Multi-Turn Evaluation of Deep Research Agents Under Process-Level Feedback
Pith reviewed 2026-06-27 16:17 UTC · model grok-4.3
The pith
Even with targeted process-level feedback, deep research agents fail to achieve reliable multi-turn improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
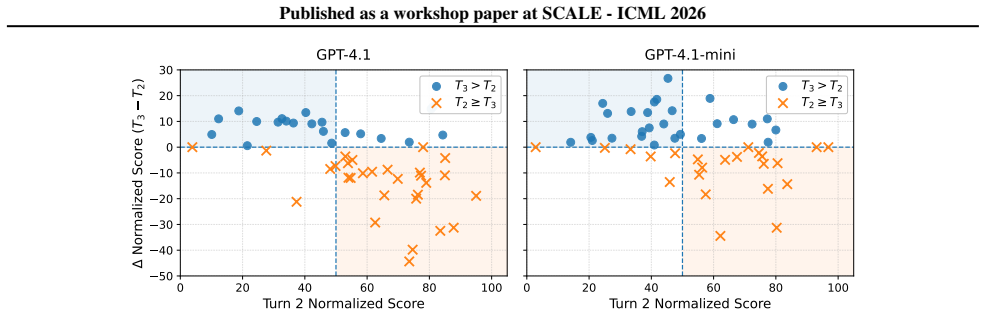
A single round of process-level feedback using Research Gap Inference yields substantial gains, raising normalized scores by approximately 8-15 points with a 35-40 percent incorporation rate of previously unsatisfied criteria. These gains do not compound over subsequent turns because agents regress on up to 24 percent of previously satisfied criteria when rewriting the full report to address remaining gaps. Under self-reflection alone, agents incorporate and regress on rubric criteria at nearly equal rates, yielding negligible net improvement.
What carries the argument
Research Gap Inference (RGI), a method that analyzes patterns of satisfied and unsatisfied rubric criteria to infer specific research-process gaps and supply targeted guidance.
If this is right
- Self-reflection alone produces negligible net improvement because incorporation and regression rates are nearly equal.
- One round of process-level feedback produces clear gains of 8-15 normalized points and 35-40 percent incorporation of new criteria.
- Subsequent turns after the first feedback round fail to compound gains because agents regress on up to 24 percent of previously satisfied criteria.
- The architectures tested cannot reliably convert repeated targeted guidance into sustained report improvement.
Where Pith is reading between the lines
- Architectures may need explicit mechanisms to preserve already-satisfied criteria during revisions rather than regenerating the full report.
- The observed regression pattern suggests a possible tension between addressing new gaps and retaining earlier quality that could be tested by tracking criterion stability per turn.
- Extending the evaluation to agents with external memory of prior feedback turns could reveal whether regression stems from loss of context during rewriting.
Load-bearing premise
The evaluation assumes that Research Gap Inference accurately identifies meaningful gaps in the agent's research process from the rubric patterns.
What would settle it
A demonstration that agents maintain or increase the fraction of satisfied criteria across three or more successive turns without regressing on prior gains would falsify the claim that reliable multi-turn improvement is out of reach.
Figures




read the original abstract
Existing benchmarks for deep research agents (DRAs) assess only single-shot outputs, ignoring a key question: can DRAs improve their reports when guided by feedback? To investigate this, we conduct a multi-turn evaluation of DRAs under two feedback settings: self-reflection, in which the agent revises its report without any external diagnostic signal, and process-level feedback, in which the agent receives guidance targeting gaps in its research strategy. To enable process-level feedback, we design Research Gap Inference (RGI), a method that analyzes patterns of satisfied and unsatisfied rubric criteria to infer research-process gaps. Our analysis reveals three key findings: (i) under self-reflection, agents incorporate and regress on rubric criteria at nearly equal rates, yielding negligible net improvement; (ii) a single round of process-level feedback yields substantial gains, raising the normalized score by approximately $8$-$15$ points and yielding a roughly $35$-$40\%$ incorporation rate; (iii) these gains do not compound over subsequent turns, as agents regress on up to $24\%$ of previously satisfied criteria when rewriting the full report to address remaining gaps. Even with targeted guidance, reliable multi-turn improvement remains out of reach for the DRA architectures we evaluate. Our code and results are publicly available at https://github.com/sabharwalrishabh/Multi-Turn-Evaluation-of-DRAs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deep research agents (DRAs) cannot achieve reliable multi-turn improvement even under targeted process-level feedback. It introduces Research Gap Inference (RGI) to generate feedback by analyzing patterns of satisfied/unsatisfied rubric criteria, then reports three findings from multi-turn evaluations: (i) self-reflection produces negligible net gains due to equal incorporation and regression rates; (ii) one round of process-level feedback raises normalized scores by 8-15 points with 35-40% incorporation; (iii) gains fail to compound because agents regress on up to 24% of previously satisfied criteria in later turns. The conclusion is that reliable iterative improvement remains out of reach for the evaluated DRA architectures. Code and results are released publicly.
Significance. If the results hold, the work supplies concrete evidence that current DRA architectures struggle with maintaining and building on progress across multiple turns, even when given diagnostic feedback on research-process gaps. This has implications for the design of iterative research agents. The public GitHub release of code and results is a clear strength, directly supporting reproducibility and follow-up experiments.
major comments (1)
- [Abstract and RGI method description] Abstract and description of RGI: The central claim—that targeted process-level feedback still fails to produce reliable multi-turn improvement—depends on RGI accurately mapping rubric patterns to meaningful, actionable research-process gaps. The manuscript supplies no validation of RGI (human agreement rates, ablation against oracle or random feedback, or error analysis), so the reported 24% regression rate and non-compounding gains could be artifacts of mis-targeted or noisy feedback rather than intrinsic DRA limitations.
minor comments (2)
- [Abstract] Abstract: Quantitative claims (8-15 point gains, 35-40% incorporation, 24% regression) are presented without any mention of the number of trials, agents evaluated, statistical tests, or variance, which weakens assessment of robustness.
- [Evaluation metrics] The definition of 'normalized score' and the exact rubric criteria used should be stated explicitly in the main text (not only supplementary) to allow independent verification.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback highlighting the need for validation of the Research Gap Inference (RGI) method. We address this point directly below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract and RGI method description] Abstract and description of RGI: The central claim—that targeted process-level feedback still fails to produce reliable multi-turn improvement—depends on RGI accurately mapping rubric patterns to meaningful, actionable research-process gaps. The manuscript supplies no validation of RGI (human agreement rates, ablation against oracle or random feedback, or error analysis), so the reported 24% regression rate and non-compounding gains could be artifacts of mis-targeted or noisy feedback rather than intrinsic DRA limitations.
Authors: We acknowledge that the current manuscript does not report quantitative validation of RGI, such as inter-annotator agreement with human experts, ablations against random or oracle feedback, or a dedicated error analysis. RGI operates by deterministically mapping patterns of unsatisfied rubric criteria to inferred research-process gaps (e.g., repeated failure on 'source diversity' criteria triggers a gap in source acquisition strategy). The public code and result release enables independent verification and extension. The regression phenomenon appears consistently in both self-reflection and process-level conditions, which would be unlikely if driven purely by RGI noise. Nevertheless, we agree that explicit validation would strengthen the central claim and will add a new subsection with (i) a small-scale human agreement study on RGI outputs and (ii) an ablation comparing RGI-derived feedback against random feedback baselines in the revised manuscript. revision: yes
Circularity Check
No significant circularity; empirical evaluation self-contained
full rationale
The paper is an empirical study that compares DRA performance across feedback conditions using experimental runs on rubric-based metrics. RGI is introduced as a heuristic method for inferring gaps from rubric patterns, but the central claims (incorporation/regression rates, non-compounding gains) are measured outcomes from agent executions rather than derived predictions or fitted parameters. No equations, self-citations, or ansatzes are invoked as load-bearing steps that reduce the results to inputs by construction. The work reports public code for reproducibility and makes no uniqueness theorems or renamings of known results. This matches the default expectation for non-circular empirical papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rubric criteria provide a valid and comprehensive measure of research report quality.
invented entities (1)
-
Research Gap Inference (RGI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Your treatment of detection methods stays at a survey level, describing general approaches without engaging with the specific systems behind them. For each area the query requires, your research should surface concrete methods and architectures introduced since 2022, grounded in peer-reviewed sources, rather than characterizing the field in broad terms
2022
-
[2]
Increase regulatory precision by identifying the exact titles, legal identifiers, and key operational provisions of major EU and US legislation
Your regulatory coverage reads as a high-level summary of policies. Increase regulatory precision by identifying the exact titles, legal identifiers, and key operational provisions of major EU and US legislation. When investigating EU, US, and international frameworks, locate the primary legislative texts and work from their specific provisions rather tha...
-
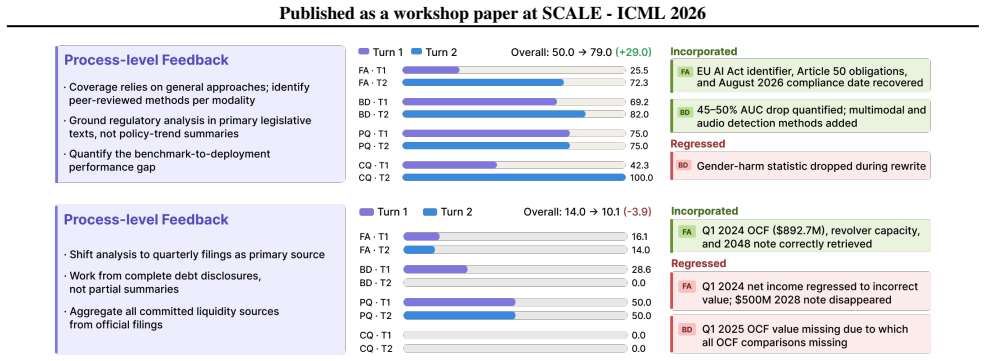
[3]
Figure 4.Task query and RGI feedback for Case 1 (Task 021)
Discussion of benchmark-versus-deployment performance can be strengthened by providing quantitative details on the magnitude of benchmark-to-real-world performance drops and linking them to concrete technical causes. Figure 4.Task query and RGI feedback for Case 1 (Task 021). Task 004 Query Analyze CME Group’s cash generation efficiency and capital alloca...
2024
-
[4]
Shift to quarterly filings as your primary source for all time-sensitive metrics across both Q1 2024 and Q1 2025, rather than deriving figures from full-year aggregates
Your analysis relies on annualized or summary-level data rather than period-specific figures. Shift to quarterly filings as your primary source for all time-sensitive metrics across both Q1 2024 and Q1 2025, rather than deriving figures from full-year aggregates
2024
-
[5]
Work from the full fixed-rate notes schedule in the official filings, ensuring all outstanding notes are captured and totals reconcile against the reported figures
Your debt analysis appears to draw on partial or secondary summaries rather than the complete capital structure disclosures. Work from the full fixed-rate notes schedule in the official filings, ensuring all outstanding notes are captured and totals reconcile against the reported figures. Account for any refinancing activity during the reporting period
-
[6]
Your liquidity assessment is built on incomplete inputs, which undermines the downstream ratios the query requires. Aggregate all committed sources of available liquidity—including both drawn and undrawn facilities—from the most recent filings and use these as the basis for coverage and concentration metrics. Figure 5.Task query and RGI feedback for Case ...
2026
-
[7]
The original research query
-
[8]
What the report covered correctly (factual accuracy passes)
-
[9]
What the report missed or got wrong (factual accuracy failures and evaluator explanations)
-
[10]
Citation signals (which sources the model found, missed, or misused -- for your inference only)
-
[11]
What the report achieved analytically (breadth-and-depth passes)
-
[12]
: model committed this error
Analytical depth failures (breadth-and-depth failures and evaluator explanations) Note on errors of commission: Some FA and BD failures are marked with the label ": model committed this error". These are negative criteria as they describe something the report should NOT have done but did (e.g., citing an unreliable figure, applying an incompatible framewo...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.