SSL-GMMVC: Interpretable Voice Conversion via Locally Linear GMM Transforms in Self-Supervised Representation Space
Pith reviewed 2026-06-27 12:09 UTC · model grok-4.3
The pith
Voice conversion is done by fitting a Gaussian mixture to paired self-supervised features and applying posterior-weighted affine transforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SSL-GMMVC models paired source-target features extracted from self-supervised speech representations using a Gaussian mixture model and performs conversion as a posterior-weighted sum of affine transforms. This yields locally linear transformations that adapt to heterogeneous feature-space structure while remaining analytically tractable. Evaluations demonstrate improved speaker similarity with comparable intelligibility and naturalness, and a constrained covariance variant surpasses a deep learning baseline as the number of mixture components increases. Component selection corresponds to phonetic structure and the learned transforms reveal interpretable scaling and rotation.
What carries the argument
Posterior-weighted sum of affine transforms from a Gaussian mixture model fitted to paired self-supervised speech features
If this is right
- Speaker similarity improves while intelligibility and naturalness stay comparable to baselines.
- Even the constrained covariance version exceeds a deep learning baseline once the number of mixture components grows.
- Mixture components align with phonetic categories in the speech data.
- The learned affine transforms show distinct scaling and rotation effects that can be inspected directly.
Where Pith is reading between the lines
- The same GMM structure could be tested on other conversion tasks such as emotion or accent adaptation to check if local linearity generalizes.
- Inspecting the posterior assignments might offer a route to control which phonetic regions are transformed independently.
- The analytic tractability of the transforms could support hybrid systems that combine the GMM with neural components for specific regions.
Load-bearing premise
Self-supervised speech representations contain heterogeneous structure that a Gaussian mixture model can capture sufficiently well for posterior-weighted affine transforms to enable effective voice conversion.
What would settle it
An experiment in which increasing the number of mixture components fails to improve speaker similarity beyond the deep learning baseline or causes the constrained covariance variant to lose its advantage would falsify the claim.
Figures


read the original abstract
We introduce SSL-GMMVC, an interpretable voice conversion method in self-supervised speech space. The method models paired source-target features with a Gaussian mixture model and performs conversion as a posterior-weighted sum of affine transforms. This yields locally linear transformations that adapt to heterogeneous feature-space structure while remaining analytically tractable. Through objective and subjective evaluations, we show that SSL-GMMVC improves speaker similarity with comparable intelligibility and naturalness, and that even a constrained covariance variant surpasses a deep learning baseline as the number of mixture components increases. Further analyses link component selection to phonetic structure and reveal interpretable scaling and rotation in the learned transforms. These findings highlight SSL-GMMVC as an effective, analyzable framework for voice conversion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SSL-GMMVC, an interpretable voice conversion method that models paired source-target features from self-supervised speech representations using a Gaussian mixture model and performs conversion via posterior-weighted sums of affine transforms. This produces locally linear, analytically tractable mappings that adapt to heterogeneous structure in the feature space. The authors claim that objective and subjective evaluations demonstrate improved speaker similarity with comparable intelligibility and naturalness, that a constrained-covariance variant surpasses a deep learning baseline as the number of mixture components K increases, and that component selection links to phonetic structure with interpretable scaling and rotation in the learned transforms.
Significance. If the central claims hold, the work supplies an interpretable, non-black-box alternative to deep neural voice conversion that remains tractable and potentially analyzable in terms of phonetic content and geometric transforms. The reported scaling behavior with K and the phonetic linkage could provide new insight into the structure of SSL representations for speech tasks.
major comments (2)
- [Abstract] Abstract: the central performance claims (improved speaker similarity, constrained-covariance variant surpassing DL baseline as K grows) are asserted without any numeric metrics, baseline details, statistical tests, or error bars, preventing verification of the result from the provided text.
- [Method] Method description: the claim that posterior-weighted affine transforms yield effective conversion and the scaling-with-K advantage requires that the SSL representation space exhibits cluster structure adequately captured by a GMM. No diagnostics (e.g., GMM log-likelihood on held-out features, visualization of component assignments against phonetic labels, or comparison against non-Gaussian mixture models) are supplied to confirm this modeling assumption, which is load-bearing for the interpretability and performance arguments.
minor comments (1)
- [Method] Clarify the precise parameterization of the affine transforms (means, covariances, and how the constrained variant is implemented) and the exact self-supervised model whose representations are used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify opportunities to strengthen the presentation of results and validation of modeling assumptions. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (improved speaker similarity, constrained-covariance variant surpassing DL baseline as K grows) are asserted without any numeric metrics, baseline details, statistical tests, or error bars, preventing verification of the result from the provided text.
Authors: We agree that the abstract would be strengthened by including specific numeric results to support the performance claims. In the revised version, we will update the abstract to report key quantitative metrics from the objective evaluations (e.g., speaker similarity scores and intelligibility measures), identify the deep learning baseline, and note that statistical significance testing was performed with error bars derived from multiple runs. This change will allow readers to assess the claims more directly from the abstract text. revision: yes
-
Referee: [Method] Method description: the claim that posterior-weighted affine transforms yield effective conversion and the scaling-with-K advantage requires that the SSL representation space exhibits cluster structure adequately captured by a GMM. No diagnostics (e.g., GMM log-likelihood on held-out features, visualization of component assignments against phonetic labels, or comparison against non-Gaussian mixture models) are supplied to confirm this modeling assumption, which is load-bearing for the interpretability and performance arguments.
Authors: The observation is correct that the manuscript does not provide explicit diagnostics such as held-out GMM log-likelihood or phonetic alignment visualizations to directly validate the cluster structure assumption. The scaling behavior with K and the phonetic linkage analyses offer indirect support, but we acknowledge this is insufficient for full substantiation. We will add supplementary diagnostics including GMM log-likelihood on held-out features and visualizations of component assignments versus phonetic labels. A systematic comparison against non-Gaussian mixture models lies outside the current scope and would require substantial additional experiments; we will note this as a limitation and direction for future work while retaining the GMM for its analytic tractability. revision: partial
Circularity Check
No circularity: standard GMM application to SSL features with independent evaluations
full rationale
The provided abstract and description present SSL-GMMVC as a direct application of Gaussian mixture modeling to paired source-target self-supervised features, using posterior-weighted affine transforms. No equations, self-citations, or claims are shown that reduce the reported improvements (speaker similarity, scaling with K) to a fitted parameter defined by the same data or to a self-citation chain. The method is described as analytically tractable and interpretable without self-definitional loops or renaming of known results. Evaluations are presented as external validation. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Its ap- plications include anonymization [2, 3], computer-assisted lan- guage learning [4, 5], and speaking aid [6, 7]
Introduction V oice conversion (VC) modifies a speaker’s voice to sound like another person while preserving linguistic content [1]. Its ap- plications include anonymization [2, 3], computer-assisted lan- guage learning [4, 5], and speaking aid [6, 7]. VC progress has been driven by advances in both trans- formation models and speech representations [8, 9...
-
[2]
Overview We propose SSL-GMMVC, a GMM-based voice conversion system operating on SSL features
SSL-GMMVC 2.1. Overview We propose SSL-GMMVC, a GMM-based voice conversion system operating on SSL features. Figure 1 shows an overview of the pipeline. We align SSL features of source and target utter- ances using nearest-neighbor matching to obtain paired source– target vectors following [20], and model their joint distribution with a GMM. At conversion...
Pith/arXiv arXiv 2026
-
[3]
Data We used American English speech from CMU ARCTIC [23], selecting three male (bdl, rms, aew) and three female (slt, clb, lnh) speakers
V oice conversion experiments 3.1. Data We used American English speech from CMU ARCTIC [23], selecting three male (bdl, rms, aew) and three female (slt, clb, lnh) speakers. Each utterance was around 2–3 seconds long. 3.2. Implementation of SSL-GMMVC Following [19, 20], we extracted 1024-dimensional SSL fea- tures from the 6th layer of WavLM-Large [12], w...
-
[4]
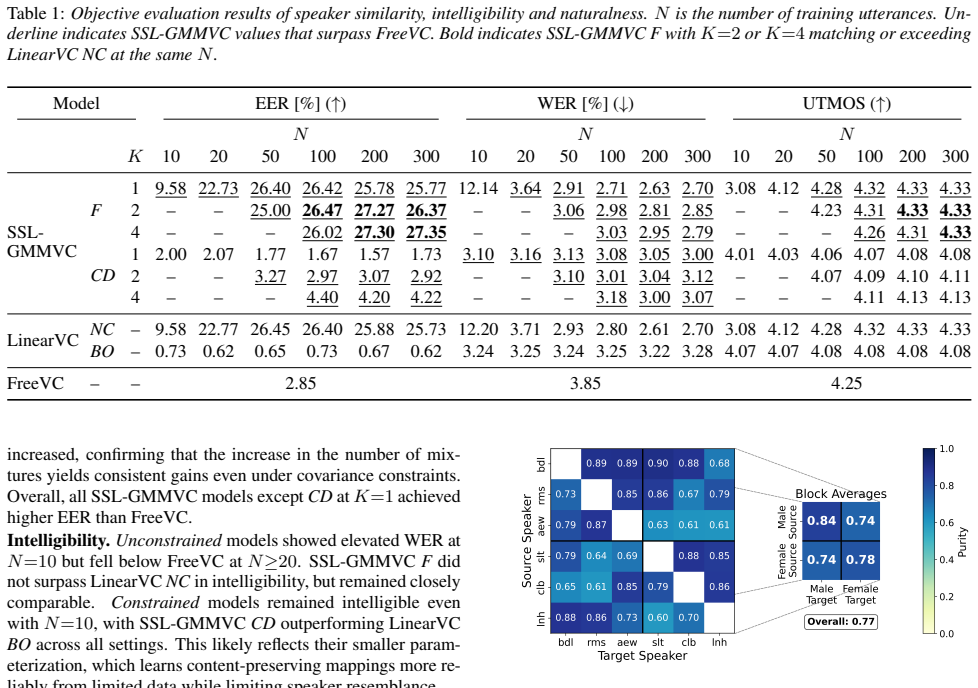
Results of the objective evaluation Table 1 summarizes the objective evaluation results
Results 4.1. Results of the objective evaluation Table 1 summarizes the objective evaluation results. Be- cause FreeVC is pretrained, its performance is independent of training-set size. We refer to SSL-GMMVCFand LinearVC NCcollectively asunconstrainedmodels, and SSL-GMMVC CDand LinearVCBOasconstrainedmodels. Speaker similarity.The EER of SSL-GMMVCFincrea...
-
[5]
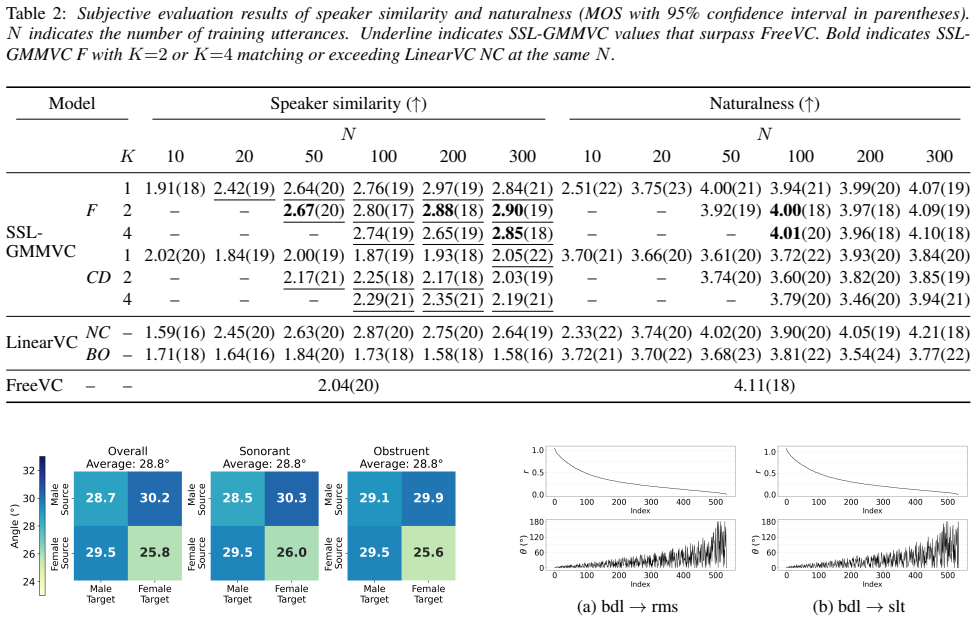
Figure 2:Purity between mixture selection and sonority (left: speaker pairs; right: gender-pair averages)
Further analysis This section investigates how mixture components relate to pho- netic categories and how the transformation matrices act on the feature space across speaker pairs. Figure 2:Purity between mixture selection and sonority (left: speaker pairs; right: gender-pair averages). 5.1. Component selection 5.1.1. Setup We analyzed SSL-GMMVCF(K=2,N=20...
-
[6]
Objective and subjective eval- uations showed that SSL-GMMVC improves speaker similarity over LinearVC in particular settings with comparable intelligi- bility and naturalness
Conclusion We presented SSL-GMMVC, a GMM-based voice conversion method that extends a single global transform to locally linear mappings in SSL feature space. Objective and subjective eval- uations showed that SSL-GMMVC improves speaker similarity over LinearVC in particular settings with comparable intelligi- bility and naturalness. Even the constrained ...
-
[7]
The authors would like to thank Kentaro Onda at The University of Tokyo, for his valuable assistance in refining this work
Acknowledgements This research was supported by JSPS KAKENHI Grant Number JP25K22829. The authors would like to thank Kentaro Onda at The University of Tokyo, for his valuable assistance in refining this work
-
[8]
Use of generative AI tools GPT-5.2 was used to aid editing and polishing this manuscript
-
[9]
V oice conversion,
D. G. Childers, K. Wu, D. Hicks, and B. Yegnanarayana, “V oice conversion,”Speech Communication, vol. 8, no. 2, pp. 147–158, 1989
1989
-
[10]
Evaluating voice conversion-based privacy protection against informed attackers,
B. M. L. Srivastava, N. Vauquier, M. Sahidullah, A. Bellet, M. Tommasi, and E. Vincent, “Evaluating voice conversion-based privacy protection against informed attackers,” inICASSP 2020- 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 2802–2806
2020
-
[11]
Zero-shot un- seen speaker anonymization via voice conversion,
H.-P. Chang, I.-C. Yoo, C. Jeong, and D. Yook, “Zero-shot un- seen speaker anonymization via voice conversion,”IEEE Access, vol. 10, pp. 130 190–130 199, 2022
2022
-
[12]
Foreign accent conversion in computer assisted pronunciation training,
D. Felps, H. Bortfeld, and R. Gutierrez-Osuna, “Foreign accent conversion in computer assisted pronunciation training,”Speech communication, vol. 51, no. 10, pp. 920–932, 2009
2009
-
[13]
A pilot study of applying sequence-to-sequence voice conversion to evaluate the intelligi- bility of l2 speech using a native speaker’s shadowings,
H. Geng, D. Saito, and N. Minematsu, “A pilot study of applying sequence-to-sequence voice conversion to evaluate the intelligi- bility of l2 speech using a native speaker’s shadowings,” in2024 Asia Pacific Signal and Information Processing Association An- nual Summit and Conference, 2024, pp. 1–6
2024
-
[14]
Speaking- aid systems using gmm-based voice conversion for electrolaryn- geal speech,
K. Nakamura, T. Toda, H. Saruwatari, and K. Shikano, “Speaking- aid systems using gmm-based voice conversion for electrolaryn- geal speech,”Speech communication, vol. 54, no. 1, pp. 134–146, 2012
2012
-
[15]
Pathological voice adaptation with autoencoder- based voice conversion,
M. Illa, B. M. Halpern, R. van Son, L. Moro-Velazquez, and O. Scharenborg, “Pathological voice adaptation with autoencoder- based voice conversion,” in11th ISCA Speech Synthesis Workshop (SSW 11), 2021, pp. 19–24
2021
-
[16]
An overview of voice conversion systems,
S. H. Mohammadi and A. Kain, “An overview of voice conversion systems,”Speech Communication, vol. 88, no. C, pp. 65–82, Apr. 2017
2017
-
[17]
An overview of voice conversion and its challenges: From statistical modeling to deep learning,
B. Sisman, J. Yamagishi, S. King, and H. Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 132–157, 2020
2020
-
[18]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460
2020
-
[19]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[20]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, Oct. 2022
2022
-
[21]
Audio self-supervised learning: A survey,
S. Liu, A. Mallol-Ragolta, E. Parada-Cabaleiro, K. Qian, X. Jing, A. Kathan, B. Hu, and B. W. Schuller, “Audio self-supervised learning: A survey,”Patterns, vol. 3, no. 12, 2022
2022
-
[22]
Self-supervised speech representation learning: A review,
A. Mohamed, H.-y. Lee, L. Borgholt, J. D. Havtorn, J. Edin, C. Igel, K. Kirchhoff, S.-W. Li, K. Livescu, L. Maaløe, T. N. Sainath, and S. Watanabe, “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, 2022
2022
-
[23]
SUPERB: Speech processing universal performance benchmark,
S. wen Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.- W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “SUPERB: Speech processing universal performance benchmark,” inInter- speech 2021, 2021, pp. 1194–1198
2021
-
[24]
S3PRL-VC: Open-source voice conversion frame- work with self-supervised speech representations,
W.-C. Huang, S.-W. Yang, T. Hayashi, H.-Y . Lee, S. Watanabe, and T. Toda, “S3PRL-VC: Open-source voice conversion frame- work with self-supervised speech representations,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6552–6556
2022
-
[25]
Freevc: Towards high-quality text-free one-shot voice conversion,
J. Li, W. Tu, and L. Xiao, “Freevc: Towards high-quality text-free one-shot voice conversion,” inICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing, 2023, pp. 1–5
2023
-
[26]
AdaptVC: High quality voice conversion with adaptive learning,
J. Kim, J.-H. Kim, Y . Choi, T. D. Nguyen, S. Mun, and J. S. Chung, “AdaptVC: High quality voice conversion with adaptive learning,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[27]
V oice conversion with just nearest neighbors,
M. Baas, B. van Niekerk, and H. Kamper, “V oice conversion with just nearest neighbors,” inProc. Interspeech 2023, 2023, pp. 2053–2057
2023
-
[28]
LinearVC: Linear transformations of self-supervised features through the lens of voice conversion,
H. Kamper, B. van Niekerk, J. Za ¨ıdi, and M.-A. Carbonneau, “LinearVC: Linear transformations of self-supervised features through the lens of voice conversion,” inProc. Interspeech 2025, 2025, pp. 1398–1402
2025
-
[29]
Analysing discrete self supervised speech representation for spoken language modeling,
A. Sicherman and Y . Adi, “Analysing discrete self supervised speech representation for spoken language modeling,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[30]
Continuous probabilis- tic transform for voice conversion,
Y . Stylianou, O. Capp´e, and E. Moulines, “Continuous probabilis- tic transform for voice conversion,”IEEE Transactions on Speech and Audio Processing, vol. 6, no. 2, p. 131, 1998
1998
-
[31]
The CMU ARCTIC speech databases,
J. Kominek and A. W. Black, “The CMU ARCTIC speech databases,” in5th ISCA Workshop on Speech Synthesis, 2004, pp. 223–224
2004
-
[32]
HiFi-GAN: Generative adversar- ial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversar- ial networks for efficient and high fidelity speech synthesis,”Ad- vances in Neural Information Processing Systems, vol. 33, pp. 17 022–17 033, 2020
2020
-
[33]
ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,” inProc. Interspeech 2020, 2020, pp. 3830–3834
2020
-
[34]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[35]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inProc. Interspeech 2022, 2022, pp. 4521–4525
2022
-
[36]
D. A. Burquest,Phonological Analysis: A Functional Approach, 3rd ed. Summer Institute of Linguistics, 2006
2006
-
[37]
Montreal forced aligner: Trainable text-speech align- ment using kaldi
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal forced aligner: Trainable text-speech align- ment using kaldi.” inProc. Interspeech 2017, 2017, pp. 498–502
2017
-
[38]
Speaker clustering of speech utterances using a voice characteristic reference space,
W.-H. Tsai, S.-S. Cheng, and H.-M. Wang, “Speaker clustering of speech utterances using a voice characteristic reference space,” in Proc. Interspeech 2004, 2004, pp. 2937–2940
2004
-
[39]
Rotational properties of vocal tract length difference in cepstral space,
D. Saito, N. Minematsu, and K. Hirose, “Rotational properties of vocal tract length difference in cepstral space,”Journal of Re- search Institute of Signal Processing, vol. 15, no. 5, pp. 363–374, 2011
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.