AutoMegaKernel: A Statically-Checked Agent Harness for Self-Retargeting Megakernel Synthesis
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
AMK compiles Hugging Face Llama models into a single CUDA kernel for the full forward pass in one launch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
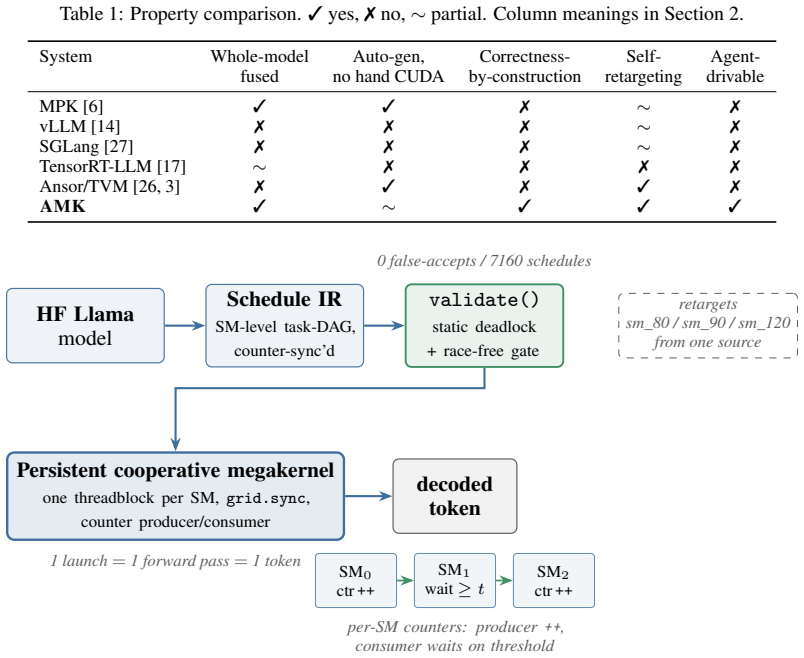
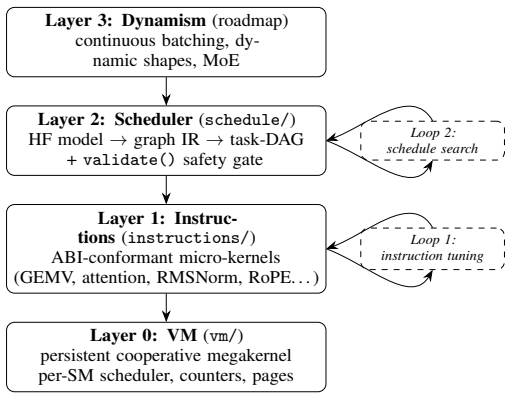
AutoMegaKernel compiles a HuggingFace Llama-family model into a single persistent cooperative CUDA kernel that runs the whole forward pass in one launch, with no per-model hand-written CUDA. A frozen schedule-IR validator statically certifies deadlock-freedom and race-freedom via static graph checks, so an unsafe agent-proposed schedule is rejected before launch.
What carries the argument
The frozen schedule-IR validator that performs static graph checks to certify deadlock-freedom and race-freedom of schedules.
If this is right
- The same codebase retargets to different compute capabilities like sm_80, sm_90, and sm_120.
- Correct megakernels are generated for all 10 supported models.
- The output matches HuggingFace greedy decode token-for-token with very low perplexity difference.
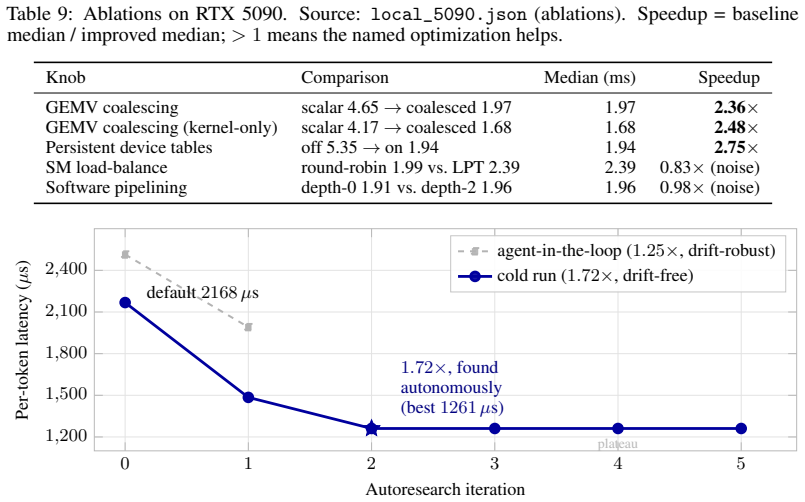
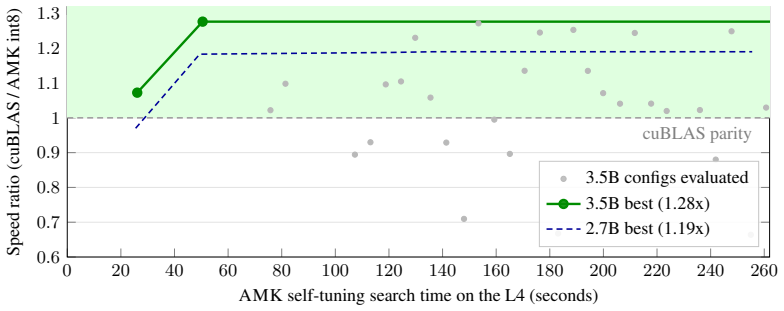
- An unattended agent loop can self-improve the megakernel performance 1.25-1.72x over baseline.
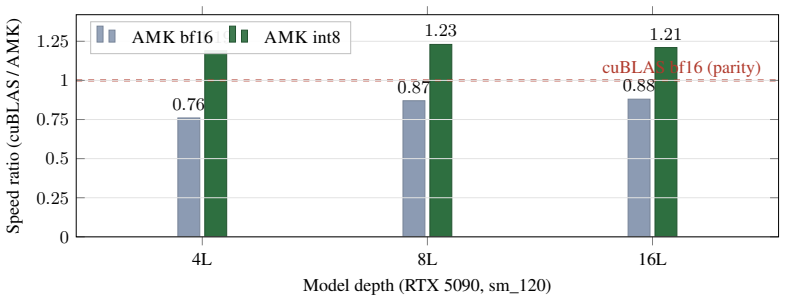
- An int8 megakernel outperforms graphed cuBLAS bf16 on several inference GPUs at batch size 1.
Where Pith is reading between the lines
- This suggests static analysis can safely enable automated synthesis of complex GPU kernels by agents.
- The performance variation across hardware points to differences between inference-optimized and training-optimized GPUs.
- The harness could potentially be adapted for other model families beyond Llama if the validator supports their operations.
Load-bearing premise
The static graph checks of the schedule-IR validator are sufficient to guarantee that accepted schedules will not have deadlocks or races.
What would settle it
A schedule that passes the validator but produces a deadlock or race condition during execution on the target GPU would show the certification is incomplete.
Figures
read the original abstract
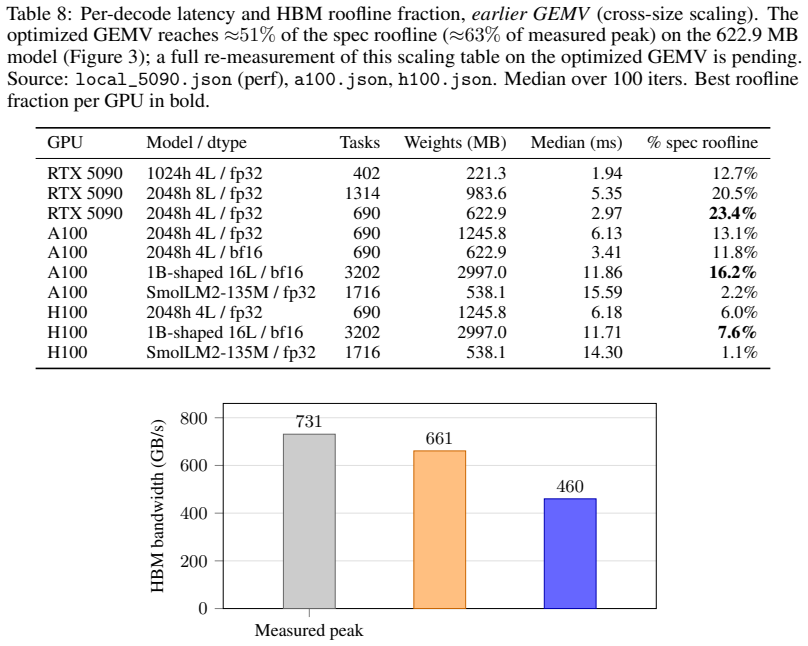
AutoMegaKernel (AMK) compiles a HuggingFace Llama-family model into a single persistent cooperative CUDA kernel that runs the whole forward pass in one launch, with no per-model hand-written CUDA. The contribution is the system, not raw speed. A frozen schedule-IR validator statically certifies deadlock-freedom and race-freedom via static graph checks (not a mechanized proof), so an unsafe agent-proposed schedule is rejected before launch: across 7,160 adversarial schedules (6,091 unsafe) it had zero false-accepts and accepted all 360 real lowerings. The same source retargets sm_80/sm_90/sm_120 from one codebase, auto-generates correct megakernels for 10 of 10 supported models, and on a real SmolLM2-135M checkpoint reproduces HuggingFace greedy decode token-for-token (perplexity match 2.5e-7). An unattended, agent-drivable autoresearch loop self-improves the megakernel over its own baseline (1.25-1.72x). A search-found int8 (W8A16) megakernel beats CUDA-graphed cuBLAS bf16 at batch-1 decode across NVIDIA's datacenter inference fleet: L4 up to 1.33x, the current-gen L40S 1.25-1.27x, A10G up to 1.08x at scale, and the consumer RTX 5090 1.19-1.23x. The ordering is not a clean function of bandwidth (the 864 GB/s L40S beats the 600 GB/s A10G); the divide is inference-class vs training-class. AMK trails cuBLAS on the high-bandwidth training-class A100/H100, where the harness localizes the cross-SM-sync bottleneck; we report the gap plainly. This is a precision-asymmetric (W8A16 vs bf16) comparison at decode position 0; the largest real checkpoint is TinyLlama-1.1B. Code and the harness: https://github.com/RightNow-AI/AutoMegaKernel
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoMegaKernel (AMK), a system that compiles HuggingFace Llama-family models into a single persistent cooperative CUDA kernel executing the full forward pass in one launch, without per-model hand-written CUDA. The core contribution is an agent-harness with a frozen schedule-IR validator that uses static graph checks to certify deadlock-freedom and race-freedom (zero false-accepts on 7,160 adversarial schedules including 6,091 unsafe ones, and acceptance of all 360 real lowerings). The same source retargets across sm_80/sm_90/sm_120, reproduces HF token-for-token outputs on SmolLM2-135M (perplexity match 2.5e-7), supports an autoresearch loop for self-improvement (1.25-1.72x), and reports precision-asymmetric (W8A16) speedups over CUDA-graphed cuBLAS bf16 on several inference GPUs while trailing on high-bandwidth training GPUs.
Significance. If the validator's static checks are complete for the schedule-IR, the work provides a practical, retargetable framework for safe automated megakernel synthesis that could reduce manual CUDA effort for inference kernels. Strengths include direct external baselines (cuBLAS, HF), empirical safety data on a large adversarial set, cross-architecture support from one codebase, and an agent-driven self-improvement loop. The explicit reporting of both gains and gaps (e.g., cross-SM sync bottleneck on A100/H100) is a positive.
major comments (1)
- [Abstract / validator description] Abstract and validator description: the central claim that the frozen schedule-IR validator 'statically certifies' deadlock-freedom and race-freedom for any agent-proposed schedule rests on static graph checks whose completeness is supported only by zero false-accepts on 7,160 schedules (6,091 unsafe). No mechanized proof, formal semantics of the schedule-IR, or exhaustive enumeration of interleavings is provided, leaving open the possibility that some unsafe schedule expressible in the IR passes the checks.
minor comments (2)
- [Performance evaluation] The performance section should clarify whether the reported speedups include the cost of the one-time compilation/validator run or are measured only at inference time.
- [Experimental results] Figure or table captions for the adversarial schedule results should explicitly state the breakdown (e.g., how many schedules were generated by each mutation type) to allow readers to assess coverage.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the focus on the validator's guarantees. The manuscript already qualifies the claim as relying on static graph checks rather than a mechanized proof; we address the concern about potential overstatement below.
read point-by-point responses
-
Referee: [Abstract / validator description] Abstract and validator description: the central claim that the frozen schedule-IR validator 'statically certifies' deadlock-freedom and race-freedom for any agent-proposed schedule rests on static graph checks whose completeness is supported only by zero false-accepts on 7,160 schedules (6,091 unsafe). No mechanized proof, formal semantics of the schedule-IR, or exhaustive enumeration of interleavings is provided, leaving open the possibility that some unsafe schedule expressible in the IR passes the checks.
Authors: We agree that the validator provides no mechanized proof or formal semantics of the schedule-IR, and that the empirical result (zero false-accepts on 7,160 schedules) does not by itself prove completeness for every possible schedule expressible in the IR. The manuscript text already states explicitly that the approach uses 'static graph checks (not a mechanized proof)'. The intended claim is narrower: that the implemented checks are designed to be sound for the deadlock and race conditions they target, and that this design has been validated on a large adversarial corpus that includes thousands of unsafe schedules. We will revise the abstract and the validator section to remove any phrasing that could be read as claiming formal certification or completeness beyond the static checks and their empirical support. This is a partial revision because we retain the empirical safety data as the primary evidence while clarifying the scope of the claim. revision: partial
- A mechanized proof or formal semantics of the schedule-IR is not available in the current work.
Circularity Check
No significant circularity; derivation is self-contained against external benchmarks
full rationale
The paper describes a systems artifact whose core claims (single-launch megakernel compilation, retargeting across GPU architectures, and static schedule validation) are supported by direct empirical comparisons to external baselines (cuBLAS, Hugging Face token-for-token match) and by testing on 7160 adversarial schedules. No equations, fitted parameters, or self-citations are present in the provided text that would reduce any reported result to a quantity defined by the authors' own prior work. The validator's soundness rests on static graph checks plus empirical zero false-accepts rather than a mechanized proof, but this is an acknowledged limitation in formal guarantee strength, not a circular reduction of the claim to its own inputs. The derivation chain therefore remains independent of self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static graph checks on the schedule-IR are sufficient to certify deadlock-freedom and race-freedom for all accepted schedules
Reference graph
Works this paper leans on
-
[1]
Ansel, E
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. V oznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, et al. PyTorch 2: Faster machine learning through dynamic Python bytecode transformation and graph compilation. InProc. 29th ACM Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2024
2024
-
[2]
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y . Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy. TVM: An automated end-to-end optimizing compiler for deep learning. InProc. 13th USENIX Symp. on Operating Systems Design and Implementation (OSDI), pages 578–594, 2018
2018
-
[4]
T. Chen, L. Zheng, E. Yan, Z. Jiang, T. Moreau, L. Ceze, C. Guestrin, and A. Krishnamurthy. Learning to optimize tensor programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[5]
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
X. Cheng, Z. Zhang, Y . Zhou, J. Ji, J. Jiang, Z. Zhao, Z. Xiao, Z. Ye, Y . Huang, R. Lai, H. Jin, B. Hou, M. Wu, Y . Dong, A. Yip, S. Wang, W. Yang, X. Miao, T. Chen, and Z. Jia. Mirage Persistent Kernel: A compiler and runtime for mega-kernelizing tensor programs.arXiv preprint arXiv:2512.22219, 2025
-
[7]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. 16
2022
-
[8]
T. Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. InInt. Conf. on Learning Representations (ICLR), 2024. arXiv:2307.08691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
T. Dao, D. Haziza, F. Massa, and G. Sizov. Flash-Decoding for long-context inference. Stanford CRFM / PyTorch technical blog, 2023
2023
-
[10]
Y . Ding, C. H. Yu, B. Zheng, Y . Liu, Y . Wang, and G. Pekhimenko. Hidet: Task-mapping programming paradigm for deep learning tensor programs. InProc. 28th ACM Int. Conf. on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2023
2023
-
[11]
https://arxiv.org/abs/ 2408.11743
E. Frantar, R. L. Castro, J. Chen, T. Hoefler, and D. Alistarh. MARLIN: Mixed-precision auto-regressive parallel inference on large language models.arXiv preprint arXiv:2408.11743, 2024
-
[12]
A. Gray. Getting started with CUDA graphs. NVIDIA Technical Blog, 2019
2019
-
[13]
J. Jaber and O. Jaber. AutoKernel: Autonomous GPU kernel optimization via iterative agent- driven search.arXiv preprint arXiv:2603.21331, 2026
-
[14]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with PagedAttention. InProc. 29th ACM Symp. on Operating Systems Principles (SOSP), 2023
2023
-
[15]
Leviathan, M
Y . Leviathan, M. Kalman, and Y . Matias. Fast inference from transformers via speculative decoding. InProc. 40th Int. Conf. on Machine Learning (ICML), pages 19274–19286, 2023
2023
-
[16]
Y . Li, F. Wei, C. Zhang, and H. Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty. InProc. 41st Int. Conf. on Machine Learning (ICML), 2024. arXiv:2401.15077
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
TensorRT-LLM: A library for optimizing large language model inference
NVIDIA. TensorRT-LLM: A library for optimizing large language model inference. https: //github.com/NVIDIA/TensorRT-LLM, 2023
2023
-
[18]
cuBLAS Library
NVIDIA. cuBLAS Library. https://docs.nvidia.com/cuda/cublas/, NVIDIA, ac- cessed 2026
2026
-
[19]
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[20]
Y . Shi, Z. Yang, J. Xue, L. Ma, Y . Xia, Z. Miao, Y . Guo, F. Yang, and L. Zhou. Welder: Scheduling deep learning memory access via tile-graph. InProc. 17th USENIX Symp. on Operating Systems Design and Implementation (OSDI), 2023
2023
- [21]
-
[22]
Spector, J
B. Spector, J. Juravsky, S. Sul, O. Dugan, D. Lim, D. Y . Fu, S. Arora, and C. Ré. Look ma, no bubbles! Designing a low-latency megakernel for Llama-1B. Hazy Research blog, Stanford University, 2025
2025
-
[23]
Tillet, H
P. Tillet, H. T. Kung, and D. Cox. Triton: An intermediate language and compiler for tiled neural network computations. InProc. 3rd ACM SIGPLAN Int. Workshop on Machine Learning and Programming Languages (MAPL), 2019
2019
-
[24]
Williams, A
S. Williams, A. Waterman, and D. Patterson. Roofline: An insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[25]
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun. Orca: A distributed serving system for transformer-based generative models. InProc. 16th USENIX Symp. on Operating Systems Design and Implementation (OSDI), 2022
2022
-
[26]
Zheng, C
L. Zheng, C. Jia, M. Sun, Z. Wu, C. H. Yu, A. Haj-Ali, Y . Wang, J. Yang, D. Zhuo, K. Sen, J. E. Gonzalez, and I. Stoica. Ansor: Generating high-performance tensor programs for deep learning. InProc. 14th USENIX Symp. on Operating Systems Design and Implementation (OSDI), pages 863–879, 2020. 17
2020
-
[27]
Zheng, L
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gon- zalez, C. Barrett, and Y . Sheng. SGLang: Efficient execution of structured language model programs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 18
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.