ReCoVLA: VLM-Guided Reward Compilation for Failure Recovery in Vision-Language-Action Policies
Pith reviewed 2026-06-27 16:40 UTC · model grok-4.3
The pith
ReCoVLA keeps a pretrained vision-language-action policy frozen and uses a VLM to compile rewards that train residual recovery policies in simulation for zero-shot real-robot deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
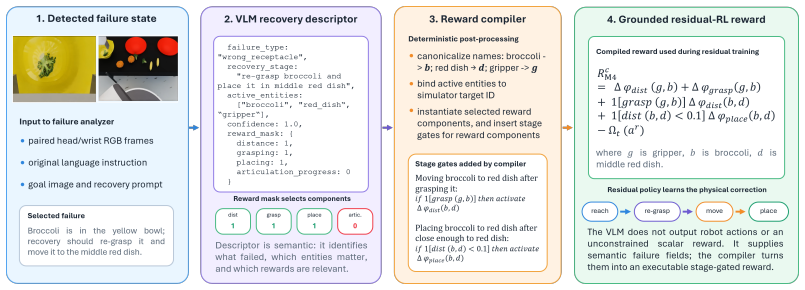
ReCoVLA is a failure-conditioned residual recovery framework that keeps a pretrained VLA policy frozen, uses an external VLM to infer failure mode and recovery stage from visual input, compiles a structured reward mask from task-relevant components, trains a residual policy on that mask inside simulation, and deploys the trained recovery policy zero-shot on real hardware.
What carries the argument
The VLM acting as a semantic reward selector that outputs a recovery descriptor and reward mask to drive in-simulation residual-policy training.
If this is right
- Different base VLAs can be paired with the same recovery module because high-level failure reasoning is decoupled from low-level corrective control.
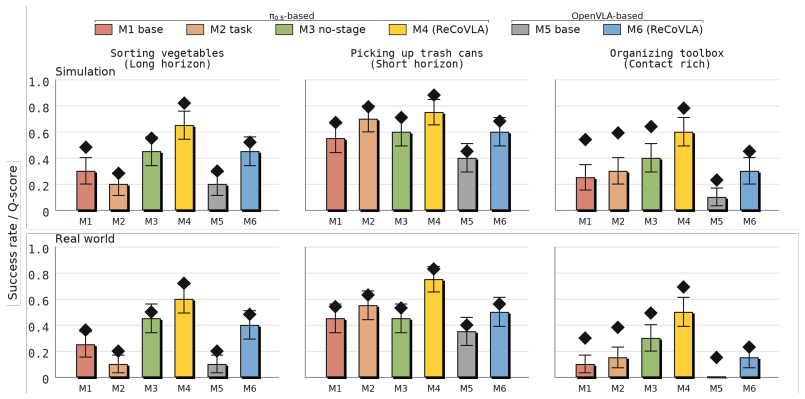
- Residual policies trained on VLM-compiled rewards outperform direct fine-tuning of the base policy on the reported manipulation tasks.
- Zero-shot sim-to-real transfer succeeds for the recovery policies across short-horizon, long-horizon, and contact-rich tasks.
- Average task success improves from 36.7 percent to 66.7 percent in simulation and reaches 61.7 percent in physical experiments.
Where Pith is reading between the lines
- The same VLM-selector approach could be tested on failure modes outside the current task set to check whether the reward-compilation step generalizes without new engineering.
- Replacing the VLM with a lighter or domain-specific model would reveal how much inference accuracy is required for the residual policies to retain their reported performance edge.
- The framework suggests a modular path for extending existing VLAs to new environments by adding only the recovery layer rather than retraining the entire policy stack.
Load-bearing premise
The VLM can correctly infer the failure mode and recovery stage from visual input so that the compiled reward mask produces a residual policy whose simulation training transfers without adaptation to real hardware.
What would settle it
A set of trials in which the VLM misclassifies the failure type, yielding reward masks that produce residual policies whose success rate on the same tasks falls to or below the fine-tuned baseline level.
Figures




read the original abstract
Vision-language-action (VLA) policies provide strong priors for language-conditioned manipulation, but remain brittle in off-nominal states requiring targeted recovery. We propose ReCoVLA -- a failure-conditioned residual recovery framework that keeps a pretrained VLA policy frozen, uses an external vision-language model (VLM) to infer the failure mode and recovery stage, and compiles a structured reward from task-relevant components. Rather than using the VLM to generate actions or rewards directly, ReCoVLA uses it as a semantic reward selector: it predicts a recovery descriptor and reward mask for in-simulation residual-policy training, followed by zero-shot sim-to-real deployment of the trained recovery policies. This decouples high-level failure understanding from low-level corrective control to support different VLAs. Experiments across short-horizon, long-horizon, and contact-rich manipulation tasks show that ReCoVLA outperforms the tested baselines on average. In simulation, our reward compiler improves average success from 36.7% for the fine-tuned $\pi_{0.5}$ baseline to 66.7%. In physical zero-shot sim-to-real experiments, ReCoVLA achieves the best average performance, with 61.7% success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReCoVLA, a failure-conditioned residual recovery framework for vision-language-action (VLA) policies. A pretrained VLA is kept frozen while an external VLM infers the failure mode and recovery stage from visual input; this information is used to compile a structured reward mask consisting of task-relevant components. A residual policy is then trained in simulation using the compiled reward and deployed zero-shot to real hardware. Experiments on short-horizon, long-horizon, and contact-rich manipulation tasks report that the approach raises average success from 36.7% (fine-tuned π0.5 baseline) to 66.7% in simulation and achieves 61.7% success in physical zero-shot sim-to-real trials, outperforming tested baselines on average.
Significance. If the reported gains are reproducible, the work supplies a modular mechanism that separates high-level semantic failure diagnosis (via VLM) from low-level corrective control (via residual policy), allowing the same recovery module to be attached to different base VLAs. The explicit use of the VLM only as a reward selector rather than an action generator, together with the structured reward compilation step, is a concrete technical contribution that could improve robustness in off-nominal states without full policy retraining.
major comments (3)
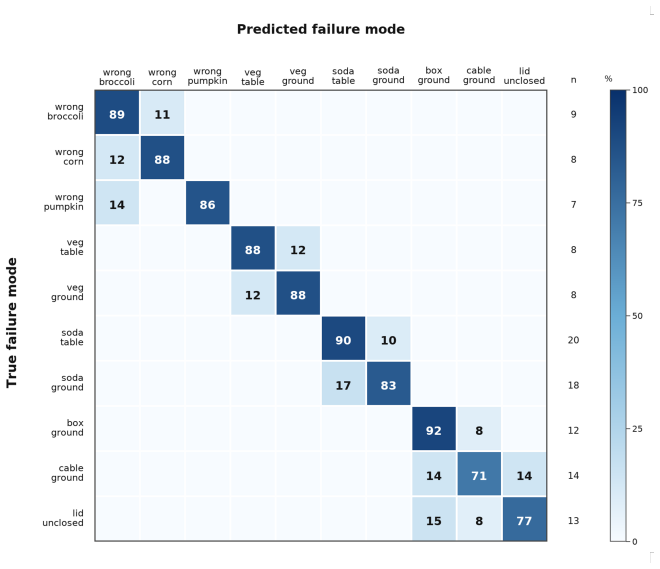
- [Experiments] Experiments section: the central performance claims (36.7 % → 66.7 % simulation, 61.7 % real) are presented without any reported VLM inference accuracy, confusion matrix, or per-failure-mode error analysis. Because the reward mask is generated directly from the VLM output, the absence of these metrics leaves the attribution of the observed gains to the proposed method unverified.
- [Physical experiments] Physical experiments subsection: the zero-shot sim-to-real transfer result is stated without any quantification of the sim-to-real gap for the same residual policies or any breakdown of real-world failure modes. This gap measurement is load-bearing for the claim that simulation-trained recovery policies transfer without adaptation.
- [Method] Method (reward compilation paragraph): the paper states that the VLM predicts a “recovery descriptor and reward mask,” yet supplies no formal definition or pseudocode for how the mask is constructed from the descriptor or how it is combined with the base task reward. Without this, it is impossible to assess whether the reported improvement reduces to the mask construction or to other unstated factors.
minor comments (1)
- [Abstract] Abstract: the numerical results are given to one decimal place but no trial count, number of tasks, or variance is supplied, which would help readers interpret the magnitude of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central performance claims (36.7 % → 66.7 % simulation, 61.7 % real) are presented without any reported VLM inference accuracy, confusion matrix, or per-failure-mode error analysis. Because the reward mask is generated directly from the VLM output, the absence of these metrics leaves the attribution of the observed gains to the proposed method unverified.
Authors: We agree that VLM inference metrics are needed to support attribution of the gains. The revised manuscript will report VLM accuracy on failure-mode and recovery-stage prediction, a confusion matrix, and per-failure-mode success rates drawn from our existing experimental logs. revision: yes
-
Referee: [Physical experiments] Physical experiments subsection: the zero-shot sim-to-real transfer result is stated without any quantification of the sim-to-real gap for the same residual policies or any breakdown of real-world failure modes. This gap measurement is load-bearing for the claim that simulation-trained recovery policies transfer without adaptation.
Authors: We acknowledge the value of explicit gap quantification. While paired sim/real metrics for the residual policies were not collected, the revised version will add a breakdown of observed real-world failure modes. The reported zero-shot success rate remains the primary evidence of transfer; additional gap measurements would require new experiments beyond the current scope. revision: partial
-
Referee: [Method] Method (reward compilation paragraph): the paper states that the VLM predicts a “recovery descriptor and reward mask,” yet supplies no formal definition or pseudocode for how the mask is constructed from the descriptor or how it is combined with the base task reward. Without this, it is impossible to assess whether the reported improvement reduces to the mask construction or to other unstated factors.
Authors: We thank the referee for noting this omission. The revised manuscript will include a formal definition of the reward mask, the mapping from recovery descriptor to mask components, and pseudocode showing how the compiled mask is combined with the base task reward. revision: yes
Circularity Check
No circularity in derivation or performance claims
full rationale
The provided abstract and method description contain no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the reported success rates (36.7% to 66.7% sim; 61.7% real) to inputs by construction. The VLM reward mask and residual policy training are treated as external components whose outputs are evaluated empirically; no self-definitional loop or ansatz smuggling is present in the text. This is a standard empirical robotics paper whose central claims rest on measured transfer performance rather than algebraic identity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[3]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635, 2011
2011
-
[4]
Y . Dai, J. Lee, N. Fazeli, and J. Chai. RACER: Rich language-guided failure recovery policies for imitation learning. InIEEE International Conference on Robotics and Automation, 2025
2025
-
[5]
S. Pan, Y . Xu, R. Xu, Z. Zhou, S. Wu, and Z. Yu. Self-correcting robot manipulation via gaussian-splatted foresight. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[6]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations, 2022
2022
-
[7]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. de Laroussilhe, A. Gesmundo, M. At- tariyan, and S. Gelly. Parameter-efficient transfer learning for NLP. InInternational Confer- ence on Machine Learning, pages 2790–2799, 2019
2019
-
[8]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the Na- tional Academy of Sciences, 114(13):3521–3526, 2017
2017
-
[9]
Andrychowicz, F
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, and W. Zaremba. Hindsight experience replay. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[10]
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete prob- lems in AI safety.arXiv preprint arXiv:1606.06565, 2016
Pith/arXiv arXiv 2016
-
[11]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[12]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: Robot manipulation with multimodal prompts. InInternational Conference on Machine Learning, pages 14975–15022. PMLR, 2023
2023
-
[13]
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[14]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. 9
Pith/arXiv arXiv 2022
-
[15]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[16]
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, et al. RoboCat: A self-improving generalist agent for robotic manipulation.Transactions on Machine Learning Research, 2024. URLhttps://arxiv.org/abs/2306.11706
arXiv 2024
-
[17]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[18]
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wu, C. Cheang, Y . Jing, W. Zhang, H. Liu, et al. Vision-language foundation models as effective robot imitators. InInternational Conference on Learning Representations, volume 2024, pages 26703–26721, 2024
2024
-
[19]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, volume 2024, pages 10641–10662, 2024
2024
-
[20]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. URLhttps://arxiv.org/ abs/2405.12213
Pith/arXiv arXiv 2024
-
[21]
P. An, Y . Guo, X. Li, J. Liu, M. Liu, Z. Wang, et al. RoboMamba: Efficient vision-language- action model for robotic reasoning and manipulation.Advances in Neural Information Pro- cessing Systems, 2024
2024
-
[22]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[23]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, et al. SpatialVLA: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025. URLhttps://arxiv.org/abs/2501.15830
Pith/arXiv arXiv 2025
-
[24]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. TinyVLA: Towards fast, data-efficient vision-language-action models for robotic manipula- tion.IEEE Robotics and Automation Letters, 2025
2025
-
[25]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[26]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. In2019 international conference on robotics and automation (ICRA), pages 6023–6029. IEEE, 2019
2019
-
[27]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Pith/arXiv arXiv 2018
-
[28]
C. Xu, J. T. Springenberg, M. Equi, A. Amin, A. Esmail, S. Levine, and L. Ke. RL token: Boot- strapping online RL with vision-language-action models.arXiv preprint arXiv:2604.23073, 2026
Pith/arXiv arXiv 2026
-
[29]
Ranjbar, N
A. Ranjbar, N. A. Vien, H. Ziesche, J. Boedecker, and G. Neumann. Residual feedback learning for contact-rich manipulation tasks with uncertainty. In2021 IEEE/RSJ International confer- ence on intelligent robots and systems (IROS), pages 2383–2390. IEEE, 2021. 10
2021
-
[30]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation. InEuropean Conference on Computer Vision, pages 306–324. Springer, 2024
2024
-
[31]
Ankile, A
L. Ankile, A. Simeonov, I. Shenfeld, M. Torne, and P. Agrawal. From imitation to refinement- residual RL for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–08. IEEE, 2025
2025
-
[32]
Pertsch, Y
K. Pertsch, Y . Lee, and J. Lim. Accelerating reinforcement learning with learned skill priors. InConference on robot learning, pages 188–204. PMLR, 2021
2021
-
[33]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[34]
J. Luo, Z. Hu, C. Xu, Y . L. Tan, J. Berg, A. Sharma, S. Schaal, C. Finn, A. Gupta, and S. Levine. SERL: A software suite for sample-efficient robotic reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16961–16969. IEEE, 2024
2024
-
[35]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[36]
Z. Zhou, A. Peng, Q. Li, S. Levine, and A. Kumar. Efficient online reinforcement learning fine- tuning need not retain offline data. InInternational Conference on Learning Representations, volume 2025, pages 32343–32368, 2025
2025
-
[37]
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. InInternational Conference on Learning Representations, volume 2025, pages 77288–77329, 2025
2025
-
[38]
H. Jiang and Z. Yang. Adaptive diffusion policy optimization for robotic manipulation.arXiv preprint arXiv:2505.08376, 2025
arXiv 2025
-
[39]
X. Yuan, T. Mu, S. Tao, Y . Fang, M. Zhang, and H. Su. Policy decorator: Model-agnostic online refinement for large policy model.arXiv preprint arXiv:2412.13630, 2024. doi:10. 48550/arXiv.2412.13630. URLhttps://arxiv.org/abs/2412.13630
arXiv 2024
-
[40]
Z. Song, G. Ouyang, M. Li, Y . Ji, C. Wang, Z. Xu, Z. Zhang, X. Zhang, Q. Jiang, F. Ji, et al. ManipLVM-R1: Reinforcement learning for reasoning in embodied manipulation with large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18558–18566, 2026
2026
-
[41]
Cully, J
A. Cully, J. Clune, D. Tarapore, and J.-B. Mouret. Robots that can adapt like animals.Nature, 521(7553):503–507, 2015
2015
-
[42]
Thananjeyan, A
B. Thananjeyan, A. Balakrishna, S. Nair, M. Luo, K. Srinivasan, M. Hwang, J. E. Gonzalez, J. Ibarz, C. Finn, and K. Goldberg. Recovery RL: Safe reinforcement learning with learned recovery zones.IEEE Robotics and Automation Letters, 6(3):4915–4922, 2021
2021
-
[43]
Y . Dai, J. Lee, N. Fazeli, and J. Chai. Racer: Rich language-guided failure recovery policies for imitation learning.arXiv preprint arXiv:2409.14674, 2024
arXiv 2024
-
[44]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models.arXiv preprint arXiv:2510.01642, 2025
arXiv 2025
-
[45]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 11
Pith/arXiv arXiv 2017
-
[46]
C. Yu, Y . Wang, Z. Guo, H. Lin, S. Xu, H. Zang, Q. Zhang, Y . Wu, C. Zhu, J. Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transforma- tion.arXiv preprint arXiv:2509.15965, 2025
arXiv 2025
-
[47]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martín-Martín, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Ay- din, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon, C...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.