CoCoSI: Collaborative Cognitive Map Construction for Spatial Intelligence
Pith reviewed 2026-06-27 14:15 UTC · model grok-4.3
The pith
A multi-agent system lets any pretrained MLLM maintain spatial coherence across long visual sequences by building a shared cognitive map through atomic commits and verification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
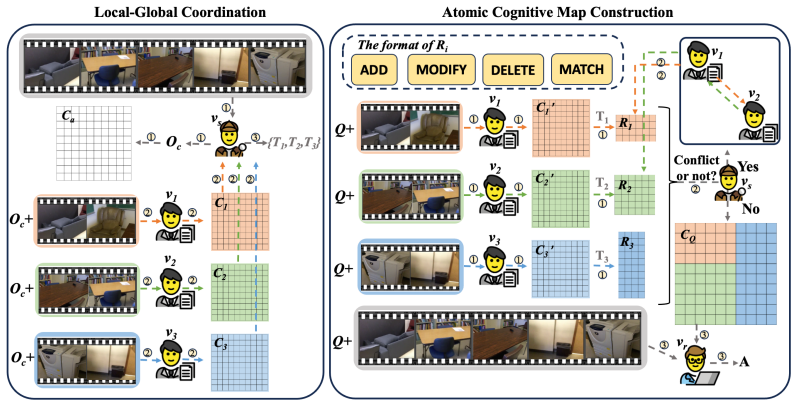
The central claim is that collaborative construction of a cognitive map, using local-global agent coordination, atomic commits for updates, and cross-agent verification, enables reliable storage and retrieval of spatial information that exceeds the context window of any unmodified pretrained MLLM, producing better results on spatial understanding tasks while remaining training-free.
What carries the argument
The collaborative cognitive map built through local-global agent coordination, atomic commits, and cross-agent verification.
If this is right
- The method applies to arbitrary pretrained MLLMs without architectural changes.
- It produces superior performance on spatial understanding tasks compared to prior approaches.
- Spatial representations remain coherent over extended multi-frame inputs.
- No finetuning or specialized memory modules are required.
- The framework operates as a lightweight plug-and-play addition.
Where Pith is reading between the lines
- The verification step might reduce spatial hallucinations that single models exhibit on long inputs.
- The same coordination pattern could support other memory-intensive tasks such as long-horizon planning from visual streams.
- If atomic commits prove stable, the approach might scale to multi-robot teams sharing a common spatial reference.
- It suggests a general route for augmenting fixed models with external structured memory instead of expanding context windows.
Load-bearing premise
A multi-agent collaborative process with atomic commits and cross-verification can reliably preserve and retrieve spatial information beyond the native context window of an unmodified pretrained MLLM.
What would settle it
A controlled test on video sequences longer than the model's context length where queries about relative object positions yield the same or lower accuracy than a single-pass baseline that simply truncates the input.
Figures


read the original abstract
Spatial intelligence is a key frontier for multimodal large language models (MLLMs), enabling them to reason about the physical world from visual experience. Inspired by human spatial cognition, recent approaches construct grid-based cognitive maps from multi-frame visual inputs to maintain coherent spatial representations over time. However, limited context lengths still challenge spatial understanding, while existing methods, such as long-context modeling and external memory, often require architectural changes, memory modules, or finetuning, limiting their applicability to off-the-shelf pretrained MLLMs. This motivates a lightweight, model-agnostic method for preserving spatial information beyond the native context window. To this end, we propose a plug-and-play multi-agent framework that collaboratively constructs cognitive maps as structured spatial memory, enhancing the spatial understanding of arbitrary pretrained MLLMs without architectural modification or additional training. Our framework features local-global agent coordination, cognitive map construction with atomic commits, and cross-agent verification. Extensive experiments demonstrate that our method achieves superior performance on spatial understanding tasks while remaining fully training-free. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoCoSI, a plug-and-play multi-agent framework for collaboratively constructing structured cognitive maps as external spatial memory. The approach uses local-global agent coordination, atomic commits during map construction, and cross-agent verification to enable spatial reasoning in unmodified pretrained MLLMs beyond their native context windows, without any training or architectural changes. It claims superior performance on spatial understanding tasks while remaining fully training-free.
Significance. If the central claims are substantiated with rigorous experiments, the work would offer a lightweight, model-agnostic solution to context-length limitations for spatial tasks in MLLMs, with potential value for embodied AI and navigation. The training-free and plug-and-play design is a notable strength if it demonstrably works with arbitrary off-the-shelf models.
major comments (2)
- [Abstract] Abstract: the claim that the external cognitive map plus cross-agent verification enables queries whose visual evidence exceeds the native context window is load-bearing, yet the manuscript provides no mechanism, encoding scheme, or ablation demonstrating that (a) the map encoding is lossless for metric relations, (b) retrieval selects the needed sub-graph without reintroducing context pressure, and (c) verification detects and repairs spatial inconsistencies rather than merely confirming syntactic well-formedness.
- [Abstract] Abstract: the assertion of 'superior performance' and 'extensive experiments' cannot be evaluated because the manuscript supplies no quantitative results, baselines, error bars, dataset details, or ablation studies, leaving the performance gains unsupported.
minor comments (1)
- [Abstract] The abstract states that code will be released but provides no link or repository information in the current version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional detail and evidence are needed to support the central claims. We address each point below and will revise the manuscript to incorporate the requested clarifications and supporting material.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the external cognitive map plus cross-agent verification enables queries whose visual evidence exceeds the native context window is load-bearing, yet the manuscript provides no mechanism, encoding scheme, or ablation demonstrating that (a) the map encoding is lossless for metric relations, (b) retrieval selects the needed sub-graph without reintroducing context pressure, and (c) verification detects and repairs spatial inconsistencies rather than merely confirming syntactic well-formedness.
Authors: We agree that the abstract is high-level and that the load-bearing claim requires explicit support. The manuscript describes local-global coordination, atomic commits for incremental map updates, and cross-agent verification, but does not include the requested ablations or encoding details. In the revision we will add: (1) a precise description of the map encoding (graph with nodes as object instances and edges as directed metric relations with coordinate tuples), (2) an ablation isolating retrieval that measures context length before/after sub-graph selection, and (3) concrete verification traces showing detection and repair of metric inconsistencies (e.g., contradictory distance or angle relations) rather than only syntactic checks. These additions will be placed in a new subsection and appendix. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'superior performance' and 'extensive experiments' cannot be evaluated because the manuscript supplies no quantitative results, baselines, error bars, dataset details, or ablation studies, leaving the performance gains unsupported.
Authors: The referee is correct that the current manuscript version does not contain the quantitative results, baselines, error bars, dataset specifications, or ablation studies referenced in the abstract. We will add a complete experimental section (including tables with means and standard deviations, baseline comparisons, dataset descriptions, and targeted ablations on coordination, atomic commits, and verification) in the revised manuscript so that the performance claims can be properly evaluated. revision: yes
Circularity Check
No circularity; engineering framework with no derivations or self-referential reductions
full rationale
The paper describes a plug-and-play multi-agent system for cognitive map construction using local-global coordination, atomic commits, and cross-agent verification. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. The central claims rest on the independent design of the framework and its experimental outcomes rather than any self-definition, fitted-input renaming, or self-citation chain. The method is presented as model-agnostic and training-free without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human spatial cognition can be effectively modeled with grid-based cognitive maps constructed from visual input
Reference graph
Works this paper leans on
-
[1]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[2]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[3]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26160–26169, 2025
2025
-
[5]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
2024
-
[6]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13504–13514, 2024
2024
-
[7]
Videobert: A joint model for video and language representation learning
Chen Sun, Austin Myers, Carl V ondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 7464–7473, 2019
2019
-
[8]
Hero: Hierarchi- cal encoder for video+ language omni-representation pre-training
Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu. Hero: Hierarchi- cal encoder for video+ language omni-representation pre-training. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 2046–2065, 2020
2020
-
[9]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
2022
-
[10]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024
2024
-
[11]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos.arXiv preprint arXiv:2408.10188, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xiangyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Videoagent: Long-form video understanding with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with large language model as agent. InEuropean Conference on Computer Vision, pages 58–76. Springer, 2024. 10
2024
-
[14]
Ziqi Pang and Yu-Xiong Wang. Mr. video: Mapreduce as an effective principle for long video understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[15]
Neural Map: Structured Memory for Deep Reinforcement Learning
Emilio Parisotto and Ruslan Salakhutdinov. Neural map: Structured memory for deep reinforce- ment learning.arXiv preprint arXiv:1702.08360, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155, 2020
Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhut- dinov. Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155, 2020
-
[17]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024
2024
-
[19]
3d-mem: 3d scene memory for embodied exploration and reasoning
Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17294–17303, 2025
2025
-
[20]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[22]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
2023
-
[23]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[24]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[25]
Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents
Boyu Chen, Zhengrong Yue, Siran Chen, Zikang Wang, Yang Liu, Peng Li, and Yali Wang. Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20237– 20246, 2025
2025
-
[26]
Longvideoagent: Multi-agent reasoning with long videos.arXiv preprint arXiv:2512.20618, 2025
Runtao Liu, Ziyi Liu, Jiaqi Tang, Yue Ma, Renjie Pi, Jipeng Zhang, and Qifeng Chen. Longvideoagent: Multi-agent reasoning with long videos.arXiv preprint arXiv:2512.20618, 2025
-
[27]
arXiv preprint arXiv:2512.10863 , year=
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, Chenming Zhu, Yiman Xie, Yilin Long, et al. Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence.arXiv preprint arXiv:2512.10863, 2025
-
[28]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Chuyi Shang, Amos You, Sanjay Subramanian, Trevor Darrell, and Roei Herzig. Trav- eler: A modular multi-lmm agent framework for video question-answering.arXiv preprint arXiv:2404.01476, 2024
-
[32]
Vca: Video curious agent for long video understanding
Zeyuan Yang, Delin Chen, Xueyang Yu, Maohao Shen, and Chuang Gan. Vca: Video curious agent for long video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20168–20179, 2025. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.