Spatial-Omni: Spatial Audio Understanding Integration in Multimodal LLMs via FOA Encoding
Pith reviewed 2026-06-27 11:51 UTC · model grok-4.3
The pith
Spatial-Omni adds an independent SO-Encoder for First-Order Ambisonics signals to existing Omni LLMs so they gain spatial audio understanding without changing the original audio encoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
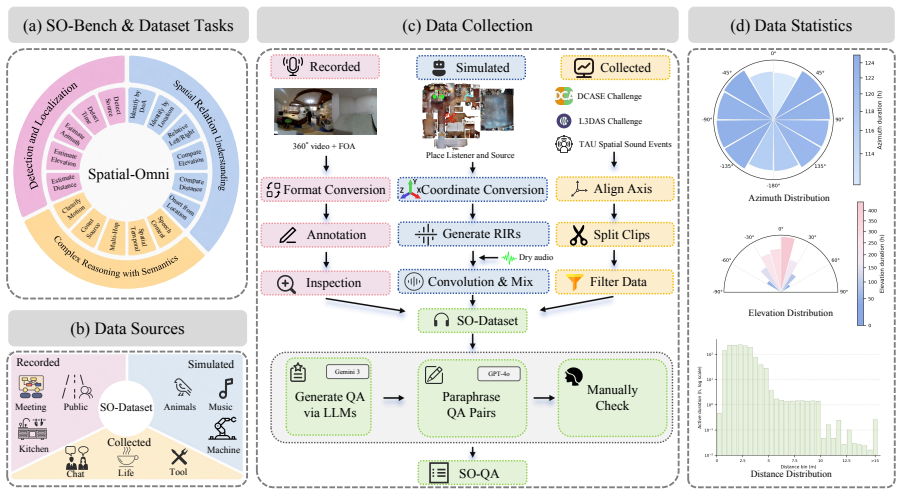
Spatial-Omni implements an SO-Encoder that processes First-Order Ambisonics signals as a separate modality and supplies spatial tokens to Omni LLMs. Staged training on the constructed SO-Dataset, SO-QA, and SO-Bench enables the model to outperform existing Large Audio-Language Models and Omni LLM models on spatial audio understanding while retaining reasonable general audio understanding.
What carries the argument
The SO-Encoder, an independent module that encodes First-Order Ambisonics spatial audio into tokens with limited added context cost.
If this is right
- Existing Omni LLMs can process spatial audio for localization and relation reasoning without any change to their original audio encoder.
- Staged training keeps general audio capabilities intact while adding the new spatial tokens.
- A single lightweight encoder supports 16 subtasks from basic detection to complex spatial reasoning.
- The method scales from open-source data, real recordings, and simulations totaling 400K clips and 2.1M QA pairs.
Where Pith is reading between the lines
- The same modular encoder pattern could be tested with higher-order ambisonics or binaural formats.
- Spatial token addition might improve downstream tasks such as robotic navigation that rely on sound direction.
- If the encoder stays small, similar independent modules could add other missing modalities like depth or thermal data.
Load-bearing premise
The staged training and separate SO-Encoder can add usable spatial tokens without lowering the base model's performance on ordinary non-spatial audio.
What would settle it
A measurable drop in accuracy on standard non-spatial audio benchmarks after the SO-Encoder and staged training are added, compared with the unmodified base model.
Figures



read the original abstract
Recent multimodal large language models mainly process audio as monaural signals, thereby discarding the spatial cues contained in spatial audio for sound localization, spatial relation reasoning, and spatial scene understanding. We propose Spatial-Omni, a lightweight method that implements SO-Encoder to inject First-Order Ambisonics (FOA) spatial audio into existing Omni LLMs as an independent modality, without modifying their original audio encoders. SO-Encoder provides spatial tokens with limited additional context cost and improves spatial audio understanding through efficient staged training. To support training and evaluation, we construct SO-Dataset, SO-QA, and SO-Bench from open-source data, real recordings, and simulations, containing 400K FOA spatial audio clips and 2.1M spatial question answering pairs. SO-Bench covers 16 spatial audio understanding subtasks, including basic detection and location estimation, spatial relation understanding, and complex spatial reasoning. Experiments show that Spatial-Omni outperforms existing open-source Large Audio-Language Models (LALMs) and Omni LLM models on spatial audio understanding tasks while retaining a reasonable level of general audio understanding. Code and data are available at https://github.com/dieKarotte/Spatial-Omni.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spatial-Omni, a lightweight integration method that adds an independent SO-Encoder to inject First-Order Ambisonics (FOA) spatial tokens into existing Omni LLMs without altering their original audio encoders. It constructs SO-Dataset (400K FOA clips), SO-QA, and SO-Bench (2.1M QA pairs across 16 subtasks covering detection, localization, spatial relations, and complex reasoning) from mixed open-source, real, and simulated sources. Staged training is used to add spatial capability while claiming retention of general audio performance; experiments are asserted to show outperformance over open-source LALMs and Omni models on spatial tasks.
Significance. If the empirical results are robust, the work would meaningfully address the monaural limitation of current multimodal LLMs by enabling spatial audio reasoning at modest context cost. The construction and public release of SO-Dataset/SO-Bench plus code availability support reproducibility and further research on spatial audio benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that 'Spatial-Omni outperforms existing open-source Large Audio-Language Models (LALMs) and Omni LLM models on spatial audio understanding tasks' is presented without any quantitative metrics, baseline names, absolute or relative scores, statistical tests, or error analysis; this absence is load-bearing for the empirical contribution.
- [Method and Experiments] §3 (method) and §4 (experiments): the assertion that the independent SO-Encoder and staged training 'retain a reasonable level of general audio understanding' requires explicit before/after metrics on non-spatial benchmarks together with ablation results on token fusion and context overhead; without these the no-degradation claim cannot be evaluated.
minor comments (2)
- [Dataset Construction] Provide a table listing the 16 subtasks in SO-Bench with sample counts and source breakdown (open-source vs. real vs. simulated).
- [SO-Encoder] Clarify the exact projection dimensions, token count, and fusion mechanism of the SO-Encoder in a dedicated subsection or figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments below and will revise the manuscript to strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Spatial-Omni outperforms existing open-source Large Audio-Language Models (LALMs) and Omni LLM models on spatial audio understanding tasks' is presented without any quantitative metrics, baseline names, absolute or relative scores, statistical tests, or error analysis; this absence is load-bearing for the empirical contribution.
Authors: We agree that the abstract would be strengthened by including quantitative support for the outperformance claim. In the revised version we will add specific metrics (e.g., average accuracy gains on SO-Bench subtasks), name the main baselines, and report absolute/relative scores. revision: yes
-
Referee: [Method and Experiments] §3 (method) and §4 (experiments): the assertion that the independent SO-Encoder and staged training 'retain a reasonable level of general audio understanding' requires explicit before/after metrics on non-spatial benchmarks together with ablation results on token fusion and context overhead; without these the no-degradation claim cannot be evaluated.
Authors: We acknowledge that explicit before/after numbers on standard non-spatial audio benchmarks, plus ablations on fusion and context cost, are needed to substantiate the retention claim. We will add these results and ablations to §4 in the revision. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical engineering contribution: an independent SO-Encoder added to existing Omni LLMs via staged training, plus newly constructed SO-Dataset/SO-Bench. No equations, fitted parameters, or derivations are presented that could reduce to inputs by construction. The central claim rests on experimental outcomes (outperformance on spatial tasks while retaining general audio capability), which are externally falsifiable via the released code and data rather than self-referential. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- SO-Encoder token count and projection dimensions
- Staged training schedule and learning rates
axioms (1)
- domain assumption Existing Omni LLMs can accept additional independent token streams from a new encoder without retraining or architectural changes to the original audio pathway.
invented entities (1)
-
SO-Encoder
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Savvy: Spatial awareness via audio-visual llms through seeing and hearing.Advances in Neural Information Processing Systems, 38:118999–119038. Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others. 2024. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Gheorghe Coma...
Pith/arXiv arXiv 2024
-
[2]
Gama: A large audio-language model with ad- vanced audio understanding and complex reasoning abilities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6288–6313. Yuan Gong, Yu-An Chung, and James Glass. 2021. Ast: Audio spectrogram transformer.arXiv preprint arXiv:2104.01778. Eric Guizzo, Christian Marinoni...
arXiv 2024
-
[3]
Overview of the l3das23 challenge on audio- visual extended reality. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–2. IEEE. Ayushi Mishra, Yang Bai, Priyadarshan Narayanasamy, Nakul Garg, and Nirupam Roy. 2025. Spatial audio processing with large language model on wearable devices.arXiv prepr...
arXiv 2023
-
[4]
OpenReview preprint, submitted to NeurIPS 2025
Hear you are: Teaching llms spatial reasoning with vision and spatial sound. OpenReview preprint, submitted to NeurIPS 2025. S Sakshi, Vaibhavi Lokegaonkar, Neil Zhang, Ramani Duraiswami, Sreyan Ghosh, Dinesh Manocha, and Lie Lu. 2025a. Spur: A plug-and-play framework for integrating spatial audio understanding and reasoning into large audio-language mode...
arXiv 2025
-
[5]
Spatial audio question answering and reason- ing on dynamic source movements.arXiv preprint arXiv:2602.16334. Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, and 1 others
-
[6]
Parthasaarathy Sudarsanam and Archontis Politis
The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797. Parthasaarathy Sudarsanam and Archontis Politis. 2025. Towards spatial audio understanding via question answering.arXiv preprint arXiv:2507.09195. Peiwen Sun, Sitong Cheng, Xiangtai Li, Zhen Ye, Huadai Liu, Honggang Zhang, Wei Xue, and Yike Guo. 2024. Both ears wide o...
Pith/arXiv arXiv 1906
-
[7]
Spatial blind spot: Auditory motion per- ception deficits in audio llms.arXiv preprint arXiv:2511.13273. Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Jun Zhang, Lu Lu, Zejun Ma, Yuxuan Wang, and 1 others. 2024a. Can large language models understand spatial audio?arXiv preprint arXiv:2406.07914. Changli Tang, Wenyi Yu, Guangzhi Su...
arXiv 2026
-
[8]
The world is not mono: Enabling spatial un- derstanding in large audio-language models.arXiv preprint arXiv:2601.02954. 12 Hogeon Yu. 2024. Doa and event guidance system for sound event localization and detection with source distance estimation. Technical report, DCASE2024 Challenge. Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng ...
Pith/arXiv arXiv 2024
-
[9]
The question must be answerable from the provided metadata
-
[10]
The question should focus on spatial audio understanding, such as source detection, direction estimation, distance estimation, motion analysis, spatial relation reasoning, or speech content under spatial conditions
-
[11]
Do not mention metadata fields explicitly in the question
-
[12]
The answer should be concise and factual
-
[13]
Metadata: {metadata} Please generate {num_questions} question-answer pairs in JSON format
If multiple sound sources are present, ensure that the question clearly specifies the target source, time interval, or spatial condition. Metadata: {metadata} Please generate {num_questions} question-answer pairs in JSON format. Prompt used for QA paraphrasing You are given a spatial audio question-answer pair. Your task is to rewrite the question into a ...
-
[14]
Do not change the answer
-
[15]
Do not introduce new spatial information
-
[16]
Keep the rewritten question answerable from the same audio clip
-
[17]
Avoid overly formal or repetitive wording
-
[18]
Original question: {question} Answer: {answer} Return only the rewritten question
Preserve the target source, time interval, and spatial relation if they are mentioned in the original question. Original question: {question} Answer: {answer} Return only the rewritten question. H Licenses and A vailability We respect the original licenses of all referenced ar- tifacts and do not redistribute them. This work uses publicly available datase...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.