Recognition: no theorem link
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Pith reviewed 2026-05-16 12:37 UTC · model grok-4.3
The pith
A survey frames mechanistic interpretability as a locate-steer-improve pipeline that turns diagnostic findings into targeted interventions for LLM alignment, capability, and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
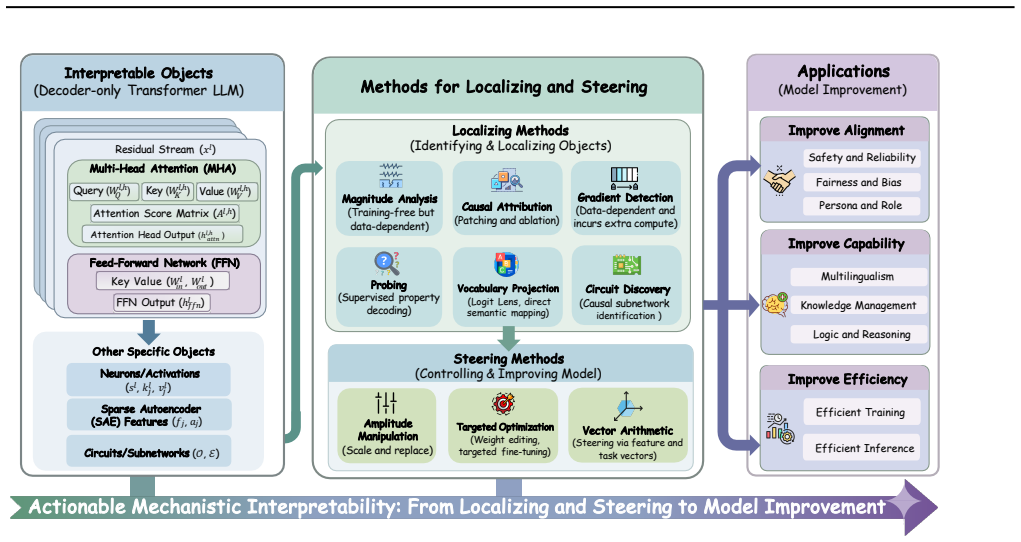
Mechanistic Interpretability can be turned into an actionable methodology for model optimization by structuring work around a Locate-Steer-Improve pipeline. Localization and steering techniques are formally categorized by the interpretable objects they target, yielding a rigorous protocol whose application demonstrably improves alignment, capability, and efficiency in large language models.
What carries the argument
The Locate-Steer-Improve pipeline, which sequences diagnosis of interpretable objects in LLMs with targeted interventions to produce measurable model improvements.
If this is right
- Practitioners can diagnose specific model behaviors by matching failure modes to the categorized localization methods.
- Steering interventions become more precise because they are indexed to the same interpretable objects used in diagnosis.
- Model updates for alignment or efficiency can be performed with less full retraining by reusing the locate-steer steps.
- The same object-based protocol can be applied across multiple models to compare their internal structures directly.
Where Pith is reading between the lines
- The pipeline could be tested on multimodal models to see whether the same object categories transfer beyond text.
- If the categorization proves stable, it might reduce the need for separate interpretability research tracks focused only on analysis.
- Adoption would require benchmark suites that measure intervention success rather than only interpretability metrics.
Load-bearing premise
Existing mechanistic interpretability methods can be systematically grouped by their interpretable objects into one unified protocol that reliably delivers measurable gains in alignment, capability, and efficiency.
What would settle it
A controlled test in which a standard suite of localization and steering techniques, when applied according to the object-based categorization, produces no statistically significant improvement on alignment or capability benchmarks would falsify the central claim.
Figures








read the original abstract
Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a survey of mechanistic interpretability (MI) techniques for large language models, organized around a three-stage pipeline of 'Locate' (identifying interpretable features or circuits), 'Steer' (intervening on those features), and 'Improve' (applying the interventions to enhance model properties). It categorizes localization and steering methods according to specific 'Interpretable Objects' to create a unified intervention protocol. The authors demonstrate the framework's utility by reviewing how it facilitates improvements in alignment, capability, and efficiency, supported by a curated collection of papers available on GitHub.
Significance. If the proposed categorization holds, this work is significant in transforming MI from a primarily diagnostic tool into an actionable methodology for model development. By providing a structured pipeline and taxonomy based on interpretable objects, it offers practitioners a clear protocol for applying MI techniques. The inclusion of a publicly available curated list enhances the survey's value as a resource for the community, potentially accelerating research in alignment and optimization of LLMs. The explicit structure around Locate-Steer-Improve distinguishes it from prior observational surveys.
major comments (1)
- [§3] §3 (Categorization by Interpretable Objects): The claim that the taxonomy establishes a 'rigorous intervention protocol' is undercut by the absence of explicit decision criteria or decision tree for assigning methods to object categories (e.g., how a hybrid activation-weight method is classified); this makes the protocol less reproducible than asserted.
minor comments (3)
- [Abstract] Abstract: The phrase 'formally categorize' overstates the contribution; the categorization is a useful descriptive taxonomy rather than a formal mathematical framework.
- [§4.3] §4.3 (Efficiency improvements): The discussion of efficiency gains cites prior work but does not quantify trade-offs (e.g., steering overhead vs. inference savings); adding a summary table would strengthen the claim.
- [Introduction] GitHub link: The curated list is a strength, but the manuscript should include a brief description of inclusion/exclusion criteria used to build the list.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recognition of the survey's potential to transform mechanistic interpretability into an actionable methodology. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation of the taxonomy.
read point-by-point responses
-
Referee: [§3] §3 (Categorization by Interpretable Objects): The claim that the taxonomy establishes a 'rigorous intervention protocol' is undercut by the absence of explicit decision criteria or decision tree for assigning methods to object categories (e.g., how a hybrid activation-weight method is classified); this makes the protocol less reproducible than asserted.
Authors: We agree that explicit decision criteria would enhance the reproducibility of the classification. The taxonomy in §3 groups methods according to the primary interpretable object they target (activations, weights, circuits, or representations), which forms the basis of the Locate-Steer-Improve protocol. For hybrid methods, the manuscript implicitly classifies them by the dominant intervention target, but we acknowledge this is not stated with sufficient precision. In the revised version, we will add a dedicated subsection (or appendix) containing a decision flowchart and explicit criteria: methods are assigned to the category matching their primary object, with hybrids noted as such and classified by the component that drives the intervention effect. This will make the protocol more rigorous without changing the core taxonomy. revision: yes
Circularity Check
No significant circularity: survey organizes external literature without derivations
full rationale
The manuscript is a survey paper that proposes an organizational taxonomy and pipeline ('Locate, Steer, and Improve') for existing mechanistic interpretability methods. It aggregates and categorizes prior work by 'Interpretable Objects' but contains no equations, fitted parameters, predictions, or novel derivations that could reduce to inputs by construction. All substantive claims rest on citations to external literature; the GitHub-curated list and three-stage structure are presented as curatorial contributions rather than self-derived results. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. This is the standard non-circular outcome for a well-structured survey.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mechanistic interpretability yields insights that can be turned into actionable interventions for LLMs
Forward citations
Cited by 7 Pith papers
-
Navigating by Old Maps: The Pitfalls of Static Mechanistic Localization in LLM Post-Training
Transformer circuits show free evolution during SFT, rendering static mechanistic localization inadequate for future parameter updates due to inherent temporal latency.
-
Attention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
The first survey on Attention Sink in Transformers structures the literature around fundamental utilization, mechanistic interpretation, and strategic mitigation.
-
Freeze Deep, Train Shallow: Interpretable Layer Allocation for Continued Pre-Training
Freezing deep layers and training shallow layers during continued pre-training of LLMs outperforms full fine-tuning and the opposite allocation on C-Eval and CMMLU, guided by a new layer-sensitivity diagnostic.
-
From Attribution to Action: A Human-Centered Application of Activation Steering
Activation steering paired with attribution enables intervention-based debugging in vision models, as all 8 interviewed experts shifted to hypothesis testing, most trusted observed responses, and highlighted risks lik...
-
Head-wise Modality Specialization within MLLMs for Robust Fake News Detection under Missing Modality
Head-wise modality specialization via attention constraints and unimodal knowledge retention in MLLMs improves robustness to missing modalities in fake news detection while preserving full multimodal performance.
-
SnapMLA: Efficient Long-Context MLA Decoding via Hardware-Aware FP8 Quantized Pipelining
SnapMLA achieves up to 1.91x higher throughput in long-output MLA decoding using FP8 quantization and specialized kernels while keeping benchmark quality near the BF16 baseline.
-
Qwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
Qwen-Scope provides open-source sparse autoencoders for Qwen models that function as practical interfaces for steering, evaluating, data workflows, and optimizing large language models.
Reference graph
Works this paper leans on
- [1]
-
[2]
Symbols of One-Loop Integrals From Mixed Tate Motives
Mst. Shapna Akter, Hossain Shahriar, Alfredo Cuzzocrea, and Fan Wu. Uncovering the interpretation of large language models. In Hossain Shahriar, Hiroyuki Ohsaki, Moushumi Sharmin, Dave Towey, A. K. M. Jahangir Alam Majumder, Yoshiaki Hori, Ji-Jiang Yang, Michiharu Takemoto, Nazmus Sakib, Ryohei Banno, and Sheikh Iqbal Ahamed, editors,48th IEEE Annual Comp...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/compsac61105.2024.00143 2024
-
[3]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Workshop Track Proceedings. OpenReview.net, 2017. URLhttps://openreview.net/ forum?id=HJ4-rAVtl
work page 2017
-
[4]
Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 1, learning hierarchical language structures.arXiv preprint arXiv:2305.13673, 2023
-
[5]
Emmanuel Ameisen, Jack Lindsey, Adam Pearce, Wes Gurnee, Nicholas L. Turner, Brian Chen, Craig Citro, David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton, Trenton Bricken, Callum McDougall, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson, Sam Zimmerman, Kelley Rivo...
work page 2025
-
[6]
Systematic outliers in large language models.arXiv preprint arXiv:2502.06415, 2025
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Systematic outliers in large language models.arXiv preprint arXiv:2502.06415, 2025
-
[7]
Sparse autoencoders can capture language-specific concepts across diverse languages, 2025
Lyzander Marciano Andrylie, Inaya Rahmanisa, Mahardika Krisna Ihsani, Alfan Farizki Wicaksono, Haryo Akbarianto Wibowo, and Alham Fikri Aji. Sparse autoencoders can capture language-specific concepts across diverse languages, 2025. URLhttps://arxiv.org/abs/2507.11230
-
[8]
Saes are good for steering–if you select the right features.arXiv preprint arXiv:2505.20063, 2025
Dana Arad, Aaron Mueller, and Yonatan Belinkov. Saes are good for steering–if you select the right features.arXiv preprint arXiv:2505.20063, 2025
-
[9]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Balcells Obeso, Aaquib Syed, Daniel Paleka, Nina Rimsky, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/ forum?id=pH3XAQME6c
work page 2024
-
[10]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213–100240, 2024. URL https://dl.acm.org/doi/10.5555/3737916.3741096
-
[11]
Behrooz Azarkhalili and Maxwell W. Libbrecht. Generalized attention flow: Feature attribution for transformer models via maximum flow. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, 54 and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, ...
work page 2025
-
[12]
Understanding jailbreak success: A study of latent space dynamics in large language models, 2024
Sarah Ball, Frauke Kreuter, and Nina Panickssery. Understanding jailbreak success: A study of latent space dynamics in large language models, 2024. URLhttps://arxiv.org/abs/2406.09289
-
[13]
Amin Banayeeanzade, Ala N Tak, Fatemeh Bahrani, Anahita Bolourani, Leonardo Blas, Emilio Ferrara, Jonathan Gratch, and Sai Praneeth Karimireddy. Psychological steering in llms: An evaluation of effectiveness and trustworthiness.arXiv preprint arXiv:2510.04484, 2025
-
[14]
Tetiana Bas and Krystian Novak. Steering latent traits, not learned facts: An empirical study of activation control limits.arXiv preprint arXiv:2511.18284, 2025
-
[15]
Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177, 2025
Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar, and Pascal Vincent. Steering large language model activations in sparse spaces.arXiv preprint arXiv:2503.00177, 2025
-
[16]
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Comput. Linguistics, 48 (1):207–219, 2022. doi: 10.1162/COLI\_A\_00422. URLhttps://doi.org/10.1162/coli_ a_00422
-
[17]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082, 2024
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082, 2024
-
[19]
Unveiling visual perception in language models: An attention head analysis approach
Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, Bingjie Wang, and Chenliang Xu. Unveiling visual perception in language models: An attention head analysis approach. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4135–4144, 2025. URL https://openaccess.thecvf.com/content/CVPR2025/papers/Bi_Unveiling_ Visu...
work page 2025
-
[20]
Hopping too late: Exploring the limitations of large language models on multi-hop queries
Eden Biran, Daniela Gottesman, Sohee Yang, Mor Geva, and Amir Globerson. Hopping too late: Exploring the limitations of large language models on multi-hop queries. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16,...
-
[21]
Open source sparse autoencoders for all residual stream layers of gpt2 small, 2024
Joseph Bloom. Open source sparse autoencoders for all residual stream layers of gpt2 small, 2024. URL https://www.alignmentforum.org/posts/f9EgfLSurAiqRJySD/ open-source-sparse-autoencoders-for-all-residual-stream
work page 2024
-
[22]
Quantizable transform- ers: Removing outliers by helping attention heads do nothing
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transform- ers: Removing outliers by helping attention heads do nothing. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 75067–75096. Curran Associates, Inc., 2023. URL https://procee...
work page 2023
-
[23]
Beyond Multiple Choice: Evaluating Steering Vectors for Summarization
Joschka Braun, Carsten Eickhoff, and Seyed Ali Bahrainian. Beyond multiple choice: Evaluating steering vectors for adaptive free-form summarization.arXiv preprint arXiv:2505.24859, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Trenton Bricken and Cengiz Pehlevan. Attention approximates sparse distributed memory.Advances in Neural Information Processing Systems, 34:15301–15315, 2021
work page 2021
-
[25]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and Ch...
work page 2023
-
[26]
Jannik Brinkmann, Chris Wendler, Christian Bartelt, and Aaron Mueller. Large language models share representations of latent grammatical concepts across typologically diverse languages. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguist...
-
[27]
Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410, 2024
-
[28]
Locating and Mitigating Gender Bias in Large Language Models, March 2024a
Yuchen Cai, Ding Cao, Rongxi Guo, Yaqin Wen, Guiquan Liu, and Enhong Chen. Locating and Mitigating Gender Bias in Large Language Models, March 2024a
-
[29]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024b
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Spectral filters, dark signals, and attention sinks
Nicola Cancedda. Spectral filters, dark signals, and attention sinks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4792–4808, 2024
work page 2024
-
[31]
Dissecting Bias in LLMs: A Mechanistic Inter- pretability Perspective, June 2025
Bhavik Chandna, Zubair Bashir, and Procheta Sen. Dissecting Bias in LLMs: A Mechanistic Inter- pretability Perspective, June 2025
work page 2025
-
[32]
Yuan Chang, Ziyue Li, Hengyuan Zhang, Yuanbo Kong, Yanru Wu, Zhijiang Guo, and Ngai Wong. Treereview: A dynamic tree of questions framework for deep and efficient llm-based scientific peer review.arXiv preprint arXiv:2506.07642, 2025
-
[33]
David Chanin, James Wilken-Smith, Tomás Dulka, Hardik Bhatnagar, and Joseph Bloom. A is for absorption: Studying feature splitting and absorption in sparse autoencoders.CoRR, abs/2409.14507,
-
[34]
doi: 10.48550/ARXIV.2409.14507. URL https://doi.org/10.48550/arXiv.2409. 14507
-
[35]
Transferring linear features across language models with model stitching
Alan Chen, Jack Merullo, Alessandro Stolfo, and Ellie Pavlick. Transferring linear features across language models with model stitching. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. 56
-
[36]
Towards under- standing safety alignment: A mechanistic perspective from safety neurons, 2025b
Jianhui Chen, Xiaozhi Wang, Zijun Yao, Yushi Bai, Lei Hou, and Juanzi Li. Towards under- standing safety alignment: A mechanistic perspective from safety neurons, 2025b. URLhttps: //openreview.net/forum?id=1NkrxqY4jK
-
[37]
Identifying query-relevant neurons in large language models for long-form texts
Lihu Chen, Adam Dejl, and Francesca Toni. Identifying query-relevant neurons in large language models for long-form texts. In Toby Walsh, Julie Shah, and Zico Kolter, editors,AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 23595–23604. AAAI Press, 2025c. doi: 1...
-
[38]
Learnable privacy neurons localization in language models
Ruizhe Chen, Tianxiang Hu, Yang Feng, and Zuozhu Liu. Learnable privacy neurons localization in language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 256–264, Bangkok, Thailand, August 2024a. Association for Computat...
-
[39]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509, 2025d
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
In-context sharpness as alerts: An inner representation perspective for hallucination mitigation
Shiqi Chen, Miao Xiong, Junteng Liu, Zhengxuan Wu, Teng Xiao, Siyang Gao, and Junxian He. In-context sharpness as alerts: An inner representation perspective for hallucination mitigation. In Forty-first International Conference on Machine Learning, 2024b. URLhttps://openreview.net/ forum?id=s3e8poX3kb
-
[41]
From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning
Wei Chen, Zhen Huang, Liang Xie, Binbin Lin, Houqiang Li, Le Lu, Xinmei Tian, Deng Cai, Yong- gang Zhang, Wenxiao Wang, Xu Shen, and Jieping Ye. From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning. InForty-first International Conference on Machine Learning, 2024c. URLhttps://openreview.net/forum?id=d2vONO90Rw
-
[43]
Yuheng Chen, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Journey to the center of the knowl- edge neurons: Discoveries of language-independent knowledge neurons and degenerate knowledge neurons. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors,Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Con...
-
[44]
Yuheng Chen, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Knowledge localization: Mission not accomplished? enter query localization! InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025f. URLhttps: //openreview.net/forum?id=tfyHbvFZ0K. 57
work page 2025
-
[47]
Hakaze Cho, Haolin Yang, Brian M Kurkoski, and Naoya Inoue. Binary autoencoder for mechanistic interpretability of large language models.arXiv preprint arXiv:2509.20997, 2025
-
[48]
IkhyunChoandJuliaHockenmaier. Towardefficientsparseautoencoder-guidedsteeringforimproved in-context learning in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28949–28961, 2025
work page 2025
-
[49]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth Interna- tional Conference on Learning Representations, 2024. URLhttps://openreview.net/forum? id=Th6NyL07na
work page 2024
-
[50]
Henry Conklin and Kenny Smith. Representations as language: An information-theoretic framework for interpretability.arXiv preprint arXiv:2406.02449, 2024
-
[51]
Towards automated circuit discovery for mechanistic interpretability
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga- Alonso. Towards automated circuit discovery for mechanistic interpretability. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 16318–16352. Curran Associates, Inc., 20...
work page 2023
-
[52]
What you can cram into a single \$&!#* vector: Probing sentence embeddings for linguistic properties
Alexis Conneau, Germán Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. What you can cram into a single \$&!#* vector: Probing sentence embeddings for linguistic properties. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July...
-
[53]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Can we interpret latent reasoning using current mechanistic interpretabil- ity tools?, 2025
Bartosz Cywiński, Bart Bussmann, Arthur Conmy, Josh Engels, Neel Nanda, and Senthooran Rajamanoharan. Can we interpret latent reasoning using current mechanistic interpretabil- ity tools?, 2025. URL https://www.alignmentforum.org/posts/YGAimivLxycZcqRFR/ can-we-interpret-latent-reasoning-using-current-mechanistic
work page 2025
-
[55]
Patrick Queiroz Da Silva, Hari Sethuraman, Dheeraj Rajagopal, Hannaneh Hajishirzi, and Sachin Kumar. Steering off course: Reliability challenges in steering language models.arXiv preprint arXiv:2504.04635, 2025. 58
-
[56]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 8493–85...
-
[57]
Adam Davies and Ashkan Khakzar. The cognitive revolution in interpretability: From explaining behavior to interpreting representations and algorithms.arXiv preprint arXiv:2408.05859, 2024
-
[58]
Neuron based personality trait induction in large language models
Jia Deng, Tianyi Tang, Yanbin Yin, Wenhao yang, Xin Zhao, and Ji-Rong Wen. Neuron based personality trait induction in large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=LYHEY783Np
work page 2025
-
[59]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35: 30318–30332, 2022
work page 2022
-
[60]
Tracing Positional Bias in Financial Decision-Making: Mechanistic Insights from Qwen2.5
Fabrizio Dimino, Krati Saxena, Bhaskarjit Sarmah, and Stefano Pasquali. Tracing Positional Bias in Financial Decision-Making: Mechanistic Insights from Qwen2.5. InProceedings of the 6th ACM International Conference on AI in Finance, pages 96–104, November 2025. doi: 10.1145/3768292. 3770394
-
[61]
From what to how: Attributing clip’s latent components reveals unexpected semantic reliance
Maximilian Dreyer, Lorenz Hufe, Jim Berend, Thomas Wiegand, Sebastian Lapuschkin, and Wojciech Samek. From what to how: Attributing clip’s latent components reveals unexpected semantic reliance. arXiv preprint arXiv:2505.20229, 2025
-
[62]
Yanrui Du, Sendong Zhao, Jiawei Cao, Ming Ma, Danyang Zhao, Fenglei Fan, Ting Liu, and Bing Qin. Towards secure tuning: Mitigating security risks arising from benign instruction fine-tuning.CoRR, abs/2410.04524, 2024. doi: 10.48550/ARXIV.2410.04524. URLhttps://doi.org/10.48550/ arXiv.2410.04524
-
[63]
Unveiling language competence neurons: A psycholinguistic approach to model interpretability
Xufeng Duan, Xinyu Zhou, Bei Xiao, and Zhenguang Cai. Unveiling language competence neurons: A psycholinguistic approach to model interpretability. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 10148–1...
work page 2025
-
[64]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints, pages arXiv–2407, 2024
work page 2024
-
[65]
Razvan-Gabriel Dumitru, Vikas Yadav, Rishabh Maheshwary, Paul-Ioan Clotan, Sathwik Tejaswi Madhusudhan, and Mihai Surdeanu. Layer-wise quantization: A pragmatic and effective method for quantizing llms beyond integer bit-levels.arXiv preprint arXiv:2406.17415, 2024
-
[66]
A mathemati- cal framework for transformer circuits.Transformer Circuits Thread, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario 59 Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah...
work page 2021
-
[67]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger B. Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition. CoRR, abs/2209.10652, 2022. doi: 10.48550/ARXIV.2209.10652. URLhttps://...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.10652 2022
-
[68]
LayerSkip: Enabling early exit inference and self-speculative decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole- Jean Wu. LayerSkip: Enabling early exit inference and self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual ...
-
[69]
Sequential integrated gradients: a simple but effective method for explaining language models
Joseph Enguehard. Sequential integrated gradients: a simple but effective method for explaining language models. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 7555–
work page 2023
-
[70]
doi: 10.18653/V1/2023.FINDINGS-ACL.477
Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.FINDINGS-ACL.477. URLhttps://doi.org/10.18653/v1/2023.findings-acl.477
-
[71]
Jiahai Feng and Jacob Steinhardt. How do language models bind entities in context? InNeurIPS 2023 Workshop on Symmetry and Geometry in Neural Representations, 2023
work page 2023
-
[72]
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R Costa-Jussà. A primer on the inner workings of transformer-based language models.arXiv preprint arXiv:2405.00208, 2024
-
[73]
Truthful or fabricated? using causal attribution to mitigate reward hacking in explanations
Pedro Ferreira, Wilker Aziz, and Ivan Titov. Truthful or fabricated? using causal attribution to mitigate reward hacking in explanations. InWorkshop on Actionable Interpretability at ICML 2025,
work page 2025
- [74]
-
[75]
Hiroki Furuta, Gouki Minegishi, Yusuke Iwasawa, and Yutaka Matsuo. Towards empirical in- terpretation of internal circuits and properties in grokked transformers on modular polynomials. Transactions on Machine Learning Research, 2024. URLhttps://openreview.net/forum?id= MzSf70uXJO
work page 2024
-
[76]
Andrey Galichin, Alexey Dontsov, Polina Druzhinina, Anton Razzhigaev, Oleg Y Rogov, Elena Tu- tubalina, and Ivan Oseledets. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders.arXiv preprint arXiv:2503.18878, 2025. URL https://arxiv.org/pdf/2503.18878
-
[77]
Sandeep Reddy Gantla. Exploring mechanistic interpretability in large language models: Challenges, approaches, and insights. In2025 International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI), pages 1–8. IEEE, 2025
work page 2025
-
[78]
H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms, 2025a
Cheng Gao, Huimin Chen, Chaojun Xiao, Zhiyi Chen, Zhiyuan Liu, and Maosong Sun. H-neurons: On the existence, impact, and origin of hallucination-associated neurons in llms, 2025a. URL https://arxiv.org/abs/2512.01797. 60
-
[79]
Scaling and evaluating sparse autoencoders
LeoGao, TomDuprélaTour, HenkTillman, GabrielGoh, RajanTroll, AlecRadford, IlyaSutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Weight-sparse transformers have interpretable circuits.arXiv preprint arXiv:2511.13653, 2025b
Leo Gao, Achyuta Rajaram, Jacob Coxon, Soham V Govande, Bowen Baker, and Dan Mossing. Weight-sparse transformers have interpretable circuits.arXiv preprint arXiv:2511.13653, 2025b
-
[81]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, et al. Causal abstraction: A theoretical foundation for mechanistic interpretability.Journal of Machine Learning Research, 26(83): 1–64, 2025
work page 2025
-
[82]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5484–5495, Online and Punta Cana, Dominican Republic, November
work page 2021
-
[83]
doi: 10.18653/v1/2021.emnlp-main.446
Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.446. URL https://aclanthology.org/2021.emnlp-main.446/
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.