Deep Slice Interpolation for Reducing Through-Plane Anisotropy and Noise in Head CT
Pith reviewed 2026-06-27 14:56 UTC · model grok-4.3
The pith
A deep learning system synthesizes intermediate CT slices to reduce through-plane anisotropy while adding implicit denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
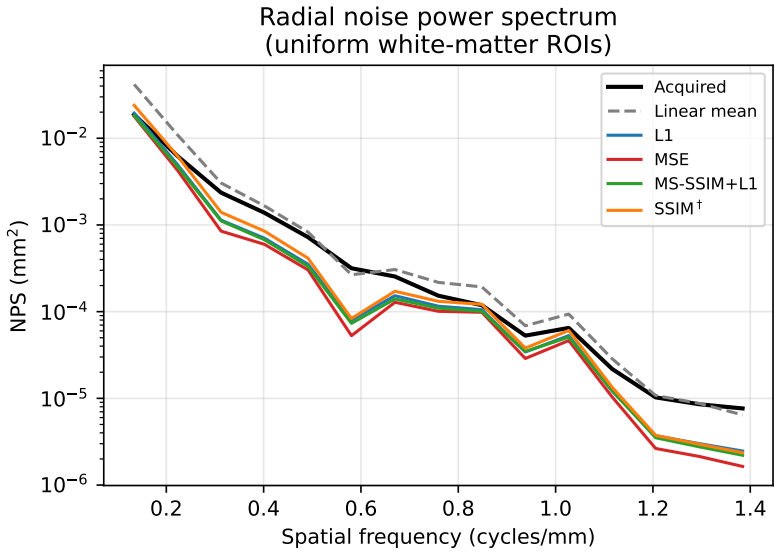
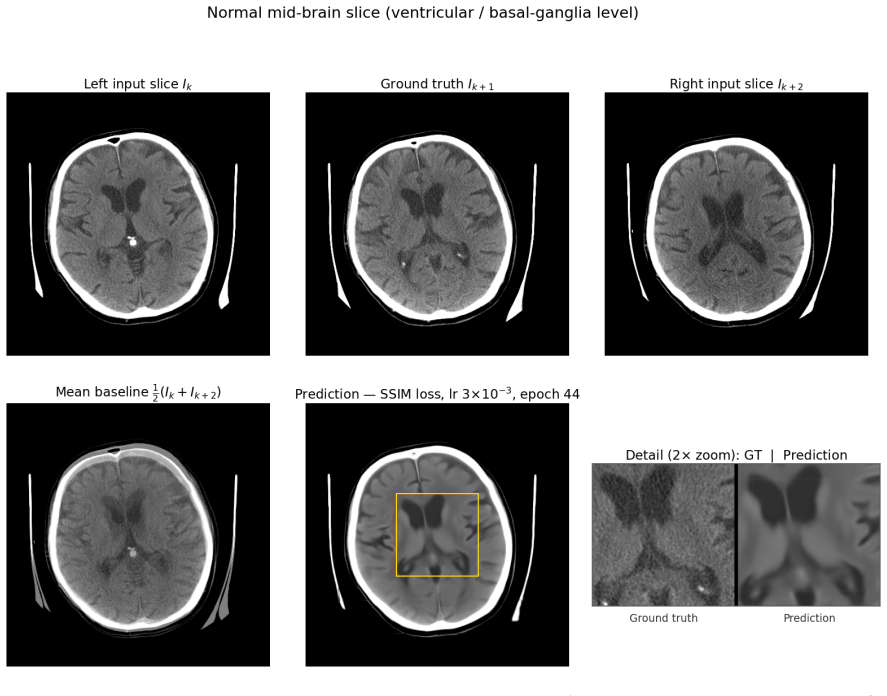
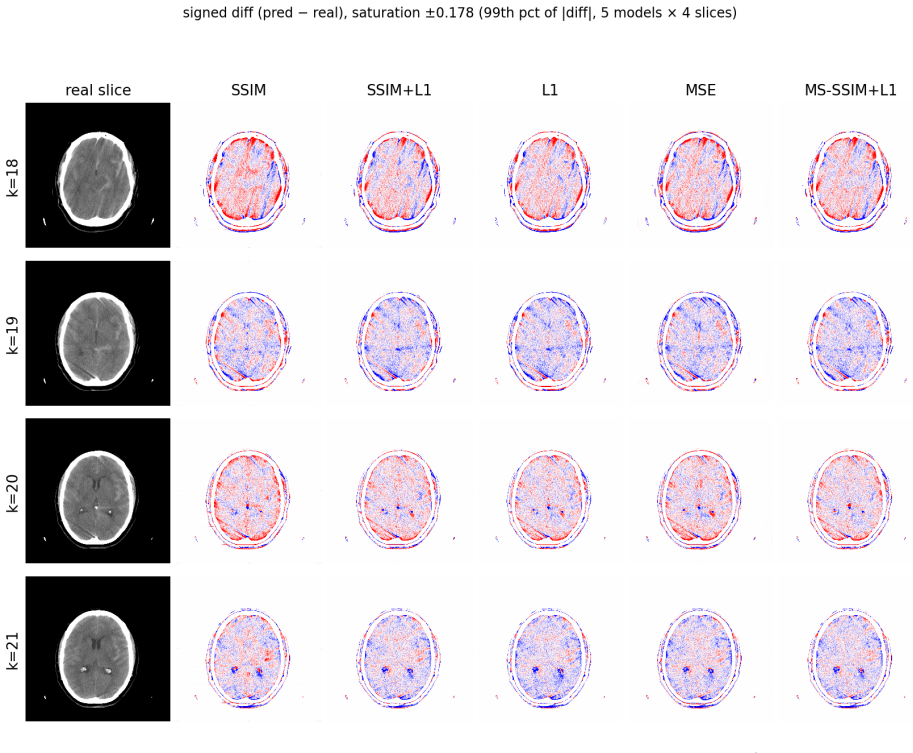
The system takes pairs of neighboring axial slices and outputs synthesized intermediate slices that halve effective through-plane spacing. All trained models surpass classical baselines and pretrained video interpolation networks on structural measures, with the MS-SSIM plus L1 combination giving the strongest overall profile. On an external head CT series the model reproduces the implicit denoising behavior predicted by the referenced theoretical analysis, indicating that both interpolation quality and the denoising side-effect are not limited to the training distribution.
What carries the argument
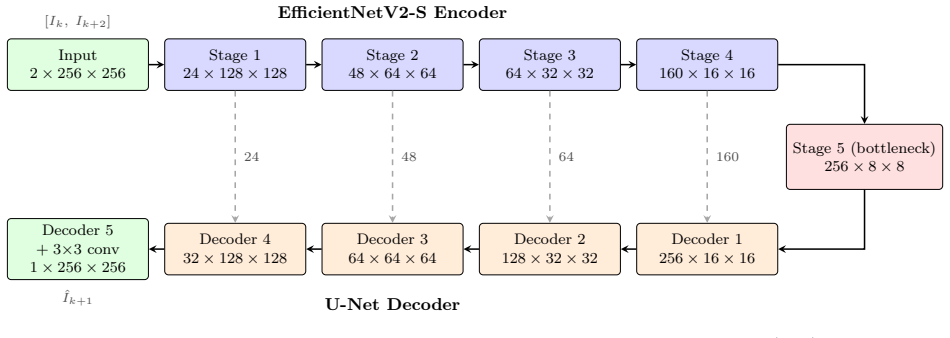
A convolutional network trained end-to-end with hybrid pixel-wise and multi-scale structural similarity losses to perform slice interpolation on anisotropic CT volumes.
If this is right
- Multiplanar reformats and 3D visualizations gain resolution without additional scanning.
- Volumetric measurements such as hematoma volume become more precise because voxel isotropy improves.
- Downstream algorithms that expect near-isotropic input receive higher-quality data from the same acquisition.
- Denoising occurs automatically during interpolation, removing the need for a separate noise-reduction step.
- Patient-level bootstrap intervals and paired tests confirm the measured gains over baselines.
Where Pith is reading between the lines
- The same architecture could be retrained on other anisotropic modalities such as certain MRI protocols to reduce slice spacing.
- Routine clinical pipelines might adopt the method to improve existing low-dose or thick-slice acquisitions rather than increasing radiation exposure.
- Larger external validation sets would be needed to confirm whether the single-case denoising observation scales to routine practice.
- The documented instability of SSIM-family losses at small batch sizes points to a practical constraint for deployment on limited hardware.
Load-bearing premise
The implicit denoising and generalization seen on one external case will hold across wider clinical populations and scanner types.
What would settle it
Quantitative comparison of hematoma volume estimates computed from original versus interpolated volumes on a multi-center test set of head CT scans with known ground-truth volumes.
Figures
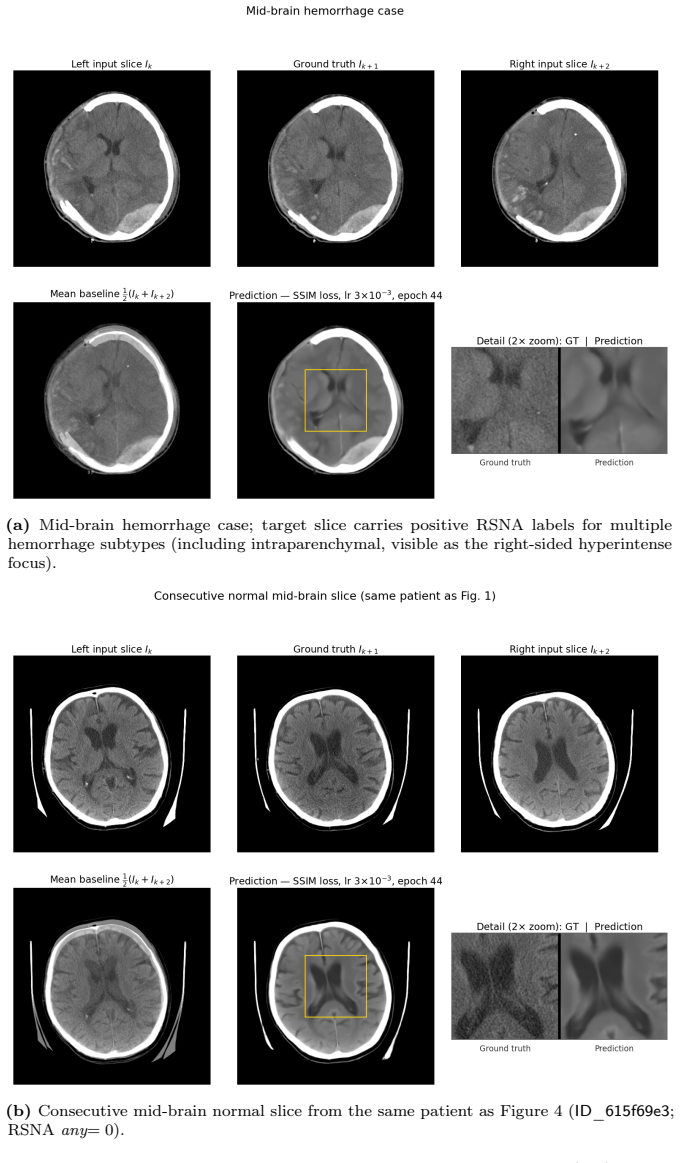
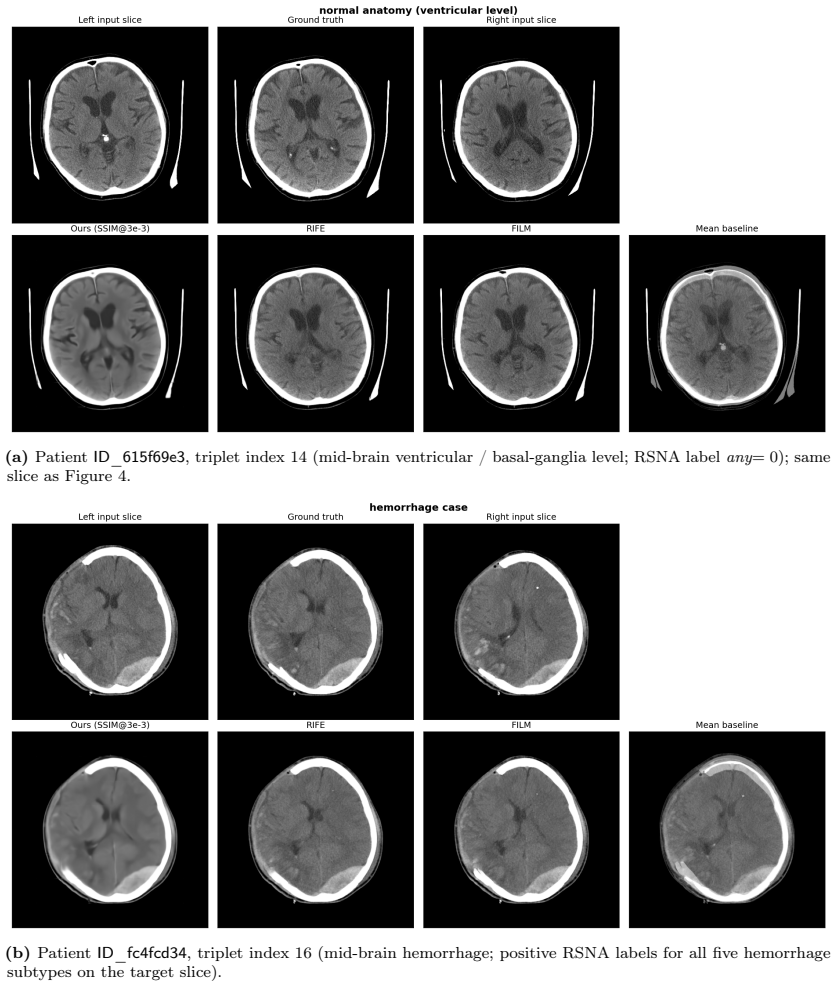
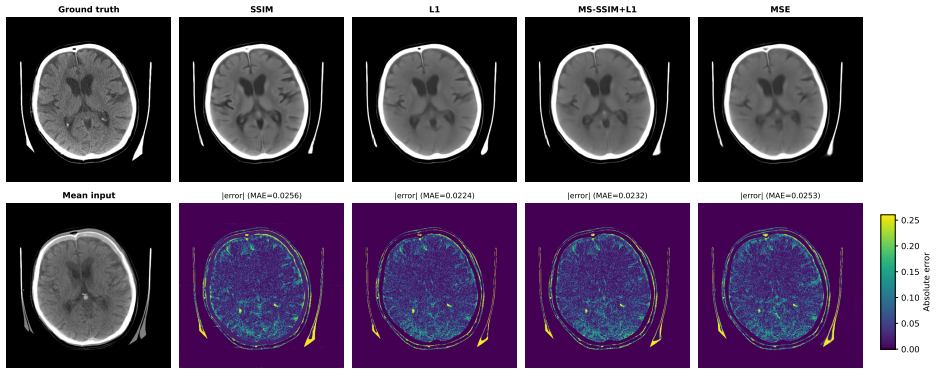

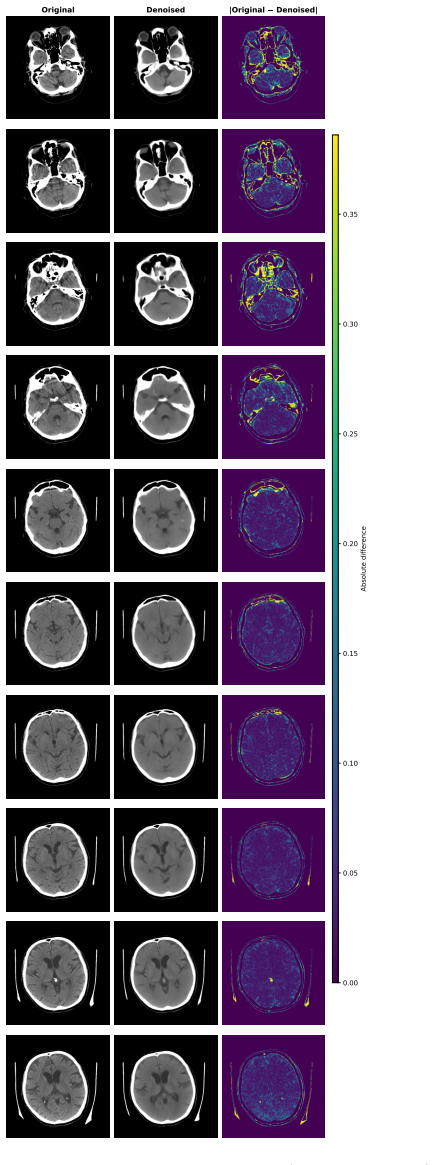

read the original abstract
Head computed tomography (CT) typically uses sub-millimeter in-plane resolution but 2-5 mm through-plane spacing, creating substantial anisotropy that degrades multiplanar reconstructions, volumetric measurements such as hematoma volume estimation, and downstream algorithms that assume near-isotropic voxels. We present a deep learning system that synthesizes intermediate CT slices from pairs of neighboring axial slices, halving the effective through-plane spacing. The system improves three-dimensional visualization while simultaneously producing inherently denoised outputs, yielding two complementary benefits from a single inference pass. To build a reliable system, we systematically evaluate pixel-wise losses, namely mean squared error (MSE) and mean absolute error (L1); structural-similarity losses, namely the structural similarity index (SSIM) and its multi-scale variant (MS-SSIM); and hybrid combinations. On a held-out test set, all converged models outperform classical interpolation baselines and pretrained video frame interpolation methods (RIFE, FILM) on all structural measures, with MS-SSIM+L1 offering the strongest balanced profile. We also document training instability in SSIM-family losses and identify partial remedies: the standard numerical fixes eliminate the dominant failure mode but leave residual divergence at smaller batch sizes. All results are reported with patient-level bootstrap confidence intervals and paired statistical tests. As an illustration, we apply the system to an out-of-distribution head CT series from Hospital Universitario Virgen del Roc\'io: the model synthesizes intermediate slices and exhibits on the real slices the implicit-denoising signature predicted by our theoretical analysis, supporting in a single external case that interpolation quality and implicit denoising are not confined to the training distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a deep learning system to synthesize intermediate axial slices in head CT scans, halving through-plane spacing to mitigate anisotropy. It systematically compares pixel-wise (MSE, L1) and structural (SSIM, MS-SSIM) losses plus hybrids, reporting that all converged models outperform classical interpolation and pretrained video methods (RIFE, FILM) on held-out test data across structural metrics, with MS-SSIM+L1 strongest. Results include patient-level bootstrap CIs and paired tests. An out-of-distribution external case from Hospital Universitario Virgen del Rocío is used to illustrate implicit denoising consistent with a referenced theoretical analysis.
Significance. If the held-out performance claims hold, the work targets a practical clinical limitation in CT by improving multiplanar reformats, volumetric estimates, and downstream isotropic-assuming algorithms, while offering incidental denoising as a byproduct. The systematic loss-function ablation and use of patient-level bootstrap confidence intervals with paired statistical tests are explicit strengths that enhance credibility of the outperformance results over baselines.
major comments (1)
- [Abstract] Abstract (final paragraph): the assertion that results on the single external OOD series 'support... that interpolation quality and implicit denoising are not confined to the training distribution' rests on one case exhibiting the predicted signature; this is insufficient to underwrite the generalization claim without additional OOD series or quantitative metrics comparing synthesized vs. real slices on that data.
minor comments (2)
- [Abstract] Abstract: model architecture, training protocol, and dataset sizes (train/validation/test split) are omitted, which limits immediate verification of the central performance claims even though statistical reporting is present.
- [Abstract] Abstract: the phrase 'Roc\'io' contains a LaTeX escape artifact and should render as 'Rocío'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the assertion that results on the single external OOD series 'support... that interpolation quality and implicit denoising are not confined to the training distribution' rests on one case exhibiting the predicted signature; this is insufficient to underwrite the generalization claim without additional OOD series or quantitative metrics comparing synthesized vs. real slices on that data.
Authors: We agree that a single external case constitutes an illustration rather than robust evidence for generalization. We will revise the abstract to describe the OOD example as an illustration of the predicted implicit-denoising signature on out-of-distribution data, removing the phrasing that it 'supports' the claim that these properties are not confined to the training distribution. The revised text will emphasize the illustrative purpose without overstating generalizability. revision: yes
Circularity Check
No circularity: empirical results on held-out and external data are independent of training inputs
full rationale
The paper reports model performance via standard held-out test-set metrics and one external OOD series, with no equations, fitted parameters, or self-citations that reduce any claimed prediction or denoising signature to the training data by construction. The referenced theoretical analysis is invoked only to interpret the single external observation and does not serve as a load-bearing derivation for the quantitative outperformance results.
Axiom & Free-Parameter Ledger
free parameters (1)
- hybrid loss weights
axioms (1)
- domain assumption Convolutional networks trained on paired neighboring slices can synthesize plausible intermediate medical images.
Reference graph
Works this paper leans on
-
[1]
Adam E. Flanders, Luciano M. Prevedello, George Shih, Safwan S. Halabi, Jayashree Kalpathy-Cramer, Robyn Ball, John T. Mongan, Anouk Stein, Felipe C. Kitamura, Matthew P. Lungren, Gagandeep Choudhary, Lesley Cala, Luiz Coelho, Monique Mogensen, Fanny Morón, Elka Miller, Ichiro Ikuta, Vahe Zohrabian, Olivia McDonnell, Christie Lincoln, Lubdha Shah, David J...
-
[2]
Deep learning applied to intracranial hemorrhage detection.Journal of Imaging, 9(2),
Luis Cortés-Ferre, Miguel Angel Gutiérrez-Naranjo, Juan José Egea-Guerrero, Soledad Pérez-Sánchez, and Marcin Balcerzyk. Deep learning applied to intracranial hemorrhage detection.Journal of Imaging, 9(2),
-
[3]
ISSN 2313-433X. doi:10.3390/jimaging9020037. URLhttps://www.mdpi.com/2313-433X/9/2/37
-
[4]
Real-time intermediate flow estimation for video frame interpolation
Zhewei Huang, Tianyuan Zhang, Wen Heng, Boxin Shi, and Shuchang Zhou. Real-time intermediate flow estimation for video frame interpolation. In Shai Avidan, Gabriel Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision – ECCV 2022, pages 624–642, Cham, 2022. Springer Nature Switzerland. ISBN 978-3-031-19781-9
2022
-
[5]
Film: Frame interpolation for large motion
Fitsum Reda, Janne Kontkanen, Eric Tabellion, Deqing Sun, Caroline Pantofaru, and Brian Curless. Film: Frame interpolation for large motion. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[6]
Bishop.Pattern Recognition and Machine Learning by Christopher M
C.M. Bishop.Pattern Recognition and Machine Learning by Christopher M. Bishop. Springer Sci- ence+Business Media, LLC, 2006. URLhttps://books.google.es/books?id=Y44SyAEACAAJ
2006
-
[7]
Hastie, R
T. Hastie, R. Tibshirani, and J. Friedman.The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. Springer Series in Statistics. Springer New York, 2009. ISBN 9780387848587. URLhttps://books.google.es/books?id=tVIjmNS3Ob8C
2009
-
[8]
Noise2Noise: Learning image restoration without clean data
Jaakko Lehtinen, Jacob Munkberg, Jon Hasselgren, Samuli Laine, Tero Karras, Miika Aittala, and Timo Aila. Noise2Noise: Learning image restoration without clean data. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 2965–2974. PMLR, 1...
2018
-
[9]
T.M. Lehmann, C. Gonner, and K. Spitzer. Survey: interpolation methods in medical image processing. IEEE Transactions on Medical Imaging, 18(11):1049–1075, 1999. doi:10.1109/42.816070
-
[10]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Cheng Peng, Wei-An Lin, Haofu Liao, Rama Chellappa, and S. Kevin Zhou. Saint: Spatially aware interpolation network for medical slice synthesis. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7747–7756, 2020. doi:10.1109/CVPR42600.2020.00777
-
[11]
Yuhua Chen, Yibin Xie, Zhengwei Zhou, Feng Shi, Anthony G. Christodoulou, and Debiao Li. Brain mri super resolution using 3d deep densely connected neural networks. In2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), pages 739–742, 2018. doi:10.1109/ISBI.2018.8363679
-
[12]
Can Zhao, Blake E. Dewey, Dzung L. Pham, Peter A. Calabresi, Daniel S. Reich, and Jerry L. Prince. Smore: A self-supervised anti-aliasing and super-resolution algorithm for mri using deep learning.IEEE Transactions on Medical Imaging, 40(3):805–817, 2021. doi:10.1109/TMI.2020.3037187
-
[13]
I³net: Inter-intra-slice interpolation network for medical slice synthesis.IEEE Transactions on Medical Imaging, 43:3306–3318, 2024
Haofei Song, Xintian Mao, Jing Yu, Qingli Li, and Yan Wang. I³net: Inter-intra-slice interpolation network for medical slice synthesis.IEEE Transactions on Medical Imaging, 43:3306–3318, 2024. URL https://api.semanticscholar.org/CorpusID:269407969
2024
-
[14]
Adacof: Adaptive collaboration of flows for video frame interpolation
Hyeongmin Lee, Taeoh Kim, Tae young Chung, Daehyun Pak, Yuseok Ban, and Sangyoun Lee. Adacof: Adaptive collaboration of flows for video frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[15]
Coleman, Paddy Gilligan, and Stefano Sanvito
Laura Gambini, Cian Gabbett, Luke Doolan, Lewys Jones, Jonathan N. Coleman, Paddy Gilligan, and Stefano Sanvito. Video frame interpolation neural network for 3d tomography across different length scales.Nature Communications, 15(1):7962, Sep 2024. ISSN 2041-1723. doi:10.1038/s41467-024-52260-2. URLhttps://doi.org/10.1038/s41467-024-52260-2
-
[16]
Data-efficient unsupervised interpolation without any intermediate frame for 4d medical images, 2024
JungEun Kim, Hangyul Yoon, Geondo Park, Kyungsu Kim, and Eunho Yang. Data-efficient unsupervised interpolation without any intermediate frame for 4d medical images, 2024. URLhttps://arxiv.org/ abs/2404.01464. 34
arXiv 2024
-
[17]
Muhammad Sarmad, Leonardo Carlos Ruspini, and Frank Lindseth. Sit-sr 3d: Self-supervised slice interpolation via transfer learning for 3d volume super-resolution.Pattern Recognition Letters, 166: 97–104, 2023. ISSN 0167-8655. doi:https://doi.org/10.1016/j.patrec.2023.01.008. URLhttps://www. sciencedirect.com/science/article/pii/S0167865523000144
-
[18]
2025.Approaches to Automated NACE Coding of German Business Activity Descriptions
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, volume 9351 ofLecture Notes in Computer Science, pages 234–241. Springer, 2015. doi:10.1007/978-3- 319-24574-4_28
-
[19]
Segmentation models pytorch.https://github.com/qubvel/segmentation_models
Pavel Iakubovskii. Segmentation models pytorch.https://github.com/qubvel/segmentation_models. pytorch, 2019
2019
-
[20]
Mingxing Tan and Quoc V. Le. Efficientnetv2: Smaller models and faster training. InInternational Con- ference on Machine Learning, 2021. URLhttps://api.semanticscholar.org/CorpusID:232478903
2021
-
[21]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5967–5976, 2017. doi:10.1109/CVPR.2017.632
-
[22]
Loss functions for image restoration with neural networks.IEEE Transactions on Computational Imaging, 3:47–57, 2017
Hang Zhao, Orazio Gallo, Iuri Frosio, and Jan Kautz. Loss functions for image restoration with neural networks.IEEE Transactions on Computational Imaging, 3:47–57, 2017. URLhttps://api. semanticscholar.org/CorpusID:5334482
2017
-
[23]
IEEE Transactions on Image Processing 13(4), 600–612 (Apr 2004)
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from er- ror visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004. doi:10.1109/TIP.2003.819861
-
[24]
Z. Wang, E.P. Simoncelli, and A.C. Bovik. Multiscale structural similarity for image quality assessment. InThe Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pages 1398–1402 Vol.2, 2003. doi:10.1109/ACSSC.2003.1292216
-
[25]
Sergey Kastryulin, Jamil Zakirov, Denis Prokopenko, and Dmitry V. Dylov. Pytorch image quality: Metrics for image quality assessment, 2022. URLhttps://arxiv.org/abs/2208.14818
arXiv 2022
-
[26]
Tizabi, Michael Baumgartner, Matthias Eisenmann, Doreen Heckmann- Nötzel, A
Annika Reinke, Minu D. Tizabi, Michael Baumgartner, Matthias Eisenmann, Doreen Heckmann- Nötzel, A. Emre Kavur, Tim Rädsch, Carole H. Sudre, Laura Acion, Michela Antonelli, Tal Arbel, Spyridon Bakas, Arriel Benis, Florian Buettner, M. Jorge Cardoso, Veronika Cheplygina, Jianxu Chen, Evangelia Christodoulou, Beth A. Cimini, Keyvan Farahani, Luciana Ferrer,...
-
[27]
Hongchi Chen, Qiuxia Li, Lazhen Zhou, and Fangzuo Li. Deep learning-based algorithms for low- dose ct imaging: A review.European Journal of Radiology, 172:111355, 2024. ISSN 0720-048X. doi:https://doi.org/10.1016/j.ejrad.2024.111355. URL https://www.sciencedirect.com/science/ article/pii/S0720048X24000718
-
[28]
Trzasko, Natalia Khaylova, James M
Armando Manduca, Lifeng Yu, Joshua D. Trzasko, Natalia Khaylova, James M. Kofler, Cynthia M. McCollough, and Joel G. Fletcher. Projection space denoising with bilateral filtering and ct noise modeling 35 for dose reduction in ct.Medical Physics, 36(11):4911–4919, 2009. doi:https://doi.org/10.1118/1.3232004. URLhttps://aapm.onlinelibrary.wiley.com/doi/abs/...
-
[29]
Reducing CT radiation dose with iterative reconstruction algorithms: the influence of scan and reconstruction parameters on image quality and CTDIvol.Eur
Thorsten Klink, Verena Obmann, Johannes Heverhagen, Alexander Stork, Gerhard Adam, and Philipp Begemann. Reducing CT radiation dose with iterative reconstruction algorithms: the influence of scan and reconstruction parameters on image quality and CTDIvol.Eur. J. Radiol., 83(9):1645–1654, September 2014
2014
-
[30]
Low-dose CT with a residual encoder-decoder convolutional neural network.IEEE Trans
Hu Chen, Yi Zhang, Mannudeep K Kalra, Feng Lin, Yang Chen, Peixi Liao, Jiliu Zhou, and Ge Wang. Low-dose CT with a residual encoder-decoder convolutional neural network.IEEE Trans. Med. Imaging, 36(12):2524–2535, December 2017
2017
-
[31]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1026–1034, 2015. doi:10.1109/ICCV.2015.123
-
[32]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS), volume 9, pages 249–256, 2010
2010
-
[33]
Claude E. Duchon. Lanczos filtering in one and two dimensions.Journal of Applied Meteorology, 18(8): 1016–1022, 1979. doi:10.1175/1520-0450(1979)018<1016:LFIOAT>2.0.CO;2
-
[34]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[35]
B. Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979. URLhttp://www.jstor.org/stable/2958830. Full publication date: Jan., 1979
arXiv 1979
-
[36]
Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83, 1945
Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics Bulletin, 1(6):80–83, 1945. URLhttps://api.semanticscholar.org/CorpusID:53662922
1945
-
[37]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: A practical and powerful approachtomultipletesting.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289– 300, 1995. doi:https://doi.org/10.1111/j.2517-6161.1995.tb02031.x. URLhttps://rss.onlinelibrary. wiley.com/doi/abs/10.1111/j.2517-6161.1995.tb02031.x
-
[38]
H. B. Mann and D. R. Whitney. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other.The Annals of Mathematical Statistics, 18(1):50 – 60, 1947. doi:10.1214/aoms/1177730491. URLhttps://doi.org/10.1214/aoms/1177730491
-
[39]
J. L. Hodges Jr. and E. L. Lehmann. Estimates of Location Based on Rank Tests.The Annals of Mathematical Statistics, 34(2):598 – 611, 1963. doi:10.1214/aoms/1177704172. URLhttps://doi.org/ 10.1214/aoms/1177704172
-
[40]
The simple difference formula: An approach to teaching nonparametric correlation
Dave Kerby. The simple difference formula: An approach to teaching nonparametric correlation. Comprehensive Psychology, 3, 01 2014. doi:10.2466/11.IT.3.1. 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.