Entropy-Aware Domain-Routed Mixture-of-Experts Speech-LLM Framework: A Case Study of Multi-Domain Child-Adult ASR
Pith reviewed 2026-06-27 12:03 UTC · model grok-4.3
The pith
A single Speech-LLM with domain-routed experts recognizes both child and adult speech more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed Entropy-Aware Domain-Routed Mixture-of-Experts framework enables unified ASR across adult and child domains by routing to appropriate experts and using a shared expert for uncertain cases, leading to performance gains on child corpora without loss on adult data.
What carries the argument
The Classifier-based Domain Router with coarse-to-fine strategy and Entropy-Aware Routing that dynamically includes a shared expert to handle boundary uncertainty.
If this is right
- Unified models can handle diverse age groups in one system.
- Domain-specific adaptations via MoP and MoL improve accuracy in varied environments.
- Entropy-aware mechanism prevents routing errors near domain edges.
- Speech-LLMs become viable for mixed adult-child applications like education and healthcare.
Where Pith is reading between the lines
- This routing approach could apply to other domain shifts such as different languages or acoustic conditions.
- Future work might explore scaling the number of experts for finer age or environment distinctions.
- Integration with other modalities could extend the framework beyond ASR.
Load-bearing premise
The domain router combined with entropy-aware routing correctly manages uncertainty at domain boundaries without adding errors that cancel out the gains.
What would settle it
Running the model on a new dataset with mixed child and adult speech where performance does not improve over baselines or adult accuracy drops would falsify the effectiveness of the routing strategy.
Figures


read the original abstract
While Speech Large Language Models (Speech-LLMs) have achieved strong performance on adult Automatic Speech Recognition (ASR), their effectiveness on child speech remains under-explored, and single models often struggle to handle diverse adult and child age groups simultaneously. This paper proposes a Mixture-of-Experts (MoE) Speech-LLM for unified ASR across adult and child speech spanning diverse environments and age groups. The framework employs a Classifier-based Domain Router (C-DR) with a coarse-to-fine strategy and integrates both a Mixture-of-Projectors (MoP) and a Mixture-of-LoRAs (MoL) to model domain-specific variations. To address routing uncertainty near domain boundaries, an Entropy-Aware Routing (EAR) mechanism is introduced to dynamically incorporate a shared expert. Experiments on public child corpora demonstrate consistent improvements over baselines while preserving adult ASR performance. To our knowledge, this is the first work leveraging Speech-LLMs for unified, multi-domain ASR encompassing both children and adults.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an Entropy-Aware Domain-Routed Mixture-of-Experts Speech-LLM Framework for multi-domain ASR covering child and adult speech. The framework includes a Classifier-based Domain Router (C-DR) using a coarse-to-fine strategy, a Mixture-of-Projectors (MoP), a Mixture-of-LoRAs (MoL), and an Entropy-Aware Routing (EAR) mechanism to manage routing uncertainty near domain boundaries. Experiments on public child corpora are reported to show consistent improvements over baselines while preserving adult ASR performance, positioning the work as the first to leverage Speech-LLMs for unified child-adult ASR.
Significance. If the experimental results are robust and reproducible, this work could be significant in the field of speech recognition by providing a unified approach to handling diverse age groups in ASR using advanced MoE techniques in Speech-LLMs. The introduction of EAR to address domain boundary issues is a targeted solution that may have broader applicability. The stress-test concern regarding lack of quantitative results in the abstract does not land, as the full manuscript is expected to contain the detailed experimental validation.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one or two key quantitative metrics (e.g., WER deltas on specific child corpora) to allow readers to immediately gauge the scale of the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report for us to address point by point.
Circularity Check
No significant circularity; empirical architecture only
full rationale
The manuscript presents an empirical MoE Speech-LLM architecture (C-DR with coarse-to-fine routing, MoP, MoL, EAR) whose central claims rest on experimental gains on public child corpora while preserving adult performance. No equations, parameter-fitting derivations, or self-citation chains appear in the abstract or described content; the contribution is framed as an engineering framework validated by benchmarks rather than any mathematical reduction to author-defined inputs. The reader's assessment of score 1.0 aligns with the absence of any load-bearing derivation step that could be inspected for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech Large Language Models (Speech-LLMs) have demon- strated strong performance on a wide range of speech-related tasks [1, 2, 3, 4, 5, 6, 7]. A typical Speech-LLM for Automatic Speech Recognition (ASR) leverages a pre-trained speech en- coder [8, 9, 10], a modality projector, and a LLM [11, 12] fine- tuned with a Low-Rank Adapter (LoRA) [1...
-
[2]
Background We study ASR across heterogeneous speech domains, including adult and child speech from diverse acoustic environments and age groups, with the goal of building a unified multi-domain ASR system using a single Speech-LLM framework. A typical Speech-LLM for ASR [1, 3] consists of a speech encoder, a modality projector, and an LLM fine-tuned with ...
Pith/arXiv arXiv 2026
-
[3]
Overall Framework Figure 1 illustrates the overall workflow of the proposed frame- work
Method 3.1. Overall Framework Figure 1 illustrates the overall workflow of the proposed frame- work. Unlike standard Speech-LLMs with a single projector and LoRA module, our framework adopts a Mixture-of-Experts (MoE) architecture to handle heterogeneous speech domains. We introduce an explicit Classifier-based Domain Router (C- DR) to guide expert select...
-
[4]
Dataset Setting We evaluate the proposed method on both child and adult speech
Experimental Settings 4.1. Dataset Setting We evaluate the proposed method on both child and adult speech. For child speech, we use MyST [18] and the sponta- neous portion of OGI (OGI-S) [19], which are collected in dif- ferent acoustic environments and include disfluency-preserving transcriptions. MyST contains dialogues between children aged 8–10 and vi...
-
[5]
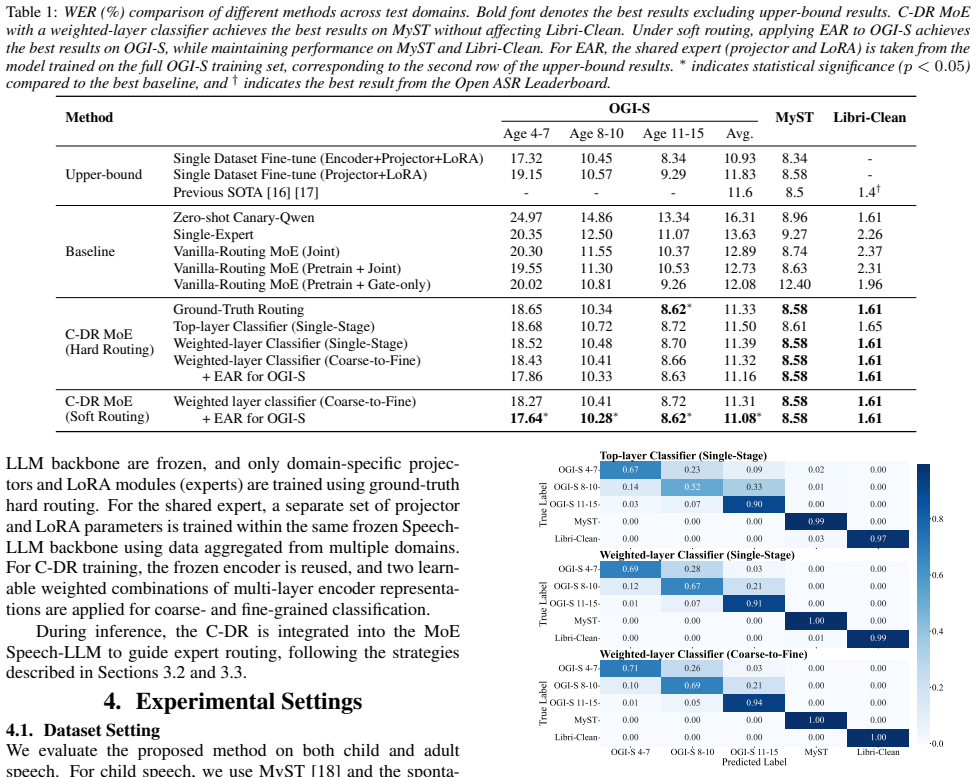
Experimental Results 5.1. Performance of Domain Classification Figure 2 shows confusion matrices for three domain classifier variants: top-layer encoder representations, weighted-sum rep- resentations with single-stage classification, and weighted-sum representations with coarse-to-fine classification. Classification across different datasets is fairly ac...
-
[6]
Conclusion We propose an Entropy-Aware Domain-Routed MoE Speech- LLM to tackle ASR across heterogeneous speech domains, in- cluding adult and child speech with diverse conditions. By com- bining mixtures of projectors and LoRA modules, along with coarse-to-fine domain classification and entropy-aware routing, our model effectively captures domain-specific...
-
[7]
Department of Education (DoE), through Grant R305C240046 to the U
Acknowledgements This research is supported in part by the National Science Foun- dation (NSF) and the Institute of Education Sciences (IES), U.S. Department of Education (DoE), through Grant R305C240046 to the U. at Buffalo. The opinions expressed are those of the authors and do not represent views of the IES, DoE, or the NSF
-
[8]
All technical content, experimental design, results, and conclusions were produced and verified by the authors
Generative AI Use Disclosure During the preparation of this work, the authors used ChatGPT (GPT-5.2 Thinking) for language editing, including proofread- ing and improving clarity and readability of the manuscript. All technical content, experimental design, results, and conclusions were produced and verified by the authors. After the use of Gen- erative A...
-
[9]
Prompting large language models with speech recog- nition abilities,
Y . Fathullah, C. Wu, E. Lakomkin, J. Jia, Y . Shangguan, K. Li, J. Guo, W. Xiong, J. Mahadeokar, O. Kalinli, C. Fuegen, and M. Seltzer, “Prompting large language models with speech recog- nition abilities,” inICASSP. IEEE, 2024, pp. 13 351–13 355
2024
-
[10]
An embarrassingly simple approach for llm with strong asr capacity,
Z. Ma, G. Yang, Y . Yang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang, and X. Chen, “An embarrassingly simple approach for llm with strong asr capacity,”arXiv preprint arXiv:2402.08846, 2024
arXiv 2024
-
[11]
Advancing multi-talker ASR performance with large language models,
M. Shi, Z. Jin, Y . Xu, Y . Xu, S. Zhang, K. Wei, Y . Shao, C. Zhang, and D. Yu, “Advancing multi-talker ASR performance with large language models,” inSLT. IEEE, 2024, pp. 14–21
2024
-
[12]
Neural codec language models are zero-shot text-to-speech synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language models are zero-shot text-to-speech synthesizers,”IEEE/ACM Trans. Audio Speech Lang. Process., vol. 33, pp. 705–718, 2025
2025
-
[13]
SALMONN: towards generic hearing abilities for large language models,
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “SALMONN: towards generic hearing abilities for large language models,” inICLR. OpenReview.net, 2024
2024
-
[14]
Emotionthinker: Prosody-aware reinforcement learning for ex- plainable speech emotion reasoning,
D. W ANG, S. LIU, T. Zhang, Y . Chen, J. Li, and H. M. Meng, “Emotionthinker: Prosody-aware reinforcement learning for ex- plainable speech emotion reasoning,” inICLR. OpenReview.net, 2026
2026
-
[15]
Train short, infer long: Speech-llm enables zero-shot streamable joint asr and di- arization on long audio,
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and di- arization on long audio,” inICASSP. IEEE, 2026, pp. 17 442– 17 446
2026
-
[16]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[17]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 29, pp. 3451–3460, 2021
2021
-
[18]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[19]
A. Grattafioriet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[20]
A. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[21]
Lora: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large lan- guage models,” inICLR. OpenReview.net, 2022
2022
-
[22]
DRAFT: A novel framework to reduce domain shifting in self-supervised learning and its application to children’s ASR,
R. Fan and A. Alwan, “DRAFT: A novel framework to reduce domain shifting in self-supervised learning and its application to children’s ASR,” inINTERSPEECH. ISCA, 2022, pp. 4900– 4904
2022
-
[23]
Towards better do- main adaptation for self-supervised models: A case study of child ASR,
R. Fan, Y . Zhu, J. Wang, and A. Alwan, “Towards better do- main adaptation for self-supervised models: A case study of child ASR,”IEEE J. Sel. Top. Signal Process., vol. 16, no. 6, pp. 1242– 1252, 2022
2022
-
[24]
Benchmarking children’s ASR with supervised and self-supervised speech foundation mod- els,
R. Fan, N. B. Shankar, and A. Alwan, “Benchmarking children’s ASR with supervised and self-supervised speech foundation mod- els,” inINTERSPEECH. ISCA, 2024
2024
-
[25]
Benchmark- ing Training Paradigms, Dataset Composition, and Model Scaling for Child ASR in ESPnet,
A. Ying, N. B. Shankar, C.-J. Lin, M. Shi, P. Wang, H. jin Shim, S. Arora, H. V . hamme, A. Alwan, and S. Watanabe, “Benchmark- ing Training Paradigms, Dataset Composition, and Model Scaling for Child ASR in ESPnet,” inWorkshop on Child Computer Inter- action - WOCCI 2025, 2025, pp. 6–10
2025
-
[26]
My science tutor (myst)-a large corpus of children’s conversational speech,
S. Pradhan, R. A. Cole, and W. H. Ward, “My science tutor (myst)-a large corpus of children’s conversational speech,” in LREC/COLING. ELRA and ICCL, 2024, pp. 12 040–12 045
2024
-
[27]
The OGI kids 2 speech corpus and recognizers,
K. Shobaki, J. Hosom, and R. A. Cole, “The OGI kids 2 speech corpus and recognizers,” inINTERSPEECH. ISCA, 2000, pp. 258–261
2000
-
[28]
Mind the shift: Using delta ssl embeddings to enhance child asr,
Z. Wanget al., “Mind the shift: Using delta ssl embeddings to enhance child asr,” inICASSP, 2026
2026
-
[29]
Enhanc- ing age-related robustness in children speaker verification,
V . M. Shetty, J. Zheng, S. M. Lulich, and A. Alwan, “Enhanc- ing age-related robustness in children speaker verification,” in ICASSP. IEEE, 2025
2025
-
[30]
Comparing unsupervised and supervised semantic speech tokens: A case study of child ASR,
M. Shiet al., “Comparing unsupervised and supervised semantic speech tokens: A case study of child ASR,” inIEEE ASRU Satel- lite Workshop-AI for Children’s Speech and Language, 2025
2025
-
[31]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. E. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inICLR (Poster). OpenReview.net, 2017
2017
-
[32]
A review of sparse expert mod- els in deep learning,
W. Fedus, J. Dean, and B. Zoph, “A review of sparse expert mod- els in deep learning,”arXiv preprint arXiv:2209.01667, 2022
arXiv 2022
-
[33]
Scaling and enhancing llm-based A VSR: A sparse mixture of projectors approach,
U. Cappellazzo, M. Kim, S. Petridis, D. Falavigna, and A. Brutti, “Scaling and enhancing llm-based A VSR: A sparse mixture of projectors approach,” inINTERSPEECH. ISCA, 2025
2025
-
[34]
Y . Lei, S. He, J. Hu, D. Zhang, X. Luo, D. Zhu, S. Feng, R. Liu, J. He, Y . Sunet al., “Moe adapter for large audio language mod- els: Sparsity, disentanglement, and gradient-conflict-free,”arXiv preprint arXiv:2601.02967, 2026
arXiv 2026
-
[35]
Mosa: Mixtures of simple adapters outperform monolithic approaches in llm-based multilingual asr,
J. Li, J. Peng, Y . Fang, S. Wang, and K. Yu, “Mosa: Mixtures of simple adapters outperform monolithic approaches in llm-based multilingual asr,” inICASSP. IEEE, 2026
2026
-
[36]
Dy- namic multi-expert projectors with stabilized routing for multilin- gual speech recognition,
I. Pandey, A. Mittal, V . Bahuguna, and G. Ramakrishnan, “Dy- namic multi-expert projectors with stabilized routing for multilin- gual speech recognition,” inICASSP. IEEE, 2026
2026
-
[37]
An Age-Agnostic System for Robust Speaker Verification,
J. Zhenget al., “An Age-Agnostic System for Robust Speaker Verification,” inWorkshop on Child Computer Interaction - WOCCI 2025, 2025, pp. 41–45
2025
-
[38]
Hdmole: Mixture of lora experts with hierarchical routing and dynamic thresholds for fine-tuning llm-based ASR models,
B. Mu, K. Wei, Q. Shao, Y . Xu, and L. Xie, “Hdmole: Mixture of lora experts with hierarchical routing and dynamic thresholds for fine-tuning llm-based ASR models,” inICASSP. IEEE, 2025, pp. 1–5
2025
-
[39]
Mixture of LoRA experts with multi-modal and multi-granularity LLM generative error cor- rection for accented speech recognition,
B. Mu, K. Wei, P. Guo, and L. Xie, “Mixture of LoRA experts with multi-modal and multi-granularity LLM generative error cor- rection for accented speech recognition,”IEEE/ACM Trans. Audio Speech Lang. Process., 2025
2025
-
[40]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” inICASSP. IEEE, 2015, pp. 5206–5210
2015
-
[41]
Canary-Qwen-2.5B,
NVIDIA, “Canary-Qwen-2.5B,” https://huggingface.co/nvidia/ canary-qwen-2.5b, 2025, hugging Face model
2025
-
[42]
Open asr leaderboard,
Hugging Face Audio Team, “Open asr leaderboard,” https:// huggingface.co/spaces/hf-audio/open asr leaderboard, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.