as no more useful for triage decisions than post-hoc explanations from standard models would falsify the claim of improved reasoning quality.
Figures



















read the original abstract
Clinical early warning systems built on electronic health records, in which clinical observations are recorded as irregularly sampled medical time series (ISMTS), must deliver both calibrated risk scores for patient triage and interpretable rationales that clinicians can verify. Large Language Models (LLMs) have been explored for this task, yet they collapse graded clinical risk into overconfident binary predictions. This risk polarization undermines both calibration and cross-patient comparability. To address this, we propose TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales. This dialectical formulation mitigates risk polarization, enabling a single LLM to yield continuous risk scores grounded in explicit clinical reasoning. Evaluated on three ISMTS benchmarks, TRIAGE achieves an average AUPRC improvement of 3.3% and reduces calibration error by 81% compared to the competitive baselines. An LLM-as-a-judge assessment further shows that our rationales surpass post-hoc explanations from the baseline by 20% in clinical reasoning quality. The source code is available at https://github.com/HyeongWon-Jang/TRIAGE .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TRIAGE, a framework that trains an LLM to generate dialectical reasoning over competing clinical outcomes by eliciting outcome-specific rationales for risk prediction on irregularly sampled medical time series (ISMTS). This is claimed to mitigate risk polarization, enabling a single LLM to produce continuous risk scores grounded in explicit clinical reasoning. On three ISMTS benchmarks, TRIAGE reports an average AUPRC improvement of 3.3% and an 81% reduction in calibration error versus competitive baselines, plus a 20% gain in clinical reasoning quality via LLM-as-a-judge evaluation. Source code is released at https://github.com/HyeongWon-Jang/TRIAGE.
Significance. If the empirical gains and rationale quality claims hold under rigorous validation, the work could meaningfully advance calibrated and interpretable LLM-based early warning systems for clinical time series data. The public code release is a clear strength that aids reproducibility.
major comments (1)
- [Evaluation section] The central claim that dialectical rationales ground continuous scores in 'explicit clinical reasoning' rests on the LLM-as-a-judge metric showing 20% quality improvement. The manuscript provides no details on judge-model independence, training-data overlap, or correlation with human clinician ratings (Evaluation section and abstract). This is load-bearing because the skeptic concern about circularity directly undermines the grounding argument even if AUPRC and calibration numbers improve.
minor comments (1)
- [Abstract] The abstract states results on 'three ISMTS benchmarks' without naming the datasets; this should be stated explicitly in the abstract for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the evaluation methodology. We will revise the manuscript to provide the requested transparency on the LLM-as-a-judge setup, thereby strengthening the support for our claims regarding explicit clinical reasoning.
read point-by-point responses
-
Referee: [Evaluation section] The central claim that dialectical rationales ground continuous scores in 'explicit clinical reasoning' rests on the LLM-as-a-judge metric showing 20% quality improvement. The manuscript provides no details on judge-model independence, training-data overlap, or correlation with human clinician ratings (Evaluation section and abstract). This is load-bearing because the skeptic concern about circularity directly undermines the grounding argument even if AUPRC and calibration numbers improve.
Authors: We agree that the Evaluation section and abstract lack sufficient detail on the LLM-as-a-judge protocol, which leaves the grounding claim vulnerable to circularity concerns. In the revised manuscript we will expand the Evaluation section to specify: (i) the judge model is a distinct, held-out instance from a different model family than those used for TRIAGE training or inference; (ii) the judge was not exposed to any of the three ISMTS benchmark datasets during its own training or fine-tuning; and (iii) we will explicitly state that no direct correlation study with human clinicians was performed and will list this as a limitation. These additions will allow readers to assess the independence of the 20 % quality improvement while preserving the primary AUPRC and calibration results, which do not rely on the judge metric. revision: yes
Circularity Check
No circularity: empirical results rest on independent benchmarks
full rationale
The abstract and provided text describe a training procedure for dialectical rationales followed by separate reporting of AUPRC, calibration error, and an LLM-as-a-judge score. No equations, parameter fits, or derivations are shown that reduce the claimed mitigation of risk polarization to the inputs by construction. The evaluation metrics are external to the method itself and do not rely on self-citation chains or renaming of known results. The LLM-as-a-judge is presented as an additional assessment rather than a load-bearing premise that loops back to the training data or model outputs in a definitional way.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer
Springer. Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks.Advances in neural information processing systems, 28. Danny Castro, Sachin Patil, Muhammad Zubair, and Michael Keenaghan. 2024. Arterial blood gas.Stat- Pearls. Zhengping Che, Sanjay Purushotham, Kyunghyu...
Pith/arXiv arXiv 2015
-
[2]
InForty-second International Conference on Machine Learning
TIMING: Temporality-aware integrated gra- dients for time series explanation. InForty-second International Conference on Machine Learning. Pengcheng Jiang, Cao Danica Xiao, Minhao Jiang, Par- minder Bhatia, Taha Kass-Hout, Jimeng Sun, and Ji- awei Han. 2025. Reasoning-enhanced healthcare pre- dictions with knowledge graph community retrieval. InInternatio...
Pith/arXiv arXiv 2025
-
[3]
InForty-second Interna- tional Conference on Machine Learning
Hi-patch: Hierarchical patch gnn for irregular multivariate time series. InForty-second Interna- tional Conference on Machine Learning. Victoria Mank, Waqas Azhar, and Kevin Brown. 2026. Leukocytosis. InStatPearls [Internet]. StatPearls Publishing. Sunil Munakomi, Konstantinos Margetis, and Lind- say M Iverson. 2026. Glasgow coma scale. InStat- Pearls [In...
2026
-
[4]
Carer-clinical reasoning-enhanced representa- tion for temporal health risk prediction. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10392–10407. OpenAI. 2025. Gpt-5.1 instant and gpt-5.1 thinking system card addendum. System card, OpenAI. Marc’Aurelio Ranzato, Sumit Chopra, Michael Auli, and Wojciech Z...
Pith/arXiv arXiv 2024
-
[5]
Yulia Rubanova, Ricky TQ Chen, and David K Duve- naud
Early prediction of sepsis from clinical data: the physionet/computing in cardiology challenge 2019.Critical care medicine, 48(2):210–217. Yulia Rubanova, Ricky TQ Chen, and David K Duve- naud. 2019. Latent ordinary differential equations for irregularly-sampled time series.Advances in neural information processing systems, 32. Takaya Saito and Marc Rehms...
Pith/arXiv arXiv 2019
-
[6]
PMLR. Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, and 1 others. 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534. Sindhu Tipirneni and Chandan K Reddy. 2022. Self- supervised transformer for sparse and irregularly sam- pled multivariate clinical time-...
Pith/arXiv arXiv 2025
-
[7]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2026. Dapo: An open-source llm reinforcement learning system at scale.Advances in Neural Information Processing Systems, 38:113222–113244. Zhuoning Yuan, Yan Yan, M...
Pith/arXiv arXiv 2026
-
[8]
## Final Decision
using gpt-oss-120b (Agarwal et al., 2025), a sparse mixture-of-experts Transformer with 117B total parameters and 5.1B active parameters per token. We load the official release weights in na- tive MXFP4 and sample at temperature 0.7 with reasoning_effort=high. We provide the full prompt in Appendix G. Table 7: In-hospital mortality prediction on MIMIC-III...
2025
-
[9]
Specifically, for P12 and MIMIC- 13https://github.com/easonLuo2001/KEDGN 14https://github.com/easonLuo2001/Hi-Patch Table 10: SFT Experimental setup details
and oversample the minority class during data collection. Specifically, for P12 and MIMIC- 13https://github.com/easonLuo2001/KEDGN 14https://github.com/easonLuo2001/Hi-Patch Table 10: SFT Experimental setup details. Parameter Value batch_size 64 (P12) 128 (P19/MIMIC-III) max_length 12,288 (P12/MIMIC-III) 11,264 (P19) num_train_epochs 3 optimizer AdamW lea...
2022
-
[10]
in addition to our 4B default, and further to Llama 3.2 3B (Grattafiori et al., 2024) across archi- tecture families. As reported in Table 14, TRIAGE 17 retains a consistent advantage over the correspond- ing baselines on every backbone, suggesting that our reasoning supervision generalizes beyond a sin- gle model. E.3 Inference Direction Analysis Since T...
2024
-
[11]
If the patient indeed survives, which features might be the cause?
-
[12]
If the patient indeed experiences in-hospital death, which features might be the cause?
-
[13]
Make a final decision: ‘0’ for survival, ‘1’ for in-hospital death
-
[14]
0” or “1
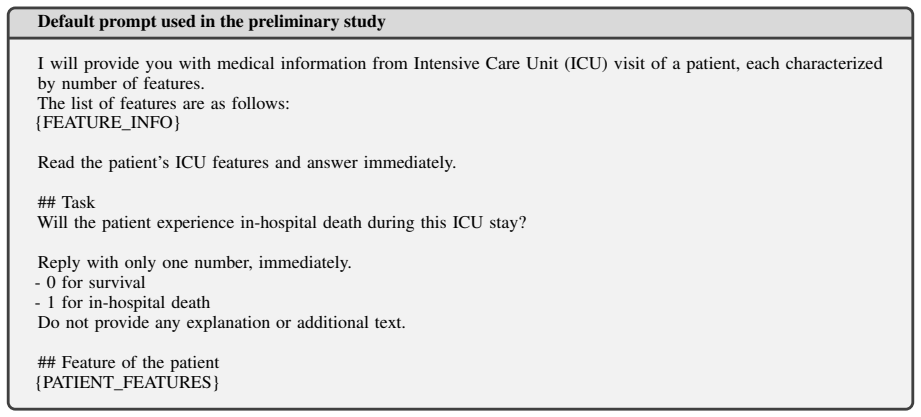
Patient Features Textualized Static Features: A patient is 54 years old, female, stayed in surgical ICU. Textualized Temporal Observations: HR: (0.2h, 73), (0.7h, 77), (1.7h, 60), … GCS: (0.2h, 15), (3.7h, 15), … BUN: (10.7h, 13), (33.2h, 8), … Figure 6: Example prompt format used by TRIAGE. Only some of the features are shown. The input is organized into...
-
[17]
Make a final decision: ‘0’ for survival, ‘1’ for in-hospital death. Your answer format must be as follows: ``` ## Rationale for survival [possible justification if patient survives] ## Rationale for in-hospital death [possible justification if patient experiences in-hospital death] ## Final Decision [0 (survival) or 1 (in-hospital death); respond by singl...
-
[18]
If the patient indeed experiences in-hospital death, which of the patient’s given features might be the cause?
-
[19]
If the patient indeed survives, which of the patient’s given features might be the cause?
-
[20]
Make a final decision: ‘0’ for survival, ‘1’ for in-hospital death. Your answer format must be as follows: ``` ## Rationale for in-hospital death [possible justification if patient experiences in-hospital death] ## Rationale for survival [possible justification if patient survives] ## Final Decision [0 (survival) or 1 (in-hospital death); respond by singl...
-
[23]
Make a final decision: ‘0’ for no sepsis onset within the next 6 hours, ‘1’ for sepsis onset within the next 6 hours. Your answer format must be as follows: ``` ## Rationale for no sepsis [possible justification if patient does not experience sepsis onset within the next 6 hours] ## Rationale for sepsis [possible justification if patient experiences sepsi...
-
[24]
If the patient indeed experiences sepsis onset within the next 6 hours, which of the patient’s given features might be the cause?
-
[25]
If the patient indeed does not experience sepsis onset within the next 6 hours, which of the patient’s given features might be the cause?
-
[26]
Make a final decision: ‘0’ for no sepsis onset within the next 6 hours, ‘1’ for sepsis onset within the next 6 hours. Your answer format must be as follows: ``` ## Rationale for sepsis [possible justification if patient experiences sepsis onset within the next 6 hours] ## Rationale for no sepsis [possible justification if patient does not experience sepsi...
-
[27]
Describe the clinical evidence observed in the patient’s features
-
[28]
""Will the patient experience in-hospital death during this ICU stay?
Make a final decision: ‘0’ for survival, ‘1’ for in-hospital death. Your answer format must be as follows: ``` ## Rationale [clinical evidence observed in the patient’s features] ## Final Decision [0 (survival) or 1 (in-hospital death); respond by single number only] ``` ## Feature of the patient {PATIENT_FEATURES} Figure 18: Prompt template used for theO...
-
[29]
Key baseline or contextual mortality-risk factors: - Examples: age, major comorbidities, chronic organ disease, frailty-relevant context, admission context, or other baseline risks
-
[30]
Main acute ICU problem or organ dysfunction: - Examples: respiratory failure, shock or hemodynamic instability, renal dysfunction, metabolic acidosis, neuro- logic depression, hepatic or coagulation dysfunction, infection signal, multi-organ dysfunction, or other acute problems explicitly supported by the data
-
[31]
- Gives special attention to persistent instability or late deterioration near the end of the observation window
Illness time course or trajectory: - Correctly distinguishes worsening, improving, fluctuating, or stable course. - Gives special attention to persistent instability or late deterioration near the end of the observation window
-
[32]
differential
Clinically meaningful prognostic abstractions: - Examples: persistent hypotension, escalating oxygen needs, worsening renal function, severe acidosis, multi- organ dysfunction, improving hemodynamics, stable oxygenation, transient isolated abnormality. - These abstractions must be grounded in the provided data. Scoring anchors: - 4: Accurate, patient-spec...
-
[33]
What objective patient-specific evidence the reasoning used correctly
-
[34]
Any unsupported claims, hallucinations, contradictions, or missing-data assumptions
-
[35]
Whether the reasoning correctly handled the temporal trajectory
-
[36]
High", "Medium
Whether the reasoning considered counterevidence or uncertainty. Do not output a long chain-of-thought. Output only the JSON object below. # Output Format Return valid JSON only. Do not include markdown, comments, or extra text. The score and all subscores must be integers. The final score must equal the sum of the four subscores after applying any cap or...
-
[37]
Observed patient information from the first 48 hours of ICU stay
-
[38]
PaO2 around 98–125 mmHg indicating adequate oxygenation
A rationale explaining why the patient is predicted to die or survive. Your task is to judge whether the rationale is grounded in the observed patient information, or whether it contains serious hallucination: concrete clinical facts that are completely absent from the patient data. Return True if the rationale’s substantive clinical evidence is present i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.