i1: A Simple and Fully Open Recipe for Strong Text-to-Image Models
Pith reviewed 2026-06-27 13:35 UTC · model grok-4.3
The pith
A fully open 3B-parameter text-to-image diffusion model matches leading closed models on five benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
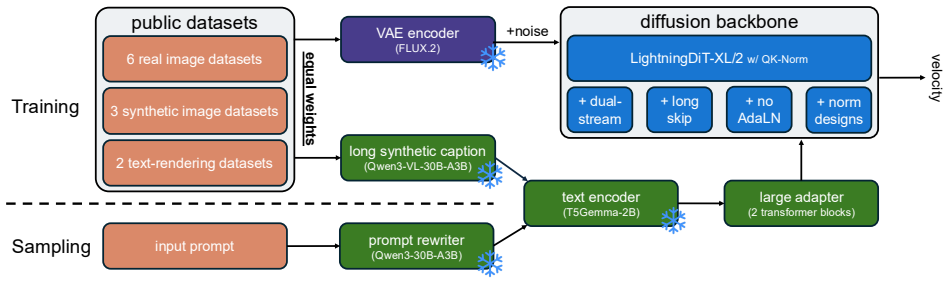
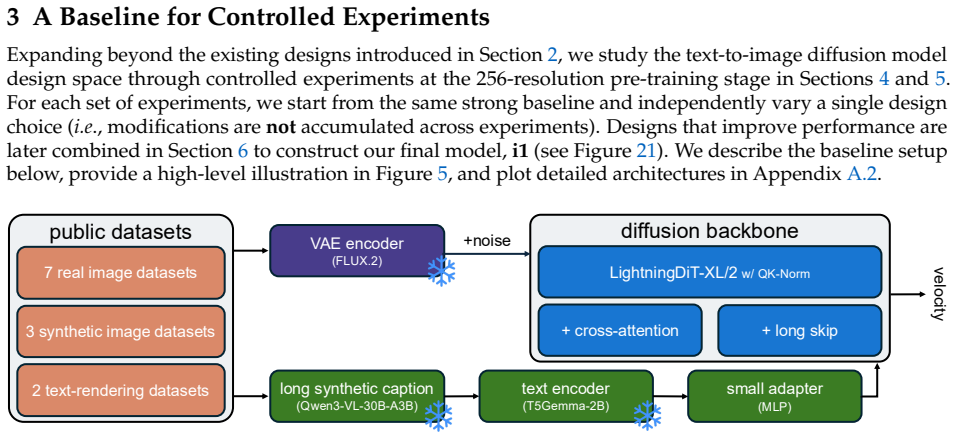
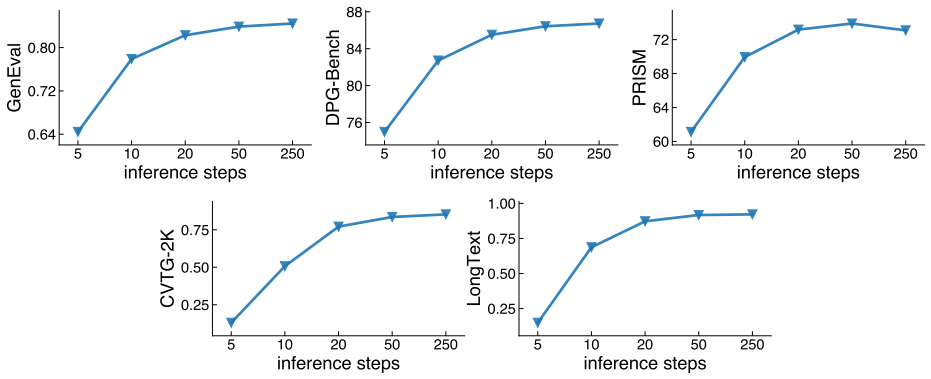
Systematic ablations reveal that equal weighting of curated datasets and modestly larger text-encoder adapters are strong defaults; when these and other simple choices are applied to train a 3B-parameter diffusion model on public data alone, the resulting i1 model matches closed leaders and exceeds the best previous fully open model by 29.5 absolute percentage points across five representative benchmarks.
What carries the argument
The set of empirical findings from 300+ ablations on dataset mixing, text encoder adapters, and related design decisions that together form the i1 training recipe.
If this is right
- Fully open text-to-image models can now reach performance levels previously limited to closed systems using only public resources.
- The released checkpoints, code, and data pipeline enable direct replication and extension by any researcher.
- Simple, non-proprietary design choices can close most of the gap to state-of-the-art performance.
- Future open research in diffusion-based generation can start from a documented, high-performing baseline rather than from scratch.
Where Pith is reading between the lines
- Releasing the full training pipeline may allow the community to test the same recipe on new public datasets or architectures.
- The emphasis on equal weighting suggests that careful curation alone, without proprietary weighting schemes, can be sufficient for strong results.
- If the model generalizes beyond the five benchmarks, it could serve as a testbed for studying failure modes that closed models hide.
Load-bearing premise
The five chosen benchmarks adequately measure overall text-to-image quality without favoring the modeling or data decisions tested in the experiments.
What would settle it
A new benchmark or large-scale human study in which i1 scores substantially below leading closed models while prior open models remain unchanged would undermine the claim of competitiveness.
Figures
























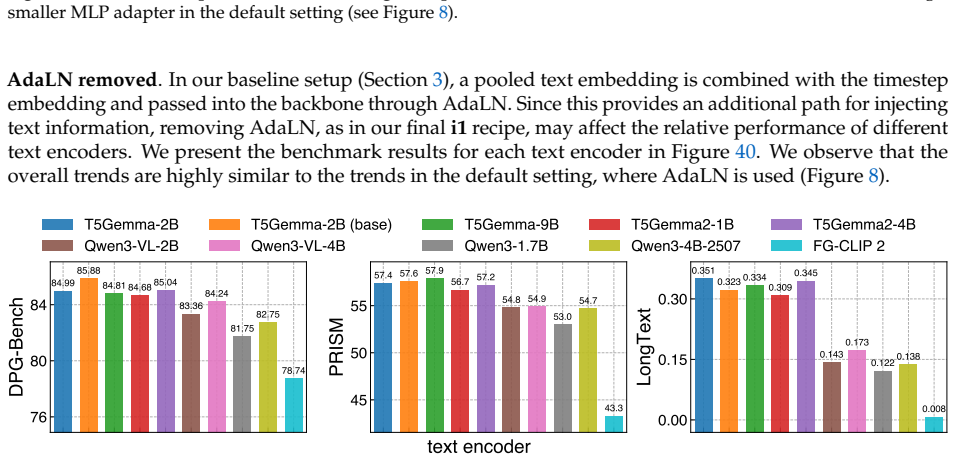





read the original abstract
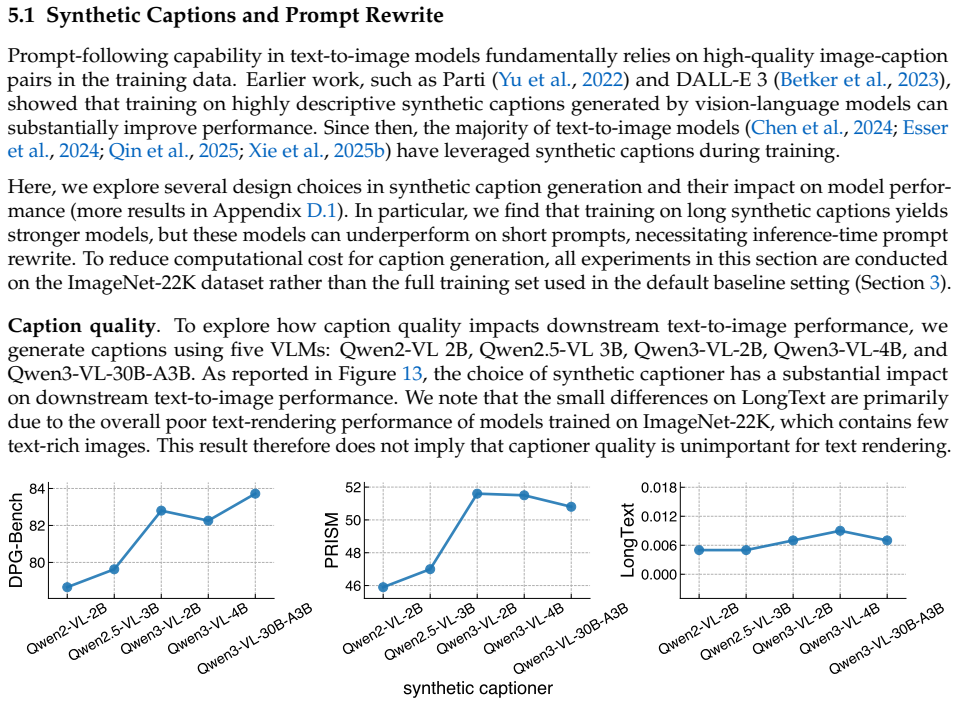
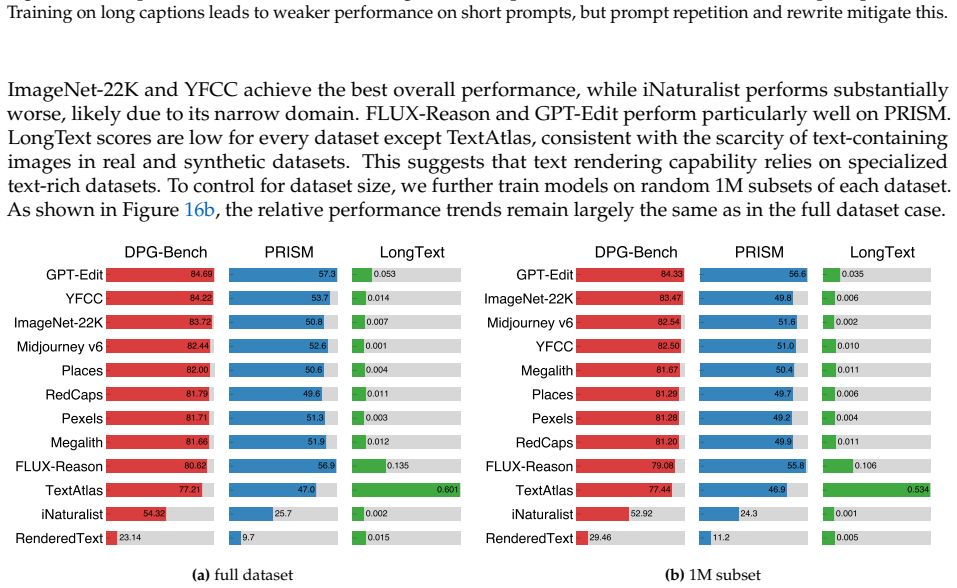
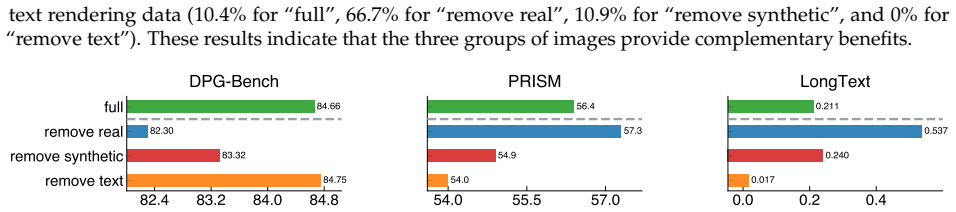
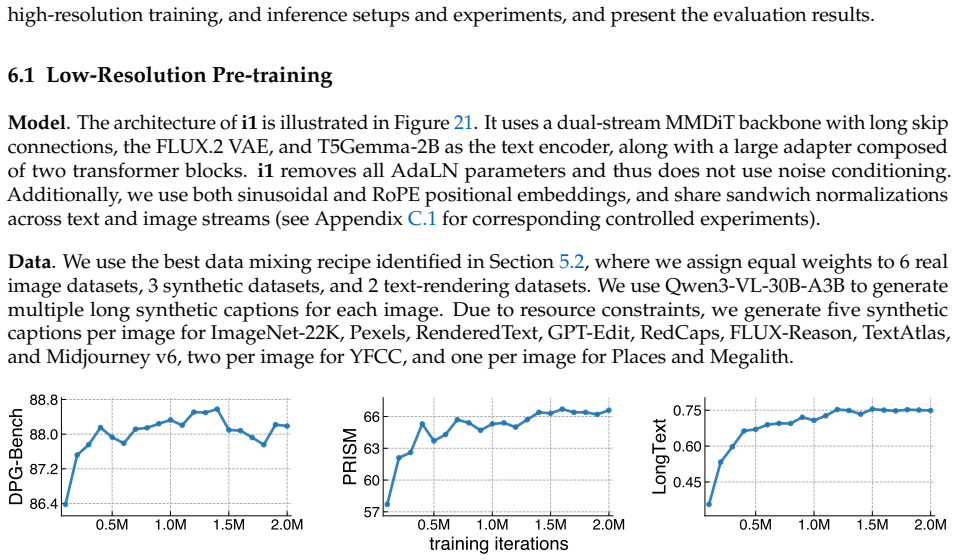
Diffusion models have consistently driven progress in text-to-image generation. However, it is challenging to attribute recent progress to specific modeling and data choices: state-of-the-art open-weight models provide limited ablations, and do not disclose their training data and full training details. The research community needs fully open (weights, data, and code) models as a foundation for further research; yet existing fully open models still fall significantly short of leading models in performance. In this project, we conduct a systematic investigation of the modeling and data design choices in text-to-image diffusion training and inference with 300+ controlled experiments totaling 700K+ TPU v6e hours. Our experiments highlight several empirical findings (e.g., equal weighting is a strong default for mixing curated datasets) and simple design decisions (e.g., larger text encoder adapters improve performance with minimal added parameters) for training strong models. Guided by these insights, we train i1, a 3B-parameter text-to-image diffusion model using only publicly available datasets. i1 is competitive with leading models on five representative benchmarks (GenEval, DPG, PRISM, CVTG-2K, and LongText), and outperforms the best existing fully open model by 29.5 absolute percentage points on average. We provide the i1 checkpoints, training and inference code, and the data processing pipeline. Together, our findings and the i1 recipe establish a practical foundation for future open research in text-to-image diffusion models. Our code is available at https://github.com/zlab-princeton/i1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts over 300 controlled experiments (700K+ TPU hours) on modeling and data choices for text-to-image diffusion models, identifies empirical insights such as equal weighting for dataset mixing and benefits of larger text-encoder adapters, and uses these to train i1, a 3B-parameter model on only public datasets. i1 is reported competitive with leading closed models and outperforms the best prior fully open model by 29.5 absolute percentage points on average across GenEval, DPG, PRISM, CVTG-2K, and LongText; the authors release weights, code, and data pipeline.
Significance. If the empirical findings and benchmark results hold under broader scrutiny, the work supplies a practical, fully open baseline (weights, code, and pipeline) that narrows the performance gap between open and closed text-to-image systems and enables reproducible follow-on research. The explicit release of training and inference code plus the data-processing pipeline is a concrete strength that supports community verification and extension.
major comments (2)
- [Abstract and evaluation description] The central performance claim (i1 competitive with closed models and +29.5 pp vs. best open model) rests exclusively on average scores across the five listed benchmarks (GenEval, DPG, PRISM, CVTG-2K, LongText). No orthogonal evaluation—human preference studies, FID on held-out distributions, or adversarial prompts outside these suites—is reported, leaving open the possibility that gains are aligned with the specific public-data mixes and design choices tested in the 300+ ablations rather than reflecting general improvements.
- [Introduction / experimental methodology] The manuscript states that 300+ controlled experiments were performed, yet provides no information on whether controls were pre-registered, whether multiple random seeds were averaged, or how post-hoc selection among the many ablations was handled; this directly affects the reliability of the “empirical findings” used to justify the final i1 recipe.
minor comments (2)
- Notation for the text-encoder adapter size and the precise definition of “equal weighting” for dataset mixing should be formalized with equations or pseudocode to allow exact reproduction.
- [Abstract] The abstract cites “five representative benchmarks” without a brief justification of why these particular suites were chosen over alternatives (e.g., why not include standard FID or human Elo ratings).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and evaluation description] The central performance claim (i1 competitive with closed models and +29.5 pp vs. best open model) rests exclusively on average scores across the five listed benchmarks (GenEval, DPG, PRISM, CVTG-2K, LongText). No orthogonal evaluation—human preference studies, FID on held-out distributions, or adversarial prompts outside these suites—is reported, leaving open the possibility that gains are aligned with the specific public-data mixes and design choices tested in the 300+ ablations rather than reflecting general improvements.
Authors: We acknowledge that the reported results rely on the five standard benchmarks. These suites were selected because they are the most commonly used public evaluations for text-to-image models and collectively probe prompt adherence, compositionality, and long-text handling. The manuscript does not include human preference studies, additional FID scores, or adversarial prompt sets. We will add a short limitations paragraph in the revised version noting the scope of the current evaluation and the value of future orthogonal assessments, while emphasizing that the fully open release of weights, code, and pipeline enables the community to perform such studies. revision: yes
-
Referee: [Introduction / experimental methodology] The manuscript states that 300+ controlled experiments were performed, yet provides no information on whether controls were pre-registered, whether multiple random seeds were averaged, or how post-hoc selection among the many ablations was handled; this directly affects the reliability of the “empirical findings” used to justify the final i1 recipe.
Authors: The experiments followed a systematic, one-factor-at-a-time design as described in the experimental sections, with each ablation varying only the targeted modeling or data choice. Pre-registration is not standard for exploratory large-scale ablation studies in this area. Key experiments averaged results over three random seeds where compute permitted; full averaging across all 300+ runs was not feasible given the 700K+ TPU-hour budget. Post-hoc selection was limited by adhering to the pre-defined experimental roadmap. We will insert a new subsection clarifying the experimental protocol, seed usage, and selection criteria to improve transparency. revision: yes
Circularity Check
No circularity: empirical results from public-data training and standard benchmarks
full rationale
The paper performs 300+ controlled experiments on public datasets, identifies empirical patterns such as equal weighting for data mixing, trains a 3B model, and reports scores on five external benchmarks (GenEval, DPG, PRISM, CVTG-2K, LongText). No equations, derivations, or fitted parameters are defined in terms of the target metrics; the central performance claim is a direct empirical outcome rather than a reduction to self-defined inputs or self-citation chains. Self-citations are absent from load-bearing steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DiffusionBench: On Holistic Evaluation of Diffusion Transformers
NanoGen unifies DiT training on ImageNet and T2I, reveals negative Pearson correlations (-0.377 to -0.580) in method rankings across metrics from 21 models, and motivates DiffusionBench for holistic evaluation.
Reference graph
Works this paper leans on
-
[1]
** Sequential Object Segmentation :** Describe objects one by one in a linear fashion to prevent feature bleeding , fully defining Object A before using a spatial marker to introduce Object B
-
[2]
four zebras
** Anti - Fusion Counting Logic :** When specifying a count ( e . g . , " four zebras ") , explicitly state the number and mandate that each instance is visually distinct , identical in nature , but clearly separated from the others
-
[3]
placed directly to the left of
** Rigid Spatial Anchoring :** Define exact relative positions using positive assertions ( e . g . , " placed directly to the left of ") rather than negative constraints , locking each object to a specific geometric coordinate in the frame
-
[4]
separated by a clear gap
** Negative Space Enforcement :** Explicitly force clear gaps and physical distance between objects using phrases like " separated by a clear gap " or " standing distinctly apart " to ensure object detection mechanisms can isolate them
-
[5]
** Attribute Binding :** Tightly bind adjectives such as color , shape , and material directly to their specific nouns immediately in the sentence to avoid cross - contamination of colors or textures between distinct objects
-
[6]
** Sensory Feature Hallucination :** Expand short , generic inputs by hallucinating rich physical textures , specific materials , and defined lighting setups to elevate the prompt length to the optimal 75 - 150 word range
-
[7]
bold , standard font ,
** Short - Text Typography :** For short quoted text , explicitly instruct the model to render it using terms like " bold , standard font ," " highly legible typography ," and " flat , undistorted lettering ."
-
[8]
** Text - Background Contrast :** Enforce high optical contrast for any rendered text by specifying that the text color sharply contrasts with the solid , plain surface it is written on , ensuring high detectability
-
[9]
** Background Neutrality :** Keep the overarching background uncluttered , neutral , or out - of - focus to maximize the visual saliency of the primary subjects and any textual elements
-
[10]
The Principle of Priority & Refinement
** Photographic Standardization :** Ground the scene in realistic studio or natural lighting with sharp focus ( unless an art style is specified ) , which enhances the geometric clarity of the objects and text . ### ** Mode B : Narrative - Dense Input ( Descriptive / Artistic / Long Text ) ** * Trigger :* Input is descriptive , structurally dense ( typica...
-
[11]
** Subject - Context Front - Loading :** Move the primary subject , main action , and the most critical textual elements to the absolute start of the prompt so they receive the highest attention weights
-
[12]
** Exact Text Transcription :** For long text blocks or paragraphs , transcribe the quoted content exactly 39 as provided without altering a single character , word , or punctuation mark
-
[13]
centered block of text ,
** Long - Text Formatting :** Describe the structural layout of long text using precise terms like " centered block of text ," " neatly aligned lines ," " clear margins ," or " bullet points " to maintain structural integrity
-
[14]
crisp , high - contrast , uniform lettering ,
** Enhanced Legibility Modifiers :** Boost the detectability of long , dense text by mandating " crisp , high - contrast , uniform lettering ," " even lighting across the text surface ," and " zero distortion or overlapping strokes ."
-
[15]
** Non - Essential Detail Trimming :** When the text to be rendered is extremely long , compress or strip away overly complex background or environmental descriptions to avoid capacity overload , ensuring the text remains the absolute visual priority
-
[16]
** Syntactic Decomplexing :** Break long , winding narrative sentences into punchy , independent , active - voice statements , forcing the model to render one visual concept fully before calculating the next
-
[17]
** Sensory Sharpening :** Translate vague , abstract , or emotional concepts into concrete , renderable physical properties , replacing poetic language with specific lighting , color , and texture instructions
-
[18]
** Anti - Hallucination Grounding :** Explicitly define the boundaries of the scene and do not introduce unprompted objects or extraneous elements that were not implied by the dense input graph
-
[19]
** Semantic Coverage Preservation :** Ensure that every distinct noun , verb , and requested attribute from the original dense input is accounted for and translated into the final rewritten output
-
[20]
- - - ** General Rewrite Rules :**
** Cohesive Stylistic Binding :** Reiterate the requested art style , medium , or global atmospheric lighting at the very end of the prompt to bind all the dense , disparate elements into a single cohesive image . - - - ** General Rewrite Rules :**
-
[21]
** Length Strategy :** Target a final output length strictly between 75 - 150 words
-
[22]
** Tone :** Objective , descriptive , and visually grounded
-
[23]
is painted on this board in bold , crisp white letters , ensuring maximum contrast and legibility . To the right , separated by a clear gap , is a solid wooden bench . The word
** Output Format :** Output exclusively the final rewritten prompt string . Do not output classification labels , reasoning , or conversational filler . - - - ** Few - Shot Examples :** ** Input ( Mode A - Spatial / Shape ) :** A triangular sign and a small sculpture ** Output :** A triangular metal road sign stands firmly on the left side of the frame . ...
1957
-
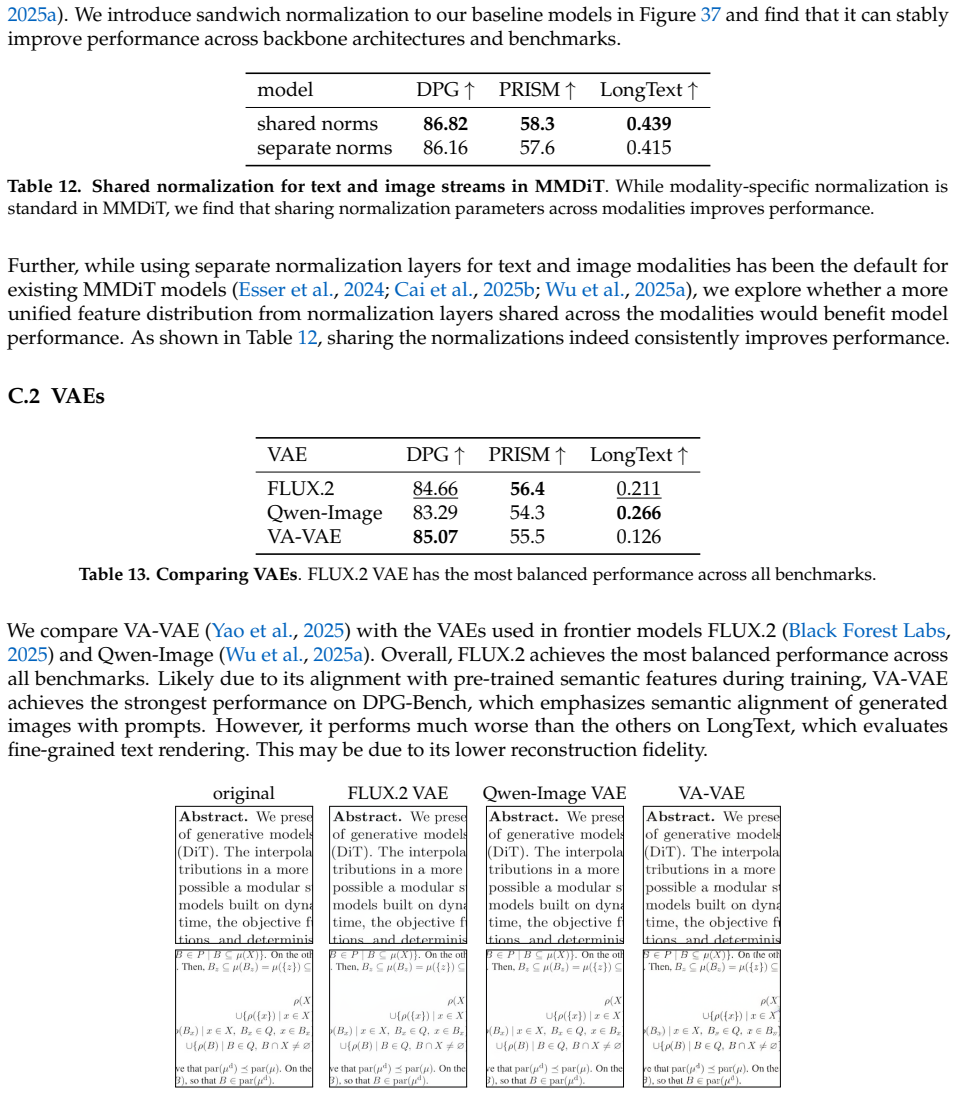
[24]
and Qwen-Image (Wu et al., 2025a). Overall, FLUX.2 achieves the most balanced performance across all benchmarks. Likely due to its alignment with pre-trained semantic features during training, VA-VAE achieves the strongest performance on DPG-Bench, which emphasizes semantic alignment of generated images with prompts. However, it performs much worse than t...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.