Compiling Rewrite Rules to Finite-State Transducers with the Worsening Trick
Pith reviewed 2026-06-27 13:53 UTC · model grok-4.3
The pith
The worsening trick compiles general rewrite rules into finite-state transducers using short and uniform formulas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By generating all legal rewrite candidates and filtering out those that are worse than another candidate for the same input, the worsening trick yields compact transducers for general rewrite rules that correctly implement the intended semantics for arbitrary regular languages in A, B, L, and R.
What carries the argument
The worsening trick, which filters rewrite candidates using a total order on 'worse' to select the correct outputs.
If this is right
- The construction supports multiple contexts, arbitrary transductions, markup, directed rewriting, weights, and parallel rewriting.
- The resulting formulas are short and uniform.
- The transducers match those produced by earlier marker-based methods where the semantics coincide.
- The method has been validated to produce matching results on collections of rewrite grammars and regression tests covering major modalities.
Where Pith is reading between the lines
- This approach may allow for more straightforward extensions to new rewrite modalities without complex adjustments to compositions.
- The uniform nature of the formulas could facilitate formal proofs of correctness for rewrite semantics.
- Applications in natural language processing might benefit from easier integration of weighted rewrite rules.
Load-bearing premise
Filtering candidates by a total order on which is worse correctly implements the rewrite semantics without introducing or omitting rewrites in overlapping or context-sensitive cases.
What would settle it
A comparison of the input-output mappings accepted by the worsening-based transducer versus a marker-based transducer on a rule with overlapping possible match positions would show a difference if the method fails.
Figures

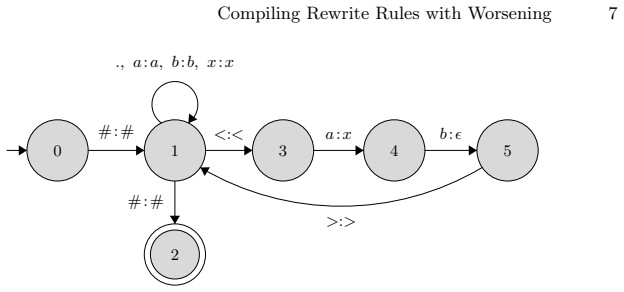


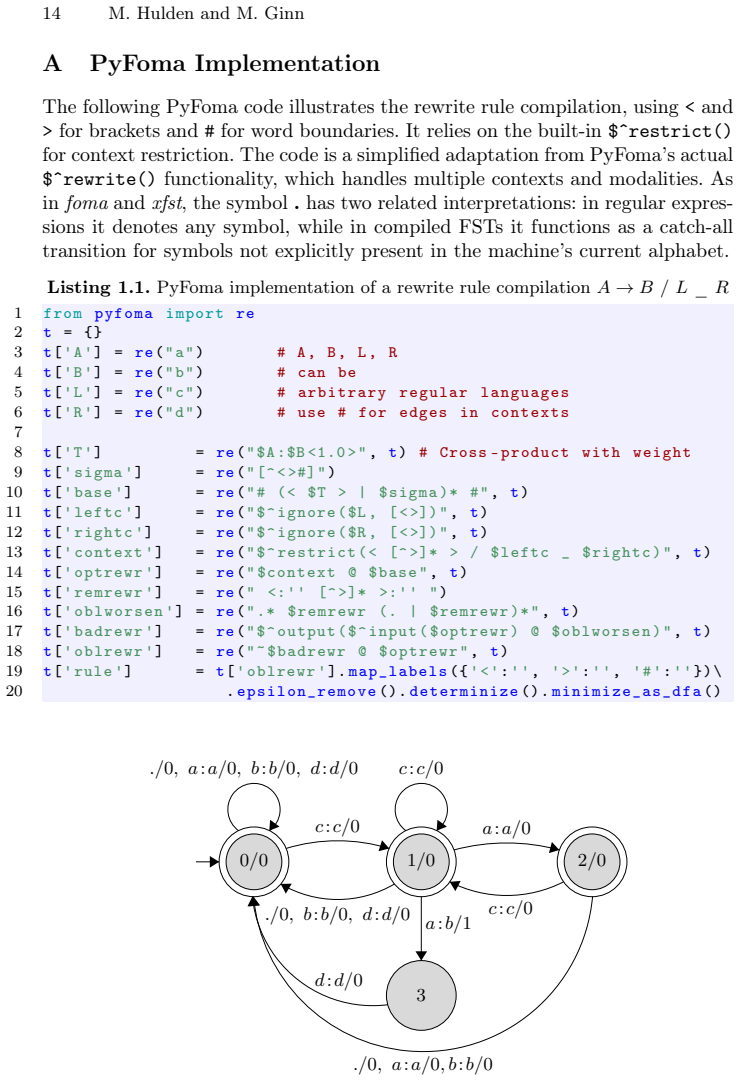

read the original abstract
Finite-state transducers (FSTs) are essential for modeling string rewriting in computational linguistics and natural language processing (NLP), particularly for phonological and morphological rewrite rules. Compiling general rewrite rules of the form $A \to B / L \, \_ \, R$, where $A$, $B$, $L$, and $R$ are arbitrary regular languages, is complex due to overlapping matches and context constraints. Traditional methods, such as those by Kaplan and Kay or Karttunen, rely on intricate transducer compositions with auxiliary markers. This paper presents a compact compilation scheme based on the "worsening trick'': generate all legal rewrite candidates, then filter candidates that are worse than another candidate for the same input. Implemented as the built-in rewrite compiler in PyFoma, the construction supports multiple contexts, arbitrary transductions, markup, directed rewriting, weights, and parallel rewriting. The resulting formulas are short and uniform, and where semantics coincide, they reproduce the same rule transducers as earlier approaches while remaining easier to extend. The implementation has been validated against foma on both a substantial collection of rewrite grammars and an automated regression suite covering the major rewrite modalities, with the resulting transducers matching exactly apart from state numbering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 'worsening trick' for compiling general rewrite rules A o B / L _ R (with A, B, L, R regular) into finite-state transducers. The method generates all legal rewrite candidates for an input and filters those that are worse than another candidate under a total order; the resulting transducers are claimed to be short and uniform, to support multiple contexts, arbitrary transductions, markup, directed rewriting, weights, and parallel rewriting, and to reproduce the transducers of Kaplan-Kay and Karttunen constructions wherever the semantics coincide. The construction is implemented in PyFoma and validated by exact transducer match (apart from state numbering) against foma on a substantial grammar collection plus an automated regression suite covering overlapping matches and multiple contexts.
Significance. If the central filtering step is correct, the approach supplies a compact, uniform algorithmic procedure that avoids intricate marker compositions and is easier to extend to the listed modalities. The external validation against foma on a broad test suite directly addresses the correctness of the total order for the supported cases and constitutes a reproducible empirical check.
major comments (2)
- [§4] §4 (Worsening Trick construction): the total order used to define 'worse' candidates is described algorithmically but lacks an explicit inductive argument or edge-case enumeration showing that it never omits a rewrite or introduces a spurious one for overlapping matches; the empirical match with foma is strong but does not substitute for such an argument when the claim is that the method is semantically equivalent wherever prior constructions apply.
- [§5] §5 (Validation): the regression suite is reported to cover 'major modalities' including overlapping matches, yet the paper does not list the precise set of test grammars or the coverage metric for context-interaction cases; without this, it is difficult to assess whether the validation fully exercises the weakest assumption identified in the construction.
minor comments (3)
- [Abstract] The abstract states that formulas are 'short and uniform' but does not exhibit the concrete transducer expressions; placing one or two representative formulas (with the worsening filter) in the abstract or introduction would make the central contribution immediately visible.
- [§4] Notation for the total order on candidates is introduced without a dedicated definition environment; a numbered definition would improve readability when the order is referenced in later sections.
- [§6] The paper mentions support for weights and parallel rewriting but does not show how the worsening order interacts with weighted transducers; a brief remark or example would clarify the extension.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive assessment, and constructive comments on our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [§4] §4 (Worsening Trick construction): the total order used to define 'worse' candidates is described algorithmically but lacks an explicit inductive argument or edge-case enumeration showing that it never omits a rewrite or introduces a spurious one for overlapping matches; the empirical match with foma is strong but does not substitute for such an argument when the claim is that the method is semantically equivalent wherever prior constructions apply.
Authors: We agree that an explicit inductive argument and edge-case enumeration for overlapping matches would strengthen the theoretical justification of the total order. The manuscript currently emphasizes the empirical equivalence with foma (exact match apart from state numbering) on a broad suite as evidence of correctness where semantics coincide. In revision we will add a dedicated subsection providing an inductive argument that the filtering step neither omits valid rewrites nor introduces spurious ones, together with explicit enumeration of the principal overlapping-match cases. revision: yes
-
Referee: [§5] §5 (Validation): the regression suite is reported to cover 'major modalities' including overlapping matches, yet the paper does not list the precise set of test grammars or the coverage metric for context-interaction cases; without this, it is difficult to assess whether the validation fully exercises the weakest assumption identified in the construction.
Authors: We accept that greater specificity on the regression suite would improve reproducibility and allow readers to evaluate coverage of context-interaction cases. In the revised version we will append the complete list of test grammars used in the automated regression suite and report the coverage metrics for overlapping matches and multiple-context interactions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents the worsening trick as an explicit algorithmic procedure: enumerate candidate rewrites for a given input and retain only those that are minimal under a stated total order on 'worse' candidates. This construction is described directly in terms of regular-language operations and candidate filtering; no equation or central claim is shown to reduce by definition to a fitted parameter, a prior self-citation, or an imported uniqueness theorem. External validation against foma on regression suites supplies an independent check that the ordering reproduces the intended semantics. The derivation therefore remains self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Regular languages are closed under the operations needed to generate and filter rewrite candidates.
Reference graph
Works this paper leans on
-
[1]
In: Alegria, I., Hulden, M
Beesley, K.R.: Kleene, a free and open-source language for finite-state program- ming. In: Alegria, I., Hulden, M. (eds.) Proceedings of the 10th International Workshop on Finite State Methods and Natural Language Processing. pp. 50–
-
[2]
Association for Computational Linguistics, Donostia–San Sebastián (Jul 2012), https://aclanthology.org/W12-6209/
2012
-
[3]
CSLI Publications, Stan- ford (2003)
Beesley, K.R., Karttunen, L.: Finite-State Morphology. CSLI Publications, Stan- ford (2003)
2003
-
[4]
Harper and Row, New York (1968)
Chomsky, N., Halle, M.: The Sound Pattern of English. Harper and Row, New York (1968)
1968
-
[5]
In: Bel, N., Hinrichs, E., Osen- ova, P., Simov, K
Gerdemann, D.: Mix and match replacement rules. In: Bel, N., Hinrichs, E., Osen- ova, P., Simov, K. (eds.) Proceedings of the Workshop on Adaptation of Language Resources and Technology to New Domains. pp. 39–47. Association for Compu- tational Linguistics, Borovets, Bulgaria (Sep 2009),https://aclanthology.org/ W09-4106/
2009
-
[6]
In: Ale- gria, I., Hulden, M
Gerdemann, D., Hulden, M.: Practical finite state Optimality Theory. In: Ale- gria, I., Hulden, M. (eds.) Proceedings of the 10th International Workshop on Finite State Methods and Natural Language Processing. pp. 10–19. Associa- tion for Computational Linguistics, Donostia–San Sebastián (Jul 2012),https: //aclanthology.org/W12-6202/
2012
-
[7]
In: Eisner, J., Karttunen, L., Thèriault, A
Gerdemann, D., van Noord, G.: Approximation and exactness in finite state Op- timality Theory. In: Eisner, J., Karttunen, L., Thèriault, A. (eds.) Proceedings of the Fifth Workshop of the ACL Special Interest Group in Computational Phonol- ogy. pp. 34–45. International Committee on Computational Linguistics, Centre Universitaire, Luxembourg (Aug 2000),htt...
2000
-
[8]
Springer Nature (2022)
Gorman, K., Sproat, R.: Finite-state text processing. Springer Nature (2022)
2022
-
[9]
In: Kohavi, Z., Paz, A
Hopcroft, J.E.: An n log n algorithm for minimizing states in a finite automaton. In: Kohavi, Z., Paz, A. (eds.) Theory of Machines and Computations. pp. 189–196. Academic Press, New York (1971)
1971
-
[10]
Hulden, M.: Finite-State Machine Construction Methods and Algorithms for Phonology and Morphology. Ph.D. thesis, University of Arizona (2009)
2009
-
[11]
In: Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguis- tics: Demonstrations Session
Hulden, M.: Foma: A finite-state compiler and library. In: Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguis- tics: Demonstrations Session. pp. 29–32. Association for Computational Linguistics (2009)
2009
-
[12]
In: Piskorski, J., Watson, B., Yli-Jyrä, A
Hulden, M.: Regular expressions and predicate logic in finite-state language pro- cessing. In: Piskorski, J., Watson, B., Yli-Jyrä, A. (eds.) Finite-State Methods and Natural Language Processing: Post-Proceedings of the 7th International Workshop FSMNLP 2008, pp. 82–89. IOS Press (2009)
2008
-
[13]
Arxiv Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance
Hulden, M., Ginn, M., Silfverberg, M., Hammond, M.: PyFoma: a Python finite- state compiler module. In: Cao, Y., Feng, Y., Xiong, D. (eds.) Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 3: System Demonstrations). pp. 258–265. Association for Computational Lin- guistics, Bangkok, Thailand (Aug 2024).https...
-
[14]
Mouton, The Hague (1972)
Johnson, C.D.: Formal Aspects of Phonological Description. Mouton, The Hague (1972)
1972
-
[15]
Computa- tional Linguistics20(3), 331–378 (1994) Compiling Rewrite Rules with Worsening 17
Kaplan, R.M., Kay, M.: Regular models of phonological rule systems. Computa- tional Linguistics20(3), 331–378 (1994) Compiling Rewrite Rules with Worsening 17
1994
-
[16]
Routledge (2013)
Karlsson, F.: Finnish: An essential grammar. Routledge (2013)
2013
-
[17]
In: Proceedings of the 33rd Annual Meet- ing of the Association for Computational Linguistics
Karttunen, L.: The replace operator. In: Proceedings of the 33rd Annual Meet- ing of the Association for Computational Linguistics. pp. 16–23. Association for Computational Linguistics, Cambridge, MA (1995)
1995
-
[18]
In: Proceedings of the 34th Annual Meeting of the Association for Computational Linguistics
Karttunen, L.: Directed replacement. In: Proceedings of the 34th Annual Meeting of the Association for Computational Linguistics. pp. 108–115. Association for Computational Linguistics, Santa Cruz, CA (1996)
1996
-
[19]
In: Pro- ceedings of the 16th International Conference on Computational Linguistics (COL- ING’96)
Kempe, A., Karttunen, L.: Parallel replacement in finite-state calculus. In: Pro- ceedings of the 16th International Conference on Computational Linguistics (COL- ING’96). pp. 622–627. Copenhagen, Denmark (1996)
1996
-
[20]
In: Proceed- ings of the 34th Annual Meeting of the Association for Computational Linguistics
Mohri, M., Sproat, R.: An efficient compiler for weighted rewrite rules. In: Proceed- ings of the 34th Annual Meeting of the Association for Computational Linguistics. pp. 231–238. Association for Computational Linguistics, Santa Cruz, CA (1996)
1996
-
[21]
In: Gunawardena, J
Pin, J.E.: Tropical Semirings. In: Gunawardena, J. (ed.) Idempotency (Bristol, 1994), pp. 50–69. Publ. Newton Inst. 11, Cambridge Univ. Press, Cambridge (1998),https://hal.science/hal-00113779
1994
-
[22]
Vaillette, N.: Logical Specification of Finite-State Transductions for Natural Lan- guage Processing. Ph.D. thesis, Ohio State University (2004)
2004
-
[23]
In: Cleophas, L., Watson, B.W
Yli-Jyrä, A., Koskenniemi, K.: Compiling contextual restrictions on strings into finite-state automata. In: Cleophas, L., Watson, B.W. (eds.) The Eindhoven FASTAR Days, Proceedings. Technische Universiteit Eindhoven, Eindhoven, The Netherlands (2004)
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.