READER: Robust Evidence-based Authorship Decoding via Extracted Representations
Pith reviewed 2026-06-27 13:17 UTC · model grok-4.3
The pith
A proxy LLM decodes the source of black-box responses by mapping outputs to activation space and accumulating evidence across prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
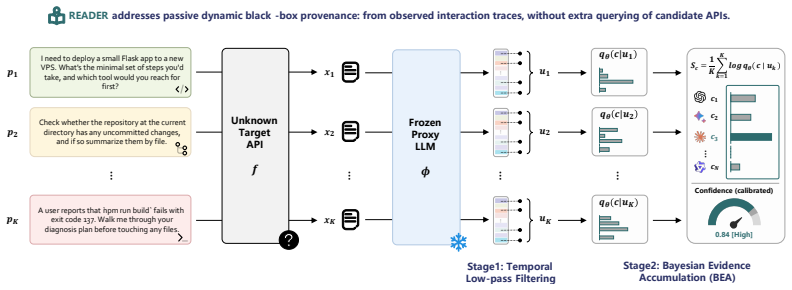
READER treats a frozen proxy LLM as a reader of hidden authorship evidence. Black-box outputs are mapped into proxy activation space; token states within each response are temporally filtered; and single-response log-posterior evidence is summed across independently sampled prompts. This Bayesian Evidence Accumulation avoids fragile mean-pooling while preserving query-wise information, converting weak model-specific traces into calibrated multi-query attribution on agent-style prompts.
What carries the argument
Bayesian Evidence Accumulation over temporally filtered proxy activations, which sums log-posterior evidence across prompts to isolate model-specific traces.
If this is right
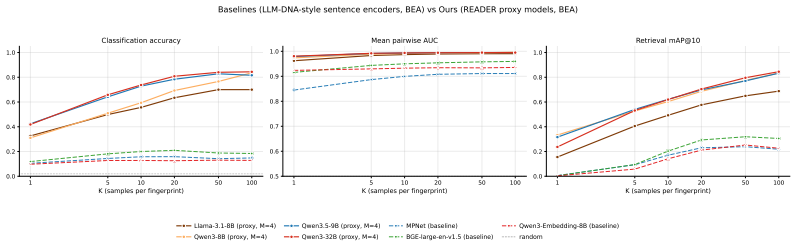
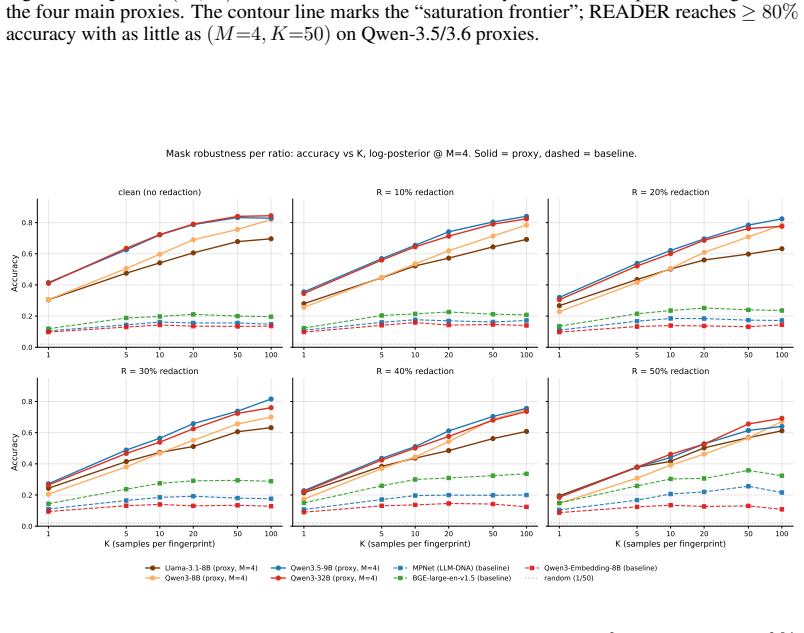
- Top-1 accuracy scales from 31-42% with one response to 70-84% with fifty responses.
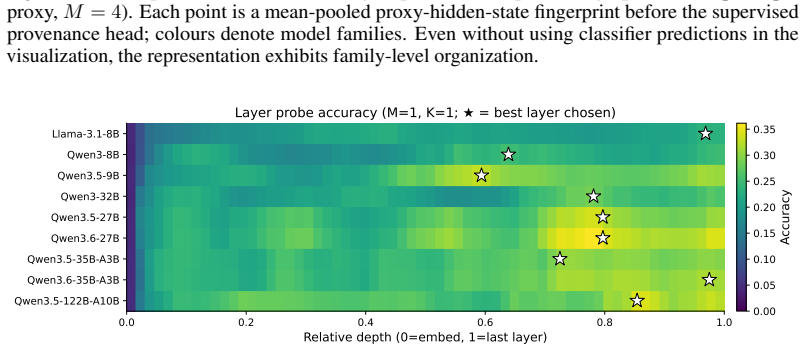
- Stronger proxy LLMs expose more linearly decodable authorship structure.
- The approach outperforms sentence-encoder fingerprints without requiring fixed benchmarks or mean-pooling.
- Provenance becomes feasible in dynamic black-box settings where prompts are query-varying and non-predefined.
Where Pith is reading between the lines
- Authorship information may already be linearly readable in the internal states of many LLMs without task-specific training.
- The same accumulation technique could be tested on distinguishing outputs from fine-tuned variants of the same base model.
- If the traces persist across prompt domains, the framework might apply to other attribution tasks such as source tracing in multi-model pipelines.
Load-bearing premise
Consistent model-specific traces exist in the proxy activation space and survive temporal filtering even though prompt semantics dominate the surface text.
What would settle it
If READER accuracy on Agent500 drops below sentence-encoder baselines when the same method is applied to a new set of agent-style prompts or a different collection of proxy LLMs.
Figures





















read the original abstract
As agentic applications increasingly route user tasks through official and third-party LLM APIs, provenance becomes an operational question: which model generated a given black-box response? We study Dynamic Black-Box LLM Provenance: identifying the source LLM from generations elicited by query-varying, non-predefined prompts rather than a fixed input set or benchmark suite. This setting is difficult because prompt semantics dominate the text, while model-specific authorship traces are weak and inconsistent at the surface level. We introduce READER (Robust Evidence-based Authorship Decoding via Extracted Representations), a lightweight provenance framework that treats a frozen proxy LLM as a reader of hidden authorship evidence. READER maps black-box outputs into proxy activation space, temporally filters token states within each response, and performs Bayesian Evidence Accumulation by summing single-response log-posterior evidence across independently sampled prompts. This avoids fragile mean-pooling of prompt-specific representations while preserving the query-wise evidence needed for calibrated confidence. On Agent500, a 50-target dataset built from agent-style prompts, READER reaches $31.0$-$42.4\%$ top-1 accuracy from a single response and $70.0$-$84.0\%$ from 50 responses, substantially outperforming sentence-encoder fingerprints. Scaling across nine proxy readers further shows that stronger LLMs expose more linearly decodable authorship structure, suggesting that authorship perception is already present in frozen LLM representations and can be converted into reliable multi-query attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces READER, a framework for dynamic black-box LLM provenance that maps generated responses into the activation space of a frozen proxy LLM, applies temporal filtering to token states within each response, and performs Bayesian log-posterior summation across multiple independent prompts to accumulate evidence for source-model attribution. On the Agent500 dataset of agent-style prompts, it reports single-response top-1 accuracies of 31.0–42.4% and 50-response accuracies of 70.0–84.0%, outperforming sentence-encoder baselines, with additional scaling results across nine proxy readers indicating that stronger LLMs yield more linearly decodable authorship structure.
Significance. If the central performance claims and the necessity of the proposed mechanisms hold after verification, the work would be significant for operational provenance in LLM API ecosystems. It provides evidence that model-specific traces can be extracted from proxy activations despite prompt dominance, and the scaling observation links proxy strength to attribution reliability. The lightweight, black-box nature and multi-query calibration are practical strengths.
major comments (2)
- [Method description and experimental results (abstract and §4)] The manuscript reports end-to-end accuracies but supplies no component ablations or comparisons to simpler baselines (e.g., mean-pooling of the same proxy activations followed by majority vote). Without these, it is impossible to determine whether temporal filtering plus Bayesian accumulation (rather than proxy choice or dataset construction) drives the reported gains over sentence-encoder fingerprints; this directly affects the load-bearing claim that the two mechanisms isolate consistent authorship traces.
- [Experimental evaluation (abstract and results section)] No error bars, statistical significance tests, dataset-construction protocol, or baseline implementation details are provided for the 31.0–42.4% and 70.0–84.0% figures. This prevents assessment of whether the outperformance is robust or could be explained by variance or artifacts in Agent500.
minor comments (2)
- [Framework description] Notation for the Bayesian accumulation step (log-posterior summation) should be formalized with explicit equations rather than prose description.
- [Scaling experiments] Clarify how the nine proxy readers were selected and whether their relative strengths were controlled for size or training data.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our work. We address each of the major comments below.
read point-by-point responses
-
Referee: [Method description and experimental results (abstract and §4)] The manuscript reports end-to-end accuracies but supplies no component ablations or comparisons to simpler baselines (e.g., mean-pooling of the same proxy activations followed by majority vote). Without these, it is impossible to determine whether temporal filtering plus Bayesian accumulation (rather than proxy choice or dataset construction) drives the reported gains over sentence-encoder fingerprints; this directly affects the load-bearing claim that the two mechanisms isolate consistent authorship traces.
Authors: We acknowledge the absence of component ablations in the current manuscript. To address this, we will include in the revision ablations that compare the full READER pipeline against mean-pooling of proxy activations with majority vote, as well as variants without temporal filtering and without Bayesian accumulation. These additions will help isolate the contribution of each proposed mechanism to the observed performance gains over sentence-encoder baselines. While the outperformance suggests the mechanisms are effective, we agree that explicit controls are necessary to substantiate the claim. revision: yes
-
Referee: [Experimental evaluation (abstract and results section)] No error bars, statistical significance tests, dataset-construction protocol, or baseline implementation details are provided for the 31.0–42.4% and 70.0–84.0% figures. This prevents assessment of whether the outperformance is robust or could be explained by variance or artifacts in Agent500.
Authors: We agree that providing error bars, statistical significance tests, the dataset construction protocol, and baseline implementation details is important for assessing robustness. In the revised manuscript, we will add these elements, including standard deviations across multiple runs where applicable, p-values for comparisons, and expanded descriptions of how Agent500 was constructed and how baselines were implemented. revision: yes
Circularity Check
No significant circularity; empirical framework with no visible self-referential derivations.
full rationale
The provided abstract and framework description introduce READER via proxy activation mapping, temporal filtering of token states, and Bayesian log-posterior summation across prompts, with empirical accuracies reported on Agent500. No equations, fitting procedures, or derivation steps are exhibited that reduce a claimed result to its inputs by construction (e.g., no self-definitional parameters or predictions that are statistically forced). Performance claims rest on end-to-end experiments rather than a closed mathematical chain, and no self-citations or uniqueness theorems are invoked in the visible text. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023. https: //transformer-cir...
2023
-
[2]
Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
Pith/arXiv arXiv 2022
-
[3]
LLM fingerprinting via semantically conditioned watermarks
Thibaud Gloaguen, Robin Staab, Nikola Jovanovi´c, and Martin Vechev. LLM fingerprinting via semantically conditioned watermarks. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[4]
TRAP: Targeted random adversarial prompt honeypot for black-box identification
Martin Gubri, Dennis Ulmer, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. TRAP: Targeted random adversarial prompt honeypot for black-box identification. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11496–11517, 2024
2024
-
[5]
Designing and interpreting probes with control tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 2733–2743, 2019. 10
2019
-
[6]
On the origins of linear representations in large language models
Yibo Jiang, Goutham Rajendran, Pradeep Kumar Ravikumar, Bryon Aragam, and Victor Veitch. On the origins of linear representations in large language models. InProceedings of the 41st International Conference on Machine Learning, pages 21879–21911, 2024
2024
-
[7]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023
2023
-
[8]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, pages 3519–3529, 2019
2019
-
[9]
Robust distortion- free watermarks for language models.Transactions on Machine Learning Research, 2024
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion- free watermarks for language models.Transactions on Machine Learning Research, 2024
2024
-
[10]
Style-specific neurons for steering LLMs in text style transfer
Wen Lai, Viktor Hangya, and Alexander Fraser. Style-specific neurons for steering LLMs in text style transfer. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 13427–13443, 2024
2024
-
[11]
A structured self-attentive sentence embedding
Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. InInternational Conference on Learning Representations, 2017
2017
-
[12]
Your large language models are leaving fingerprints
Hope McGovern, Rickard Stureborg, Yoshi Suhara, and Dimitris Alikaniotis. Your large language models are leaving fingerprints. InProceedings of the 1st Workshop on GenAI Content Detection, pages 85–95, 2025
2025
-
[13]
Scalable fingerprinting of large language models
Anshul Nasery, Jonathan Hayase, Creston Brooks, Peiyao Sheng, Himanshu Tyagi, Pramod Viswanath, and Sewoong Oh. Scalable fingerprinting of large language models. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[14]
Model provenance testing for large language models
Ivica Nikolic, Teodora Baluta, and Prateek Saxena. Model provenance testing for large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[15]
GPT-4o system card
OpenAI. GPT-4o system card. https://openai.com/index/gpt-4o-system-card/ , 2024
2024
-
[16]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InProceedings of the 41st International Conference on Machine Learning, pages 39643–39666, 2024
2024
-
[17]
Kornaropoulos, and Giuseppe Ateniese
Dario Pasquini, Evgenios M. Kornaropoulos, and Giuseppe Ateniese. LLMmap: Fingerprinting for large language models. In34th USENIX Security Symposium, pages 299–318, 2025
2025
-
[18]
Are you copying my model? protecting the copyright of large language models for eaas via backdoor watermark
Wenjun Peng, Jingwei Yi, Fangzhao Wu, Shangxi Wu, Bin Bin Zhu, Lingjuan Lyu, Binxing Jiao, Tong Xu, Guangzhong Sun, and Xing Xie. Are you copying my model? protecting the copyright of large language models for eaas via backdoor watermark. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 7653–7668, 2023
2023
-
[19]
Provable model provenance set for large language models.arXiv preprint arXiv:2602.00772, 2026
Xiaoqi Qiu, Hao Zeng, Zhiyu Hou, and Hongxin Wei. Provable model provenance set for large language models.arXiv preprint arXiv:2602.00772, 2026
arXiv 2026
-
[20]
Abhilasha Ravichander, Yonatan Belinkov, and Eduard H. Hovy. Probing the probing paradigm: Does probing accuracy entail task relevance? InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, pages 3363–3377, 2021
2021
-
[21]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 15504–15522, 2024
2024
-
[22]
Tak, Amin Banayeeanzade, Anahita Bolourani, Mina Kian, Robin Jia, and Jonathan Gratch
Ala N. Tak, Amin Banayeeanzade, Anahita Bolourani, Mina Kian, Robin Jia, and Jonathan Gratch. Mechanistic interpretability of emotion inference in large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 13090–13120, 2025. 11
2025
-
[23]
Yuqiao Tan, Minzheng Wang, Shizhu He, Huanxuan Liao, Chengfeng Zhao, Qiunan Lu, Tian Liang, Jun Zhao, and Kang Liu. Bottom-up policy optimization: Your language model policy secretly contains internal policies.arXiv preprint arXiv:2512.19673, 2025
Pith/arXiv arXiv 2025
-
[24]
Paul Tschisgale and Peter Wulff. Evidence for daily and weekly periodic variability in gpt-4o performance.arXiv preprint arXiv:2602.15889, 2026
Pith/arXiv arXiv 2026
-
[25]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574, 2024
Pith/arXiv arXiv 2024
-
[26]
Zehao Wu, Yanjie Zhao, and Haoyu Wang. Gradient-based model fingerprinting for LLM similarity detection and family classification.arXiv preprint arXiv:2506.01631, 2025
arXiv 2025
-
[27]
Llm dna: Tracing model evolution via functional representations
Zhaomin Wu, Haodong Zhao, Ziyang Wang, Jizhou Guo, Qian Wang, and Bingsheng He. Llm dna: Tracing model evolution via functional representations. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[28]
Instruc- tional fingerprinting of large language models
Jiashu Xu, Fei Wang, Mingyu Ma, Pang Wei Koh, Chaowei Xiao, and Muhao Chen. Instruc- tional fingerprinting of large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3277–3306, 2024
2024
-
[29]
MergePrint: Merge- resistant fingerprints for robust black-box ownership verification of large language models
Shojiro Yamabe, Futa Kai Waseda, Tsubasa Takahashi, and Koki Wataoka. MergePrint: Merge- resistant fingerprints for robust black-box ownership verification of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 6894–6916, 2025
2025
-
[30]
Toward efficient agents: Memory, tool learning, and planning
Xiaofang Yang, Lijun Li, Heng Zhou, Tong Zhu, Xiaoye Qu, Yuchen Fan, Qianshan Wei, Rui Ye, Li Kang, Yiran Qin, et al. Toward efficient agents: Memory, tool learning, and planning. arXiv preprint arXiv:2601.14192, 2026
arXiv 2026
-
[31]
A fingerprint for large language models.arXiv preprint arXiv:2407.01235, 2024
Zhiguang Yang and Hanzhou Wu. A fingerprint for large language models.arXiv preprint arXiv:2407.01235, 2024
arXiv 2024
-
[32]
PhyloLM: Inferring the phylogeny of large language models and predicting their performances in benchmarks
Nicolas Yax, Pierre-Yves Oudeyer, and Stefano Palminteri. PhyloLM: Inferring the phylogeny of large language models and predicting their performances in benchmarks. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[33]
HuRef: Human-readable fingerprint for large language models
Boyi Zeng, Lizheng Wang, Yuncong Hu, Yi Xu, Chenghu Zhou, Xinbing Wang, Yu Yu, and Zhouhan Lin. HuRef: Human-readable fingerprint for large language models. InAdvances in Neural Information Processing Systems, volume 37, pages 126332–126362, 2024
2024
-
[34]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Feijiang Han, et al. Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models.arXiv preprint arXiv:2601.14004, 2026
Pith/arXiv arXiv 2026
-
[35]
REEF: Representation encoding fingerprints for large language models
Jie Zhang, Dongrui Liu, Chen Qian, Linfeng Zhang, Yong Liu, Yu Qiao, and Jing Shao. REEF: Representation encoding fingerprints for large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[36]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. 12 A READER Inference Algorithm Algorithm 1READER inference with Bayesian Evidence Accumulation Input:...
Pith/arXiv arXiv 2023
-
[37]
The training cross-entropy stalls at ≈2.28 (Tab
The M=4 regime collapses outright.Across all six K-values, attn-pool loses 14–35 percentage points of test accuracy. The training cross-entropy stalls at ≈2.28 (Tab. 11), close to ln(C/5)≈2.30 — in other words, the joint head fails to converge in 60 epochs, and the softmax over M=4 positions never finds a sparse weighting that outperforms the uniform one....
-
[38]
Crucially, the fold-to-fold standard deviation grows by 5–7× (e.g
Larger M partly mitigates but never reverses the loss.At M=8 and M=16 the attn-pool head does converge (L ≈1.96 and 1.09 respectively), but its test accuracy is uniformly belowthe uniform-pool accuracy by up to 23.8 pp. Crucially, the fold-to-fold standard deviation grows by 5–7× (e.g. M=8, K=50: 0.017 mean-pool vs. 0.065 attn-pool). The attn-pool solutio...
-
[39]
Empirically all three behave the same: 45/45 non-degenerate cells across the three proxies are ∆acc ≤ −0.054
The negative result is independent of subspace entanglementandof the cross- K aggre- gator.Under the principal-angle reading, the qwen3-8b intra-view is degenerate ( θ1 ≈0 ◦) and should be theworstcase for a learnable position weighting; the two other proxies have θ1 ∈[43.6 ◦,53.1 ◦] and should be thebestcases. Empirically all three behave the same: 45/45...
-
[40]
12) sits at M=1, where Eq
The only positive cell confirms M=1 is degenerate, not useful.The only ∆>0 cell in the K≤50 sweep (Tab. 12) sits at M=1, where Eq. 4 reduces to identity and the gain is bounded by +0.001. This is the expected σ-level fluctuations of joint AdamW vs. closed-form LR under finite folds, not evidence of a learnable signal: at M=1 theonlything wattn controls is...
-
[41]
This pin-points the optimisation pathology in Sec
The M=4 collapse is the deepest undereveryproxy.The worst ∆acc per proxy within the K≤50 operating regime is −0.334 (qwen3-8b), −0.224 (qwen3.5-9b), and −0.250 (llama-3.1-8b-base), all atM=4. This pin-points the optimisation pathology in Sec. D.2.3, item 3, as proxy-independent: a 4-position softmax with ∼3 effective degrees of freedom is precisely the re...
-
[42]
M large ⇒ uniform αm ≡1/M approaches the optimum ⇒ optimiser converges back to mean- pool faster
Empirical trajectory.The M=1→16 contraction is exactly the shape predicted by “M large ⇒ uniform αm ≡1/M approaches the optimum ⇒ optimiser converges back to mean- pool faster”. Linear extrapolation gives ∆(M=32)∼ −2 to −5 pp and ∆(M=∞)→0 −, never positive
-
[43]
information-poor token
Hidden-state redundancy at the chosen layer.At layers ℓ⋆ ∈ {19,23,31} each response- internal token has already integrated the full prefix via self-attention; cross-position infor- mation is strongly overlapping (cf. Sec. D.3.2, where θ8 ≥85.2 ◦ for every proxy/view). There is no large “information-poor token” mass in the M-window for an attention head to...
-
[44]
find the few high-Rpositions
Fisher-ratio profile under M.Tab. 13 shows the per-position authorship signal is either flat in M (Qwen3-8B) ordecreasing( R drops 6×–22× between M=1 and M=16 on the other two proxies), so the upper bound for any data-driven re-weighting is at best the M=1 Fisher ratio and the expected return from “find the few high-Rpositions” is small. We did not extend...
-
[45]
Following the principal-angle analysis of Tab
Proxy hidden states are already heavily contextualised.At ℓ⋆=23 of Qwen3-8B (60% depth), each of the Mmax=16 response-internal tokens has, via self-attention inside the proxy, integrated information from the full 128-token suffix. Following the principal-angle analysis of Tab. 14, the leading semantic direction is partially shared across positions while t...
-
[46]
Joint training distorts the StandardScaler basis.The mean-pool baseline is trained as W·StandardScaler(u (c,p)), with closed-form per-feature moments. Joint AdamW on (wattn,W) freely shifts the implicit feature mean as α moves, whichunscalesthe LR head’s input distribution; this is consistent with the heavy F1 collapse on a few classes (Tab. 10) being dri...
-
[47]
The M=4 pathology is an optimisation, not a capacity, failure.With only four positions to attend over and 50 classes, the softmax has 3 effective degrees of freedom per sample; combined with the small number of joint training steps (60 epochs × 80 batches/epoch) this leaves the head firmly in the local-minimum regime where it neither collapses to uniform ...
-
[48]
1 M P m is a fixed linear map; W is trained by convex L2-regularised multinomial logistic regression on its output
Mean-pool has no such optimisation surface. 1 M P m is a fixed linear map; W is trained by convex L2-regularised multinomial logistic regression on its output. There is no joint local minimum to fall into, no fold-to-fold attention drift, and no calibration distortion. This is why mean-pool’s fold standard deviations (Tab. 9) are 3–7× tighter than attn-po...
-
[49]
Q-LP.Does M-averaging by itself amplify the authorship-to-semantic signal-to-noise ratio?
-
[50]
The dataset comprises C=50 target LLMs queried on P=500 shared agent-domain probe prompts
Q-Geom.How are the semantic and authorship subspaces geometrically arranged in the proxy at the chosen layer? Setup.We cross three proxies ϕ∈ {Qwen3-8B,Qwen3.5-9B,Llama-3.1-8B} , each at its best probe layer ℓ⋆ ∈ {23,19,31} respectively. The dataset comprises C=50 target LLMs queried on P=500 shared agent-domain probe prompts. We extract two feature views...
-
[51]
Q-LLN.Does averaging K filtered features u(c,pk) contract the semantic variance and lift the Fisher ratioR= Var between/Varwithin monotonically withK?
-
[52]
information-theoretic soft-gate
Q-Csem.Is the limiting semantic centroid Ep[S(p)] a rigid, model-independent constant — the closed-form premise that would let mean-pooling recovera (c) exactly? Setup.Three proxies ϕ∈ {Qwen3-8B,Qwen3.5-9B,Llama-3.1-8B} at their best probe layers ℓ⋆ ∈ {23,19,31} . We use Agent500 (P=500 ) with C=50 target LLMs. For each proxy, we evaluate two feature view...
arXiv 2090
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.