SEF-CLGC at SemEval-2026 Task 11: Logical Notation Impact on Language Model Performance
Pith reviewed 2026-06-27 16:51 UTC · model grok-4.3
The pith
Small language models trained on natural and symbolic languages achieve 27.80% content score while reducing reasoning bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The experiments demonstrate that relying solely on small language models trained on a combination of natural and symbolic languages allows the best model to achieve a content score of 27.80% on SemEval-2026 Task 11 Subtask 1 while significantly lowering the content bias in reasoning.
What carries the argument
SEF-CLGC pipeline that integrates formal logical notations into small language model training and evaluation.
If this is right
- Small language models can reach measurable performance on content reasoning when trained with symbolic languages.
- Content bias decreases when models learn both natural language and formal notations.
- Reasoning evaluation can be performed without large language models by using this mixed training approach.
Where Pith is reading between the lines
- Similar training mixtures might improve performance on other logic or math benchmarks.
- If the bias reduction holds, it could help create more neutral reasoning systems for applications where content should not sway conclusions.
Load-bearing premise
The gains in score and bias reduction result from the natural-symbolic language combination and not from other aspects of model selection or tuning.
What would settle it
Running the same task with identical small language models but trained only on natural language and observing no change or worsening in content score and bias would challenge the claim.
Figures

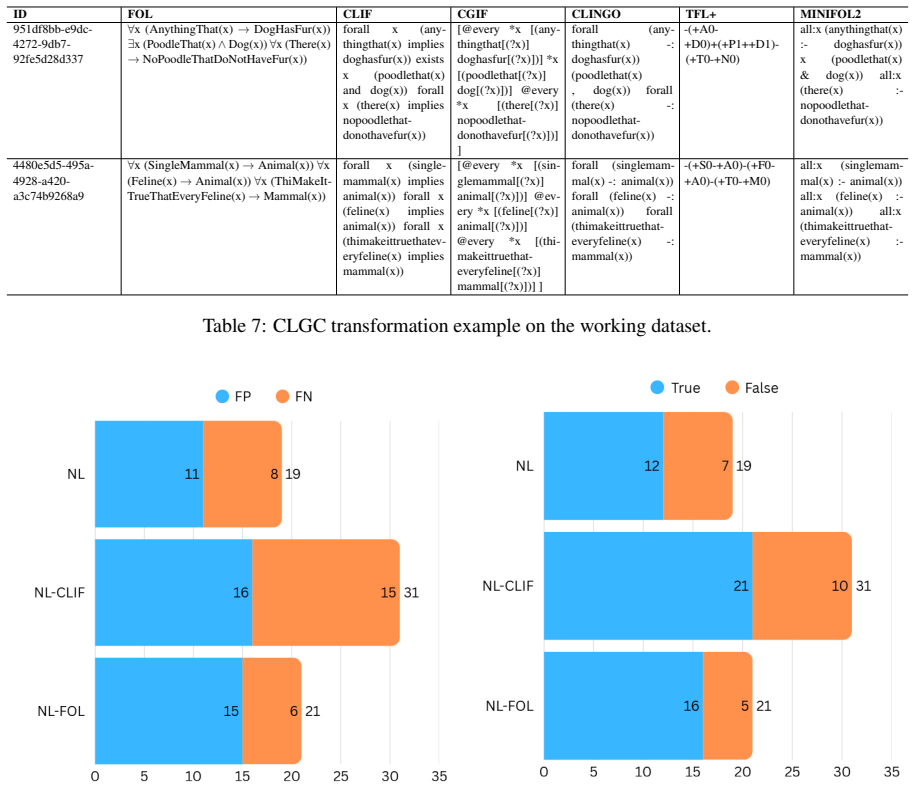
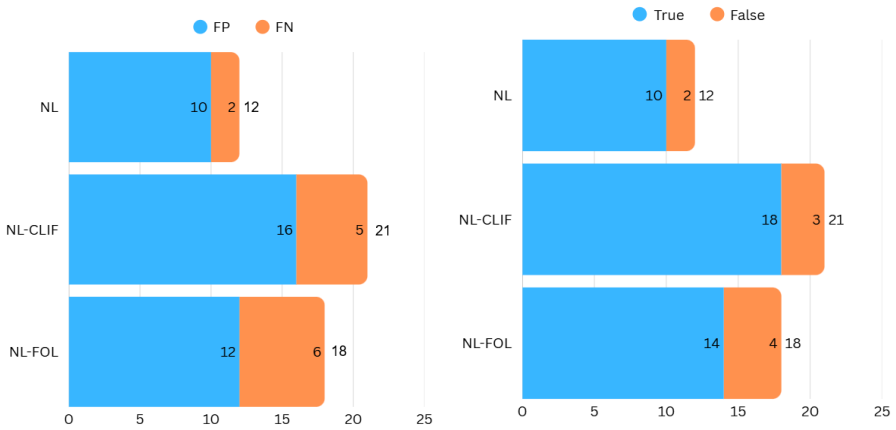
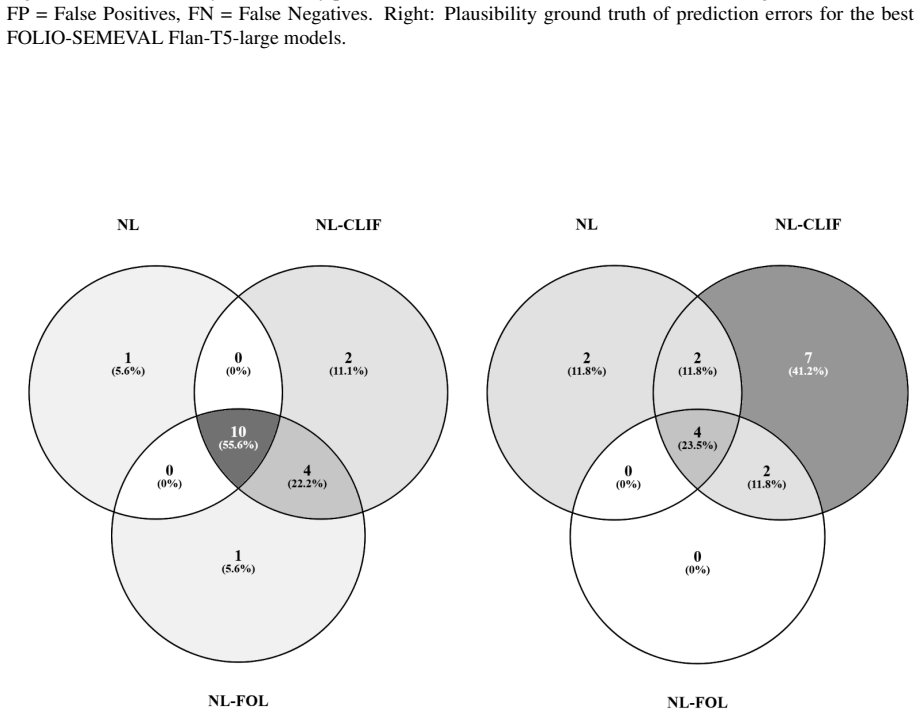

read the original abstract
This paper revisits our pipeline called Syllogistic Evaluation Framework-Common Logic Grammar Construction (SEF-CLGC). We combine formal logical notations with Small Language Models (SLMs) to evaluate reasoning performance on the SemEval-2026 Task 11 Subtask 1: Disentangling Content and Formal Reasoning in Large Language Models. Our experiments show that by relying solely on SLMs, trained on a combination of natural and symbolic languages, our best model achieves a content score of 27.80% on the task while significantly lowering the content bias in reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the SEF-CLGC pipeline, which integrates formal logical notations with Small Language Models (SLMs) trained on a combination of natural and symbolic languages. It reports results on SemEval-2026 Task 11 Subtask 1, claiming that the best such model achieves a content score of 27.80% while significantly lowering content bias in reasoning.
Significance. If the reported score and bias reduction can be substantiated through controlled experiments, the work would provide evidence that symbolic language training in SLMs can help disentangle content and formal reasoning while mitigating bias. The focus on SLMs rather than larger models would be a practical contribution for efficiency in logical evaluation tasks.
major comments (2)
- [Abstract] Abstract: The manuscript states a content score of 27.80% and a qualitative claim of bias reduction but supplies no experimental details, model specifications, training data composition, baselines, statistical tests, or error analysis, so the central claim cannot be verified from the given text.
- [Abstract] Abstract: The attribution of the 27.80% score and bias reduction specifically to training on a combination of natural and symbolic languages is unsupported, as no ablation removing the symbolic component, no natural-language-only baseline, and no controls for model selection or tuning are described.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the concerns about the abstract's lack of detail and the attribution of results to the combined natural-symbolic training below. We will revise the abstract and add supporting experiments where needed to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states a content score of 27.80% and a qualitative claim of bias reduction but supplies no experimental details, model specifications, training data composition, baselines, statistical tests, or error analysis, so the central claim cannot be verified from the given text.
Authors: We agree that the abstract is overly concise and does not include sufficient experimental details for independent verification. The full manuscript describes the SLM architectures and training procedures in Section 3, the natural and symbolic data composition in Section 4, baselines in Section 5, and statistical tests plus error analysis in Section 6. We will expand the abstract to include the key model specifications, training data summary, baseline comparisons, and a brief note on the bias metrics and statistical significance. revision: yes
-
Referee: [Abstract] Abstract: The attribution of the 27.80% score and bias reduction specifically to training on a combination of natural and symbolic languages is unsupported, as no ablation removing the symbolic component, no natural-language-only baseline, and no controls for model selection or tuning are described.
Authors: The SEF-CLGC results are reported for the integrated pipeline using mixed natural and symbolic training. We acknowledge that an explicit ablation study would better isolate the contribution of the symbolic component. We will add a natural-language-only baseline comparison using the same SLM and task setup in the revised experiments section. Model selection criteria and hyperparameter controls are already detailed in Section 3.2 and will be cross-referenced more explicitly from the abstract and results. revision: yes
Circularity Check
No derivation chain; empirical competition report with no load-bearing predictions or self-definitional steps
full rationale
The paper is a report of experimental results on SemEval-2026 Task 11. It describes training SLMs on natural+symbolic data and reports an achieved content score of 27.80% on the shared-task test set. No equations, derivations, uniqueness theorems, or predictive claims are present that could reduce to inputs by construction. The result is an empirical measurement, not a derived quantity. Self-reference to the authors' prior pipeline is descriptive only and does not carry the central claim. Per the rules, this is the normal non-finding for an empirical paper without a derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , MONTH = Sep, KEYWORDS =
Akl, Hanna Abi , BOOKTITLE =. 2025 , MONTH = Sep, KEYWORDS =
2025
-
[2]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
A systematic analysis of large language models as soft reasoners: The case of syllogistic inferences , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[3]
arXiv preprint arXiv:2207.07051 , year=
Language models show human-like content effects on reasoning tasks , author=. arXiv preprint arXiv:2207.07051 , year=
-
[4]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
A systematic comparison of syllogistic reasoning in humans and language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[5]
arXiv preprint arXiv:1405.3694 , year=
Clingo= ASP+ control: Preliminary report , author=. arXiv preprint arXiv:1405.3694 , year=
-
[6]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Folio: Natural language reasoning with first-order logic , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[7]
arXiv preprint arXiv:2506.08669 , year=
Enhancing reasoning capabilities of small language models with blueprints and prompt template search , author=. arXiv preprint arXiv:2506.08669 , year=
-
[8]
arXiv preprint arXiv:2504.09923 , year=
Guiding reasoning in small language models with llm assistance , author=. arXiv preprint arXiv:2504.09923 , year=
-
[9]
Reasoning Circuits in Language Models: A Mechanistic Interpretation of Syllogistic Inference
Kim, Geonhee and Valentino, Marco and Freitas, Andre. Reasoning Circuits in Language Models: A Mechanistic Interpretation of Syllogistic Inference. Findings of the Association for Computational Linguistics: ACL 2025. 2025
2025
-
[10]
Faithful Chain-of-Thought Reasoning
Lyu, Qing and Havaldar, Shreya and Stein, Adam and Zhang, Li and Rao, Delip and Wong, Eric and Apidianaki, Marianna and Callison-Burch, Chris. Faithful Chain-of-Thought Reasoning. Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Lin...
2023
-
[11]
arXiv preprint arXiv:2602.02462 , year=
Abstract Activation Spaces for Content-Invariant Reasoning in Large Language Models , author=. arXiv preprint arXiv:2602.02462 , year=
-
[12]
arXiv preprint arXiv:2601.07790 , year=
Benchmarking Small Language Models and Small Reasoning Language Models on System Log Severity Classification , author=. arXiv preprint arXiv:2601.07790 , year=
-
[13]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Exploring reasoning biases in large language models through syllogism: Insights from the NeuBAROCO dataset , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[14]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Verification and refinement of natural language explanations through LLM-symbolic theorem proving , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improving chain-of-thought reasoning via quasi-symbolic abstractions , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Evaluating the deductive competence of large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[17]
arXiv preprint arXiv:2502.11569 , year=
Towards reasoning ability of small language models , author=. arXiv preprint arXiv:2502.11569 , year=
-
[18]
arXiv preprint arXiv:2505.12189 , year =
Mitigating Content Effects on Reasoning in Language Models through Fine-Grained Activation Steering , author =. arXiv preprint arXiv:2505.12189 , year =
-
[19]
SemEval-2026 Task 11: Disentangling Content and Formal Reasoning in Large Language Models
Valentino, Marco and Ranaldi, Leonardo and Pucci, Giulia and Ranaldi, Federico and Freitas, Andr. SemEval-2026 Task 11: Disentangling Content and Formal Reasoning in Large Language Models. Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026). 2026
2026
-
[20]
arXiv preprint arXiv:2510.05077 , year=
Slm-mux: Orchestrating small language models for reasoning , author=. arXiv preprint arXiv:2510.05077 , year=
-
[21]
SylloBio-NLI: Evaluating large language models on biomedical syllogistic reasoning , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[22]
Faithful Logical Reasoning via Symbolic Chain-of-Thought
Xu, Jundong and Fei, Hao and Pan, Liangming and Liu, Qian and Lee, Mong-Li and Hsu, Wynne. Faithful Logical Reasoning via Symbolic Chain-of-Thought. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[23]
arXiv e-prints , pages=
A Technical Study into Small Reasoning Language Models , author=. arXiv e-prints , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.