Reasoning without Gold Standards: A Proxy-Judge Theory of Autoformalization
Pith reviewed 2026-06-27 16:42 UTC · model grok-4.3
The pith
A vector of per-axis proxy checks replaces gold standards for autoformalization by driving targeted refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
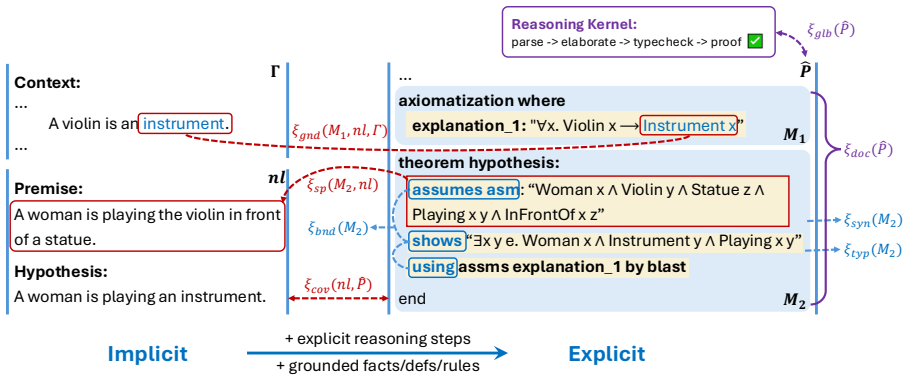
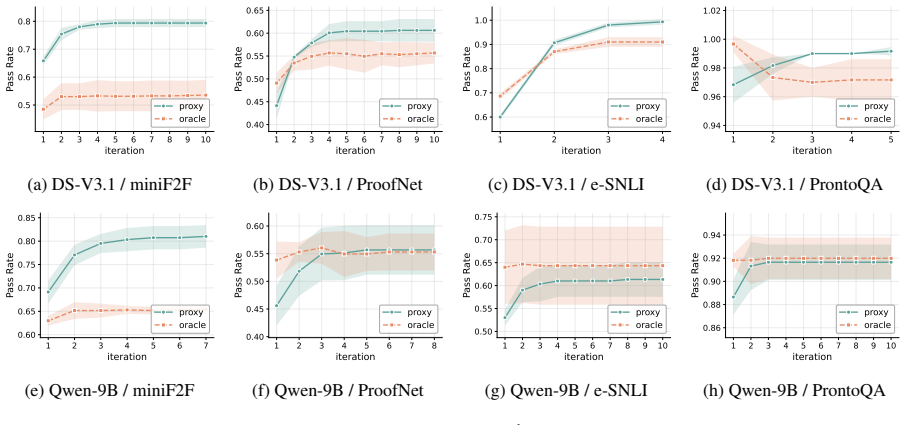
The framework replaces gold-standard matching with a vector of per-axis property checks organized along global, per-module, and cross-domain scopes. This vector aggregates into a verdict that drives a reflective refinement loop, where each iteration addresses only judged violations. Under bounded judge noise the intrinsic gap contracts geometrically to a noise-dependent plateau, and the approach yields higher pass rates than single-shot baselines while the per-axis version beats matched scalar proxies on benchmarks with headroom.
What carries the argument
The verdict vector from per-axis proxy checks that routes the reflective refinement loop to specific repair targets.
If this is right
- Refinement consistently increases pass rate over the single-shot ICL baseline on miniF2F, ProofNet, e-SNLI, and ProntoQA.
- The per-axis proxy outperforms a matched scalar proxy on benchmarks where the baseline leaves room for improvement.
- The expected intrinsic gap contracts geometrically to a noise-dependent plateau under bounded judge noise.
- Structured proxy judgments supply both a practical refinement signal and a theoretical convergence handle when exact references are unavailable.
Where Pith is reading between the lines
- Similar per-axis proxy methods could extend to other open-ended reasoning tasks that lack unique correct outputs, such as code generation or proof synthesis.
- The geometric contraction result suggests that increasing the number of axes or reducing judge noise could further tighten the plateau.
- Testing the framework on larger-scale formalization datasets would reveal whether the convergence behavior holds beyond the current benchmarks.
Load-bearing premise
The per-axis proxy checks provide a sufficiently complete and unbiased signal so that the reflective refinement loop corrects errors without systematic blind spots or amplifying judge mistakes.
What would settle it
Observing that refinement fails to improve or degrades performance on a benchmark where errors fall outside the three structural scopes covered by the proxy checks would falsify the claim that the framework reliably substitutes for gold standards.
Figures

read the original abstract
Complex reasoning tasks increasingly require systems to produce outputs whose correctness cannot be judged by exact match against a single reference. Autoformalization (AF) is a representative example; it asks a model to translate informal mathematical or logical reasoning into a formally checkable object, yet expert-validated formalizations do not scale beyond toy cases and a single informal argument can admit many valid formal renderings. Progress therefore depends on whether partial, structured proxies can substitute for exact references. We introduce a reference-free proxy-judge framework for AF that replaces gold-standard matching with a vector of per-axis property checks. The framework organizes the proxy along three structural scopes that cover global properties of the elicited object, per-module properties internal to its sub-components, and cross-domain properties that re-align it to the informal source, and aggregates each axis into a verdict vector. The vector drives a reflective refinement loop in which a violated coordinate routes the controller to a matching repair target, so each iteration changes only what is judged wrong. Under bounded judge noise, the expected intrinsic gap contracts geometrically to a noise-dependent plateau. Across seven formalization backbones on miniF2F, ProofNet, e-SNLI, and ProntoQA, refinement consistently lifts Pass Rate over the single-shot ICL baseline, and the per-axis proxy outperforms a matched scalar proxy on benchmarks where the baseline has room to improve. Structured proxy judgments therefore provide both a practical refinement signal and a theoretical handle on convergence when exact references are unavailable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a reference-free proxy-judge framework for autoformalization that organizes proxy checks along three structural scopes (global properties, per-module properties, and cross-domain properties) into a verdict vector. This vector drives a reflective refinement loop that targets repairs to violated coordinates. The central theoretical claim is that under bounded judge noise the expected intrinsic gap contracts geometrically to a noise-dependent plateau. Empirical results across seven formalization backbones on miniF2F, ProofNet, e-SNLI, and ProntoQA show that refinement lifts pass rate over single-shot ICL and that the per-axis proxy outperforms a matched scalar proxy on benchmarks with room for improvement.
Significance. If the geometric contraction result holds and the proxy scopes prove exhaustive, the framework supplies both a practical refinement mechanism and a theoretical account of convergence for tasks lacking scalable gold standards. The multi-benchmark empirical demonstration of consistent gains over baselines adds practical utility for autoformalization and related reference-free reasoning settings.
major comments (2)
- [Abstract / framework description paragraph] Abstract and framework description: the geometric contraction claim requires that every possible deviation from a correct formal object triggers at least one of the three axes (global, per-module, cross-domain), yet no coverage argument, completeness proof, or counter-example enumeration is supplied to establish that the chosen scopes are exhaustive for the space of autoformalization mistakes. This assumption is load-bearing for the contraction factor being strictly less than 1 on every iteration.
- [Abstract] Abstract: the geometric contraction result is asserted without visible derivation steps, an explicit noise model, or the precise definition of the intrinsic gap, so it is unclear whether the rate is independently derived or shaped by the internal formalization of gap and noise within the framework.
minor comments (1)
- [Abstract] The abstract states results on 'seven formalization backbones' but does not name them or report controls, statistical details, or exclusion criteria, which would aid verification even if full experimental sections exist.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / framework description paragraph] Abstract and framework description: the geometric contraction claim requires that every possible deviation from a correct formal object triggers at least one of the three axes (global, per-module, cross-domain), yet no coverage argument, completeness proof, or counter-example enumeration is supplied to establish that the chosen scopes are exhaustive for the space of autoformalization mistakes. This assumption is load-bearing for the contraction factor being strictly less than 1 on every iteration.
Authors: We agree that exhaustiveness of the three scopes is a load-bearing assumption for guaranteeing a contraction factor strictly below 1 on every iteration. The scopes were selected to align with the natural decomposition of formal objects (global invariants, internal module correctness, and source alignment), and our empirical error analysis on the benchmarks indicates that nearly all observed failures are captured by at least one axis. However, the manuscript does not supply a formal coverage argument or exhaustive counter-example enumeration. In revision we will add a dedicated subsection that (a) motivates the scopes via a taxonomy of common autoformalization error classes, (b) discusses plausible uncovered edge cases, and (c) reports the fraction of benchmark errors that trigger multiple axes, thereby making the assumption explicit and falsifiable even if a complete proof is not feasible for the open-ended formalization space. revision: yes
-
Referee: [Abstract] Abstract: the geometric contraction result is asserted without visible derivation steps, an explicit noise model, or the precise definition of the intrinsic gap, so it is unclear whether the rate is independently derived or shaped by the internal formalization of gap and noise within the framework.
Authors: The abstract summarizes the main theoretical result; the full derivation appears in Section 3. There we define the intrinsic gap as the minimum distance (under a property-vector metric) to any correct formal object, introduce the bounded per-axis noise model (each judge errs independently with probability at most ε), and derive the contraction E[G_{t+1}] ≤ ρ E[G_t] + O(ε) with ρ < 1 when the probability of detecting a violated axis exceeds a noise-dependent threshold. We will revise the abstract to include a brief parenthetical pointer to Section 3 and will add an explicit one-paragraph recap of the noise model and gap definition at the end of the introduction for readers who encounter the claim first in the abstract. revision: partial
Circularity Check
No circularity; derivation relies on external bounded-noise assumption rather than self-definition
full rationale
The abstract presents the geometric contraction of the expected intrinsic gap as following from the proxy framework under a bounded judge noise assumption, with the three axes (global, per-module, cross-domain) driving targeted repairs in the reflective loop. No equations are supplied that define the intrinsic gap directly in terms of proxy violations such that contraction holds by construction, nor is there any self-citation invoked to establish uniqueness or exhaustiveness of the axes. The completeness of the three scopes is stated as an organizing principle of the framework but is not shown to reduce the contraction claim to a tautology; the empirical lifts on Pass Rate across backbones supply an independent check. The derivation therefore remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Judge noise is bounded
invented entities (1)
-
proxy-judge framework with three structural scopes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year =
Autoformalization with Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[2]
arXiv preprint arXiv:2009.03393 , year =
Generative Language Modeling for Automated Theorem Proving , author =. arXiv preprint arXiv:2009.03393 , year =
Pith/arXiv arXiv 2009
-
[3]
2022 , url =
Zheng, Kunhao and Han, Jesse Michael and Polu, Stanislas , booktitle =. 2022 , url =
2022
-
[4]
Proceedings of the 36th International Conference on Machine Learning (ICML) , series =
Learning to Prove Theorems via Interacting with Proof Assistants , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , series =. 2019 , url =
2019
-
[5]
and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , booktitle =
Yang, Kaiyu and Swope, Aidan M. and Gu, Alex and Chalamala, Rahul and Song, Peiyang and Yu, Shixing and Godil, Saad and Prenger, Ryan and Anandkumar, Anima , booktitle =. 2023 , url =
2023
-
[6]
Advances in Neural Information Processing Systems , year =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[7]
Advances in Neural Information Processing Systems , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , year =
-
[8]
Advances in Neural Information Processing Systems , year =
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[9]
Advances in Neural Information Processing Systems , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , year =
-
[10]
arXiv preprint arXiv:2212.08073 , year =
Constitutional AI: Harmlessness from AI Feedback , author =. arXiv preprint arXiv:2212.08073 , year =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
arXiv preprint arXiv:2211.14275 , year =
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. arXiv preprint arXiv:2211.14275 , year =
-
[13]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
International Conference on Learning Representations (ICLR) , year =
Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs , author =. International Conference on Learning Representations (ICLR) , year =
-
[15]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[16]
arXiv preprint arXiv:2302.12433 , year =
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics , author =. arXiv preprint arXiv:2302.12433 , year =
-
[17]
Beyond Gold Standards: Epistemic Ensemble of
Zhang, Lan and Valentino, Marco and Freitas, Andr\'e , journal =. Beyond Gold Standards: Epistemic Ensemble of. 2025 , url =
2025
-
[18]
SIAM Review , volume =
Optimization Methods for Large-Scale Machine Learning , author =. SIAM Review , volume =
-
[19]
Markov Chains and Stochastic Stability , author =
-
[20]
Neuro-Dynamic Programming , author =
-
[21]
Camburu, Oana-Maria and Rockt. e-. Advances in Neural Information Processing Systems , volume =
-
[22]
International Conference on Learning Representations (ICLR) , year =
Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought , author =. International Conference on Learning Representations (ICLR) , year =
-
[23]
Do Natural Language Explanations Represent Valid Logical Arguments? Verifying Entailment in Explainable
Valentino, Marco and Pratt-Hartmann, Ian and Freitas, Andr. Do Natural Language Explanations Represent Valid Logical Arguments? Verifying Entailment in Explainable. Proceedings of the 14th International Conference on Computational Semantics (IWCS) , pages =. 2021 , url =
2021
-
[24]
arXiv preprint arXiv:2601.23166 , year =
Monotonic Reference-Free Refinement for Autoformalization , author =. arXiv preprint arXiv:2601.23166 , year =
-
[25]
Quan, Xin and Valentino, Marco and Dennis, Louise A. and Freitas, Andr. Faithful and Robust. arXiv preprint arXiv:2505.24264 , year =
-
[26]
Dantas, Pierre and Cordeiro, Lucas and Sun, Youcheng and Junior, Waldir , journal =. The. 2025 , url =
2025
-
[27]
de Moura, Leonardo and Ullrich, Sebastian , editor =. The. Automated Deduction -- CADE 28 , pages =. 2021 , publisher =
2021
-
[28]
and Wenzel, Markus , series =
Nipkow, Tobias and Paulson, Lawrence C. and Wenzel, Markus , series =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.