Flaws in the LLM Automation Narrative
Pith reviewed 2026-06-27 10:50 UTC · model grok-4.3
The pith
Human experts outperform a frontier LLM on average and with less variability when writing code for a data analysis task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a novel task of writing computer code to complete a data analysis assignment, human experts achieve better average performance and lower variability than a frontier LLM, indicating that LLMs do not consistently match expert levels and that benchmarks must assess variance and error magnitude.
What carries the argument
The novel benchmarking task requiring participants to write computer code to complete a data analysis assignment, used to compare average performance, response variance, and error magnitude between the LLM and human experts.
If this is right
- Evaluations limited to average performance on standardized datasets can overstate LLM capabilities for real-world use.
- High-stakes contexts require explicit checks on performance variability and the size of individual errors.
- Claims of expert-level automation should be tested on tasks unlikely to appear in training data.
- Measuring error magnitude alongside averages gives a fuller picture of model suitability.
Where Pith is reading between the lines
- The same variance-focused approach could be applied to other domains where LLMs are proposed for expert replacement, such as legal drafting or medical summarization.
- Repeated testing on fresh tasks might show whether variability decreases as models improve or remains a persistent trait.
- Risk assessments for deploying LLMs in analysis pipelines should incorporate worst-case error sizes rather than averages alone.
Load-bearing premise
Writing code to finish a data analysis assignment serves as a valid proxy for the high-stakes knowledge-economy tasks where reliability and error magnitude matter most.
What would settle it
Finding that the LLM matches or exceeds human experts in average scores while showing equal or lower variability across several different novel data analysis coding tasks would undermine the central claim.
Figures
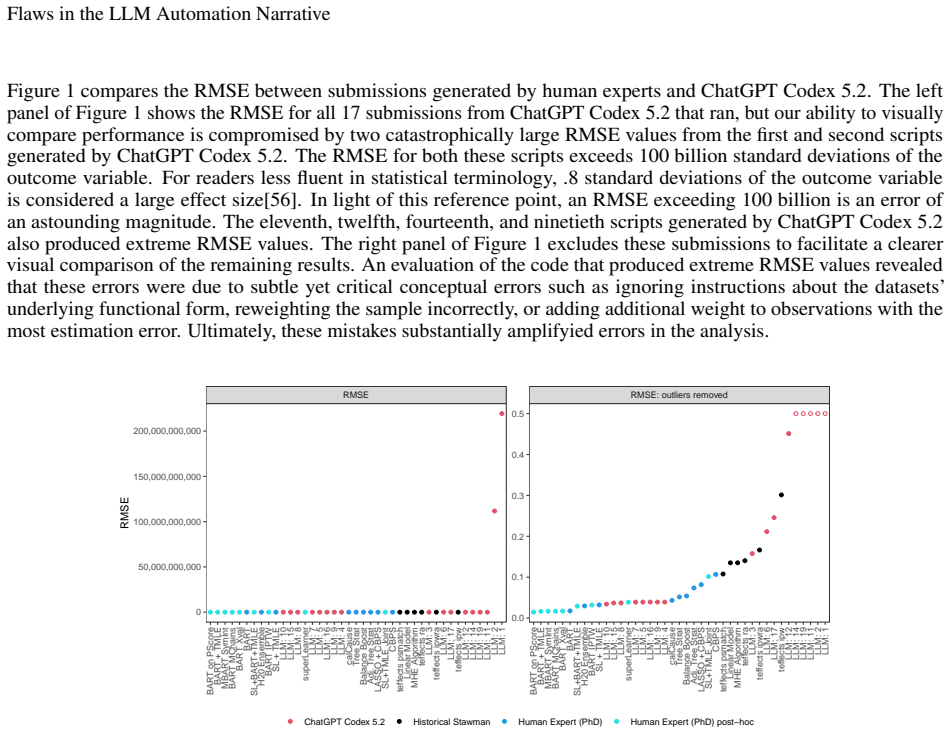
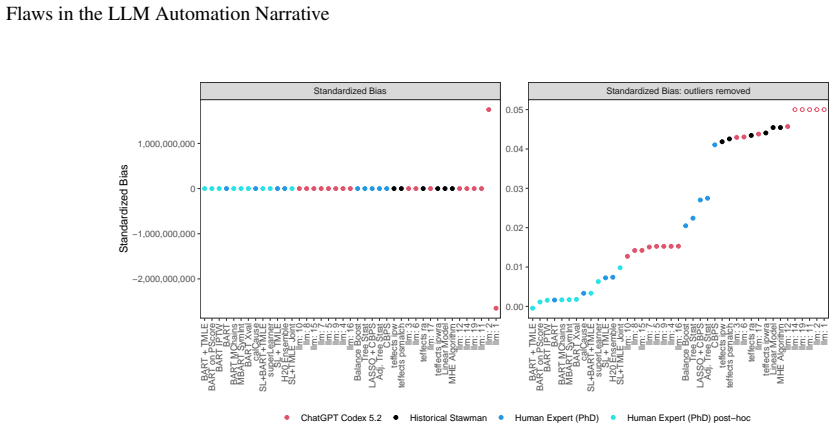
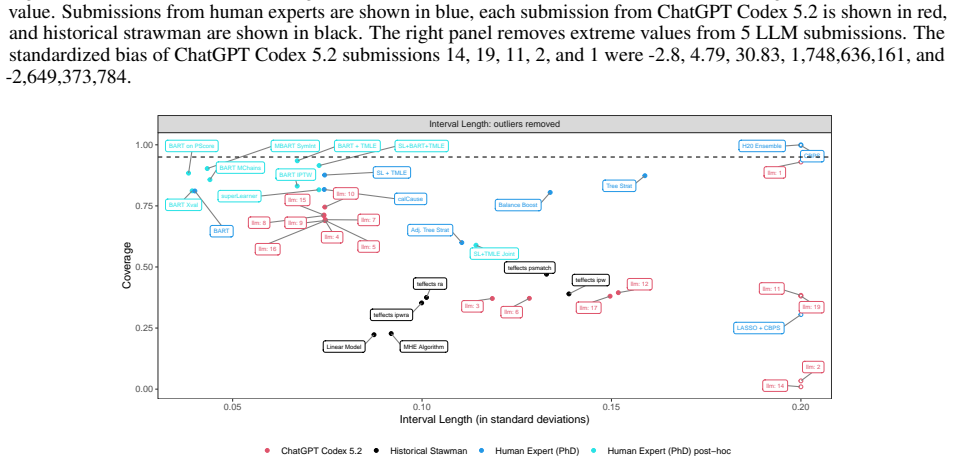
read the original abstract
Large Language Models (LLMs) are increasingly described as performing at the level of human experts on knowledge economy tasks. These claims are primarily based on how LLMs perform on benchmarking tasks that measure average performance across standardized datasets. Primary limitations of many benchmarking tasks are that they often measure performance based on content directly included in LLM training data, and they frequently do not assess the reliability of LLM performance or the magnitude of LLM errors. However, in high stakes contexts, these qualities are critically important. Through a novel LLM benchmarking task that requires writing computer code to complete a data analysis task, we compare the performance of a frontier LLM against submissions from human experts and explicitly measure the variance of responses and the magnitude of errors. Our study reveals that the human experts perform better on average on a range of metrics and demonstrate less variability in performance. Our results provide evidence that LLMs do not consistently perform at the level of human experts and demonstrate the importance of measuring variance and assessing error magnitude in LLM benchmark evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that claims of LLMs matching human experts on knowledge-economy tasks rest on flawed benchmarks that emphasize average performance on training-data-overlapping tasks while ignoring reliability and error magnitude. It introduces a novel benchmarking task—writing code to complete a data analysis assignment—and reports that human experts outperform a frontier LLM on average across metrics while exhibiting lower performance variability, thereby providing evidence against consistent LLM-expert parity and underscoring the value of variance and error-magnitude measurements.
Significance. If the empirical comparison is shown to be robust under controlled conditions with adequate sample size and clearly defined metrics, the result would usefully shift emphasis in LLM evaluation from mean benchmark scores toward reliability and tail-risk considerations, particularly for high-stakes applications.
major comments (2)
- [Abstract] Abstract: the central empirical claim that 'human experts perform better on average on a range of metrics and demonstrate less variability' is stated without any sample size for the human cohort, number of LLM samples or prompting protocol, explicit metric definitions, statistical tests, or error-bar information; this absence renders the variability conclusion unverifiable and is load-bearing for the paper's primary result.
- [Abstract] Abstract (benchmarking task paragraph): the novel coding-for-data-analysis task is presented as a proxy for high-stakes knowledge-economy work, yet no details are supplied on task standardization, human recruitment criteria, time limits, or how LLM outputs were evaluated for functional correctness versus stylistic quality; without these, the claimed superiority cannot be assessed for generalizability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of clarity and verifiability in our empirical claims. We address each major comment below, proposing revisions to the abstract to incorporate necessary details from the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that 'human experts perform better on average on a range of metrics and demonstrate less variability' is stated without any sample size for the human cohort, number of LLM samples or prompting protocol, explicit metric definitions, statistical tests, or error-bar information; this absence renders the variability conclusion unverifiable and is load-bearing for the paper's primary result.
Authors: The manuscript body provides these details: human cohort size of 15 experts, 50 LLM samples using a fixed prompting protocol, explicit metrics including functional correctness, code efficiency, and error magnitude, along with t-tests and standard error bars for variability comparisons. We agree the abstract should allow verification of the primary result and will revise it to include sample sizes, a brief metrics overview, and reference to the statistical analysis. This is a targeted addition that does not change the findings. revision: yes
-
Referee: [Abstract] Abstract (benchmarking task paragraph): the novel coding-for-data-analysis task is presented as a proxy for high-stakes knowledge-economy work, yet no details are supplied on task standardization, human recruitment criteria, time limits, or how LLM outputs were evaluated for functional correctness versus stylistic quality; without these, the claimed superiority cannot be assessed for generalizability.
Authors: The full paper specifies task standardization through a fixed data analysis assignment with clear requirements, human recruitment from professionals with at least five years of experience, time limits of two hours for humans matched by equivalent LLM inference budget, and evaluation separating functional correctness (via automated tests) from stylistic aspects (via expert rubric). We will update the abstract to concisely note these elements to support assessment of generalizability. revision: yes
Circularity Check
No circularity: direct empirical comparison with no derivations
full rationale
The paper reports an empirical study comparing frontier LLM performance against human experts on a novel coding-for-data-analysis task, measuring averages, variance, and error magnitude. No equations, parameter fits, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation chain. The central claim rests on observed outcomes from the benchmarking task rather than any reduction to inputs by construction. This matches the reader's assessment of score 0.0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Penguin Group, 2025
Karen Hao.Empire of AI: Dreams and nightmares in Sam Altman’s OpenAI. Penguin Group, 2025
2025
-
[3]
On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
2021
-
[4]
The cost of compute: A $7 trillion race to scale data centers.McKinsey & Company.[Online], 2025
Jesse Noffsinger, M Patel, P Sachdeva, A Bhan, H Chang, and M Goodpaster. The cost of compute: A $7 trillion race to scale data centers.McKinsey & Company.[Online], 2025
2025
-
[5]
Morris, M
S. Morris, M. Acton, and R. Rosner-Uddin. Big tech’s ‘breathtaking’ $660bn spending spree reignites ai bubble fears
-
[6]
Labor market impacts of ai: A new measure and early evidence
Maxim Massenkoff and Peter McCrory. Labor market impacts of ai: A new measure and early evidence. 2026
2026
-
[7]
Openai secures up to $110bn in record funding deal
The Financial Times. Openai secures up to $110bn in record funding deal
-
[8]
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, et al. Gdpval: Evaluating ai model performance on real-world economically valuable tasks.arXiv preprint arXiv:2510.04374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Introducing gpt-5
OpenAI. Introducing gpt-5. 2025. Accessed on October 23, 2025
2025
-
[10]
Openai claims gpt-5 model boosts chatgpt to ’phd level’
Lily Jamali and Liv McMahon. Openai claims gpt-5 model boosts chatgpt to ’phd level’. InBBC, 2025. Accessed on October 23, 2025
2025
-
[11]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
2019
-
[12]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024. 8 Flaws in the LLM Automation Narrative
2024
-
[13]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[14]
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models.Advances in neural information processing systems, 36:44123–44279, 2023
Neel Guha, Julian Nyarko, Daniel Ho, Christopher Ré, Adam Chilton, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel Rockmore, Diego Zambrano, et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models.Advances in neural information processing systems, 36:44123–44279, 2023
2023
-
[15]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, et al. Livebench: A challenging, contamination-free llm benchmark. arXiv preprint arXiv:2406.19314, 4:2, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Don’t make your llm an evaluation benchmark cheater.arXiv preprint arXiv:2311.01964, 2023
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. Don’t make your llm an evaluation benchmark cheater.arXiv preprint arXiv:2311.01964, 2023
-
[17]
Leak, cheat, repeat: Data contamina- tion and evaluation malpractices in closed-source llms
Simone Balloccu, Patrícia Schmidtová, Mateusz Lango, and Ondˇrej Dušek. Leak, cheat, repeat: Data contamina- tion and evaluation malpractices in closed-source llms. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (V olume 1: Long Papers), pages 67–93, 2024
2024
-
[18]
A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
2024
-
[19]
ai 1 Gatti Alice 1 Li Nathaniel 1 Khoja Adam 1 Kim Ryan 1 Ren Richard 1 Hausenloy Jason 1 Zhang Oliver 1 Mazeika Mantas 1 Hendrycks Dan dan@ safe
Center for AI Safety Phan Long agibenchmark@ safe. ai 1 Gatti Alice 1 Li Nathaniel 1 Khoja Adam 1 Kim Ryan 1 Ren Richard 1 Hausenloy Jason 1 Zhang Oliver 1 Mazeika Mantas 1 Hendrycks Dan dan@ safe. ai 1. A benchmark of expert-level academic questions to assess ai capabilities.Nature, 649(8099):1139–1146, 2026
2026
-
[20]
Designing life science assessments in the era of generative artificial intelligence.PloS one, 21(4):e0346127, 2026
Andrew C Kwong, Christopher Magnano, Cristina DeOliveira, Christine Goglia, Joseph J Loparo, and John Jacob Peters. Designing life science assessments in the era of generative artificial intelligence.PloS one, 21(4):e0346127, 2026
2026
-
[21]
Llms will always hallucinate, and we need to live with this
Sourav Banerjee, Ayushi Agarwal, and Saloni Singla. Llms will always hallucinate, and we need to live with this. InIntelligent Systems Conference, pages 624–648. Springer, 2025
2025
-
[22]
Do large language model benchmarks test reliability?arXiv preprint arXiv:2502.03461, 2025
Joshua Vendrow, Edward Vendrow, Sara Beery, and Aleksander Madry. Do large language model benchmarks test reliability?arXiv preprint arXiv:2502.03461, 2025
-
[23]
Prompt Stability Scoring for Text Annotation with Large Language Models
Christopher Barrie, Elli Palaiologou, and Petter TÃk, rnberg. Prompt stability scoring for text annotation with large language models.arXiv preprint arXiv:2407.02039, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Jialun Cao, Yuk-Kit Chan, Zixuan Ling, Wenxuan Wang, Shuqing Li, Mingwei Liu, Ruixi Qiao, Yuting Han, Chaozheng Wang, Boxi Yu, et al. How should we build a benchmark? revisiting 274 code-related benchmarks for llms.arXiv preprint arXiv:2501.10711, 2025
-
[25]
Claude-powered AI agent’s confession after deleting a firm’s entire database: ’i violated every principle i was given’.https://theguardian.com, apr 2026
Sanya Mansoor. Claude-powered AI agent’s confession after deleting a firm’s entire database: ’i violated every principle i was given’.https://theguardian.com, apr 2026. Accessed: 2026-06-03
2026
-
[26]
Climbing towards nlu: On meaning, form, and understanding in the age of data
Emily M Bender and Alexander Koller. Climbing towards nlu: On meaning, form, and understanding in the age of data. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 5185–5198, 2020
2020
-
[27]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Do large language models know what they are capable of?arXiv preprint arXiv:2512.24661, 2025
Casey O Barkan, Sid Black, and Oliver Sourbut. Do large language models know what they are capable of?arXiv preprint arXiv:2512.24661, 2025
-
[29]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[30]
Gpt-4 passes the bar exam
Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. Gpt-4 passes the bar exam. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 382(2270), 2024
2024
-
[31]
Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al. Finben: A holistic financial benchmark for large language models.Advances in Neural Information Processing Systems, 37:95716–95743, 2024. 9 Flaws in the LLM Automation Narrative
2024
-
[32]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Reliability of llms as medical assistants for the general public: a randomized preregistered study.Nature Medicine, pages 1–7, 2026
Andrew M Bean, Rebecca Elizabeth Payne, Guy Parsons, Hannah Rose Kirk, Juan Ciro, Rafael Mosquera-Gómez, Sara Hincapié M, Aruna S Ekanayaka, Lionel Tarassenko, Luc Rocher, et al. Reliability of llms as medical assistants for the general public: a randomized preregistered study.Nature Medicine, pages 1–7, 2026
2026
-
[34]
From scores to steps: Diagnosing and improving llm performance in evidence-based medical calculations
Benlu Wang, Iris Xia, Yifan Zhang, Junda Wang, Feiyun Ouyang, Shuo Han, Arman Cohan, Hong Yu, and Zonghai Yao. From scores to steps: Diagnosing and improving llm performance in evidence-based medical calculations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10820–10844, 2025
2025
-
[35]
A systematic review of large language model (llm) evaluations in clinical medicine.BMC Medical Informatics and Decision Making, 25(1):117, 2025
Sina Shool, Sara Adimi, Reza Saboori Amleshi, Ehsan Bitaraf, Reza Golpira, and Mahmood Tara. A systematic review of large language model (llm) evaluations in clinical medicine.BMC Medical Informatics and Decision Making, 25(1):117, 2025
2025
-
[36]
Why we need to be careful with llms in medicine.Frontiers in medicine, 11:1495582, 2024
Jean-Christophe Bélisle-Pipon. Why we need to be careful with llms in medicine.Frontiers in medicine, 11:1495582, 2024
2024
-
[37]
Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. Large legal fictions: Profiling legal hallucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
2024
-
[38]
Hallucination-free? assessing the reliability of leading ai legal research tools.Journal of empirical legal studies, 22(2):216–242, 2025
Varun Magesh, Faiz Surani, Matthew Dahl, Mirac Suzgun, Christopher D Manning, and Daniel E Ho. Hallucination-free? assessing the reliability of leading ai legal research tools.Journal of empirical legal studies, 22(2):216–242, 2025
2025
-
[39]
Zichen Chen, Jiaao Chen, Jianda Chen, and Misha Sra. Standard benchmarks fail–auditing llm agents in finance must prioritize risk.arXiv preprint arXiv:2502.15865, 2025
-
[40]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance agent benchmark: Benchmarking llms on real-world financial research tasks.arXiv preprint arXiv:2508.00828, 2025
-
[41]
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn $1 million from real-world freelance software engineering?arXiv preprint arXiv:2502.12115, 2025
-
[42]
David Noever and Forrest McKee. Can ai freelancers compete? benchmarking earnings, reliability, and task success at scale.arXiv preprint arXiv:2505.13511, 2025
-
[43]
Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein. Measuring the impact of early-2025 ai on experienced open-source developer productivity.arXiv preprint arXiv:2507.09089, 2025
-
[44]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
The genai divide state of ai in business 2025
Aditya Challapally, Chris Pease, Raskar Ramesh, and Chari Chari, Pradyumna. The genai divide state of ai in business 2025. Technical report, MIT NANDA, 2025
2025
-
[46]
Satellite Imagery Feature Detection using Deep Convolutional Neural Network: A Kaggle Competition
Vladimir Iglovikov, Sergey Mushinskiy, and Vladimir Osin. Satellite imagery feature detection using deep convolutional neural network: A kaggle competition.arXiv preprint arXiv:1706.06169, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Kaggle forecasting competitions: An overlooked learning opportunity.International Journal of F orecasting, 37(2):587–603, 2021
Casper Solheim Bojer and Jens Peder Meldgaard. Kaggle forecasting competitions: An overlooked learning opportunity.International Journal of F orecasting, 37(2):587–603, 2021
2021
-
[48]
Cambridge University Press, 2021
Andrew Gelman, Jennifer Hill, and Aki Vehtari.Regression and other stories. Cambridge University Press, 2021
2021
-
[49]
Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition
Vincent Dorie, Jennifer Hill, Uri Shalit, Marc Scott, and Dan Cervone. Automated versus do-it-yourself methods for causal inference: Lessons learned from a data analysis competition. 2019
2019
-
[50]
Machine learning for causal inference
Jennifer Hill, George Perrett, and Vincent Dorie. Machine learning for causal inference. InHandbook of matching and weighting adjustments for causal inference, pages 415–444. Chapman and Hall/CRC, 2023
2023
-
[51]
Estimating treatment effects with causal forests: An application.Observational studies, 5(2):37–51, 2019
Susan Athey and Stefan Wager. Estimating treatment effects with causal forests: An application.Observational studies, 5(2):37–51, 2019
2019
-
[52]
Estimation and inference of heterogeneous treatment effects using random forests
Stefan Wager and Susan Athey. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113(523):1228–1242, 2018
2018
-
[53]
Bayesian nonparametric modeling for causal inference.Journal of Computational and Graphical Statistics, 20(1):217–240, 2011
Jennifer L Hill. Bayesian nonparametric modeling for causal inference.Journal of Computational and Graphical Statistics, 20(1):217–240, 2011
2011
-
[54]
Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects (with discussion).Bayesian Analysis, 15(3):965–1056, 2020
P Richard Hahn, Jared S Murray, and Carlos M Carvalho. Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects (with discussion).Bayesian Analysis, 15(3):965–1056, 2020. 10 Flaws in the LLM Automation Narrative
2020
-
[55]
Causal methods madness: Lessons learned from the 2022 acic competition to estimate health policy impacts.Observational Studies, 9(3):3–27, 2023
Dan RC Thal and Mariel M Finucane. Causal methods madness: Lessons learned from the 2022 acic competition to estimate health policy impacts.Observational Studies, 9(3):3–27, 2023
2022
-
[56]
Routledge, 2013
Jacob Cohen, Patricia Cohen, Stephen G West, and Leona S Aiken.Applied multiple regression/correlation analysis for the behavioral sciences. Routledge, 2013
2013
-
[57]
Scaffolding responsible software use: evaluating the effectiveness of a causal inference tool.The American Statistician, pages 1–11, 2026
George Perrett, Jennifer Hill, Anugya Srivastava, and Marc Scott. Scaffolding responsible software use: evaluating the effectiveness of a causal inference tool.The American Statistician, pages 1–11, 2026
2026
-
[58]
Amazon service was taken down by ai coding bot
R Rosner-Uddin. Amazon service was taken down by ai coding bot
-
[59]
Benjamin Weiser and Karen Zraick. A.i. ‘Hallucinations’ created errors in court filing, top law firm says.The New York Times, Apr 2026
2026
-
[60]
Is your SATT where it’s at?
Howard Bauchner and Frederick P Rivara. Fabricated references: a new threat to editorial integrity.The Lancet, 407(10541):1765–1766, 2026. 11 Flaws in the LLM Automation Narrative Appendix A: The prompt Contest Motivation: Causal inference researchers are constantly striving to create robust estimation procedures that will reliably estimate treatment effe...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.