Difference-Aware Retrieval Policies for Imitation Learning
Pith reviewed 2026-06-27 16:25 UTC · model grok-4.3
The pith
DARP improves imitation learning by predicting actions from k-nearest expert neighbors and their state differences rather than a global policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
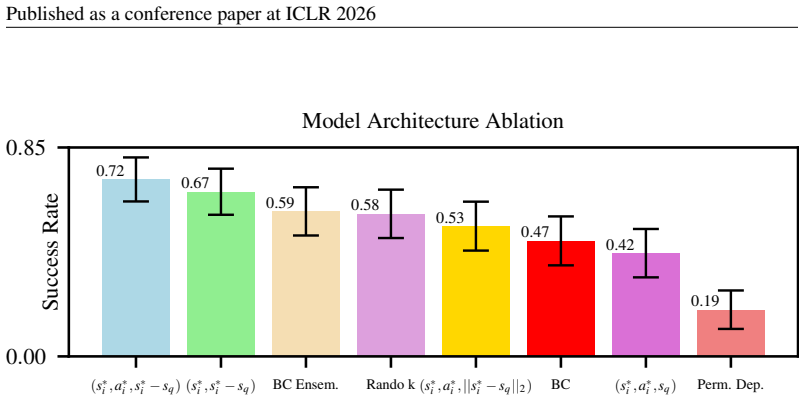
DARP reparameterizes imitation learning around local neighborhood structure. It trains a model to output actions from the k-nearest neighbors drawn from expert demonstrations, the actions those neighbors took, and the relative distance vectors between each neighbor state and the query state. This replaces the usual global parametric policy and produces consistent gains of 15-46 percent over behavior cloning in continuous control, robotic manipulation, and visual-feature settings while respecting exactly the same data and assumption limits.
What carries the argument
k-nearest-neighbor retrieval combined with relative state-distance vectors that reparameterize action prediction around local differences instead of absolute state-to-action mappings.
If this is right
- The approach produces 15-46 percent higher task success than behavior cloning across continuous control benchmarks.
- The same gains appear in robotic manipulation experiments and when inputs are high-dimensional visual features.
- No additional demonstration collection, online expert access, or task-specific engineering is required.
- Compounding errors are reduced because the policy stays anchored to nearby expert data at every step.
Where Pith is reading between the lines
- The same retrieval logic could be tested on imitation datasets that are larger or more redundant than the ones used here.
- Performance may depend on how the state distance metric is chosen when the underlying dynamics have different invariances.
- Hybrid policies that combine the retrieval head with a small parametric correction term remain untested in the reported experiments.
Load-bearing premise
The local neighborhood structure captured by k-NN retrieval and relative distance vectors is enough to yield better generalization than a single global parametric policy.
What would settle it
Running DARP and standard behavior cloning on the same expert dataset in a new continuous-control or manipulation task and finding equal or lower success rates for DARP would show the claimed gains do not hold.
Figures






read the original abstract
Parametric imitation learning via behavior cloning can suffer from poor generalization to out-of-distribution states due to compounding errors during deployment. We show that reusing the training data during inference via a semi-parametric retrieval-based imitation learning approach can alleviate this challenge. We present Difference-Aware Retrieval Policies for Imitation Learning (DARP), a semi-parametric retrieval-based imitation learning approach that addresses this limitation by reparameterizing the imitation learning problem in terms of local neighborhood structure rather than direct state-to-action mappings. Instead of learning a global policy, DARP trains a model to predict actions based on $k$-nearest neighbors from expert demonstrations, their corresponding actions, and the relative distance vectors between neighbor states and query states. DARP requires no additional assumptions beyond those made for standard behavior cloning -- it does not require additional data collection, online expert feedback, or task-specific knowledge. We demonstrate consistent performance improvements of 15-46% over standard behavior cloning across diverse domains, including continuous control and robotic manipulation, and across different representations, including high-dimensional visual features. Code and demos are available at https://weirdlabuw.github.io/darp-site/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Difference-Aware Retrieval Policies (DARP) for imitation learning, a semi-parametric method that trains a model to predict actions from k-nearest neighbors drawn from expert demonstrations, the neighbors' actions, and the relative distance vectors between those neighbors and the query state. It claims this reparameterization around local neighborhood structure yields consistent 15-46% performance gains over standard behavior cloning across continuous control, robotic manipulation, and visual-feature domains, while requiring no additional data, online feedback, or task-specific knowledge beyond the assumptions of behavior cloning.
Significance. If the reported gains are robust, DARP would provide a practical, retrieval-based alternative to purely parametric behavior cloning that leverages existing demonstration data at inference time to improve generalization under compounding errors. The public code release is a positive factor for reproducibility. The approach is empirically driven rather than theoretically derived, so its significance hinges on whether the local-difference representation demonstrably mitigates distribution shift relative to direct state-to-action mappings.
major comments (2)
- [Abstract and §1] Abstract and §1: The claim that 'DARP requires no additional assumptions beyond those made for standard behavior cloning' is load-bearing for the central contribution. The model is trained exclusively on neighborhoods and relative vectors computed from expert states; at deployment the query states are reached via compounding errors, so the distribution of neighbor identities and relative-vector magnitudes can differ substantially. No analysis or mechanism is provided to ensure the learned predictor encounters similar input distributions, which weakens the 'no additional assumptions' statement relative to standard BC.
- [Experiments] Experiments section (performance tables): The 15-46% improvements are presented as the primary evidence, yet the manuscript provides no information on the number of random seeds, statistical significance testing, or whether baseline implementations were re-tuned to match the DARP hyper-parameter budget (particularly the choice of k). Without these details the magnitude and reliability of the gains cannot be assessed.
minor comments (1)
- [Method] Notation for the relative distance vector is introduced without an explicit equation; adding a short definition (e.g., Eq. (X)) would improve clarity when the input representation is first described.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The claim that 'DARP requires no additional assumptions beyond those made for standard behavior cloning' is load-bearing for the central contribution. The model is trained exclusively on neighborhoods and relative vectors computed from expert states; at deployment the query states are reached via compounding errors, so the distribution of neighbor identities and relative-vector magnitudes can differ substantially. No analysis or mechanism is provided to ensure the learned predictor encounters similar input distributions, which weakens the 'no additional assumptions' statement relative to standard BC.
Authors: We thank the referee for this observation. The claim is meant to convey that DARP introduces no new requirements for data collection, online expert feedback, or task-specific knowledge beyond standard behavior cloning. We acknowledge that test-time query states (and thus retrieved neighbors and relative vectors) can differ due to compounding errors, as is true for BC itself. DARP's design uses relative distances precisely to improve robustness under such shifts. In revision we will clarify the wording of the claim and add a short discussion of input distribution differences at deployment. revision: partial
-
Referee: [Experiments] Experiments section (performance tables): The 15-46% improvements are presented as the primary evidence, yet the manuscript provides no information on the number of random seeds, statistical significance testing, or whether baseline implementations were re-tuned to match the DARP hyper-parameter budget (particularly the choice of k). Without these details the magnitude and reliability of the gains cannot be assessed.
Authors: We agree these details are necessary for assessing reliability. In the revised manuscript we will report the number of random seeds used for each experiment, include statistical significance testing (e.g., paired t-tests), and explicitly state that baselines were re-implemented and tuned under an equivalent hyper-parameter budget, including sweeps over the number of neighbors k. revision: yes
Circularity Check
No circularity; empirical algorithmic change evaluated on benchmarks
full rationale
The paper introduces DARP as a semi-parametric retrieval method that reparameterizes imitation learning around k-NN neighbors and relative distance vectors instead of direct state-to-action mappings. No equations, derivations, or fitted parameters are shown that reduce the reported 15-46% gains to quantities defined by construction inside the paper. The central claims rest on empirical evaluation across standard continuous control and manipulation benchmarks rather than any self-citation chain, uniqueness theorem, or ansatz smuggled via prior work. The method is explicitly stated to require no additional assumptions beyond standard behavior cloning, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (number of neighbors)
axioms (1)
- domain assumption Expert demonstrations are available and sufficient for the task
Reference graph
Works this paper leans on
-
[1]
Robotics: Science and Systems (RSS) , year =
The Surprising Effectiveness of Representation Learning for Visual Imitation , author =. Robotics: Science and Systems (RSS) , year =. doi:10.15607/RSS.2022.XVIII-052 , publisher =
-
[2]
IEEE Robotics and Automation Letters , year =
Emmanuel Pignat and Sylvain Calinon , title =. IEEE Robotics and Automation Letters , year =
-
[3]
International Conference on Learning Representations (ICLR) 2023 , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations (ICLR) 2023 , year =
2023
-
[4]
International Conference on Learning Representations (ICLR) 2018 , year =
Elman Mansimov and Kyunghyun Cho , title =. International Conference on Learning Representations (ICLR) 2018 , year =
2018
-
[5]
Steven L. Salzberg and David W. Aha , title =. Selecting Models from Data: Artificial Intelligence and Statistics IV , editor =. 1994 , pages =. doi:10.1007/978-1-4612-2660-4\_33 , url =
-
[6]
Dean Pomerleau , title =. Neural Comput. , volume =. 1991 , url =. doi:10.1162/NECO.1991.3.1.88 , timestamp =
-
[7]
Smooth Imitation Learning via Smooth Costs and Smooth Policies , booktitle =
Sapana Chaudhary and Balaraman Ravindran , editor =. Smooth Imitation Learning via Smooth Costs and Smooth Policies , booktitle =. 2022 , url =. doi:10.1145/3493700.3493716 , timestamp =
-
[8]
Stanislas Ducotterd and Alexis Goujon and Pakshal Bohra and Dimitris Perdios and Sebastian Neumayer and Michael Unser , title =. J. Mach. Learn. Res. , volume =. 2024 , url =
2024
-
[9]
Learning from demonstration with model-based Gaussian process , booktitle =
No. Learning from demonstration with model-based Gaussian process , booktitle =. 2019 , url =
2019
-
[10]
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
Jan Ole von Hartz and Adrian R. The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.03296 , eprinttype =. 2505.03296 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.03296 2025
-
[11]
2020 , eprint=
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems , author=. 2020 , eprint=
2020
-
[12]
Srinivasa and Abhishek Gupta , title =
Liyiming Ke and Yunchu Zhang and Abhay Deshpande and Siddhartha S. Srinivasa and Abhishek Gupta , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[13]
Arun Venkatraman and Martial Hebert and J. Andrew Bagnell , editor =. Improving Multi-Step Prediction of Learned Time Series Models , booktitle =. 2015 , url =. doi:10.1609/AAAI.V29I1.9590 , timestamp =
-
[14]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , booktitle =
St. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , booktitle =. 2011 , url =
2011
-
[15]
Spencer and Sanjiban Choudhury and Arun Venkatraman and Brian D
Jonathan C. Spencer and Sanjiban Choudhury and Arun Venkatraman and Brian D. Ziebart and J. Andrew Bagnell , title =. CoRR , volume =. 2021 , url =. 2102.02872 , timestamp =
-
[16]
2025 , note =
Sridhar, Kaustubh and Dutta, Souradeep and Jayaraman, Dinesh and Lee, Insup , booktitle =. 2025 , note =
2025
-
[17]
2024 , eprint=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. 2024 , eprint=
2024
-
[18]
Conference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand , series =
Suraj Nair and Aravind Rajeswaran and Vikash Kumar and Chelsea Finn and Abhinav Gupta , editor =. Conference on Robot Learning, CoRL 2022, 14-18 December 2022, Auckland, New Zealand , series =. 2022 , url =
2022
-
[19]
2012 IEEE/RSJ international conference on intelligent robots and systems , pages=
Mujoco: A physics engine for model-based control , author=. 2012 IEEE/RSJ international conference on intelligent robots and systems , pages=. 2012 , organization=
2012
-
[20]
2020 , eprint=
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. 2020 , eprint=
2020
-
[21]
7th Annual Conference on Robot Learning , year=
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations , author=. 7th Annual Conference on Robot Learning , year=
-
[22]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning , author=. arXiv preprint arXiv:2009.12293 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[23]
Proceedings of the 36th International Conference on Machine Learning , pages=
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks , author=. Proceedings of the 36th International Conference on Machine Learning , pages=
-
[24]
Advances in Neural Information Processing Systems 30 , editor =
Deep Sets , author =. Advances in Neural Information Processing Systems 30 , editor =. 2017 , publisher =
2017
-
[25]
The International Journal of Robotics Research , year =
Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song , title =. The International Journal of Robotics Research , year =
-
[26]
1997 , series=
Spectral Graph Theory , author=. 1997 , series=
1997
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning with local and global consistency , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[28]
Journal of Computer and System Sciences , volume=
Towards a theoretical foundation for Laplacian-based manifold methods , author=. Journal of Computer and System Sciences , volume=. 2008 , publisher=
2008
-
[29]
Proceedings of Robotics: Science and Systems (RSS) , year=
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[30]
2014 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Accelerating imitation learning through crowdsourcing , author=. 2014 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2014 , organization=
2014
-
[31]
International Conference on Learning Representations , year=
SEABO: A Simple Search-Based Method for Offline Imitation Learning , author=. International Conference on Learning Representations , year=
-
[32]
Proceedings of Robotics: Science and Systems (RSS) , year =
Behavior Retrieval: Few-Shot Imitation Learning by Querying Unlabeled Datasets , author =. Proceedings of Robotics: Science and Systems (RSS) , year =
-
[33]
FlowRetrieval: Flow-Guided Data Retrieval for Few-Shot Imitation Learning , booktitle =
Li. FlowRetrieval: Flow-Guided Data Retrieval for Few-Shot Imitation Learning , booktitle =. 2024 , url =
2024
-
[34]
The Thirteenth International Conference on Learning Representations , year=
STRAP: Robot Sub-Trajectory Retrieval for Augmented Policy Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[35]
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning , author=. arXiv preprint arXiv:2505.03296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year =
Kobayashi, Taisuke , title =. 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year =
2022
-
[37]
The Twelfth International Conference on Learning Representations , year=
CCIL: Continuity-Based Data Augmentation for Corrective Imitation Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[38]
International Conference on Machine Learning , year =
Asadi, Kavosh and Misra, Dipendra and Littman, Michael , title =. International Conference on Machine Learning , year =
-
[39]
arxiv preprint arXiv:2410.11825 , year=
Learning Smooth Humanoid Locomotion through Lipschitz-Constrained Policies , author=. arxiv preprint arXiv:2410.11825 , year=
-
[40]
Learning for Dynamics and Control Conference , year =
Tu, Stephen and others , title =. Learning for Dynamics and Control Conference , year =
-
[41]
Advances in Neural Information Processing Systems , volume =
Lee, Jonathan and others , title =. Advances in Neural Information Processing Systems , volume =. 2023 , pages =
2023
-
[42]
arXiv preprint arXiv:2408.15980 , year=
In-Context Imitation Learning via Next-Token Prediction , author=. arXiv preprint arXiv:2408.15980 , year=
-
[43]
arxiv preprint arXiv:2503.01206 , year=
Action Tokenizer Matters in In-Context Imitation Learning , author=. arxiv preprint arXiv:2503.01206 , year=
-
[44]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Instant Policy: In-Context Imitation Learning via Graph Diffusion , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[45]
Proceedings of Robotics: Science and Systems (RSS) , year=
Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[46]
arXiv preprint arXiv:2507.21452 , year=
Retrieve-Augmented Generation for Speeding up Diffusion Policy without Additional Training , author=. arXiv preprint arXiv:2507.21452 , year=
-
[47]
Robotics: Science and Systems (RSS) , year=
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots , author=. Robotics: Science and Systems (RSS) , year=
-
[48]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Efficient reductions for imitation learning , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.