Linguistically Augmented Audio Speech Data (LinguAS)
Pith reviewed 2026-06-27 14:41 UTC · model grok-4.3
The pith
Augmenting audio deepfake datasets with five linguistic features improves detection model performance beyond ASVspoof 2021 baselines and models like HuBert and XLSR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
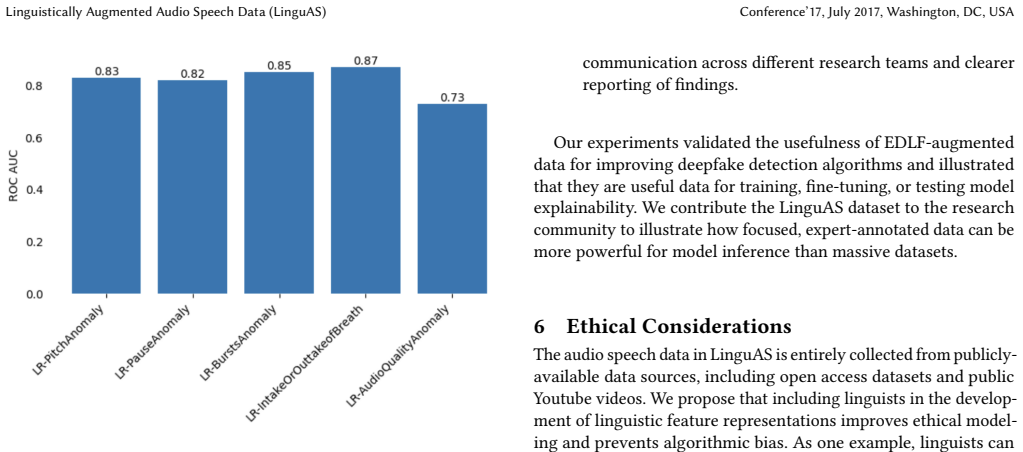
LinguAS augments genuine and spoofed audio samples with five Expert-Defined Linguistic Features (EDLFs) that occur frequently in spoken English and characterize natural human speech. When detection models are trained on data that includes these EDLF annotations, performance rises substantially above the ASVspoof 2021 deep learning baselines and SSL models such as HuBert and XLSR. The dataset maintains balance across four spoofed attack types and genuine samples while adding metadata on speaker gender and generator sources.
What carries the argument
The LinguAS dataset, which annotates each audio sample with five EDLFs to supply larger-timescale linguistic cues for training deepfake detectors.
If this is right
- Detection models gain accuracy by using linguistic cues at longer timescales in addition to frame-level audio features.
- The balanced collection of four attack types with gender and generator metadata supports more detailed evaluation of model behavior.
- Emphasizing traits of real human language improves the ability of models to flag malicious deepfakes.
Where Pith is reading between the lines
- Automating annotation of the five features could remove the need for manual labeling and allow much larger datasets.
- The same linguistic augmentation strategy might transfer to deepfake detection in video or text domains.
- Hybrid systems that combine EDLFs with existing self-supervised audio models could yield further robustness gains.
Load-bearing premise
The five linguistic features are reliably annotatable by experts and are the direct cause of the observed performance gains rather than other dataset properties such as sample balance or metadata.
What would settle it
Retrain the same detection models on the identical audio samples but without the EDLF annotations and measure whether accuracy falls back to baseline levels.
Figures



read the original abstract
Maliciously-created fake speech, including deepfaked and spoofed audio, is proliferating at an alarming rate, and detection models are racing to stay ahead of the curve. Yet, most detection models are trained to make inference on frame-level audio features alone without leveraging valuable linguistic cues at larger timescales. To address this gap, we present Linguistically Augmented Audio Speech Data (LinguAS), a dataset of genuine and deepfaked audio samples annotated with five strategically-chosen, Expert-Defined Linguistic Features (EDLFs) that occur frequently in spoken English and are characteristic of natural human speech. LinguAS contains over 800 audio samples, each of which are annotated with EDLFs. The dataset has a balanced number of four spoofed audio attack types and a proportionate number of genuine speech samples. We also include metadata on speaker gender and the generator/source for each spoofed audio sample, offering more granularity for model training. We found that models trained on data augmented with EDLFs had improved model performance significantly beyond the ASVspoof 2021 deep learning baselines and SSL models like HuBert and XLSR. LinguAS's augmented linguistic, gender, and generator metadata provide audio deepfake researchers with a dataset that emphasizes real human language traits to improve model inference of faked speech. Data and code are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the LinguAS dataset of over 800 genuine and deepfaked audio samples annotated with five Expert-Defined Linguistic Features (EDLFs) characteristic of natural spoken English. The dataset is balanced across four spoof attack types and supplies metadata on speaker gender and spoof generator. The central claim is that models trained on data augmented with these EDLFs achieve significantly improved performance over ASVspoof 2021 deep-learning baselines and SSL models such as HuBERT and XLSR.
Significance. If the performance gains can be rigorously demonstrated and attributed to the linguistic annotations, the dataset would supply a useful resource for incorporating longer-timescale linguistic cues into audio deepfake detection. The balanced attack distribution and auxiliary metadata are constructive design choices. The current absence of experimental evidence, however, prevents any assessment of whether these features deliver the claimed benefit.
major comments (2)
- [Abstract] Abstract: the assertion that 'models trained on data augmented with EDLFs had improved model performance significantly beyond the ASVspoof 2021 deep learning baselines and SSL models like HuBert and XLSR' is unsupported by any description of experimental protocol, model architectures, evaluation metrics, statistical tests, or ablation results.
- No ablation or control experiment is described that holds the balanced attack types and gender/generator metadata fixed while removing or randomizing only the EDLF annotations; therefore the performance delta cannot be attributed specifically to the linguistic features rather than the balancing or auxiliary metadata.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current version of the manuscript does not provide sufficient experimental details to support the performance claims, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'models trained on data augmented with EDLFs had improved model performance significantly beyond the ASVspoof 2021 deep learning baselines and SSL models like HuBert and XLSR' is unsupported by any description of experimental protocol, model architectures, evaluation metrics, statistical tests, or ablation results.
Authors: We acknowledge that the abstract asserts performance improvements without accompanying experimental details in the manuscript. In the revision we will add a dedicated Experiments section that specifies the model architectures, training and evaluation protocols, metrics (such as EER), statistical significance tests, and complete results tables comparing LinguAS-augmented models against the cited ASVspoof 2021 and SSL baselines. revision: yes
-
Referee: [—] No ablation or control experiment is described that holds the balanced attack types and gender/generator metadata fixed while removing or randomizing only the EDLF annotations; therefore the performance delta cannot be attributed specifically to the linguistic features rather than the balancing or auxiliary metadata.
Authors: We agree that an ablation isolating the contribution of the EDLFs is required to attribute gains specifically to the linguistic annotations rather than to dataset balancing or other metadata. The revised manuscript will include such controlled experiments, keeping attack-type balance and gender/generator metadata fixed while comparing models trained with versus without (or with randomized) EDLF annotations. revision: yes
Circularity Check
No circularity: empirical dataset contribution with external baselines
full rationale
The paper introduces LinguAS as an annotated dataset and reports empirical performance gains on external benchmarks (ASVspoof 2021, HuBERT, XLSR). No equations, fitted parameters, derivations, or first-principles results are present. No self-citations are used to justify load-bearing uniqueness claims or ansatzes. The central performance claim rests on comparisons to independent external models rather than any reduction to the paper's own inputs or annotations by construction. This is a standard empirical dataset paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EDLFs occur frequently in spoken English and are characteristic of natural human speech
invented entities (1)
-
Expert-Defined Linguistic Features (EDLFs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z. Akhtar, T. L. Pendyala, and V. S. Athmakuri. 2024. Video and Audio Deepfake Datasets and Open Issues in Deepfake Technology: Being Ahead of the Curve. Forensic Sciences4, 3 (2024), 289–377. doi:10.3390/forensicsci4030021
-
[2]
Almutairi and H
Z. Almutairi and H. Elgibreen. 2022. A review of modern audio deepfake detection methods: Challenges and future directions.Algorithms15, 5 (2022), 155
2022
-
[3]
L. Blue, K. Warren, H. Abdullah, C. Gibson, L. Vargas, J. O’Dell, K. Butler, and P. Traynor. 2022. Who are you (i really wanna know)? detecting audio DeepFakes through vocal tract reconstruction. In31st USENIX Security Symposium (USENIX Security 22). 2691–2708
2022
-
[4]
E. Chodroff and C. Wilson. 2014. Burst spectrum as a cue for the stop voicing contrast in American English.The Journal of the Acoustical Society of America 136, 5 (2014), 2762–2772. doi:10.1121/1.4896470
-
[5]
T. P. Doan, L. Nguyen-Vu, S. Jung, and K. Hong. 2023. Bts-e: Audio deepfake detection using breathing-talking-silence encoder. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 1–5
2023
-
[6]
S. Duanmu. 2007.The phonology of standard Chinese. Oxford University Press
2007
- [7]
-
[8]
Huang and C.-M
L. Huang and C.-M. Pun. 2019. Audio replay spoof attack detection using segment- based hybrid feature and DenseNetLSTM network. InICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2567–2571
2019
-
[9]
Iskarous and A
K. Iskarous and A. Vietti. 2025. Phonetic information in the vowel spectrum: the meaning of mel-Frequency Cepstral Coefficients.Journal of Phonetics112 (2025), 101434
2025
-
[10]
Ito and L
K. Ito and L. Johnson. 2017. The LJ speech dataset. (2017)
2017
-
[11]
S. A. Jun. 2005.Prosodic typology: the phonology of intonation and phrasing. Oxford University Press
2005
-
[12]
J. E. Kallay, U. Mayr, and M. A. Redford. 2019. Characterizing the coordination of speech production and breathing. InProceedings of the... International Congress of Phonetic Sciences, Vol. 2019. 1412
2019
-
[13]
Keaton, Zahra Khanjani, Christine Mallinson, and Vandana P
Ashley R. Keaton, Zahra Khanjani, Christine Mallinson, and Vandana P. Janeja. 2024. Linguistically Augmented Audio Speech Data (LinguAS) Dataset. https://figshare.com/projects/_b_Linguistically_Augmented_Audio_ Speech_Data_LinguAS_b_/206566. (2024). Data available at Figshare
2024
-
[14]
Keaton, Zahra Khanjani, Christine Mallinson, and Vandana P
Ashley R. Keaton, Zahra Khanjani, Christine Mallinson, and Vandana P. Janeja
-
[15]
https://doi.org/10.6084/m9.figshare.25909297
Linguistically Augmented Audio Speech Data (LinguAS), Direct link for Data frame and description. https://doi.org/10.6084/m9.figshare.25909297
-
[16]
Z. Khanjani, T. Ale, J. Wang, L. Davis, C. Mallinson, and V. Janeja. 2024. In- vestigating Causal Cues: Strengthening Spoofed Audio Detection with Human- Discernible Linguistic Features. (2024). arXiv:2409.06033 doi:arXiv:2409.06033
-
[17]
Khanjani, L
Z. Khanjani, L. Davis, A. Tuz, K. Nwosu, C. Mallinson, and V. P. Janeja. 2023. Learning to Listen and Listening to Learn: Spoofed Audio Detection Through Lin- guistic Data Augmentation. In2023 IEEE International Conference on Intelligence and Security Informatics (ISI). Charlotte, NC, USA, 01–06
2023
-
[18]
Keaton, Christine Mallinson, and Vandana P
Zahra Khanjani, Ashley R. Keaton, Christine Mallinson, and Vandana P. Janeja
-
[19]
https://github.com/MultiDataLab/LinguAS
LinguAS Code Repository. https://github.com/MultiDataLab/LinguAS. (2024). Source code available at GitHub
2024
-
[20]
Z. Khanjani, C. Mallinson, J. Foulds, and V. P. Janeja. 2024. ALDAS: Audio- Linguistic Data Augmentation for Spoofed Audio Detection.arXiv preprint arXiv:2410.15577(2024). arXiv:2410.15577 [cs.SD]
-
[21]
Khochare, C
J. Khochare, C. Joshi, B. Yenarkar, S. Suratkar, and F. Kazi. 2021. A deep learn- ing framework for audio deepfake detection.Arabian Journal for Science and Engineering(2021), 1–12
2021
-
[22]
Kim, S.-W
K.-W. Kim, S.-W. Park, J. Lee, and M.-C. Joe. 2022. Assem-vc: Realistic voice conversion by assembling modern speech synthesis techniques. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 6997–7001
2022
-
[23]
Kinnunen, M
T. Kinnunen, M. Sahidullah, H. Delgado, M. Todisco, N. Evans, J. Yamagishi, and K. A. Lee. 2017. The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection. InInterspeech 2017. ISCA, 26
2017
-
[24]
Koenecke, A
A. Koenecke, A. Nam, E. Lake, J. Nudell, M. Quartey, Z. Mengesha, others, and S. Goel. 2020. Racial disparities in automated speech recognition.Proceedings of the national academy of sciences117, 14 (2020), 7684–7689
2020
-
[25]
Kumar, R
K. Kumar, R. Kumar, T. de Boissière, L. Gestin, W. Z. Teoh, J. Sotelo, A. de Brébisson, Y. Bengio, and A. C. Courville. 2019. Melgan: Generative adversarial networks for conditional waveform synthesis. InAdvances in neural information processing systems 32
2019
-
[26]
C.-I. Lai, A. Abad, K. Richmond, J. Yamagishi, N. Dehak, and S. King. 2019. Atten- tive filtering networks for audio replay attack detection. InICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 6316–6320
2019
-
[27]
J. M. Martín-Doñas, A. Álvarez, E. Rosello, A. M. Gomez, and A. M. Peinado. 2024. Exploring Self-supervised Embeddings and Synthetic Data Augmentation for Robust Audio Deepfake Detection. InInterspeech 2024. 2085–2089. doi:10.21437/ Interspeech.2024-942
2024
-
[28]
Z. Mostaani and M.M. Doss. 2022. On Breathing Pattern Information in Synthetic Speech. InProc. Interspeech 2022. 2768–2772. doi:10.21437/Interspeech.2022-10271
- [29]
- [30]
-
[31]
Pindrop. 2025. Pindrop’s 2025 Voice Intelligence and Security Report Re- veals 1,300% Surge in Deepfake Fraud.PR Newswire(12 June 2025). https: //www.prnewswire.com/news-releases/pindrops-2025-voice-intelligence-- security-report-reveals-1-300-surge-in-deepfake-fraud-302479482.html
2025
-
[32]
Reimao and V
R. Reimao and V. Tzerpos. 2019. FoR: A dataset for synthetic speech detection. In2019 International Conference on Speech Technology and Human-Computer Dialogue (SpeD). 1–10
2019
-
[33]
Rochet-Capellan and S
A. Rochet-Capellan and S. Fuchs. 2014. Take a breath and take the turn: how breathing meets turns in spontaneous dialogue.Philosophical Transactions of the Royal Society B: Biological Sciences369, 1658 (2014). Pages: 20130399
2014
-
[34]
Sahidullah, T
M. Sahidullah, T. Kinnunen, and C. HanilÇi. [n. d.]. A comparison of features for synthetic speech detection. Year and conference details are missing from the reference text
-
[35]
Eliza Strickland. 2022. Andrew Ng, AI Minimalist: The Machine-Learning Pioneer Says Small Is the New Big.IEEE Spectrum59, 4 (2022), 22–50
2022
-
[36]
Valle, J
R. Valle, J. Li, R. Prenger, and B. Catanzaro. 2020. Mellotron: Multispeaker expressive voice synthesis by conditioning on rhythm, pitch and global style tokens. InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6189–6193
2020
-
[37]
WaveNet: A Generative Model for Raw Audio
A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, others, and K. Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.0349912, 1 (2016). arXiv:1609.03499 [cs.SD]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[38]
X. Wang and J. Yamagishi. 2021. A comparative study on recent neural spoofing countermeasures for synthetic speech detection.arXiv preprint arXiv:2103.11326 (2021). arXiv:2103.11326 [cs.SD]
-
[39]
J. R. Westbury and P. A. Keating. 1986. On the Naturalness of Stop Consonant Voic- ing.Journal of Linguistics22, 1 (1986), 145–166. doi:10.1017/s0022226700010598
-
[40]
Z. Wu, J. Yamagishi, T. Kinnunen, C. HanilÇi, M. Sahidullah, A. Sizov, N. Evans, M. Todisco, and H. Delgado. 2017. Asvspoof: the automatic speaker verification spoofing and countermeasures challenge.IEEE Journal of Selected Topics in Signal Processing11, 4 (2017), 588–604. Linguistically Augmented Audio Speech Data (LinguAS) Conference’17, July 2017, Wash...
2017
-
[41]
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, et al. 2021. Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection.arXiv preprint arXiv:2109.00537(2021). arXiv:2109.00537 [cs.SD]
-
[42]
Zhang, Z
K. Zhang, Z. Hua, R. Lan, Y. Zhang, and Y. Guo. 2025. Phoneme-Level Feature Discrepancies: A Key to Detecting Sophisticated Speech Deepfakes.Proceedings of the AAAI Conference on Artificial Intelligence39, 1 (2025), 1066–1074. doi:10. 1609/aaai.v39i1.32093 Conference’17, July 2017, Washington, DC, USA Keaton, Khanjani et al. Appendix A.1 Dataset Metadata ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.