Divide and Cooperate: Role-Decomposed Multi-Agent LLM Training with Cross-Agent Learning Signals
Pith reviewed 2026-06-27 14:21 UTC · model grok-4.3
The pith
Dividing search and generation into two cooperative agents with cross-agent abstention signals improves multi-hop QA over monolithic models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
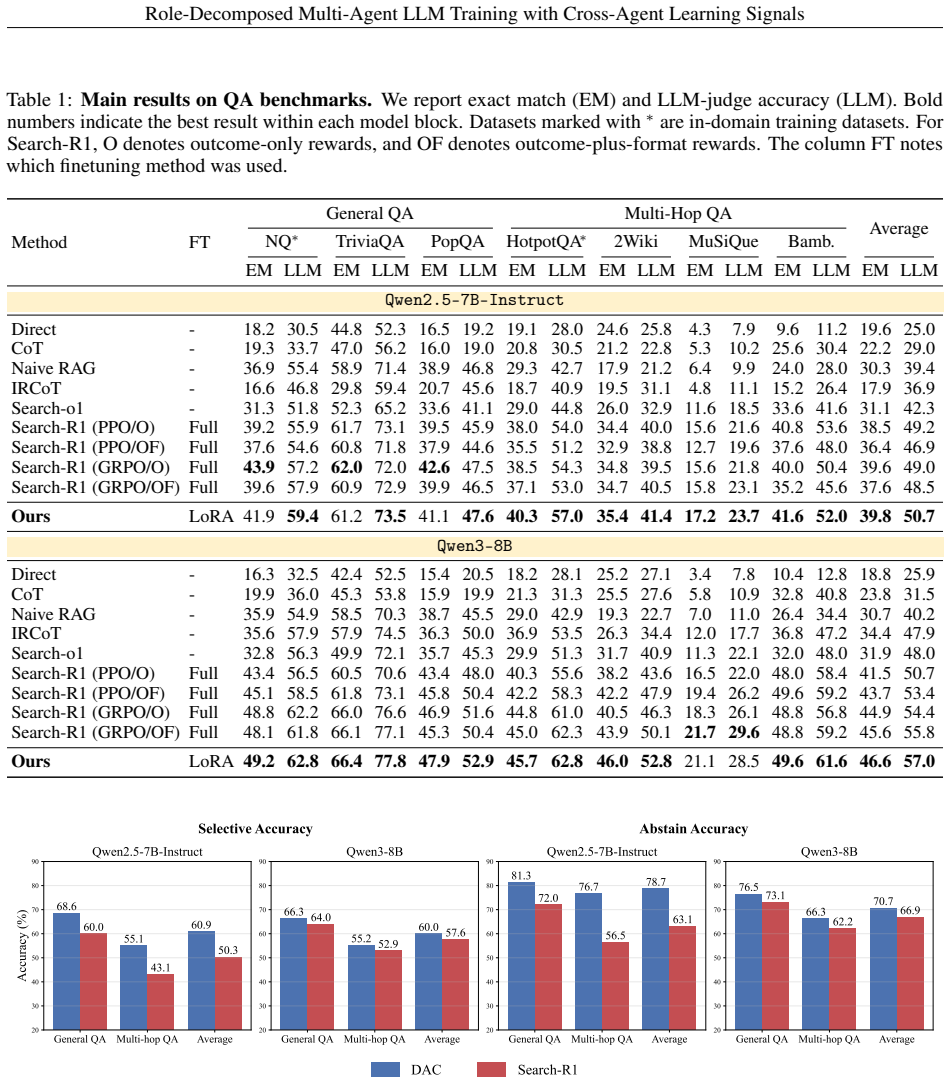
DAC decomposes agentic search into a generator that produces answers and verifies evidence sufficiency by abstaining when needed, and a searcher that receives the abstention as a structured reward signal while supplying diverse evidence through hard-positive augmentation. This cross-agent setup resolves conflicting roles and credit assignment issues, and the resulting system, trained parameter-efficiently with LoRA on a shared backbone, outperforms baselines that fully fine-tune monolithic models on general and multi-hop question answering tasks.
What carries the argument
Role-decomposed multi-agent framework with cross-agent learning signals from generator abstention and hard-positive evidence augmentation.
If this is right
- Separates conflicting roles to shrink the effective policy space and ease exploration.
- Supplies structured cross-agent rewards that improve credit assignment between search and generation steps.
- Enables strong performance using only parameter-efficient LoRA modules rather than full fine-tuning.
- Increases generator robustness through exposure to augmented hard-positive evidence.
- Generalizes across both standard and multi-hop QA benchmarks.
Where Pith is reading between the lines
- The same decomposition pattern could be tested on other multi-step agent tasks such as tool-use chains or planning where roles also conflict.
- An ablation that trains the two agents on completely separate backbones rather than shared ones would show whether parameter sharing is necessary for the reported gains.
- Extending the framework to three or more specialized agents might reveal whether further decomposition yields additional credit-assignment benefits.
Load-bearing premise
The generator's abstention decision when evidence is insufficient can be reliably converted into a structured reward signal for the searcher without introducing training instability or bias.
What would settle it
A controlled run in which the abstention signal is removed or replaced by random noise and the multi-agent system then matches or underperforms the monolithic baseline on the same QA benchmarks would falsify the value of the cross-agent signal.
Figures


read the original abstract
Modern language agents which perform multi-step reasoning have shown strong performance in knowledge-intensive question answering. However, existing approaches typically couple evidence acquisition and answer generation within a single policy. This forces a single model to play multiple potentially conflicting roles, inducing a combinatorial explosion in the policy space and hindering efficient exploration. It also introduces a credit assignment problem during training: a search action that retrieves sufficient evidence may still be penalized when generation fails, and vice versa. We propose DAC (Divide and Cooperate), a role-decomposed multi-agent training framework that divides agentic search into two cooperative subtasks, each handled by a dedicated agent trained with role-specific learning signals. The generator serves a dual role as both an answer producer and an evidence sufficiency verifier, abstaining when retrieved evidence is insufficient. This abstention signal is incorporated into the search agent's reward, providing structured cross-agent learning signals that improve credit assignment. Conversely, the searcher exposes the generator to diverse and challenging evidence environments by hard-positive evidence augmentation, improving its robustness. Experiments on general and multi-hop QA benchmarks show that DAC, implemented via parameter-efficient LoRA modules over a shared backbone, achieves strong performance against prior baselines that rely on full fine-tuning of monolithic models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DAC, a role-decomposed multi-agent training framework for language agents in knowledge-intensive QA. It splits the task into a searcher agent and a generator agent (which also verifies evidence sufficiency and abstains when evidence is insufficient). The abstention supplies a structured reward to the searcher for improved credit assignment, while the searcher supplies hard-positive evidence augmentation to the generator. The method is implemented with parameter-efficient LoRA modules over a shared backbone and claims strong performance on general and multi-hop QA benchmarks relative to prior baselines that use full fine-tuning of monolithic models.
Significance. If the performance results hold with proper controls, the work could advance efficient training of multi-step reasoning agents by mitigating combinatorial policy explosion and credit-assignment problems through explicit role decomposition and cross-agent signals. The parameter-efficient LoRA implementation is a concrete strength that avoids the cost of full fine-tuning.
major comments (2)
- Abstract: The abstract asserts strong benchmark performance but supplies no metrics, baseline details, statistical significance, or ablation results, preventing assessment of whether data supports the central claim.
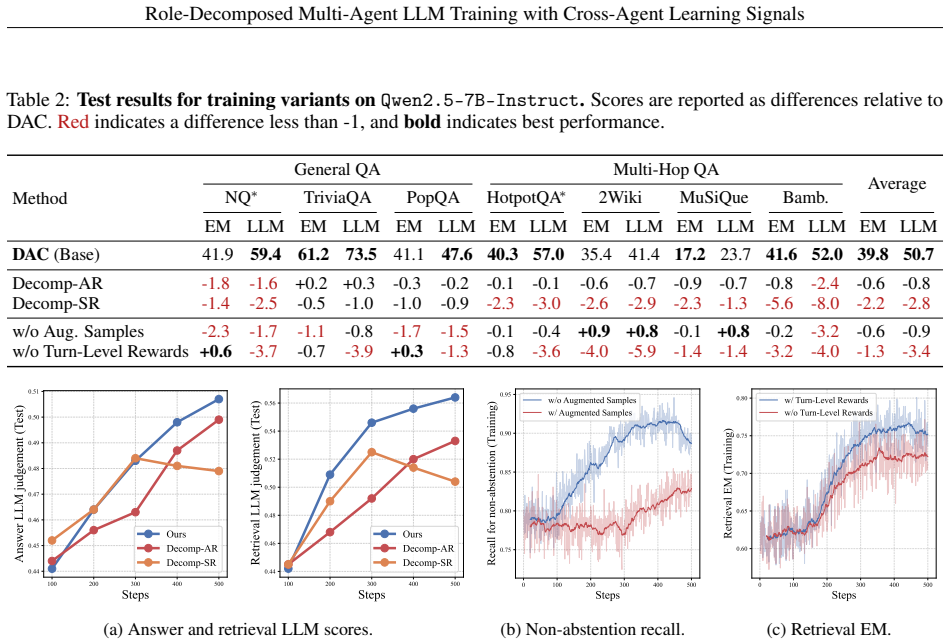
- Abstention-to-reward conversion (described in Abstract and implied in the method): The generator's abstention decision when evidence is insufficient is converted into a structured reward signal for the searcher. No implementation details, threshold, or validation experiments are supplied. This mechanism is load-bearing for the credit-assignment improvement claim; if abstention correlates with generation difficulty rather than objective evidence sufficiency, the cross-agent signal could introduce bias or instability rather than resolve the problem.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: The abstract asserts strong benchmark performance but supplies no metrics, baseline details, statistical significance, or ablation results, preventing assessment of whether data supports the central claim.
Authors: We agree that the abstract is currently too high-level. In the revised manuscript we will add concrete performance numbers (e.g., exact accuracy/F1 gains on the reported QA benchmarks), name the primary baselines, and briefly note the ablation results that support the contribution of the cross-agent signals. revision: yes
-
Referee: Abstention-to-reward conversion (described in Abstract and implied in the method): The generator's abstention decision when evidence is insufficient is converted into a structured reward signal for the searcher. No implementation details, threshold, or validation experiments are supplied. This mechanism is load-bearing for the credit-assignment improvement claim; if abstention correlates with generation difficulty rather than objective evidence sufficiency, the cross-agent signal could introduce bias or instability rather than resolve the problem.
Authors: The current manuscript describes the abstention signal at a conceptual level but does not supply the precise threshold, reward-mapping formula, or dedicated validation experiments that would allow readers to assess whether abstention tracks evidence sufficiency rather than generation difficulty. We will add these implementation details, the exact threshold used, and an ablation that isolates the correlation between abstention and evidence quality in the revised version. revision: yes
Circularity Check
No circularity: method described without equations or self-referential reductions
full rationale
The abstract and description present DAC as a role-decomposed training framework using LoRA modules, with abstention signals and cross-agent rewards defined descriptively. No equations, fitted parameters renamed as predictions, or self-citations are provided that would allow any load-bearing claim to reduce to its own inputs by construction. The performance claim is empirical against baselines and does not invoke uniqueness theorems or ansatzes from prior author work. The derivation chain is therefore self-contained against external benchmarks with no detectable circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning to Give Checkable Answers with Prover-Verifier Games.arXiv:2108.12099 [cs.LG],
Cem Anil, Guodong Zhang, Yuhuai Wu, and Roger Grosse. Learning to Give Checkable Answers with Prover-Verifier Games.arXiv:2108.12099 [cs.LG],
-
[2]
5-thinking: Advancing superb reasoning models with reinforcement learning , author=
ByteDance Seed. Seed1.5-Thinking: Advancing Superb Reasoning Models with Reinforcement Learning. arXiv:2504.13914 [cs.CL],
-
[3]
Yiqun Chen, Lingyong Yan, Zixuan Yang, Erhan Zhang, Jiashu Zhao, Shuaiqiang Wang, Dawei Yin, and Jiaxin Mao. Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search.arXiv:2601.04703 [cs.AI],
-
[4]
Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han
International Committee on Computational Linguistics. Pengcheng Jiang, Xueqiang Xu, Jiacheng Lin, Jinfeng Xiao, Zifeng Wang, Jimeng Sun, and Jiawei Han. s3: You Don’t Need That Much Data to Train a Search Agent via RL. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical...
2025
-
[5]
Towards a Science of Scaling Agent Systems
Association for Computational Linguistics. Yubin Kim, Ken Gu, Chanwoo Park, Chunjong Park, Samuel Schmidgall, A. Ali Heydari, Yao Yan, Zhihan Zhang, Yuchen Zhuang, Yun Liu, Mark Malhotra, Paul Pu Liang, Hae Won Park, Yuzhe Yang, Xuhai Xu, Yilun Du, Shwetak Patel, Tim Althoff, Daniel McDuff, and Xin Liu. Towards a Science of Scaling Agent Systems.arXiv:251...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Prover-Verifier Games improve legibility of LLM outputs.arXiv:2407.13692 [cs.CL],
Jan Hendrik Kirchner, Yining Chen, Harri Edwards, Jan Leike, Nat McAleese, and Yuri Burda. Prover-Verifier Games improve legibility of LLM outputs.arXiv:2407.13692 [cs.CL],
-
[7]
Tongyi DeepResearch Technical Report
Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhang, Zile Qiao, Chenxi Wang, Donglei Yu, Gang Fu, Haiyang Shen, Jiayi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
Xuan-Phi Nguyen, Shrey Pandit, Revanth Gangi Reddy, Austin Xu, Silvio Savarese, Caiming Xiong, and Shafiq Joty. SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents. arXiv:2509.06283 [cs.AI],
-
[9]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b Model Card.arXiv:2508.10925 [cs.CL],
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis
Association for Computational Linguistics. Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, December
2023
-
[11]
Association for Computational Linguistics. Qwen Team. Qwen2.5 technical report.arXiv:2412.15115 [cs.CL], 2025a. Qwen Team. Qwen3 technical report.arXiv:2505.09388 [cs.CL], 2025b. John Schulman and Thinking Machines Lab. LoRA Without Regret.Thinking Machines Lab: Connectionism,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proximal Policy Optimization Algorithms
URLhttps://thinkingmachines.ai/blog/lora/. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms.arXiv:1707.06347 [cs.LG],
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL],
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Association for Computing Machinery. Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning.arXiv:2503.05592 [cs.AI],
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Association for Computational Linguistics. Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv:2212.03533 [cs.CL],
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
11 Role-Decomposed Multi-Agent LLM Training with Cross-Agent Learning Signals Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceed...
2018
-
[17]
GRAIT: Gradient-Driven Refusal-Aware Instruction Tuning for Effective Hallucination Mitigation
Runchuan Zhu, Zinco Jiang, Jiang Wu, Zhipeng Ma, Jiahe Song, Fengshuo Bai, Dahua Lin, Lijun Wu, and Conghui He. GRAIT: Gradient-Driven Refusal-Aware Instruction Tuning for Effective Hallucination Mitigation. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational Linguistics: NAACL 2025, pages 4006–4021, Albuquerq...
2025
-
[18]
Therefore, the generator’s threshold is determined by a trade-off between the reward for abstaining on insufficient evidence, weighted by α, and the reward for answering on hard but sufficient evidence, weighted by γcG(1). That is, when the generator is sufficiently accurate on hard-evidence inputs and the effective proportion of hard-sufficient examples ...
2025
-
[19]
For Qwen2.5-7B-Instruct, both agents use learning rate 1×10 −6
with β1 = 0.9, β2 = 0.999, and weight decay 0.01. For Qwen2.5-7B-Instruct, both agents use learning rate 1×10 −6. ForQwen3-8B, the searcher uses learning rate2×10 −6 and the generator uses learning rate1×10 −5. We train for 500 steps and save checkpoints every 100 steps. In any case that training diverges, we evaluate the last stable checkpoint according ...
2025
-
[20]
The EM-based verification scores for answer correctness and evidence sufficiency are computed as follows. After basic text normalization, an answer is correct if it exactly matches the gold answer, and an evidence set is sufficient if any retrieved document contains the gold answer as an exact string match. For noise-based evidence augmentation, we retrie...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.