Decoy-Calibrated Failure Audits for Language Models
Pith reviewed 2026-06-27 17:22 UTC · model grok-4.3
The pith
Janus confirms an error descriptor only when it exceeds the performance of frequency-matched random decoys on discovery data and maintains its lift on held-out data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
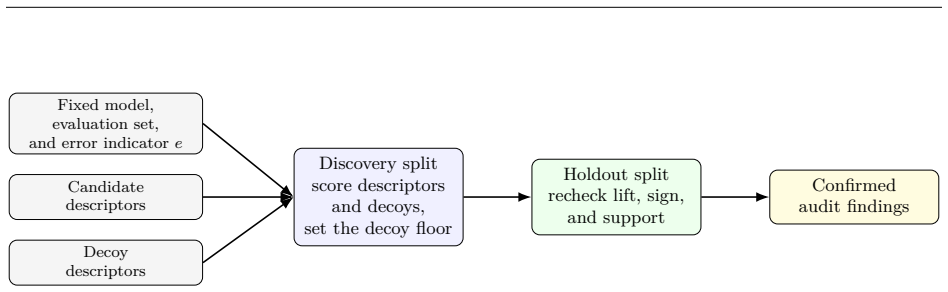
Janus scores each candidate error explanation, called a descriptor, by its error-rate lift, then compares it against fake descriptors that have identical frequencies but are randomly permuted across examples. A descriptor is accepted as a finding only if its lift exceeds the maximum lift among the decoys on the discovery set and if the lift remains positive on a held-out set. In experiments, this procedure recovers a planted failure mode involving long lookup chains but rejects all candidates flagged by an uncalibrated baseline on two standard benchmarks.
What carries the argument
The Janus procedure, which establishes a decoy-calibrated threshold for error-rate lift and requires replication on held-out data to confirm descriptors.
If this is right
- In a controlled audit of multi-table lookup tasks, Janus identifies the planted failure involving long-chain descriptors and their interactions.
- On MuSiQue and LongBench v2, the SliceLine baseline flags plausible high-error pockets but Janus confirms none of them.
- On LongBench v2 an uncalibrated fixed threshold reports 20 descriptors, the decoy floor leaves one, and the holdout check rejects the last one after its lift shrinks from 0.36 to 0.05.
- The resulting principle separates proposing explanations from reporting them: candidates may come from any source but only those that beat decoys and replicate become audit findings.
Where Pith is reading between the lines
- The same two-stage check could be applied to post-hoc analyses in other model families where many candidate factors are examined after the fact.
- Without similar calibration, many published reports of concentrated failure modes in language models may reflect selection effects rather than stable patterns.
- Integrating descriptor generation with the Janus filter could produce automated audit pipelines that still control for multiple testing.
Load-bearing premise
Randomly assigned decoy descriptors with matching frequencies form a valid null distribution that captures the rate of spurious error associations from testing many candidates.
What would settle it
An experiment in which known spurious descriptors are shown to pass the decoy floor and holdout check at high rates, or in which a verified true failure mode is rejected by the procedure.
Figures




read the original abstract
Useful audits reveal not only how often a model fails, but also where its failures concentrate. An auditor may test many candidate explanations: long inputs, indirect questions, distracting evidence, or combinations of these factors. The risk is selection. The largest observed effect may reflect a real failure mode, or it may simply be the best result among many tried. We introduce Janus, a procedure for deciding when a proposed error explanation is credible enough to report. The goal is not to generate new explanations, but to decide which ones hold up. The auditor starts with a fixed model, a labeled evaluation set, and a frozen list of candidate explanations, which we call descriptors. Janus scores each descriptor by its error-rate lift, then compares real descriptors with fake ones that have the same frequencies but are randomly assigned to examples. A descriptor is confirmed only if it beats this decoy floor on the data used for discovery and then repeats on separate held-out data. In a controlled audit of multi-table lookup tasks, Janus identifies the planted failure, confirming long-chain descriptors and their interactions. The LLM often stops partway through the lookup chain instead of reaching the final answer. On two public benchmarks, MuSiQue and LongBench v2, the SliceLine baseline flags plausible high-error pockets, but Janus confirms none of them. Ablations show why both safeguards matter. On LongBench v2, an uncalibrated fixed threshold reports 20 descriptors, the decoy floor leaves one, and the holdout check rejects the last one after its lift shrinks from 0.36 to 0.05. The resulting principle separates proposing explanations from reporting them. Candidates may come from any source, but only those that beat decoys and replicate on fresh data become audit findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Janus, a procedure to decide which candidate error descriptors (explanations for LM failures) are credible to report. Descriptors are scored by error-rate lift; each is compared against a decoy floor obtained by randomly reassigning descriptors to examples while preserving marginal frequencies. A descriptor is confirmed only if it exceeds the decoy floor on the discovery split and its lift replicates on a held-out split. In a controlled multi-table lookup audit, Janus recovers the planted long-chain failure mode and its interactions. On MuSiQue and LongBench v2, SliceLine flags high-error pockets but Janus confirms none. Ablations illustrate that both the decoy calibration and the hold-out check are required; an uncalibrated threshold reports 20 descriptors on LongBench v2 while the full procedure reports zero.
Significance. If the frequency-matched decoy distribution supplies a valid null for the maximum lift under multiple testing, the method supplies a practical safeguard that cleanly separates proposal of explanations from their reporting. The controlled experiment with a planted isolated failure and the explicit ablation on LongBench v2 (lift shrinking from 0.36 to 0.05 after hold-out) are concrete strengths that make the central claim falsifiable and reproducible in principle.
major comments (2)
- [§3] §3 (Janus procedure) and the controlled-experiment section: the central claim that the decoy floor supplies a valid null for the maximum lift rests on the assumption that random frequency-matched reassignment adequately approximates the tail of the maximum lift under the joint distribution of descriptor–error associations. When candidate descriptors are correlated (e.g., overlapping conditions such as “long input” and “multi-hop lookup”), the permutation distribution can underestimate the probability of large spurious lifts. The manuscript tests only an isolated planted failure; no experiment or theoretical argument is given that the calibration remains valid under realistic descriptor dependence. This assumption is load-bearing for the “beats decoy floor” confirmation rule.
- [Experiments on public benchmarks] Public-benchmark results (MuSiQue and LongBench v2): the claim that Janus confirms none of the SliceLine pockets is presented without quantitative error bars on the lift estimates, without the exact number of descriptors tested, and without the precise definition of the discovery versus hold-out splits. These omissions prevent assessment of whether the zero confirmations are robust or sensitive to split choice.
minor comments (2)
- [§3] Notation for the decoy floor and lift statistic is introduced without an explicit equation number; adding a displayed equation would improve traceability.
- [Ablations] The ablation paragraph on LongBench v2 reports a lift drop from 0.36 to 0.05 but does not state the number of descriptors that survived the decoy floor before the hold-out check.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (Janus procedure) and the controlled-experiment section: the central claim that the decoy floor supplies a valid null for the maximum lift rests on the assumption that random frequency-matched reassignment adequately approximates the tail of the maximum lift under the joint distribution of descriptor–error associations. When candidate descriptors are correlated (e.g., overlapping conditions such as “long input” and “multi-hop lookup”), the permutation distribution can underestimate the probability of large spurious lifts. The manuscript tests only an isolated planted failure; no experiment or theoretical argument is given that the calibration remains valid under realistic descriptor dependence. This assumption is load-bearing for the “beats decoy floor” confirmation rule.
Authors: We agree that descriptor dependence is a substantive concern for the permutation null. The controlled experiment plants an isolated failure with descriptors constructed to be independent. The public-benchmark experiments do not report pairwise or higher-order correlations among the SliceLine descriptors. The frequency-matched permutation controls marginals but does not guarantee control of the maximum-lift tail under arbitrary dependence. We will revise §3 and the discussion to state this assumption explicitly as a limitation and note that additional simulation studies with correlated descriptors would be needed for stronger validation. revision: yes
-
Referee: [Experiments on public benchmarks] Public-benchmark results (MuSiQue and LongBench v2): the claim that Janus confirms none of the SliceLine pockets is presented without quantitative error bars on the lift estimates, without the exact number of descriptors tested, and without the precise definition of the discovery versus hold-out splits. These omissions prevent assessment of whether the zero confirmations are robust or sensitive to split choice.
Authors: We will supply the omitted details in the revision. The revised text and appendix will state the exact number of descriptors evaluated on each benchmark, report bootstrap standard errors or confidence intervals on the lift estimates, and specify the discovery/hold-out split (including the randomization seed or stratification method). These quantities are recorded in our experimental pipeline and can be added without altering the reported conclusions. revision: yes
Circularity Check
No significant circularity; procedure uses independent random decoys and held-out replication
full rationale
The Janus confirmation rule (beat decoy floor on discovery data + replicate on held-out) is defined via external random frequency-matched reassignment and a separate data split. These are not derived from or fitted to the observed lifts; the null is generated independently rather than by construction from the real descriptor–error associations. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central claim therefore remains self-contained against external benchmarks and does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Randomly permuted decoy descriptors with preserved marginal frequencies constitute an appropriate null model for chance error associations.
- domain assumption The held-out evaluation set is statistically independent of the discovery set and representative of the same distribution.
Reference graph
Works this paper leans on
-
[1]
Controlling the False Discovery Rate via Knockoffs , journal =
Barber, Rina Foygel and Cand. Controlling the False Discovery Rate via Knockoffs , journal =
-
[2]
Panning for Gold: ‘Model-X’ Knockoffs for High Dimensional Controlled Variable Selection , journal =
Cand. Panning for Gold: ‘Model-X’ Knockoffs for High Dimensional Controlled Variable Selection , journal =. 2018 , month =
2018
-
[3]
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , urldate =
Yoav Benjamini and Yosef Hochberg , journal =. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , urldate =
-
[4]
IEEE Transactions on Knowledge and Data Engineering , volume=
Automated data slicing for model validation: A big data-ai integration approach , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2019 , publisher=
2019
-
[5]
Sagadeeva, Svetlana and Boehm, Matthias , title =. 2021 , isbn =. doi:10.1145/3448016.3457323 , booktitle =
-
[6]
Domino: Discovering Systematic Errors with Cross-Modal Embeddings , booktitle =
Eyuboglu, Sabri and Varma, Maya and Saab, Khaled and Delbrouck, Jean-Benoit and Lee-Messer, Christopher and Dunnmon, Jared and Zou, James and R. Domino: Discovering Systematic Errors with Cross-Modal Embeddings , booktitle =
-
[7]
and Leyton-Brown, Kevin , title =
d'Eon, Greg and d'Eon, Jason and Wright, James R. and Leyton-Brown, Kevin , title =. Proceedings of the ACM Conference on Fairness, Accountability, and Transparency , pages =
-
[8]
Advances in Neural Information Processing Systems , year =
Wang, Fulton and Adebayo, Julius and Tan, Sarah and Garcia-Olano, Diego and Kokhlikyan, Narine , title =. Advances in Neural Information Processing Systems , year =
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Yu, Han and Zou, Hao and Liu, Jiashuo and Xu, Renzhe and He, Yue and Zhang, Xingxuan and Cui, Peng , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[10]
and Visweswaran, Shyam and Batmanghelich, Kayhan , title =
Ghosh, Shantanu and Syed, Rayan and Wang, Chenyu and Choudhary, Vaibhav and Li, Binxu and Poynton, Clare B. and Visweswaran, Shyam and Batmanghelich, Kayhan , title =. Findings of the Association for Computational Linguistics: ACL , pages =
-
[11]
International Conference on Learning Representations , year =
Chen, Muxi and Zhao, Chenchen and Xu, Qiang , title =. International Conference on Learning Representations , year =
-
[12]
and Cand
Cherian, John J. and Cand. Statistical Inference for Fairness Auditing , journal =
-
[13]
Debelak, Rudolf , title =
-
[14]
and Saria, Suchi , title =
Subbaswamy, Adarsh and Sahiner, Berkman and Petrick, Nicholas and Pai, Vinay and Adams, Roy and Diamond, Matthew C. and Saria, Suchi , title =. npj Digital Medicine , volume =
-
[15]
and Gygi, Steven P
Elias, Joshua E. and Gygi, Steven P. , title =. Nature Methods , volume =
-
[16]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =
-
[17]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Ribeiro, Marco Tulio and Lundberg, Scott , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[18]
and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =. Transactions of the Association for Computational Linguistics , volume =
-
[19]
Transactions of the Association for Computational Linguistics , volume =
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , title =. Transactions of the Association for Computational Linguistics , volume =
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Bai, Yushi and Tu, Shangqing and Zhang, Jiajie and Peng, Hao and Wang, Xiaozhi and Lv, Xin and Cao, Shulin and Xu, Jiazheng and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[21]
ICLR Blogposts , year =
The 99\ author =. ICLR Blogposts , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.