Preserving Plasticity in Continual Learning via Dynamical Isometry
Pith reviewed 2026-06-27 17:24 UTC · model grok-4.3
The pith
Dynamical isometry keeps neural networks able to learn new tasks by holding layer Jacobian singular values near one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
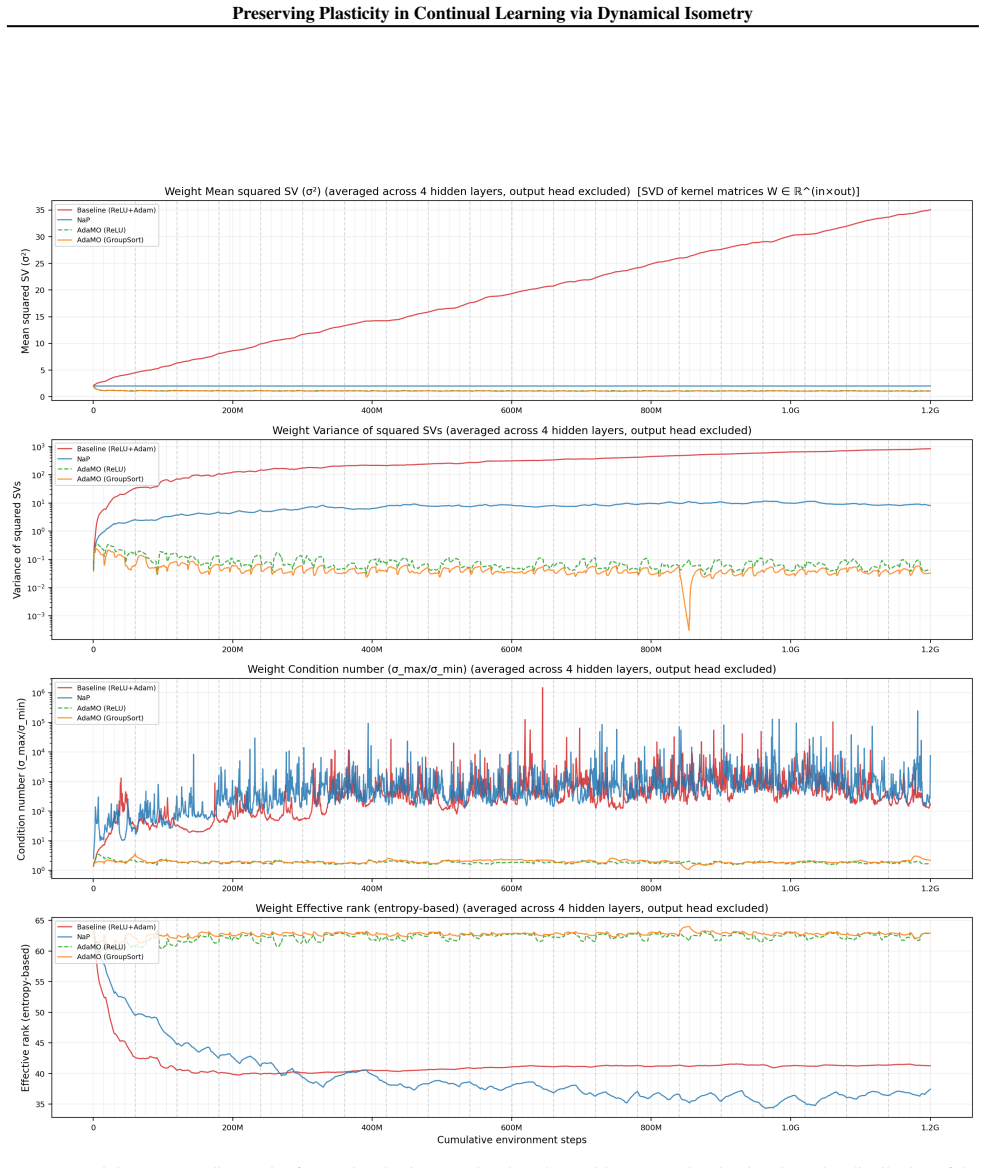
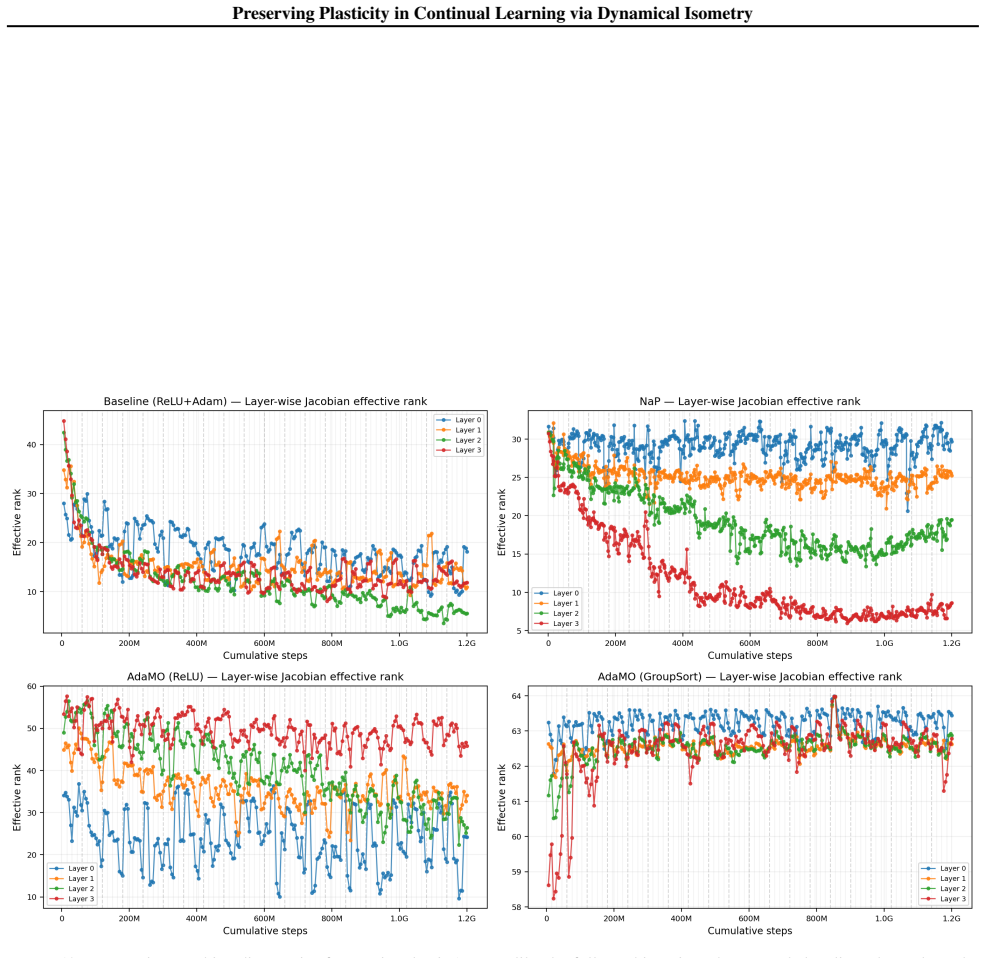
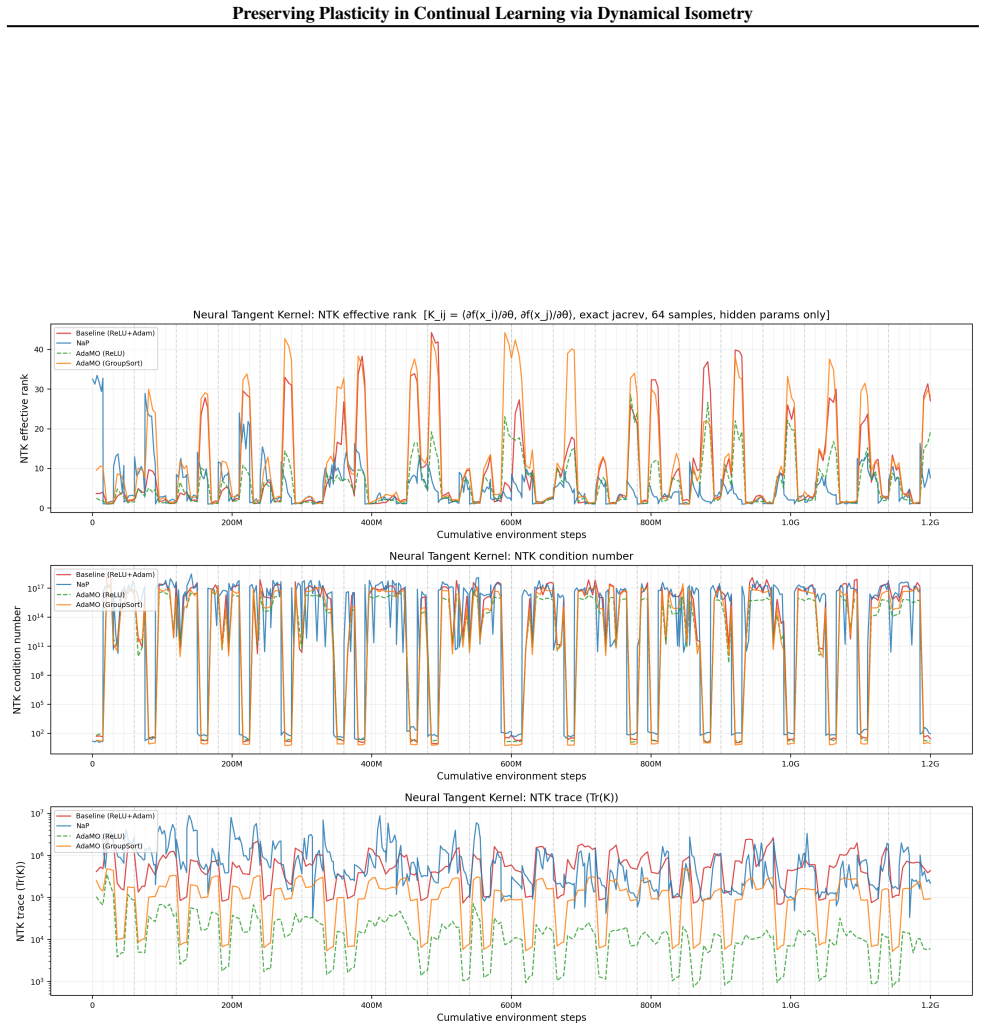
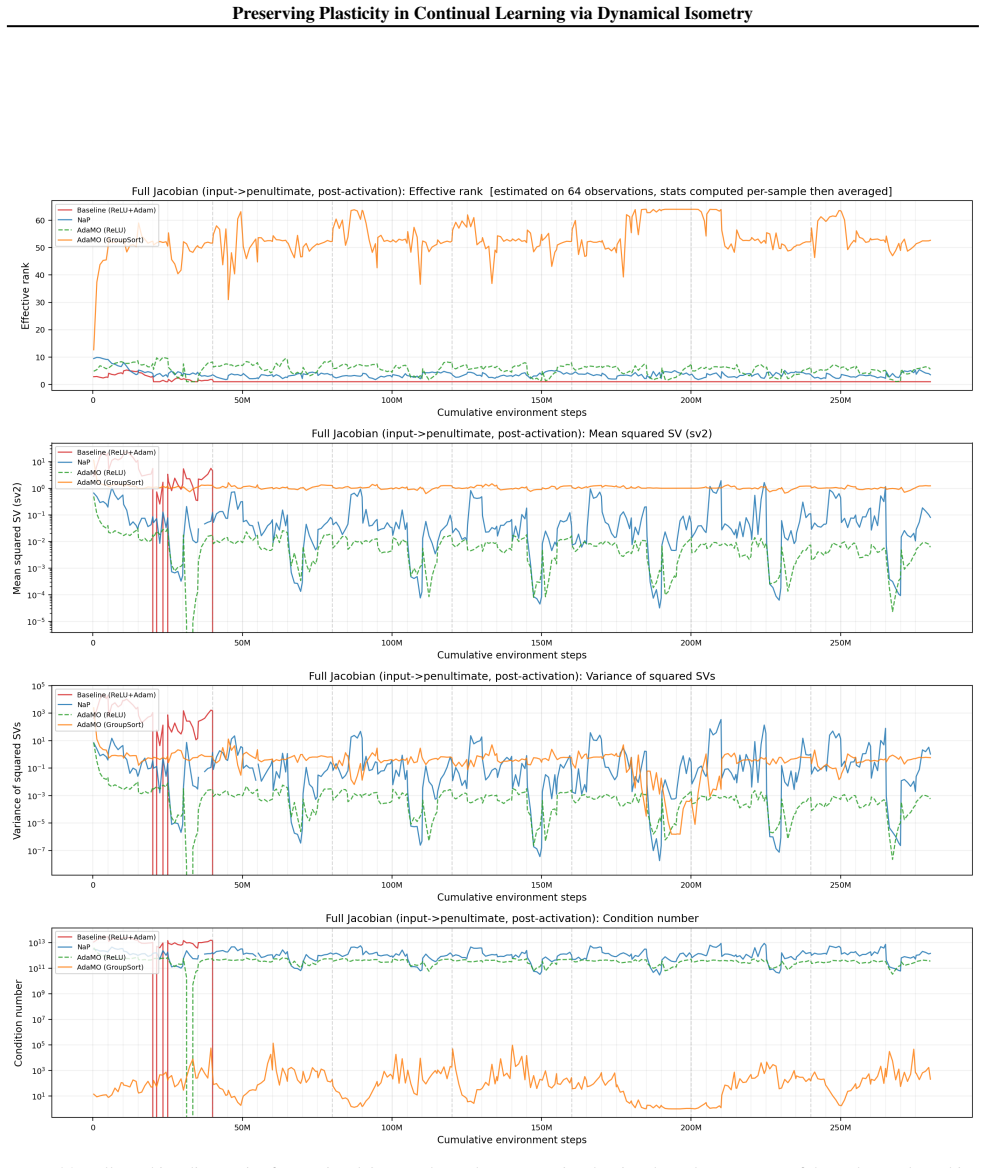
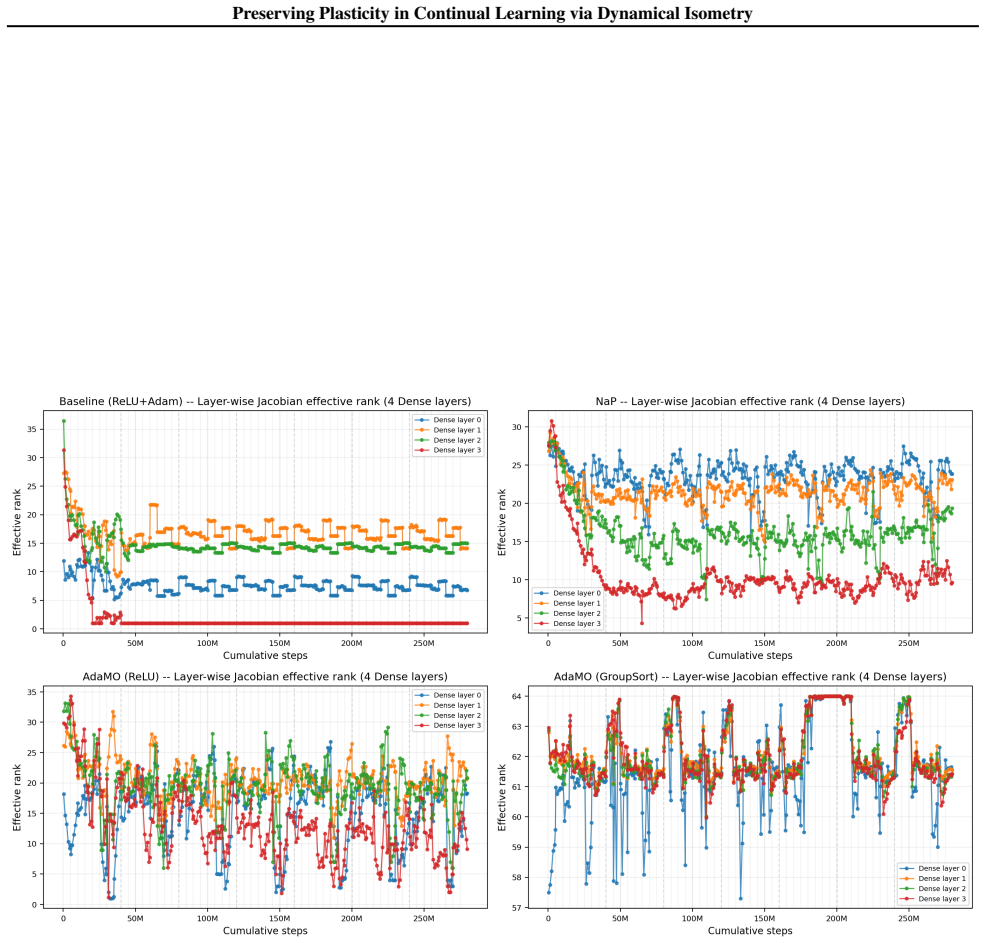
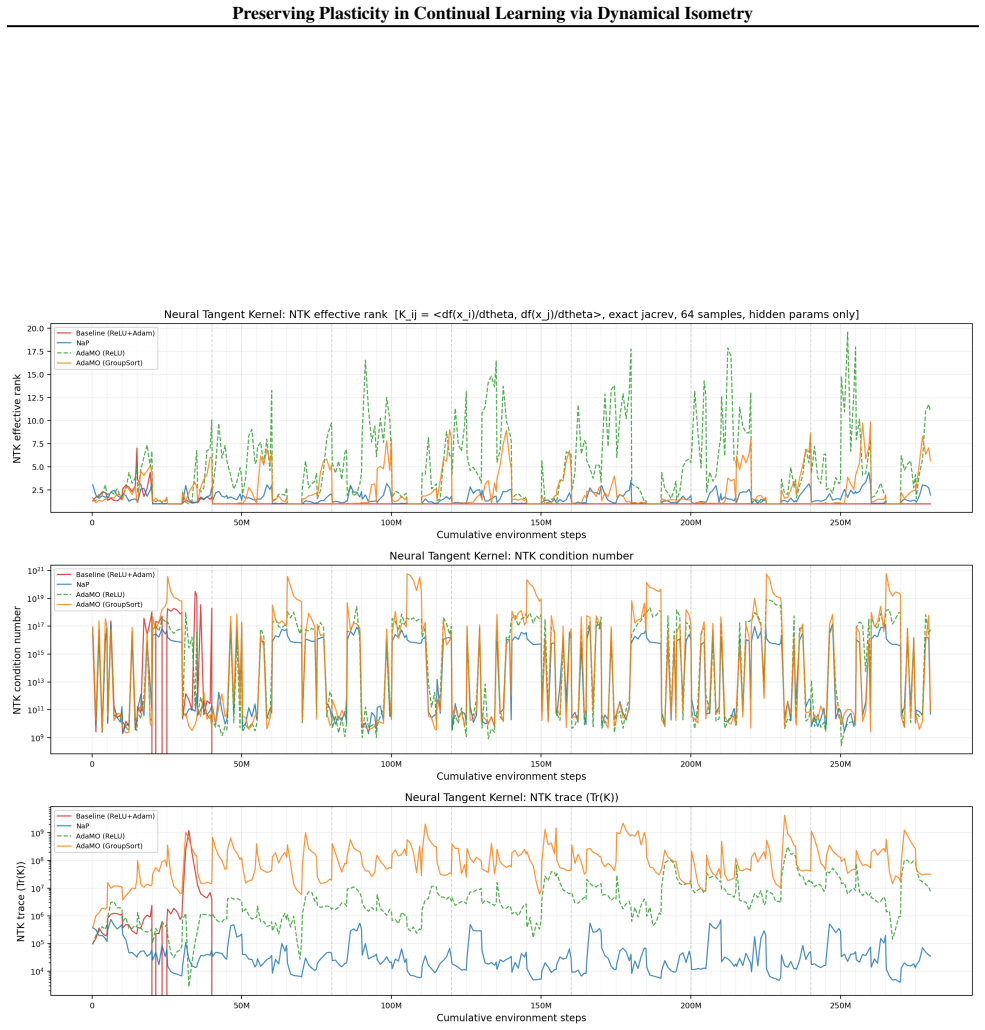
Dynamical isometry is the mechanism that preserves plasticity because it keeps the empirical Neural Tangent Kernel well-conditioned across tasks. The authors establish this by revisiting almost-everywhere isometric networks that remain expressive approximators, by deriving a regularization term that promotes isometry and reactivates dormant ReLUs, and by constructing AdamO to apply the regularization separately from gradient steps. They further show that earlier plasticity methods only achieve partial isometry.
What carries the argument
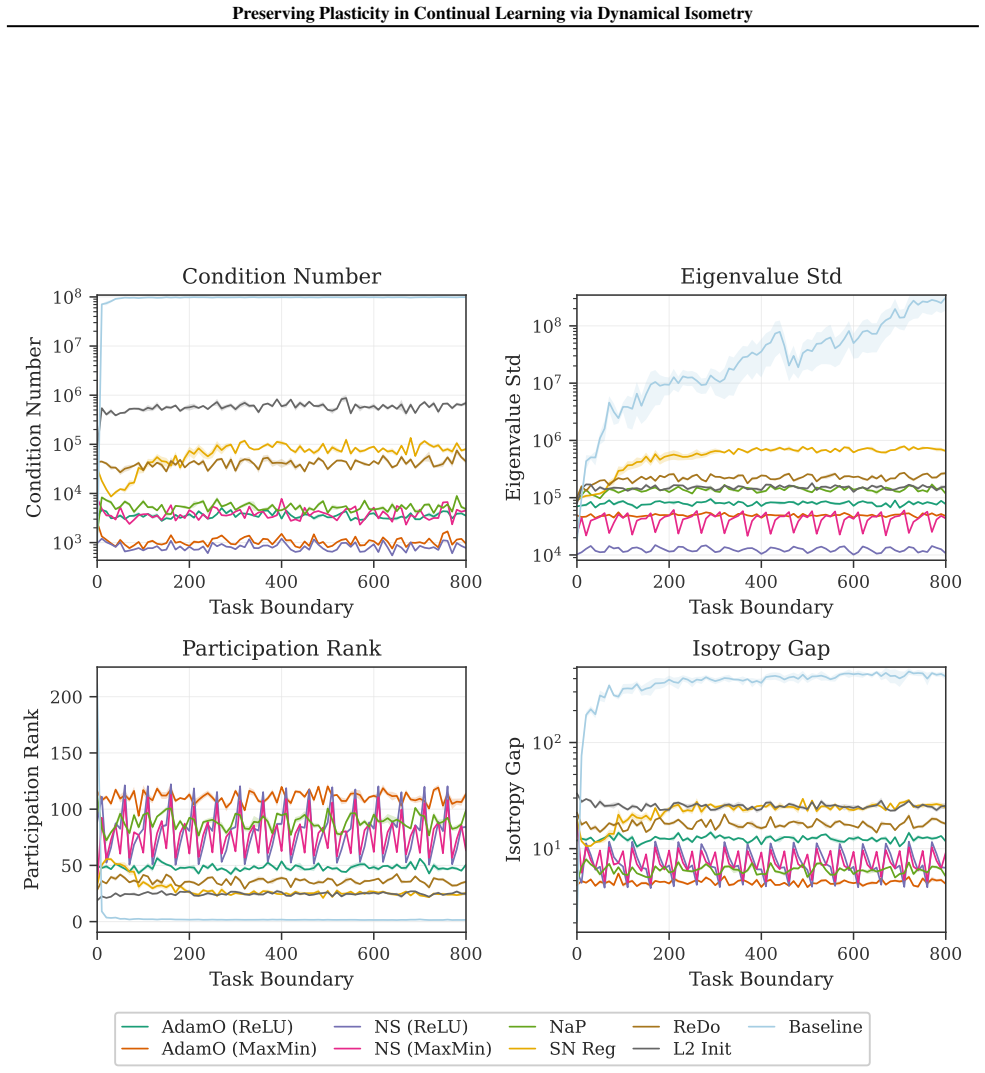
Dynamical isometry: the requirement that the singular values of each layer's Jacobian stay close to one, which keeps gradient flow and the neural tangent kernel stable under non-stationary data.
If this is right
- Near-dynamical isometry remains compatible with universal approximation by nonlinear networks.
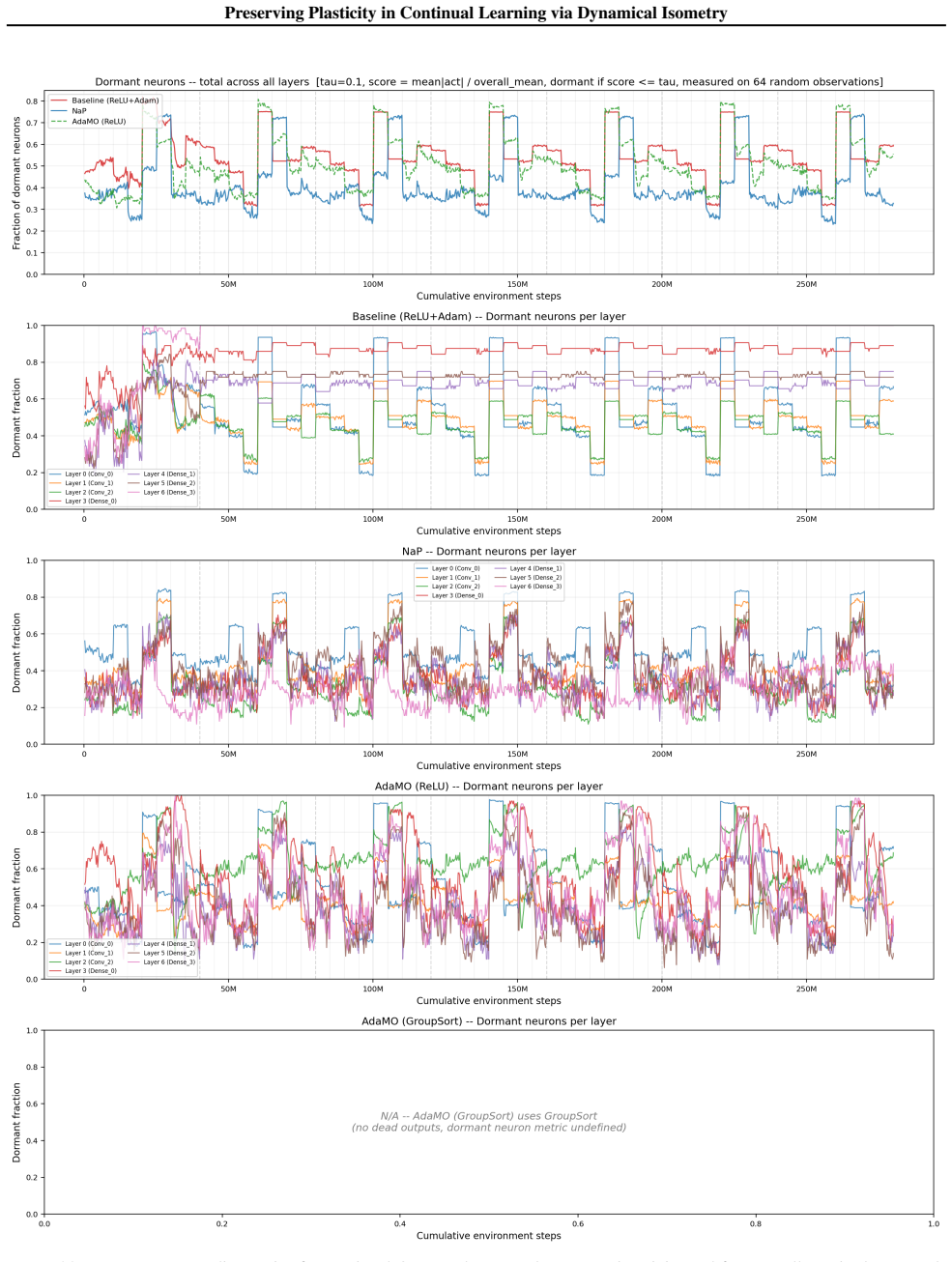
- The proposed regularizer reactivates dormant ReLU units as a side effect of promoting isometry.
- AdamO applies isometry regularization without interfering with the base gradient updates.
- Prior plasticity methods achieve only a partial form of isometry.
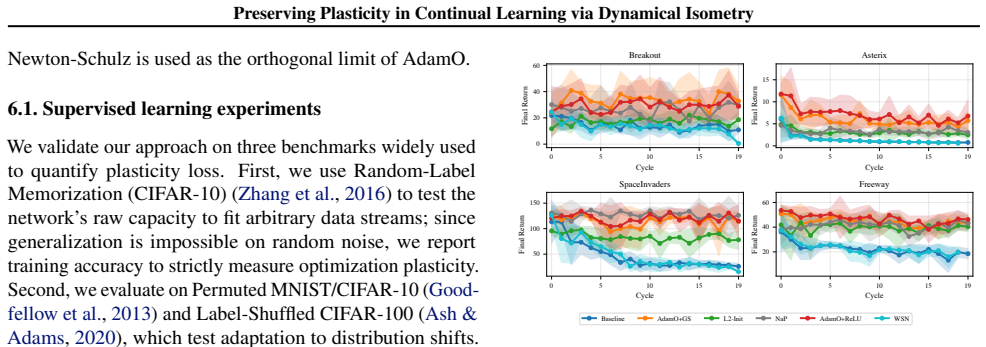
- The same regularization and optimizer yield consistent gains on both supervised and reinforcement-learning continual benchmarks.
Where Pith is reading between the lines
- If dynamical isometry is the dominant factor, then replay buffers and architectural resets become secondary rather than essential for long-horizon continual learning.
- The same Jacobian-regularization idea could be tested in non-stationary control problems where the data distribution drifts continuously rather than in discrete tasks.
- Measuring the full spectrum of Jacobian singular values rather than only their mean or condition number might give a stricter test of the isometry hypothesis.
Load-bearing premise
That the empirical Neural Tangent Kernel and layer-wise Jacobian singular values are the primary quantities that control plasticity loss.
What would settle it
A controlled run in which Jacobian singular values are forced to remain near one yet plasticity still collapses on a standard continual-learning benchmark, or in which isometry is deliberately broken yet plasticity is retained.
Figures











read the original abstract
Continual training of deep neural networks under non-stationarity often leads to a progressive loss of plasticity, eventually limiting further learning. We relate plasticity to the empirical Neural Tangent Kernel, and identify dynamical isometry (the condition that layer-wise Jacobian singular values remain close to one) as a key mechanism for preserving plasticity in continual learning. We revisit a class of networks that are almost-everywhere isometric while remaining universal Lipschitz function approximators, demonstrating that near-dynamical isometry is compatible with expressive nonlinear representations. For general architectures, we propose an efficient isometry-promoting regularization scheme and identify a novel mechanism by which it can reactivate dormant ReLU units. Building on this, we introduce AdamO, an Adam-style adaptive optimizer that decouples isometry regularization from gradient updates, analogous to AdamW. We further reinterpret prior plasticity-preserving approaches through the lens of dynamical isometry, showing that they target only a partial measure of isometry. Across supervised and reinforcement-learning continual-learning benchmarks designed to induce plasticity loss, our methods consistently match or outperform existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that loss of plasticity in continual learning can be understood and mitigated through the lens of dynamical isometry (layer-wise Jacobian singular values near 1), which preserves the empirical Neural Tangent Kernel. It shows that near-isometric networks remain universal Lipschitz approximators, introduces an isometry-promoting regularizer that can reactivate dormant ReLUs, proposes the AdamO optimizer (decoupling isometry regularization from gradients, analogous to AdamW), reinterprets prior plasticity methods as targeting only partial isometry, and reports that the resulting methods match or outperform existing approaches on supervised and RL continual-learning benchmarks designed to induce plasticity loss.
Significance. If the mechanism attribution holds, the work offers a unifying perspective on plasticity preservation and practical tools (regularizer + AdamO) that could be adopted broadly. Credit is due for the explicit analogy to AdamW, the demonstration that near-dynamical isometry is compatible with expressive nonlinear representations, and the reinterpretation of prior methods through the isometry lens.
major comments (2)
- [Abstract] Abstract: the central claim that dynamical isometry is the operative mechanism (via its effect on the eNTK) is load-bearing for the contribution, yet the text provides no ablation or control that holds feature drift, loss-landscape curvature, and other factors fixed while varying only the layer-wise Jacobian singular-value distribution. Without such isolation, the reported outperformance cannot be attributed specifically to isometry.
- [Abstract] Abstract: the asserted relation between plasticity and the empirical Neural Tangent Kernel is stated without an explicit equation or derivation showing how the singular-value condition controls the eNTK spectrum under non-stationary data; this link is required to make the mechanism claim falsifiable rather than correlational.
minor comments (2)
- [Abstract] The abstract refers to 'benchmarks designed to induce plasticity loss' but supplies neither dataset names, task sequences, nor hyper-parameter details; these must be added for reproducibility.
- Notation for the isometry-promoting regularizer and the precise definition of 'near-dynamical isometry' (e.g., tolerance on singular values) should be introduced with an equation in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the mechanism claims. We address each major comment below and outline planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that dynamical isometry is the operative mechanism (via its effect on the eNTK) is load-bearing for the contribution, yet the text provides no ablation or control that holds feature drift, loss-landscape curvature, and other factors fixed while varying only the layer-wise Jacobian singular-value distribution. Without such isolation, the reported outperformance cannot be attributed specifically to isometry.
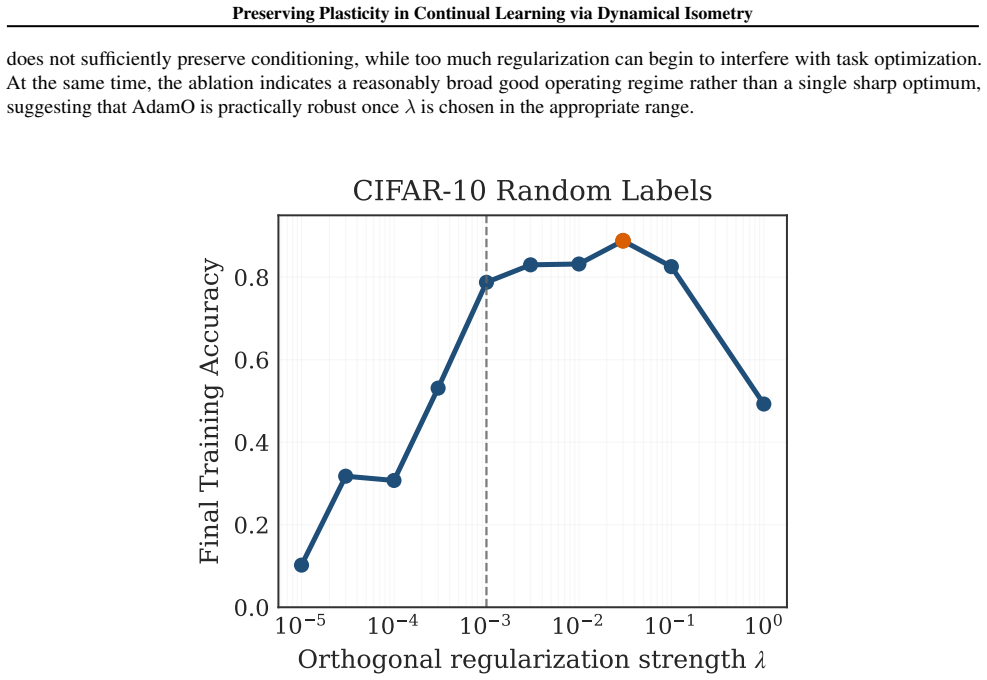
Authors: We agree that a fully isolated ablation varying only the Jacobian singular-value distribution while holding feature drift and curvature fixed would provide stronger causal evidence. Such a control is difficult to construct in non-stationary continual learning because changes to the Jacobian spectrum necessarily influence representations and optimization dynamics. Our regularizer is explicitly designed to target isometry (via a penalty on deviation of singular values from 1) without directly regularizing other quantities, and we compare against baselines that do not enforce this property. In revision we will add a dedicated limitations paragraph discussing this point and explaining why complete isolation remains challenging. revision: partial
-
Referee: [Abstract] Abstract: the asserted relation between plasticity and the empirical Neural Tangent Kernel is stated without an explicit equation or derivation showing how the singular-value condition controls the eNTK spectrum under non-stationary data; this link is required to make the mechanism claim falsifiable rather than correlational.
Authors: Section 3 of the manuscript derives the link: the eNTK is the Gram matrix of the product of layer-wise Jacobians, so that the spectrum of the eNTK remains well-conditioned precisely when the singular values of each Jacobian stay near 1. Under non-stationary data this prevents progressive ill-conditioning that correlates with plasticity loss. We will insert a concise reference to this derivation (or a one-sentence summary) into the abstract and introduction to make the mechanistic claim more explicit and falsifiable. revision: yes
Circularity Check
No circularity: derivation remains independent of its inputs
full rationale
The paper relates plasticity loss to the empirical NTK and identifies dynamical isometry (Jacobian singular values near 1) as a mechanism, then proposes an isometry-promoting regularizer and AdamO optimizer while reinterpreting prior methods. No equations, fitted parameters, or self-citations are shown that reduce any central claim to a tautology or post-hoc fit by construction. The identification of isometry as key is presented as an empirical and theoretical observation rather than a definitional equivalence, and the new methods are introduced as independent contributions. This satisfies the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plasticity loss can be diagnosed and mitigated via the empirical Neural Tangent Kernel and layer-wise Jacobian singular values.
Reference graph
Works this paper leans on
-
[1]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Norm-preserving Orthogonal Permutation Linear Unit Activation Functions (OPLU)
Chernodub, A. and Nowicki, D. Norm-preserving orthog- onal permutation linear unit activation functions (oplu). arXiv preprint arXiv:1604.02313,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
M., Kaur, S., Li, Y ., Kolter, J
Cohen, J. M., Kaur, S., Li, Y ., Kolter, J. Z., and Talwalkar, A. Gradient descent on neural networks typically occurs at the edge of stability.arXiv preprint arXiv:2103.00065,
-
[4]
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Goodfellow, I. J., Mirza, M., Xiao, D., Courville, A., and Bengio, Y . An empirical investigation of catastrophic for- getting in gradient-based neural networks.arXiv preprint arXiv:1312.6211,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Grishina, E., Smirnov, M., and Rakhuba, M. Ac- celerating newton-schulz iteration for orthogonaliza- tion via chebyshev-type polynomials.arXiv preprint arXiv:2506.10935,
-
[6]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Maintaining plas- ticity in continual learning via regenerative regularization
Kumar, S., Marklund, H., and Van Roy, B. Maintaining plas- ticity in continual learning via regenerative regularization. arXiv preprint arXiv:2308.11958,
-
[8]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
-
[10]
Lyle, C., Rowland, M., and Dabney, W. Understanding and preventing capacity loss in reinforcement learning.arXiv preprint arXiv:2204.09560,
-
[11]
P., Pascanu, R., and Dabney, W
10 Preserving Plasticity in Continual Learning via Dynamical Isometry Lyle, C., Zheng, Z., Khetarpal, K., Martens, J., van Hasselt, H. P., Pascanu, R., and Dabney, W. Normalization and effective learning rates in reinforcement learning.Ad- vances in Neural Information Processing Systems, 37: 106440–106473, 2024a. Lyle, C., Zheng, Z., Khetarpal, K., van Ha...
-
[12]
The emer- gence of spectral universality in deep networks
Pennington, J., Schoenholz, S., and Ganguli, S. The emer- gence of spectral universality in deep networks. InInter- national Conference on Artificial Intelligence and Statis- tics, pp. 1924–1932. PMLR,
1924
-
[13]
URL https://arxiv.org/abs/2510. 01764. Saxe, A. M., McClelland, J. L., and Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
L2 Regularization versus Batch and Weight Normalization
Van Laarhoven, T. L2 regularization versus batch and weight normalization.arXiv preprint arXiv:1706.05350,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
MinAtar: An Atari-Inspired Testbed for Thorough and Reproducible Reinforcement Learning Experiments
URL https://arxiv.org/abs/ 1903.03176. Zhang, C., Bengio, S., Hardt, M., Recht, B., and Vinyals, O. Understanding deep learning requires rethinking general- ization.arXiv preprint arXiv:1611.03530,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[17]
We run 8 seeds per method
Learning rate for Adam and AdamO is 1e-3. We run 8 seeds per method. For Lipschitz-1 networks, we leave the output head unrestricted (or regularize it with a softer regularizer) so the network can approximate L-lipschitz functions. Algorithm hyperparameters: • For AdamO, we use a regularization strength of 1e-3 for the orthogonal penalty. Learning rate is...
2019
-
[18]
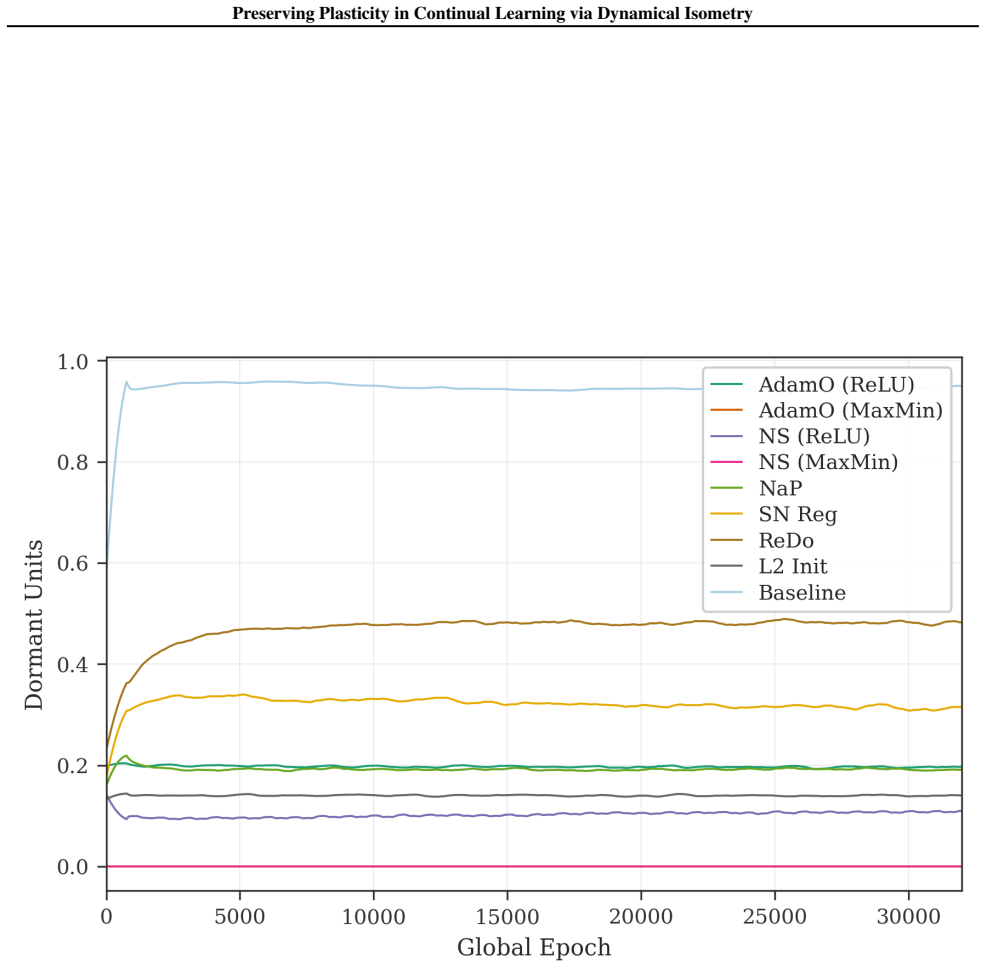
This provides direct empirical support for the revival mechanism discussed in Section 4.3
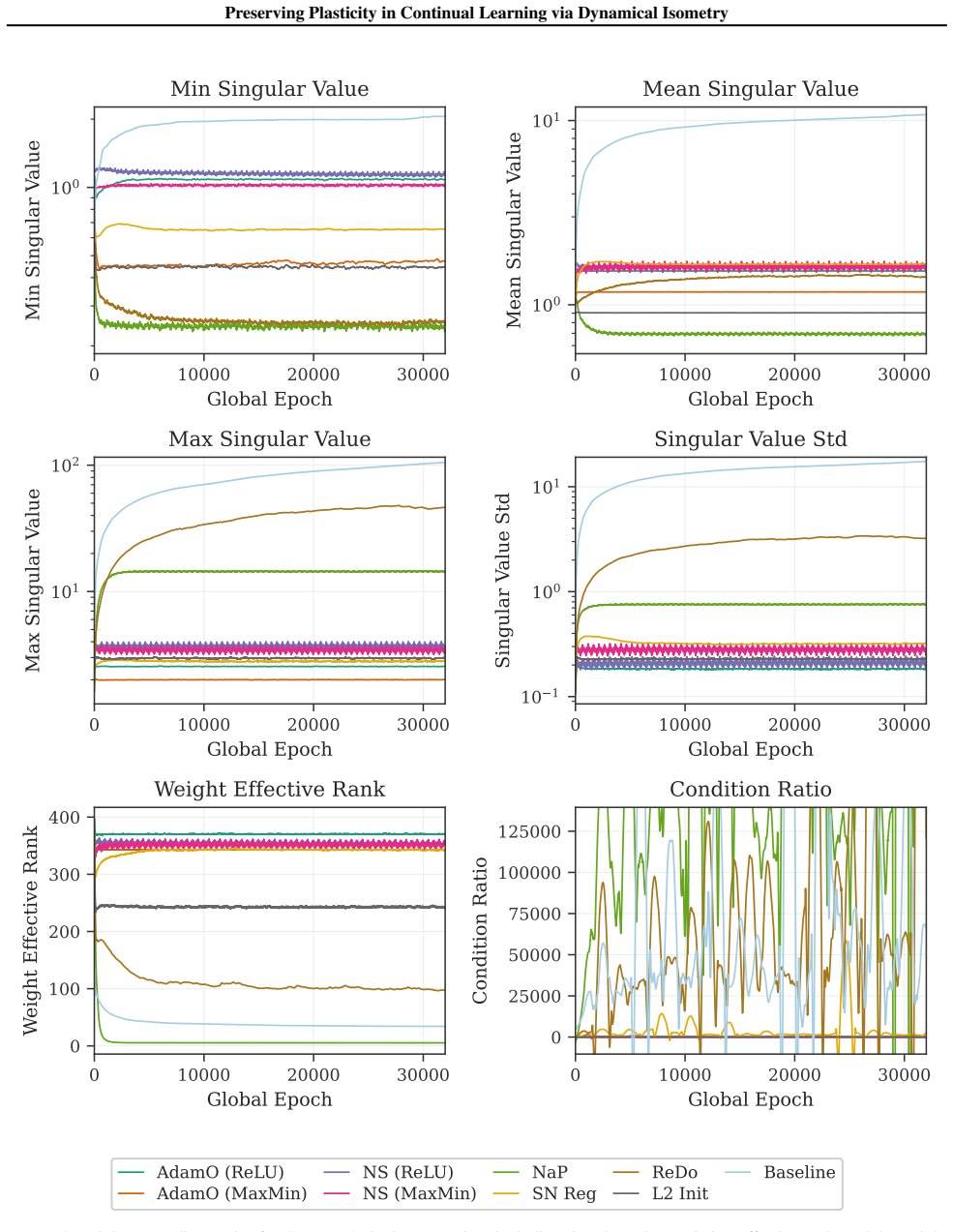
The figure tracks how the number of Sokar-style dormant ReLU units evolves during training, and highlights that the isometry- preserving methods substantially reduce or reverse the buildup of inactive features relative to the baselines. This provides direct empirical support for the revival mechanism discussed in Section 4.3. B.5. Minatar The RL diagnosti...
2048
-
[19]
Octax We consider the environemnts ”brix”, ”submarine”, ”filter”, ”tank”, ”blinky”, ”missile”, ”ufo”, ”wipeoff” in this sequence for 3 cycles with 5 million training steps per env
B.6. Octax We consider the environemnts ”brix”, ”submarine”, ”filter”, ”tank”, ”blinky”, ”missile”, ”ufo”, ”wipeoff” in this sequence for 3 cycles with 5 million training steps per env. We utilise PPO with shared backbone following the implementation provided in (Radji et al., 2025). A precise list of our hyperparameters is given in table
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.